







PNN模型理论和实践
1、原理
PNN,全称为Product-based Neural Network,认为在embedding输入到MLP之后学习的交叉特征表达并不充分,提出了一种product layer的思想,既基于乘法的运算来体现体征交叉的DNN网络结构,如下图:

按照论文的思路,我们也从上往下来看这个网络结构:
输出层
输出层很简单,将上一层的网络输出通过一个全链接层,经过sigmoid函数转换后映射到(0,1)的区间中,得到我们的点击率的预测值:
![]()
l2层
根据l1层的输出,经一个全链接层 ,并使用relu进行激活,得到我们l2的输出结果:
![]()
l1层
l1层的输出由如下的公式计算:
![]()
重点马上就要来了,我们可以看到在得到l1层输出时,我们输入了三部分,分别是lz,lp 和 b1,b1是我们的偏置项,这里可以先不管。lz和lp的计算就是PNN的精华所在了。我们慢慢道来
Product Layer
product思想来源于,在ctr预估中,认为特征之间的关系更多是一种and“且”的关系,而非add"加”的关系。例如,性别为男且喜欢游戏的人群,比起性别男和喜欢游戏的人群,前者的组合比后者更能体现特征交叉的意义。
product layer可以分成两个部分,一部分是线性部分lz,一部分是非线性部分lp。二者的形式如下:

在这里,我们要使用到论文中所定义的一种运算方式,其实就是矩阵的点乘啦:
![]()
我们先继续介绍网络结构,有关Product Layer的更详细的介绍,我们在下一章中介绍。
Embedding Layer
Embedding Layer跟DeepFM中相同,将每一个field的特征转换成同样长度的向量,这里用f来表示。
![]()
损失函数
使用和逻辑回归同样的损失函数,如下:
![]()
2、Product Layer详细介绍
前面提到了,product layer可以分成两个部分,一部分是线性部分lz,一部分是非线性部分lp。
看上面的公式,我们首先需要知道z和p,这都是由我们的embedding层得到的,其中z是线性信号向量,因此我们直接用embedding层得到:
![]()
论文中使用的等号加一个三角形,其实就是相等的意思,你可以认为z就是embedding层的复制。
对于p来说,这里需要一个公式进行映射:
![]()
![]()
不同的g的选择使得我们有了两种PNN的计算方法,一种叫做Inner PNN,简称IPNN,一种叫做Outer PNN,简称OPNN。
接下来,我们分别来具体介绍这两种形式的PNN模型,由于涉及到复杂度的分析,所以我们这里先定义Embedding的大小为M,field的大小为N,而lz和lp的长度为D1。
2.1 IPNN
IPNN的示意图如下:

IPNN中p的计算方式如下,即使用内积来代表pij:
![]()
所以,pij其实是一个数,得到一个pij的时间复杂度为M,p的大小为N*N,因此计算得到p的时间复杂度为N*N*M。而再由p得到lp的时间复杂度是N*N*D1。因此 对于IPNN来说,总的时间复杂度为N*N(D1+M)。文章对这一结构进行了优化,可以看到,我们的p是一个对称矩阵,因此我们的权重也可以是一个对称矩阵,对称矩阵就可以进行如下的分解:

因此:


因此:
![]()
从而得到:

可以看到,我们的权重只需要D1 * N就可以了,时间复杂度也变为了D1*M*N。
2.2 OPNN
OPNN的示意图如下:

OPNN中p的计算方式如下:

此时pij为M*M的矩阵,计算一个pij的时间复杂度为M*M,而p是N*N*M*M的矩阵,因此计算p的事件复杂度为N*N*M*M。从而计算lp的时间复杂度变为D1 * N*N*M*M。这个显然代价很高的。为了减少负责度,论文使用了叠加的思想,它重新定义了p矩阵:

这里计算p的时间复杂度变为了D1*M*(M+N)
计算广告CTR预估系列(八)--PNN模型理论与实践
一、介绍
1.1 名词解释
1.2 数据特点
1.3 参数约定
二、相关工作
三、损失 & 评价函数
3.1 损失函数
3.2 评价函数
四、PNN详解
4.1 架构图
4.2 IPNN
4.3 OPNN
4.4 PNN*
五、优化
六、总结
七、代码实战
IPNN
OPNN
Reference
计算广告CTR预估系列往期回顾
一、介绍
非常感谢PNN论文作者,上海交通大学曲彦儒同学的耐心讲解,PNN细节的地方还是挺多的。作者的github大家可以关注下:
https://github.com/Atomu2014
1.1 名词解释
User Response Prediction:
在信息检索领域(IR,Information Retrieval),个性化任务是一类非常重要的任务。包括:推荐系统、web search、线上广告。
其核心就是User Respinse Predicton,是指给出用户关于一个预先定义好的行为的概率。这些行为包括:clicks、purchases。预测的概率代表了用户对特定物品感兴趣的程度,物品包括:新闻、商品、广告。而这会影响商家对于展示文档的排序,广告投标等。
1.2 数据特点
IR问题最大的数据特点就是multi-field categorical,举例来说:[Weekday=Tuesday, Gender=Male, City=London],经过one-hot之后转换成高纬度稀疏的数据:
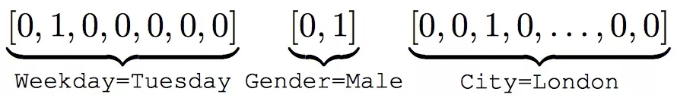
One-hot示例
一个类别型特征就是一个field,比如上面的Weekday、Gender、City这是三个field。
1.3 参数约定
我们约定参数含义如下:
-
N。Field个数,也是嵌入向量的个数。
-
M。Embedding Vector的维度。
-
D1。第一个隐藏层的神经元个数。
-
lz。Product Layer中z对应的输出,也就是lz乘以全连接权重w就得到了第一个隐层的输入的一部分。
-
lp。Product Layer中p部分对应的输出,再经过全连接权重W就得到第一个隐层的输入的一部分。
二、相关工作
在PNN之前提出了Logistic Regression、GBDT、FM等模型,期待能高效的学习线性与非线性模式,减少人工特征工程的干预。但是都不是非常理想,像LR GBDT依旧非常依赖人工特征工程,FM则缺少对高阶组合特征的建模,仅仅对特定阶的组合特征建模。
随着DNN在图像处理、语音识别、自然语言处理领域大放异彩,将DNN应用于CTR预估或者推荐系统的研究逐渐多了起来。DNN的输入往往是dense real vector 但是multi-field类别型特征起初是高维且稀疏的。常见的做法是通过加入Embedding Layer将输入映射到低维度的Embedding空间中。FNN使用FM初始化embedding vector,同时也受限于FM;CCPM利用CNN卷积来学习组合特征,但是只在相邻的特征间卷积,没有考虑到非相邻的特征的组合;
所以有了PNN,主要的做法如下:PNN包括三层:Embedding Layer、Product Layer、Full-connect Layer。
-
最开始的输入太稀疏维度太高,没法直接放到DNN中去学习,所以比较通用的做法就是通过Embedding到一个低维的稠密的实数向量中,作为原始特征的在Embedding空间中的表示。
-
然后PNN利用Product Layer来学习filed之间的交互特征,这也就引入了非线性的组合特征。可以采用内积、外积、内积+外积的形式。
-
最后利用全连接层充分的学习高阶组合特征,并得到最终CTR预测概率。
三、损失 & 评价函数
3.1 损失函数
PNN使用的是log loss,形式化如下:
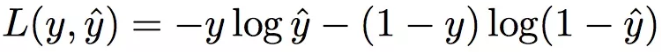
PNN log loss
3.2 评价函数
论文中给出了几种常用的评价函数,包括:AUC、log loss、RIG、RMSE。
RIG(Relative Information Gain), RIG = 1 - NE。 NE就是我们上一篇文章LR+GBDT中提到过的Normalized Cross Entropy。
四、PNN详解
4.1 架构图

