







如果说新手如何快速了解GAN,那么这篇论文tutorial应该会被大家推荐。首先作者牛,Ian Goodfellow就是GAN之父;其次文章详细,不仅有技术,也有背景、思想、技巧。我也同样是一名GAN新手,读了之后理解的并不一定很准确,也希望和大家多交流。
为什么要学习GAN
第一部分首先解答了why,总结来说,有以下几点:
- 生成模型是对我们表达高维概率分布的考验
- 生成模型可以通过几种方式与强化学习相结合(包括model-based、model-free)
- 时序生成模型可以预测未来
- 能够在虚拟环境中学习,并应用到真实环境
- 可以使用缺失数据进行训练,并对缺失数据进行预测
- 处理多模态输出(单一输入对应不同正确输出)
- 许多任务本质上需要从一些分布中现实地生成样本
可以说,这是能让计算机进行自我创作的一种途径。在过去的几年中,我们一直去教给计算机很多知识,比如这是一只狗,那是一只猫,计算机也很听话的记住了这些知识。如今我们向计算机提出这个问题:狗是什么样的,计算机能够解答吗?其实之前也有人尝试过,用反卷积的方法,恢复出狗的样子,但是效果并不好,一股抽象派画风,毕竟没有经过专门的训练。
GAN在擅长的领域:
- 超分辨率
- 艺术创作
- Image-to-image translation
超分辨率重建是图像复原的全新手段。这让我想起了16年光电设计,据说就有队采用这种方法,搬台电脑跑很长时间。从光学上恢复,就要考虑镜头啊、点扩散函数啊之类的,而深度学习的超分辨率,是需要靠计算机自己脑补的。

艺术创作好说,风格迁移技术目前也比较成熟了。
最后一个大家可能还是比较陌生的,这是一个类似于神笔马良的工具,通过简单的简笔画,就能生成较为复杂的实物图片。之前网上也流行过一阵,现在一时找不到链接了。。
GAN如何工作?
如果详细地讲,那会很复杂,特别是概率、损失来看。不过我不会着重讲这些,一个是因为难于理解,另一个是因为我也怕讲错了= =
还是拿Goodfellow的比喻吧:G是一个生产假币的队伍,想尽办法让假币无法被识别出来;D是警察,想尽办法查出假币。双方不断在竞争,不断学习,从而达到生成器可以以假乱真的效果。这些也在我之前写的博客中有介绍: Generative Adversarial Nets。GAN可以被看作是一个强化学习,但又有所区别。生成器并没有直接接触到训练数据,所有有关训练数据的信息只是通过判别器学到的。
稍微复杂一点说,我们所做的生成器
pmodel
,是需要学习模型的概率分布
pdata
,如果我们做得很完美很精确,那么我们完全可以恢复出
pdata
。但我们无法访问
pdata
本身,只有
pdata
采样出来的
m
个样本。如何用部分去尽可能得恢复全部,是我们所需要思考的。我们不可能把世界上的所有猫都看个遍,但我们仍有分辨猫、创作猫的能力,这就是因为我们学到了猫的特征和共性的特点。按说计算机也有相同的能力,至少在分辨上,为什么生成就更难一些呢?

