






## load the data
face <- read.csv("face.csv")
## two-party vote share for Democrats and Republicans
face$d.share <- face$d.votes / (face$d.votes + face$r.votes)
face$r.share <- face$r.votes / (face$d.votes + face$r.votes)
face$diff.share <- face$d.share - face$r.share
plot(face$d.comp, face$diff.share, pch = 16,
col = ifelse(face$w.party == "R", "red", "blue"),##col设置颜色,w.party是R就是红色,不是就是蓝色
xlim = c(0, 1), ylim = c(-1, 1),
xlab = "Competence scores for Democrats",
ylab = "Democratic margin in vote share",
main = "Facial competence and vote share")plot函数:写在前面的是x,后是y。col设置颜色。ifelse(判断条件,是会咋样,否会咋样)
cor(face$d.comp, face$diff.share)cor计算相关系数。返回值介于(-1,1)之间,-1表示完全负相关,1表示完全正相关,0表示没有线性关系。
fit <- lm(diff.share ~ d.comp, data = face) # fit the model
fit
## lm(face$diff.share ~ face$d.comp)
coef(fit) # get estimated coefficients
head(fitted(fit)) # get fitted or predicted values
plot(face$d.comp, face$diff.share, xlim = c(0, 1.05), ylim = c(-1,1),
xlab = "Competence scores for Democrats",
ylab = "Democratic margin in vote share",
main = "Facial competence and vote share")
abline(fit) # add regression line
abline(v = 0, lty = "dashed")
epsilon.hat <- resid(fit) # residuals
sqrt(mean(epsilon.hat^2)) # RMSElm函数的格式:myfit<-lm(formula,data)其中,formula指要拟合的模型形式,data是一个数据框,包含了用于拟合模型的数据。lm里面是(y~x)
输出结果:
Call:
lm(formula = diff.share ~ d.comp, data = face)
Coefficients:
(Intercept) d.comp
-0.3122 0.6604
cofficients第一个是截距第二个是斜率。上面的就是diff.share = 0.6604d.comp-0.3122
coef(fit)就是查看以上的两个系数,输出结果:
> coef(fit)
(Intercept) d.comp
-0.3122259 0.6603815 fitted()是回归拟合的预测值
fitted(拟合)是在给定样本上做预测,而predict(预测)是在新的样本上做预测
> head(fitted(fit))
1 2 3 4 5 6
0.06060411 -0.08643340 0.09217061 0.04539236 0.13698690 -0.10057206 输出前6条拟合数据。用的就是上述的截距和斜率,比如第一条:d.comp=0.564567612,斜率取0.6603815,截距取-0.3122259,计算结果就是0.06060411。第二条到第六条也是这么算的。
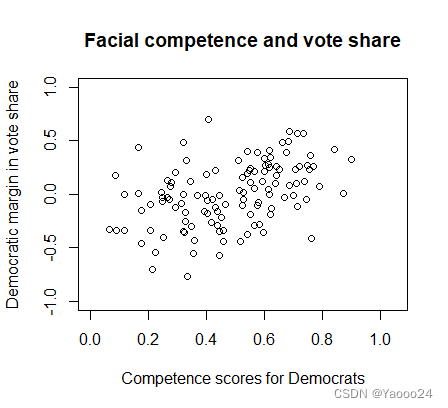
plot(face$d.comp, face$diff.share, xlim = c(0, 1.05), ylim = c(-1,1),
xlab = "Competence scores for Democrats",
ylab = "Democratic margin in vote share",
main = "Facial competence and vote share")画出来如下图:
abline()函数:增加一条线:abline 函数的作用是在一张图表上添加直线, 可以是一条斜线,通过x或y轴的交点和斜率来确定位置;也可以是一条水平或者垂直的线,只需要指定与x轴或y轴交点的位置就可以了。v=多少就是x轴等于多少(相当于加一条平行于y轴的直线),h=多少就是y等于多少(相当于加一条平行于x轴的直线)
abline(fit) # add regression line
abline(v = 0, lty = "dashed")abline(fit)就是加上述那个一次函数那条线(线性模型),加完上面两条线之后如图:

residuals:残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。“残差”蕴含了有关模型基本假设的重要信息。如果回归模型正确的话, 我们可以将残差看作误差的观测值。
为了明确解释变量和随机误差各产生的效应是多少,统计学上把数据点与它在回归直线上相应位置的差异称为残差,把每个残差平方之后加起来 称为残差平方和,它表示随机误差的效应。一组数据的残差平方和越小,其拟合程度越好。如下为计算残差和:
epsilon.hat <- resid(fit) # residuals残差
sqrt(mean(epsilon.hat^2)) # RMSEsqrt计算平方根,mean计算平均值,里面是残差的平方的和。如下图:
> epsilon.hat <- resid(fit) # residuals残差
> sqrt(mean(epsilon.hat^2)) # RMSE
[1] 0.2642361———————————————————————————————————————————
## proportion of female politicians in reserved GP vs. unreserved GP
mean(women$female[women$reserved == 1])#reserved=1中女性的比例
mean(women$female[women$reserved == 0])#reserved=0中女性的比例给所有reserved=1的female算平均值,由于female只有0或者1,所以算出来的就是reserved=1中female=1的占比。
mean(women$water[women$reserved == 1]) -
mean(women$water[women$reserved == 0])reserved=1的water的平均值减去reserved=0的waterd的平均值
> sum(women$water[women$reserved == 1])
[1] 2591
> sum(women$reserved == 1)
[1] 108reserved=1的water求和是2591,reserved=1的一共108条,除完了就是平均值。















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