PNN 架构图
我们按照上图,一层一层的来分析,看看从输入到输出,模型有哪些参数,参数的维度大小是多少,哪些需要训练,哪些不用训练:
Input:
首先,一个类别型特征就是一个Field。比如用户信息包括:性别、职业等,这里的性别是一个Field,职业是另一个Field。上图中的Input是one-hot之后的,而且只给出了类别型特征。所以每个Field i都是一个向量,向量的大小就是类别型特征one-hot之后的维度。所以不同Field的维度是不同的。
Embedding Layer:
上图说的非常清楚,Embedding是Field-wisely Connected。什么意思那?就是每个Field只管自己的嵌入,Field之间网络的权重毫无关系,自己学习自己的。而且只有权重,没有bias。一个Field经过嵌入后,得到一个Feature,也就是对应的Embedding Vector嵌入向量。其维度一般是预先设定好的定值,论文中采用的是10. 也就说是不同Feature的维度都是一样的。
Product Layer:
重点来了,上图有个地方困扰我很久,最终跟论文作者讨论了下终于看懂了。先给出结论:
-
Product Layer中z中每个圈都是一个向量,向量大小为Embedding Vector大小,向量个数 = Field个数 = Embedding向量的个数。
-
Product Layer中如果是内积,p中每个圈都是一个值;如果是外积,p中每个圆圈都是一个二维矩阵。
一个是向量,一个是值(也可能是矩阵),全给画成圈了(吐槽下……)
解释下怎么回事,这里对于Embedding Vector有两种处理策略:
-
直接和内积或外积结果拼接,输入到神经网络
-
先进行一次线性变换,再和内积或外积结果拼接,输入到神经网络
Embedding Layer中的那个1,其实就是直接把Embedding Vector拿来用并没有进行线性变换。这样做处理起来很简单,但是也有个缺点。Embedding Vector和内积项或外积项的数值分布差异交大,没有进行线性变换,导致分布不稳定不利于训练。不过,听作者说,在新论文中这个问题已经被很好的解决了,大家拭目以待吧~
在数据流中,假设Field个数为N,那么经过Embedding后的Field得到了N个Feature,或者说是N个嵌入向量。这N个嵌入向量直接拿过来并排放到z中就是z。这部分代表的是对低维度特征,或者说原始特征的建模。作者的说法是,不加入这一部分训练会非常不稳定,加入之后稳定了很多。
然后,针对这N个嵌入向量,两两组合进行Product operation,把结果放到一起就得到了p。首先,N个向量两两组合,会产生N(N-1)/2对组合,这就是p中圆圈的个数,或者说神经元的个数。如果是内积运算,那么每个神经元就是一个实数值;如果进行外积运算,那么每个神经元就是一个二维矩阵。后面我们详细讨论。
Hidden Layer:
把z和p直接拼接起来,就得到了第一个隐层的输入。经过多个隐藏层最后给出CTR预测值。
根据Product Layer的操作不同,PNN有三种变体:IPNN、OPNN、PNN*
4.2 IPNN
如果Product Layer使用内积运算,那么就是IPNN。p中每个神经元都是一个实数值,和z中的嵌入向量拼接起来,喂给神经网络就行了。
4.3 OPNN
如果Product Layer使用外积运算,就得到OPNN。外积得到的是一个矩阵,所以p中的每个神经元都是一个矩阵。针对两个M维的嵌入向量e1和e2. 它们外积得到的是M*M的二维矩阵。一共有N个嵌入向量,那么矩阵就有N(N-1)/2个。那么一个二维矩阵怎么输入到神经网络中去那?
针对外积产生的每一个二维矩阵,我们都通过另外一个矩阵W,大小为M*M。这两个矩阵对应位置相乘,再相加,就得到了最终的结果。
也就是说,最终外积产生的二维矩阵,通过和另外一个需要学习的参数矩阵,对应位置相乘,再相加,得到了一个标量,一个实数值。
逻辑上如下图所示:

PNN_Product_Layer逻辑理解
上图是最朴素的逻辑,实际写代码的时候利用下面的公式来稍微降低下复杂度:
假设两个嵌入向量,列向量U,V。⊙表示对应位置相乘,然后再相加的操作。UV的外积结果为二维矩阵。那么有公式:![]()
等式右边比左边的复杂度要低一些。写代码的时候,就是按照公式右边来计算的。公式可以这样理解:外积与参数矩阵相乘,相当于对u经过w矩阵投影,在投影空间中与v计算内积。是一个非常有用的trick。这里的参数矩阵并不是神经网络的参数矩阵,而是用来把外积的结果矩阵,转变为一个实数值的矩阵,对应代码中的kernel矩阵。
4.4 PNN*
如果Product Layer同时使用内积+外积,把内积和外积的结果拼接起来,就得到PNN*。
五、优化
PNN中针对内积和外积的运算都进行了优化。但是其实并不是必须的,只要计算资源足够,两个优化直接忽略即可。
PNN原始的论文中,针对外积部分每两个嵌入向量组合,一共有N(N-1)/2这么多对组合。这个复杂度是O(NN)的,论文中通过下面的公式进行了化简:
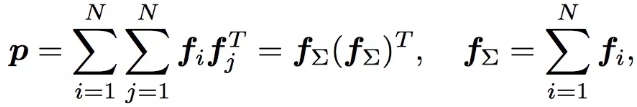
论文中针对外积的优化,已经去掉
其中的fi就是嵌入向量。也就是说先把所有的嵌入向量相加求和,然后再和自己进行外积。得到一个(N,N)的外积矩阵。然后再和D1个不同的W进行对应位置相乘相加的操作,就得到了最后隐藏层输入的D1个值。
这里的优化主要是把嵌入向量的N(N-1)/2个组合对,优化成了一个。把平方的复杂度降低到线性的。
但是,经过作者沟通了解到,这一部分的优化其实没必要,在新的PNN中已经去掉了!
为什么那?因为即使是N平方的复杂度,但是每两个嵌入向量进行外积的计算完全可以并行化!其实是可以接受的,所以现在已经去掉了。
我们后面给出的代码也是没有进行优化的,因为嵌入向量的pair仍然是N^2的。
六、总结
PNN从FM何FNN的角度出发,提出利用内积或者外积来学习高阶的非线性特征,还是挺有创新的。
基本上使用DNN的模型,最开始都是经过Embedding把原始高纬度稀疏的输入转换为低维度稠密的向量,PNN也不例外。对于FM来说,这就是隐向量,FNN也是利用FM来进行Embedding Vector的初始化的。
-
PNN中如果采用内积操作,那么嵌入向量两两组合每对组合都得到一个实数值。如果后面隐藏层的权重矩阵W全是1的话,那么PNN就变成了FM。
-
PNN使用外积操作稍微麻烦,因为嵌入向量两两组合后,每对组合就是一个二维矩阵。那么怎么把这些二维矩阵输入到神经网络中那?通过和一个矩阵对应位置相乘在相加,就把这些二维外积矩阵转换成了一个实数值。
-
OPNN的实现代码中利用了公式进行了转换,稍微降低了复杂度。公式如下:
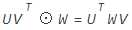
-
另外,PNN论文中针对外积部分的优化,跟作者沟通得知在新的论文中已经去掉了,大家就不用纠结了
NFM模型理论和实践
1、引言
在CTR预估中,为了解决稀疏特征的问题,学者们提出了FM模型来建模特征之间的交互关系。但是FM模型只能表达特征之间两两组合之间的关系,无法建模两个特征之间深层次的关系或者说多个特征之间的交互关系,因此学者们通过Deep Network来建模更高阶的特征之间的关系。
因此 FM和深度网络DNN的结合也就成为了CTR预估问题中主流的方法。有关FM和DNN的结合有两种主流的方法,并行结构和串行结构。两种结构的理解以及实现如下表所示:
| 结构 | 描述 | 常见模型 |
|---|---|---|
| 并行结构 | FM部分和DNN部分分开计算,只在输出层进行一次融合得到结果 | DeepFM,DCN,Wide&Deep |
| 串行结构 | 将FM的一次项和二次项结果(或其中之一)作为DNN部分的输入,经DNN得到最终结果 | PNN,NFM,AFM |
今天介绍的NFM模型(Neural Factorization Machine),便是串行结构中一种较为简单的网络模型。
2、NFM模型介绍
我们首先来回顾一下FM模型,FM模型用n个隐变量来刻画特征之间的交互关系。这里要强调的一点是,n是特征的总数,是one-hot展开之后的,比如有三组特征,两个连续特征,一个离散特征有5个取值,那么n=7而不是n=3.