这就跟我们之前给的评判标准(或者是损失)有关了。比如上图是视频序列预测,真实值是左边,中间是优化均方差(mean squared error )得到的。看起来很模糊,这就是因为预测就带有不确定性,稍微上下左右偏一些,MSE就会很大。因此在使MSE最小这个过程中,就自动平均了各种可能出现的情况,导致图像模糊。因此这也不能够怪计算机算得不准,而是评价标准不好。有时多种人能接受的预测,我们只需要选择其中一种即可,而不是多种的平均。
损失函数
GAN分为判别器和生成器两个损失,判别器损失
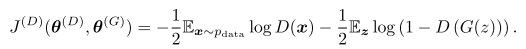
而生成器损失 J(G) 分为多种,比如:
- Minimax
- Heuristic, non-saturating game
- Maximum likelihood game
Minimax
Minimax game也就是零和游戏,直接将判别器的损失取反:
判别器使交叉熵变小,而生成器又最大化相同的交叉熵,当然其优化的参数是不一样的。
从直观上很好理解,既然两个的任务相反(造假和验假),那么干脆损失相反就好了。但这样会导致当判别器以高置信拒绝生成的样本时,生成器梯度消失,从而难以训练。
non-saturating game
这个就是为了让每方出现错误时都能产生很强的梯度:
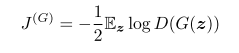
也采用交叉熵最小,且是非零和的。
Maximum likelihood game
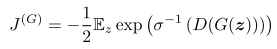
极大似然的方式,减小数据与模型的KL散度,其中
σ
是logistic sigmoid function。
GAN结构
具体的GAN结构大多数都是在Goodfellow的框架下,很多也只是在修改loss function,github上有一个项目:generative-models收集了很多GAN模型,我们拿来看一下,例子是LSGAN。
主要的代码和注释:
X = tf.placeholder(tf.float32, shape=[None, X_dim]) # X为图像输入,mnist 784
z = tf.placeholder(tf.float32, shape=[None, z_dim]) # z为噪声输入,64
...
...
def sample_z(m, n):
return np.random.uniform(-1., 1., size=[m, n]) # 生成随机噪声
def generator(z): # 生成器模型
G_h1 = tf.nn.relu(tf.matmul(z, G_W1) + G_b1) # 把噪声作为输入,经过两层全链接
G_log_prob = tf.matmul(G_h1, G_W2) + G_b2
G_prob = tf.nn.sigmoid(G_log_prob)
return G_prob # 输出图像
def discriminator(x): # 鉴别器模型
D_h1 = tf.nn.relu(tf.matmul(x, D_W1) + D_b1) # 把图像作为输入,经过一层全链接输出
out = tf.matmul(D_h1, D_W2) + D_b2
return out # 输出判别结果
G_sample = generator(z) # 生成结果
D_real = discriminator(X) # 对于真数据,判别器给出的结果
D_fake = discriminator(G_sample) # 对于假数据,判别器给出的结果
# LS损失函数
D_loss = 0.5 * (tf.reduce_mean((D_real - 1)**2) + tf.reduce_mean(D_fake**2)) # 鉴别器损失
G_loss = 0.5 * tf.reduce_mean((D_fake - 1)**2) # 生成器损失
D_solver = (tf.train.AdamOptimizer(learning_rate=lr)
.minimize(D_loss, var_list=theta_D)) # 优化鉴别器
G_solver = (tf.train.AdamOptimizer(learning_rate=lr)
.minimize(G_loss, var_list=theta_G)) # 优化生成器DCGAN
上面项目的代码都是以mnist为数据集,且层数很少,只是拿来理解用的。真正实用的还是deep convolution 结构。这种结构也是借鉴了CNN,把卷积层反向换成了反卷积:

文中提到了几点需要注意的地方:
- 使用batch normalization(除了G最后一层和D第一层)
- 主要结构为全卷积网络,无pooling、unpooling层(没有这两种层是趋势)
- 使用Adam优化器而不是SGD

GAN还有一点有趣的是可以在潜在空间中用简单运算进行有意义的语义解释,比如我们用这样一个公式:眼镜男-男+女=眼镜女,就可以在没有眼镜女数据的情况下生成眼镜女图像:

GAN tips and tricks
训练技巧
- train with labels
也就是class-conditional GAN。传统的GAN在生成时输入的是随机的噪声,因此很难控制输出的结果。如果在训练时加入类别条件信息,生成时也加入其中,就可以实现定向、定类生成。 - One-side label soothing
方法是对于真实图片,鉴别器的标签不设置为1,而是0.9这种接近于1的数字。目的是避免D过于自信。 - virtual batch normalization
如果使用不同的minibatch进行归一化处理,会导致参数的波动,特别是batch小的时候,minibatch间应该相互独立。
G与D的平衡
G与D两个的地位有区别吗?哪个更重要一些呢?
Goodfellow这样说:GAN通过估算数据密度和模型密度的比例来工作,只有D最佳时,才能正确估计,因此D应该占主导地位。从另一个角度说,D的层可以更深一些。
但有时D太准确又导致G的梯度消失,这也就是之前minimax game中所提到的问题。
有时D过于自信,拒绝G的生成,又会导致G梯度爆炸,这种情况可以用one-sided label smoothing解决。
还有一个问题是G与D的训练方法,既然D比较重要,那么G训练一次,D训练多次,会有改进吗?这个问题不同论文给出的结果不尽相同,没有统一的答案,有空的话都试试好了。
GAN的问题
最重要的问题就是难以收敛(Non-convergence),两个players 在训练中相互干扰,自然很难。目前在function space更新,可以证明是收敛的;但实际上训练是在parameter space更新,是否收敛没有明确的证明。
另一个问题是mode collapse:

在学习中只学习到了一部分的分布,没有学习到所有模式。而鉴别器在鉴别时会拒绝单一模式,因此会导致生成器在单一模式中循环生成,无法收敛,如上图所示。
针对这一问题,目前有minibatch feature、unrolled GAN等方法,具体不再讲解。
写到现在感觉还是疏漏了很多东西,其中一部分也是自己还没有能明白的,不敢班门弄斧。具体还是要去看57页原文才能全面了解。国内也有一些资料,比如今年的《生成对抗网络GAN的研究与展望》,也是比较新,可以当作参考和了解。
王坤峰 ,苟超 ,段艳杰 ,林懿伦 ,郑心湖,王飞跃 . 生成对抗网络GAN的研究与展望. 自动化学报, 2017,43(3): 321-332















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