顺便回顾一下化简过程:
可以看到,不考虑最外层的求和,我们可以得到一个K维的向量。
对于NFM模型,目标值的预测公式变为:

其中,f(x)是用来建模特征之间交互关系的多层前馈神经网络模块,架构图如下所示:

Embedding Layer和我们之间几个网络是一样的,embedding 得到的vector其实就是我们在FM中要学习的隐变量v。
Bi-Interaction Layer名字挺高大上的,其实它就是计算FM中的二次项的过程,因此得到的向量维度就是我们的Embedding的维度。最终的结果是:

Hidden Layers就是我们的DNN部分,将Bi-Interaction Layer得到的结果接入多层的神经网络进行训练,从而捕捉到特征之间复杂的非线性关系。
在进行多层训练之后,将最后一层的输出求和同时加上一次项和偏置项,就得到了我们的预测输出:

是不是很简单呢,哈哈。
AFM模型理论和实践
1、引言
在CTR预估中,为了解决稀疏特征的问题,学者们提出了FM模型来建模特征之间的交互关系。但是FM模型只能表达特征之间两两组合之间的关系,无法建模两个特征之间深层次的关系或者说多个特征之间的交互关系,因此学者们通过Deep Network来建模更高阶的特征之间的关系。
因此 FM和深度网络DNN的结合也就成为了CTR预估问题中主流的方法。有关FM和DNN的结合有两种主流的方法,并行结构和串行结构。两种结构的理解以及实现如下表所示:
| 结构 | 描述 | 常见模型 |
|---|---|---|
| 并行结构 | FM部分和DNN部分分开计算,只在输出层进行一次融合得到结果 | DeepFM,DCN,Wide&Deep |
| 串行结构 | 将FM的一次项和二次项结果(或其中之一)作为DNN部分的输入,经DNN得到最终结果 | PNN,NFM,AFM |
今天介绍的AFM模型(Attentional Factorization Machine),便是串行结构中一种网络模型。
2、AFM模型介绍
我们首先来回顾一下FM模型,FM模型用n个隐变量来刻画特征之间的交互关系。这里要强调的一点是,n是特征的总数,是one-hot展开之后的,比如有三组特征,两个连续特征,一个离散特征有5个取值,那么n=7而不是n=3.
顺便回顾一下化简过程:
可以看到,不考虑最外层的求和,我们可以得到一个K维的向量。
不难发现,在进行预测时,FM会让一个特征固定一个特定的向量,当这个特征与其他特征做交叉时,都是用同样的向量去做计算。这个是很不合理的,因为不同的特征之间的交叉,重要程度是不一样的。如何体现这种重要程度,之前介绍的FFM模型是一个方案。另外,结合了attention机制的AFM模型,也是一种解决方案。
关于什么是attention model?本文不打算详细赘述,我们这里只需要知道的是,attention机制相当于一个加权平均,attention的值就是其中权重,判断不同特征之间交互的重要性。
刚才提到了,attention相等于加权的过程,因此我们的预测公式变为:

圆圈中有个点的符号代表的含义是element-wise product,即:

因此,我们在求和之后得到的是一个K维的向量,还需要跟一个向量p相乘,得到一个具体的数值。
可以看到,AFM的前两部分和FM相同,后面的一项经由如下的网络得到:

图中的前三部分:sparse iput,embedding layer,pair-wise interaction layer,都和FM是一样的。而后面的两部分,则是AFM的创新所在,也就是我们的Attention net。Attention背后的数学公式如下:

总结一下,不难看出AFM只是在FM的基础上添加了attention的机制,但是实际上,由于最后的加权累加,二次项并没有进行更深的网络去学习非线性交叉特征,所以AFM并没有发挥出DNN的优势,也许结合DNN可以达到更好的结果。
一、引言
二、Model Feature Interaction
2.1 介绍
2.2 FM
2.2.1 优点
2.2.2 缺点
2.3 Deep Neural Network
2.3.1 DNN优化困难
三、Neural Factorization Machine(NFM)
3.1 NFM模型
3.1.1 Embedding Layer
3.1.2 Bi-Interaction Layer
3.1.3 Hidden Layer
3.3.4 Prediction Layer
3.2 NFM vs Wide&Deep、DeepCross
3.3 复杂度分析
3.4 训练
3.4.1 目标函数
3.4.2 参数估计
3.4.3 Dropout
3.4.4 Batch Normalization
四、实验结果分析
4.1 数据集
4.2 实验结果
五、总结
六、代码实战
Reference
计算广告CTR预估系列往期回顾
一、引言
NFM全称Neural Factorization Machine,它用来解决的问题是Sparse Prediction。也就是说,当模型输入特别稀疏而且特征组合对于预测结果非常重要的时候,就可以考虑是用NFM模型。像CTR预估、推荐系统都属于这类问题。另外,公众号整个系列里介绍的模型都是用来处理这样的输入数据的,所以大家要时刻注意各个模型的适用场景、侧重点以及优缺点,活学活用。
一直关注公众号的同学可能已经听烦了,每篇文章开头都是在介绍模型输入特征。针对Sparse Prediction最开始有了FM来对低阶的二阶特征组合建模,后来又引入了DNN来对高阶的非线性组合特征建模,比如Wide&Deep(Google)、DeepCross(微软)、DeepFM(华为+哈工大)、DIN(阿里)、PNN(上交)。当然,还有通过不是DNN的其他方法来对非线性高阶组合特征建模的,比如LR+GBDT(Facebook)、MLR(阿里)。
NFM也是用FM+DNN来对问题建模的,相比于上面提到的这些DNN模型,NFM的特别之处在哪那?
NFM相比于上面提到的DNN模型,模型结构更浅、更简单(
shallower structure),但是性能更好,训练和调整参数更加容易。上面提到的所有模型,都可以在公众号的历史文章中找到!主页君倾尽心血针对模型使用场景、提出背景、侧重问题特点、模型优缺点以及代码实践进行了总结整理。特别有料!
二、Model Feature Interaction
2.1 介绍
这么多类别特征,特征组合也是非常多的。传统的做法是通过人工特征工程或者利用决策树来进行特征选择,选择出比较重要的特征。但是这样的做法都有一个缺点,就是:无法学习训练集中没有出现的特征组合。
最近几年,Embedding-based方法开始成为主流,通过把高维稀疏的输入embed到低维度的稠密的隐向量空间中,模型可以学习到训练集中没有出现过的特征组合。
Embedding-based大致可以分为两类:
-
factorization machine-based linear models
-
neural network-based non-linear models
下面分别简单介绍下
2.2 FM
FM全称Factorization Machine通过隐向量内积来对每一对特征组合进行建模。形式化为:
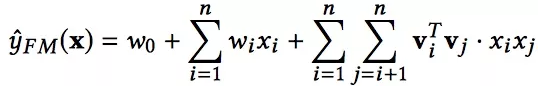
FM公式
w0是全局偏置;wi是单特征的权重;vi vj代表特征xi xj的隐向量。xi表示一个小特征,原始的类别型特征经过one-hot得到二值特征。比如gender经过one-hot之后,gender=male是一个xi, gender=female是另一个xi。
2.2.1 优点
FM很好的解决了高纬度高稀疏输入特征组合的问题。通过隐向量内积来建模权重,针对在训练集中没有出现过的特征组合或者出现次数很好的特征组合,也能有效的学习。
2.2.2 缺点
FM的缺点就是它毕竟还是属于线性模型,它的表达能力受限,而且它只能对二阶组合特征进行建模。
解释下什么是线性模型:
待预测的target是输入参数的线性组合。
形式化如下:
假设输入参数为![]() ,待预测target为y,那么有
,待预测target为y,那么有![]() ,其中g h是theta无关的表达式。
,其中g h是theta无关的表达式。
NFM针对FM的缺点,在二阶特征组合的隐向量空间中,引入了非线性变换来提升模型非线性表达能力;同时,也可以学习到高阶的组合特征。
2.3 Deep Neural Network
DNN模型已经在计算机视觉、自然语言处理、语音识别领域取得成功。但是DNN在IR(信息检索)领域的应用并不是很多。原因是IR中的输入太稀疏了。而(1)DNN如果处理稀疏数据研究的并不多;(2)稀疏数据如何在DNN中处理特征组合也不是很清楚。
但是,最近业内也开始了各种尝试。比如Google的Wide&Deep,微软的DeepCross,以及FNN、PNN等。Wide&Deep的Deep部分是一个MLP,输入是把特征Embedding vector拼接起来得到的;DeepCross的区别在于NN部分不是MLP,而是使用了state-of-the-art residual network。
2.3.1 DNN优化困难
虽然多层神经网络已经被证明可以有效的学习高阶特征组合。但是DNN的缺点也很明显:网络优化或者说网络学习比较困难。
业内大部分DNN的架构都是:把特征的嵌入向量简单拼接起来,输入到神经网络中学习。这样简单的拼接嵌入向量,因为缺失了很多组合特征的信息(carry too little information about feature interactions in low level)效果并不好,那么只能寄希望于后面的MLP可以弥补不足。但是为了提高NN的学习能力就需要增加网络层数,复杂的网络结构会收到诸如梯度消失/爆炸、过拟合、degradation等问题的困扰,网络的学习或者优化会非常困难。
解释下degradation problem。概念是Resident Neural Network中作者通过观察提出的,简单说就是:随着网络层数的增加,训练准确率不升反降,非常反常。
为了证明这一点,作者进行了实验:

DNN训练具有挑战
如果不对嵌入层预训练,Wide&Deep和DeepCross的性能比FM还差,而且DeepCross严重过拟合,Wide&Deep遇到了degradation问题。
如果使用FM预训练初始化嵌入层,Wide&Deep和DeepCross性能都提升了,甚至超过了FM。Wide&Deep的degradation问题也解决了,因为训练集的性能得到了提升。但是两者依旧都有过拟合的问题。实验说明DNN的训练学习真的存在困难。
NFM摒弃了直接把嵌入向量拼接输入到神经网络的做法,在嵌入层之后增加了Bi-Interaction操作来对二阶组合特征进行建模。这使得low level的输入表达的信息更加的丰富,极大的提高了后面隐藏层学习高阶非线性组合特征的能力。
三、NFM
3.1 NFM模型
架构图如下:


NFM架构图
NFM可以形式化如下:
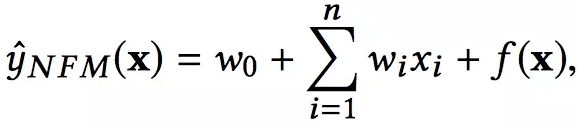
NFM公式
f(x)是NFM的核心,用来学习二阶组合特征和高阶的组合特征模式。
3.1.1 Embedding Layer
和其他的DNN模型处理稀疏输入一样,Embedding将输入转换到低维度的稠密的嵌入空间中进行处理。作者稍微不同的处理是,使用原始的特征值乘以Embedding vector,使得模型也可以处理real valued feature。
3.1.2 Bi-Interaction Layer
Bi是Bi-linear的缩写,这一层其实是一个pooling层操作,它把很多个向量转换成一个向量,形式化如下:
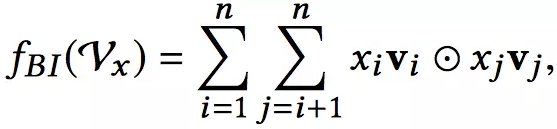
Bi-linear Interaction
fBI的输入是整个的嵌入向量,xi xj是特征取值,vi vj是特征对应的嵌入向量。中间的操作表示对应位置相乘。所以原始的嵌入向量任意两个都进行组合,对应位置相乘结果得到一个新向量;然后把这些新向量相加,就得到了Bi-Interaction的输出。这个输出只有一个向量。
需要说明的是:Bi-Interaction并没有引入额外的参数,而且它的计算复杂度也是线性的,和max/min pooling以及原来的拼接操作复杂度都是相同的。因为上式可以参考FM的优化方法,化简如下(想想一个矩阵):
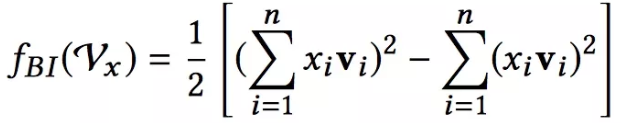
BI化简公式
它的计算复杂度是O(NK)。其中k是嵌入向量的维度,N是输入x中非零特征的个数。这个公式大家要搞懂是怎么回事哦,代码里面就是按照这个来写的。
总结,Bi-Interaction Layer实现了对二阶组合特征的建模,但是又没有引入额外的开销,包括参数数量和计算复杂度。
3.1.3 Hidden Layer
这个跟其他的模型基本一样,堆积隐藏层以期待来学习高阶组合特征。模型结构可以参考Wide&Deep论文的结论,一般选用constant的效果要好一些。
3.3.4 Prediction Layer
最后一层隐藏层zL到输出层最后预测结果形式化如下:
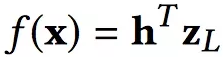
DNN最后的输出
其中h是中间的网络参数。考虑到前面的各层隐藏层权重矩阵,f(x)形式化如下:
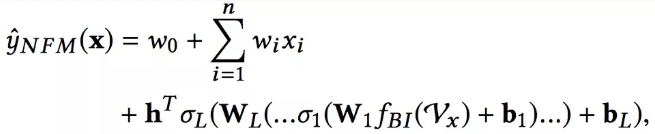
NFM形式化公式
这里的参数为![]() ,相比于FM其实多出的参数就是隐藏层的参数,所以说FM也可以看做是一个神经网络架构,就是去掉隐藏层的NFM。我们把去掉隐藏层的NFM称为NFM-0,形式化如下:
,相比于FM其实多出的参数就是隐藏层的参数,所以说FM也可以看做是一个神经网络架构,就是去掉隐藏层的NFM。我们把去掉隐藏层的NFM称为NFM-0,形式化如下:
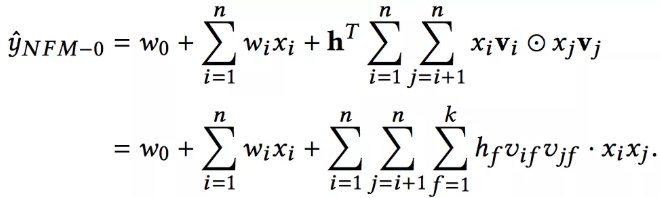
0-Hidden Layer NFM
如果h为全1向量,那么此时NFM就是FM。
这是第一次把FM看做是神经网络来处理,这样的观点对于优化FM提供了一些新的思路。同时,像NN中常用的技巧也可以应用到这里面来,比如Dropout,实验发现在正则化FM的时候,使用Dropout比传统的L2正则化还要有效。
3.2 NFM vs Wide&Deep、DeepCross
如果要求简明扼要说明NFM到底做了什么,就是这一段!
最重要的区别就在于Bi-Interaction Layer。Wide&Deep和DeepCross都是用拼接操作(concatenation)替换了Bi-Interaction。
Concatenation操作的最大缺点就是它并没有考虑任何的特征组合信息,所以就全部依赖后面的MLP去学习特征组合,但是很不幸,MLP的学习优化非常困难。
使用Bi-Interaction考虑到了二阶特征组合,使得输入的表示包含更多的信息,减轻了后面MLP部分的学习压力,所以可以用更简单的模型,取得更好的成绩。
3.3 复杂度分析
上面提到过,NFM相比于FM,复杂度增加在MLP部分。所以NFM的复杂度和Wide&Deep、DeepCross是相同的,形式化如如下:
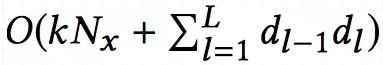
NFM复杂度
3.4 训练
3.4.1 目标函数
NFM可以用于分类、回归、ranking问题,对应着不同的目标函数。
-
回归。square loss
-
分类。Hinge Loss 或 log loss
-
ranking。Contrastive max-margin loss
论文中以回归问题为例,使用square loss,形式化如下。这里并没有正则化项,因为作者发现在NFM中使用Dropout能够得到更好的效果。
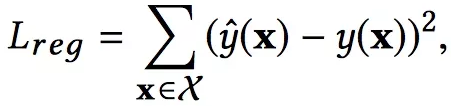
L2正则化
3.4.2 参数估计
使用mini-batch Adagrad来进行参数估计,Adagrad是SGD的变体,特点是每个参数都有自己的学习速率。然后让参数沿着目标函数负梯度的方向进行更新,是下降最快的方向,形式化如下:
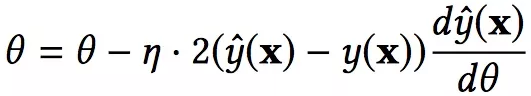
参数学习
这里唯一需要指出的是Bi-Interaction在求梯度时是怎么做的:
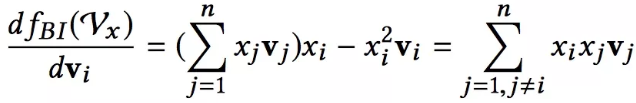
Bi-Interaction导数
所以,NFM的训练依旧可以是端到端的训练,只需要把Bi-Interaction插入到网络中即可。
3.4.3 Dropout
Dropout在训练过程中随机丢掉一些神经元,那么再一次参数更新中也就只会更新部分参数。可以理解成是相当于很多个小的NN取平均值。增加了模型的抗过拟合能力。在NFM中,Bi-Interaction的输出后就增加了Dropout操作,随机的丢弃了一部分的输出。随后的MLP同样应用了Dropout。
需要注意的是,在测试阶段,Dropout是不使用的,所有的神经元都会激活。
3.4.4 Batch Normalization
DNN的训练面临很多问题。其中一个就是协方差偏移(covariance shift),意思就是:由于参数的更新,隐藏层的输入分布不断的在变化,那么模型参数就需要去学习这些变化,这减慢了模型的收敛速度。
Batch Normalization就是为了解决这个问题的,形式化如下:
![]()
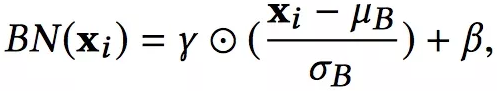
Batch Normalization
对于隐藏层的输入,BN在mini-batch数据上,把输入转换成均值为0,方差为1的高斯分布。其中的gamma、beta是两个超参数,为了扩大模型的表达能力,如果模型发现不应用BN操作更好,那么就可以通过学习这两个参数来消除BN的影响。NFM中Bi-Interaction Layer的输出就是MLP的第一个输出,包括后面所有隐藏层的输入都需要进行Batch Normalization。
注意,在测试预测的时候,BN操作同样有效,这时的均值和方差在整个测试集上来进行计算。
四、实验结果分析
4.1 数据集
使用了两份公开的数据集:
-
Frappe。http://baltrunas.info/research-menu/frappe
-
MovieLens。https://grouplens.org/datasets/movielens/latest/
随机的取70%数据作训练集,20%数据作验证集,10%数据作测试集。
4.2 实验结果
FM相当于是去掉DNN的NFM,论文中给出的数据是只用了一个隐藏层的NFM,相比于FM性能提升了7.3%;NFM只用了一个隐藏层,相比于3个隐藏层的Wide&Deep,和10个隐藏层的DeepCross,NFM用更简单的模型,更少的参数得到了性能的提升。
论文中对比了FM、Wide&Deep模型,效果不用说肯定是NFM最好,这里就不贴图了,感兴趣的小伙伴可以去原论文中查看。此处,只给出一些重要的结论:
-
Dropout在NFM中可以有效的抑制过拟合
-
Batch Normalization在NFM中可以加快训练速度
-
NFM使用一个隐藏层得到了最好的效果
-
如果用FM来pre-train嵌入层,NFM会收敛的非常快,但是NFM最终的效果并没有变好。说明NFM对参数有很好的鲁棒性。
-
模型性能基本上随着Factor的增加而提升。Factor指Embedding向量的维度。
五、总结
NFM主要的特点如下:
-
NFM核心就是在NN中引入了Bilinear Interaction(Bi-Interaction) pooling操作。基于此,NN可以在low level就学习到包含更多信息的组合特征。
-
通过deepen FM来学校高阶的非线性的组合特征
所以,依旧是FM+DNN的组合套路,不同之处在于如何处理Embedding向量,这也是各个模型重点关注的地方。现在来看,如何用DNN来处理高维稀疏的数据并没有一个统一普适的方法,业内依旧在摸索中。
一、简介
二、FM
三、AFM
3.1 模型
3.2 模型训练
3.3 过拟合
四、总结
五、代码实践
Reference
计算广告CTR预估系列往期回顾
一、简介
AFM全称是Attentional Factorization Machine,和NFM是同一个作者。AFM是在FM上的改进,它最大的特点就是使用一个attention network来学习不同组合特征的重要性。
推荐系统或者CTR预估中输入中类别型特征比较多,因为这些类别型特征不是独立的,所以他们的组合特征就显得非常重要。
一个简单的办法就是给每一个组合特征(cross feature)一个权重。但是这种cross feature-based方法的通病就在于训练集中很多组合特征并没有出现,导致无法有效学习。
FM通过为每一个特征学习一个嵌入向量,也叫做隐向量,通过两个隐向量的内积来表示这个组合特征的权重。但是同样有个问题就是,在预测中有一部分特征是不重要甚至是没用的,它们会引入噪声并对预测造成干扰。对于这样的特征,在预测的时候应该赋予一个比较小的权重,但是FM并没有考虑到这一点。对于不同的特征组合,FM并没有区分它们的权重(可以认为内积之后看成一个组合特征,它们的权重都是1)。
本文通过引入Attention机制,创新新的提出了AFM,用来赋予不同的特征组合不同的重要程度。权重可以在网络中自动学习,不需要引入额外的领域知识。更重要的是,AFM可以
二、FM
FM全称是Factorization Machine,形式化公式如下:
![]()
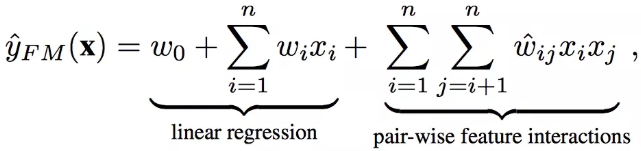
Factorization Machine
其中w是两个特征隐向量v的内积。FM有下面两个问题:
-
一个特征针对其他不同特征都使用同一个隐向量。所以有了FFM用来解决这个问题。
-
所有组合特征的权重w都有着相同的权重1。AFM就是用来解决这个问题的。
在一次预测中,并不是所有的特征都有用的,但是FM对于所有的组合特征都使用相同的权重。AFM就是从这个角度进行优化的,针对不同的特征组合使用不同的权重。这也使得模型更加可解释性,方便后续针对重要的特征组合进行深入研究。
三、AFM
AFM全称是Attentional Factorization Machine。
3.1 模型
AFM的模型结构如下:

AFM模型架构
注意,这里面省去了线性部分,只考虑特征组合部分。
Sparse Input和Embedding Layer和FM中的是相同的,Embedding Layer把输入特征中非零部分特征embed成一个dense vector。下面着重说说剩下的三层。
Pair-wise Interaction Layer:
这一层主要是对组合特征进行建模,原来的m个嵌入向量,通过element-wise product操作得到了m(m-1)/2个组合向量,这些向量的维度都是嵌入向量的维度k。形式化如下:
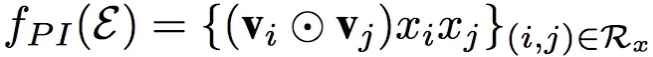
Pair-wise Interaction Layer
也就是Pair-wise Interaction Layer的输入是所有嵌入向量,输出也是一组向量。输出是任意两个嵌入向量的element-wise product。任意两个嵌入向量都组合得到一个Interacted vector,所以m个嵌入向量得到m(m-1)/2个向量。
如果不考虑Attention机制,在Pair-wise Interaction Layer之后直接得到最终输出,我们可以形式化如下:
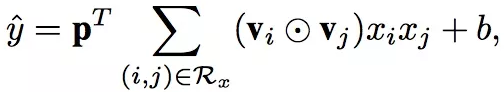
Generalize FM
其中p和b分别是权重矩阵和偏置。当p全为1的时候,我们发现这就是FM。这个只是说明AFM的表达能力是在FM之上的,实际的情况中我们还使用了Attention机制。NFM中的Bilinear Interaction Layer也是把任意两个嵌入向量做element-wise product,然后进行sum pooling操作。
Attention-based Pooling Layer:
Attention机制的核心思想在于:当把不同的部分压缩在一起的时候,让不同的部分的贡献程度不一样。AFM通过在Interacted vector后增加一个weighted sum来实现Attention机制。形式化如下:
![]()
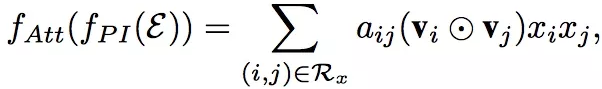
Attention-based Pooling Layer
aij是Attention score,表示不同的组合特征对于最终的预测的贡献程度。可以看到:
-
Attention-based Pooling Layer的输入是Pair-wise Interaction Layer的输出。它包含
m(m-1)/2个向量,每个向量的维度是k。(k是嵌入向量的维度,m是Embedding Layer中嵌入向量的个数) -
Attention-based Pooling Layer的输出是一个k维向量。它对Interacted vector使用Attention score进行了weighted sum pooling操作。
Attention score的学习是一个问题。一个常规的想法就是随着最小化loss来学习,但是这样做对于训练集中从来没有一起出现过的特征组合的Attention score无法学习。
AFM用一个Attention Network来学习。
Attention network实际上是一个one layer MLP,激活函数使用ReLU,网络大小用attention factor表示,就是神经元的个数。
Attention network的输入是两个嵌入向量element-wise product之后的结果(interacted vector,用来在嵌入空间中对组合特征进行编码);它的输出是组合特征对应的Attention score。最后,使用softmax对得到的Attention score进行规范化,Attention Network形式化如下:
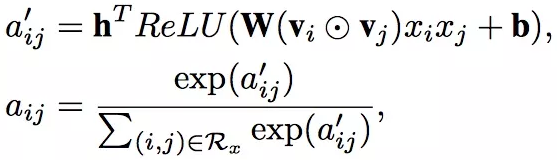
Attention Network
总结,AFM模型总形式化如下:
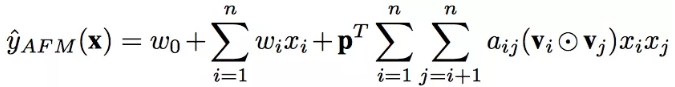
AFM模型总形式化
前面一部分是线性部分;后面一部分对每两个嵌入向量进行element-wise product得到Interacted vector;然后使用Attention机制得到每个组合特征的Attention score,并用这个score来进行weighted sum pooling;最后将这个k维的向量通过权重矩阵p得到最终的预测结果。
3.2 模型训练
AFM针对不同的任务有不同的损失函数。
-
回归问题。square loss。
-
分类问题。log loss。
论文中针对回归问题来讨论,所以使用的是square loss,形式化如下:
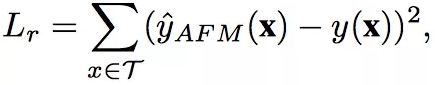
AFM square loss
模型参数估计使用的是SGD。
3.3 过拟合
防止过拟合常用的方法是Dropout或者L2 L1正则化。AFM的做法是:
-
在Pair-wise Interaction Layer的输出使用Dropout
-
在Attention Network中使用L2正则化
Attention Network是一个one layer MLP。不给他使用Dropout是因为,作者发现如果同时在interaction layer和Attention Network中使用Dropout会使得训练不稳定,并且降低性能。
所以,AFM的loss函数更新为:
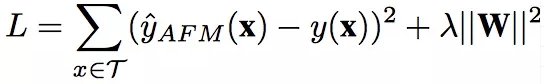
AFM Loss Function
其中W是Attention Network的参数矩阵。
四、总结
AFM是在FM的基础上改进的。相比于其他的DNN模型,比如Wide&Deep,DeepCross都是通过MLP来隐式学习组合特征。这些Deep Methods都缺乏解释性,因为并不知道各个组合特征的情况。相比之下,FM通过两个隐向量内积来学习组合特征,解释性就比较好。
通过直接扩展FM,AFM引入Attention机制来学习不同组合特征的权重,即保证了模型的可解释性又提高了模型性能。但是,DNN的另一个作用是提取高阶组合特征,AFM依旧只考虑了二阶组合特征,这应该算是AFM的一个缺点吧。
DeepFM升级版XDeepFM模型强势来袭!
1、引言
对于预测性的系统来说,特征工程起到了至关重要的作用。特征工程中,挖掘交叉特征是至关重要的。交叉特征指的是两个或多个原始特征之间的交叉组合。例如,在新闻推荐场景中,一个三阶交叉特征为AND(user_organization=msra,item_category=deeplearning,time=monday_morning),它表示当前用户的工作单位为微软亚洲研究院,当前文章的类别是与深度学习相关的,并且推送时间是周一上午。
传统的推荐系统中,挖掘交叉特征主要依靠人工提取,这种做法主要有以下三种缺点:
1)重要的特征都是与应用场景息息相关的,针对每一种应用场景,工程师们都需要首先花费大量时间和精力深入了解数据的规律之后才能设计、提取出高效的高阶交叉特征,因此人力成本高昂;
2)原始数据中往往包含大量稀疏的特征,例如用户和物品的ID,交叉特征的维度空间是原始特征维度的乘积,因此很容易带来维度灾难的问题;
3)人工提取的交叉特征无法泛化到未曾在训练样本中出现过的模式中。
因此自动学习特征间的交互关系是十分有意义的。目前大部分相关的研究工作是基于因子分解机的框架,利用多层全连接神经网络去自动学习特征间的高阶交互关系,例如FNN、PNN和DeepFM等。其缺点是模型学习出的是隐式的交互特征,其形式是未知的、不可控的;同时它们的特征交互是发生在元素级(bit-wise)而不是特征向量之间(vector-wise),这一点违背了因子分解机的初衷。来自Google的团队在KDD 2017 AdKDD&TargetAD研讨会上提出了DCN模型,旨在显式(explicitly)地学习高阶特征交互,其优点是模型非常轻巧高效,但缺点是最终模型的表现形式是一种很特殊的向量扩张,同时特征交互依旧是发生在元素级上。
我们用下图来回顾一下DCN的实现:
下面是我对文中提到的两个重要概念的理解:
bit-wise VS vector-wise
假设隐向量的维度为3维,如果两个特征(对应的向量分别为(a1,b1,c1)和(a2,b2,c2)的话)在进行交互时,交互的形式类似于f(w1 * a1 * a2,w2 * b1 * b2 ,w3 * c1 * c2)的话,此时我们认为特征交互是发生在元素级(bit-wise)上。如果特征交互形式类似于 f(w * (a1 * a2 ,b1 * b2,c1 * c2))的话,那么我们认为特征交互是发生在特征向量级(vector-wise)。
explicitly VS implicitly
显式的特征交互和隐式的特征交互。以两个特征为例xi和xj,在经过一系列变换后,我们可以表示成 wij * (xi * xj)的形式,就可以认为是显式特征交互,否则的话,是隐式的特征交互。
微软亚洲研究院社会计算组提出了一种极深因子分解机模型(xDeepFM),不仅能同时以显式和隐式的方式自动学习高阶的特征交互,使特征交互发生在向量级,还兼具记忆与泛化的学习能力。
我们接下来就来看看xDeepFM这个模型是怎么做的吧!
2、xDeepFM模型介绍
2.1 Compressed Interaction Network
为了实现自动学习显式的高阶特征交互,同时使得交互发生在向量级上,文中首先提出了一种新的名为压缩交互网络(Compressed Interaction Network,简称CIN)的神经模型。在CIN中,隐向量是一个单元对象,因此我们将输入的原特征和神经网络中的隐层都分别组织成一个矩阵,记为X0和Xk。CIN中每一层的神经元都是根据前一层的隐层以及原特征向量推算而来,其计算公式如下:

其中点乘的部分计算如下:

我们来解释一下上面的过程,第k层隐层含有H_k条神经元向量。隐层的计算可以分成两个步骤:(1)根据前一层隐层的状态Xk和原特征矩阵X0,计算出一个中间结果Z^k+1,它是一个三维的张量,如下图所示:

在这个中间结果上,我们用Hk+1个尺寸为m*Hk的卷积核生成下一层隐层的状态,该过程如图2所示。这一操作与计算机视觉中最流行的卷积神经网络大体是一致的,唯一的区别在于卷积核的设计。CIN中一个神经元相关的接受域是垂直于特征维度D的整个平面,而CNN中的接受域是当前神经元周围的局部小范围区域,因此CIN中经过卷积操作得到的特征图(Feature Map)是一个向量,而不是一个矩阵。

如果你觉得原文中的图不够清楚的话,希望下图可以帮助你理解整个过程:

CIN的宏观框架可以总结为下图:

可以看出,它的特点是,最终学习出的特征交互的阶数是由网络的层数决定的,每一层隐层都通过一个池化操作连接到输出层,从而保证了输出单元可以见到不同阶数的特征交互模式。同时不难看出,CIN的结构与循环神经网络RNN是很类似的,即每一层的状态是由前一层隐层的值与一个额外的输入数据计算所得。不同的是,CIN中不同层的参数是不一样的,而在RNN中是相同的;RNN中每次额外的输入数据是不一样的,而CIN中额外的输入数据是固定的,始终是X^0。
可以看到,CIN是通过(vector-wise)来学习特征之间的交互的,还有一个问题,就是它为什么是显式的进行学习?我们先从X1来开始看,X1的第h个神经元向量可以表示成:

进一步,X^2的第h个神经元向量可以表示成:

最后,第k层的第h个神经元向量可以表示成:

因此,我们能够通过上面的式子对特征交互的形式进行一个很好的表示,它是显式的学习特征交叉。
2.2 xDeepFM
将CIN与线性回归单元、全连接神经网络单元组合在一起,得到最终的模型并命名为极深因子分解机xDeepFM,其结构如下图:

集成的CIN和DNN两个模块能够帮助模型同时以显式和隐式的方式学习高阶的特征交互,而集成的线性模块和深度神经模块也让模型兼具记忆与泛化的学习能力。值得一提的是,为了提高模型的通用性,xDeepFM中不同的模块共享相同的输入数据。而在具体的应用场景下,不同的模块也可以接入各自不同的输入数据,例如,线性模块中依旧可以接入很多根据先验知识提取的交叉特征来提高记忆能力,而在CIN或者DNN中,为了减少模型的计算复杂度,可以只导入一部分稀疏的特征子集。
YouTube深度学习推荐系统
1、引言
youtube的视频推荐面临三方面的挑战:
1)Scale:视频和用户数量巨大,很多现有的推荐算法能够在小的数据集上表现得很好,但是在这里效果不佳。需要构建高度专业化的分布式学习算法和高效的服务系统来处理youtube庞大的用户和视频数量。
2)Freshness:体现在视频和用户行为更新频繁。
3)Noise:相较于庞大的视频库,用户的行为是十分稀疏的,同时,我们基本上能获得的都是用户的隐式反馈信号。构造一个强健的系统是十分困难的。
2、Youtube推荐系统整体架构

由于网站视频数量太多,视频候选集太大,不宜用复杂网络直接进行推荐,这会造成响应时间的增加。因此,整个架构走粗排 + 精排两阶段的路子:召回阶段从成百上千万的视频中选择百量级的候选视频;排序阶段完成对几百个候选视频的精排。
3、候选集生成Candidate Generation
候选集生成阶段从巨大的视频库中挑选几百个用户可能感兴趣的候选集。模型的结构如下图所示:

关于该架构,我们从以下几个方面进行讨论:
3.1 输入特征
模型的输入包括用户观看过视频的embedding,用户搜索过token的embedding,用户地理信息embedding,用户的年龄和性别信息。
这里有一个很有意思并且值得我们深思的特征,被称为"Example Age"。我们知道,每一秒中,YouTube都有大量视频被上传,推荐这些最新视频对于YouTube来说是极其重要的。同时,通过观察历史数据发现,用户更倾向于推荐那些尽管相关度不高但是是最新(fresh)的视频。看论文的图片,我们可能认为该特征表示视频被上传之后距现在的时间。但文章其实没有定义这个特征是如何获取到的,应该是训练时间-Sample Log的产生时间。而在线上服务阶段,该特征被赋予0值甚至是一个比较小的负数。这样的做法类似于在广告排序中消除position bias。
假设这样一个视频十天前发布的,许多用户在当前观看了该视频,那么在当天会产生许多Sample Log,而在后面的九天里,观看记录不多,Sample Log也很少。如果我们没有加入Example Age这个特征的话,无论何时训练模型,这个视频对应的分类概率都是差不多的,但是如果我们加入这个特征,模型就会知道,如果这条记录是十天前产生的话,该视频会有很高的分类概率,如果是最近几天产生的话,分类概率应该低一些,这样可以更加逼近实际的数据。实验结果也证明了这一点,参见下图:

对于给定的视频,以example age作为一个特征训练的模型能够准确表示数据中观察到的上传时间和随时间变化的流行度。如果没有该特征,该模型将近似地预测训练窗口的平均可能性。
3.2 样本和上下文选择
在这里,正样本是用户所有完整观看过的视频,其余可以视作负样本。
训练样本是从Youtube所有的用户观看记录里产生的,而并非只是通过推荐系统产生的。同时,针对每一个用户的观看记录,都生成了固定数量的训练样本,这样,每个用户在损失函数中的地位都是相等的,防止一小部分超级活跃用户主导损失函数。
在对待用户的搜索历史或者观看历史时,可以看到Youtube并没有选择时序模型,而是完全摒弃了序列关系,采用求平均的方式对历史记录进行了处理。这是因为考虑时序关系,用户的推荐结果将过多受最近观看或搜索的一个视频的影响。文章中给出一个例子,如果用户刚搜索过“tayer swift”,你就把用户主页的推荐结果大部分变成tayer swift有关的视频,这其实是非常差的体验。为了综合考虑之前多次搜索和观看的信息,YouTube丢掉了时序信息,将用户近期的历史纪录等同看待。但是上述仅是经验之谈,也许类似阿里深度学习演化网络中RNN + Attention的方法,能够取得更好的推荐效果。
最后,在处理测试集的时候,YouTube没有采用经典的随机留一法(random holdout),而是把用户最近的一次观看行为作为测试集,主要是为了避免引入future information,产生与事实不符的数据穿越(避免引入超越特征。)。如下图:

3.3 离线训练
从模型结构可以看出,在离线训练阶段,将其视为了一个分类问题。使用隐式反馈来进行学习,用户完整观看过一个视频,便视作一个正例。如果将视频库中的每一个视频当作一个类别,那么在时刻t,对于用户U和上下文C,用户会观看视频i的概率为:
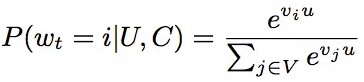
其中,u是用户的embedding,这个embedding,是网络最后一个Relu激活函数的输出,vi是视频i的embedding。那么问题来了,输入时,每一个视频也有一个对应的embedding,这个embedding是不是计算softmax的embedding呢?这里文章也没有说清楚?也许一个视频对应一个embedding,也许一个视频对应两组不同的embedding。
使用多分类问题的一个弊端是,我们有百万级别的classes,模型是非常难以训练的,因此在实际中,Youtube并使用负样本采样(negative sampling)的方法,将class的数量减小。还有一种可以替换的方法,成为hierarchical softmax,但经过尝试,这种方法并没有取得很好的效果。关于上面的两种方法,大家是不是想起了word2vec中训练词向量的两种方式?但是这里的负采样和word2vec中的负采样方法是不同的,这里采样之后还是一个多分类问题,而word2vec中的负采样方法是将问题转为了一个二分类问题。
下图是离线训练的结果,使用的评价指标是MAP(Mean Average Precision),主要考察的两个点是输入特征以及网络层数对于实验效果的影响:

3.4 在线服务
对于在线服务来说,有严格的性能要求,必须在几十毫秒内返回结果。因此,youtube没有重新跑一遍模型,而是通过保存用户的embedding和视频的embedding,通过最近邻搜索的方法得到top N的结果。
从图中可以看到,最终的结果是approx topN的结果,所以并不是直接计算用户embedding和每个视频embedding的内积。如果这样做的话,N个视频的内积计算 + 排序,时间复杂度大概是NlogN,这样很难满足时间复杂度要求。如果使用局部敏感哈希(Locality-Sensitive Hashing, LSH)等近似最近邻快速查找技术,时间复杂度是可以大大降低的。
但文中只是提到说使用hash的方法来得到近似的topN,所以也许不是局部敏感哈希方法,不过如果想要了解一下该方法的原理,可以参考博客:https://www.cnblogs.com/wt869054461/p/8148940.html
4、排序Ranking
排序过程是对生成的候选集做进一步细粒度的排序。模型的结构图如下所示:

4.1 输入特征
在排序阶段,输入的特征主要有:
impression video ID embedding: 当前要计算的video的embedding
watched video IDs average embedding: 用户观看过的最后N个视频embedding的average pooling
language embedding: 用户语言的embedding和当前视频语言的embedding
time since last watch: 用户上次观看同频道时间距现在的时间间隔
previous impressions: 该视频已经被曝光给该用户的次数
第4个特征有一点attention的意思,加入我们刚看了一场NBA比赛的集锦,我们很可能继续观看NBA频道的其他视频,那么这个特征就很好地捕捉到了这一行为。第5个特征一定程度上引入了exploration的思想,避免同一个视频持续对同一用户进行无效曝光。尽量增加用户没看过的新视频的曝光可能性。
4.2 特征处理
特征处理主要包含对于离散变量的处理和连续变量的处理。
对于离散变量,这里主要是视频ID,Youtube这里的做法是有两点:
1、只保留用户最常点击的N个视频的embedding,剩余的长尾视频的embedding被赋予全0值。可能的解释主要有两点,一是出现次数较少视频的embedding没法被充分训练。二是也可以节省线上服务宝贵的内存资源。
2、对于相同域的特征可以共享embedding,比如用户点击过的视频ID,用户观看过的视频ID,用户收藏过的视频ID等等,这些公用一套embedding可以使其更充分的学习,同时减少模型的大小,加速模型的训练。
对于连续特征,主要进行归一化处理,神经网络对于输入的分布及特征的尺度是十分敏感。因此作者设计了一种积分函数将连续特征映射为一个服从[0,1]分布的变量。该积分函数为:![]()
个人理解就是将概率密度分布转换成了累计密度分布。
为了引入特征的非线性,除了加入归一化后的特征外,还加入了该特征的平方和开方值。
4.3 建模期望观看时间
在训练阶段,Youtube没有把问题当作一个CTR预估问题,而是通过weighted logistic 建模了用户的期望观看时间。
在这种情况下,对于正样本,权重是观看时间,而对于负样本,权重是单位权重(可以认为是1),那么,此时,观看时长的几率(odds,在原逻辑回归中,指正例发生的概率与负例发生概率的比值)为:
上式中,Ti指样本中第i条正样本的观看时长,N是所有的训练样本,k是正样本的个数。在k特别小的情况下,上式近似为ET,P是点击率,E[T]是视频的期望观看时长,因为P非常小,那么乘积近似于E[T]。
同时,对于逻辑回归,我们知道几率的计算公式其实就是exp(wx + b),同时几率可以近似于期望观看时长E[T],那么我们在测试阶段,就可以直接输出exp(wx + b),作为期望观看时长。
离线训练的效果如下图:

5、总结
简单讲,YouTube的同学们构建了两级推荐结构从百万级别的视频候选集中进行视频推荐,第一级candidate generation model负责“初筛”,从百万量级的视频库中筛选出几百个候选视频,第二级ranking model负责“精排”,引入更多的feature对几百个候选视频进行排序。
1、文中把推荐问题转换成多分类问题,在next watch的场景下,每一个备选video都会是一个分类,因此总共的分类有数百万之巨,这在使用softmax训练时无疑是低效的,这个问题Youtube是如何解决的?
这个问题原文的回答是这样的
We rely on a technique to sample negative classes from the background distribution ("candidate sampling") and then correct for this sampling via importance weighting.
简单说就是进行了负采样(negative sampling)并用importance weighting的方法对采样进行calibration。文中同样介绍了一种替代方法,hierarchical softmax,但并没有取得更好的效果。
2、在candidate generation model的serving过程中,Youtube为什么不直接采用训练时的model进行预测,而采用一种最近邻搜索的方法?
这个问题的答案是一个经典的工程和学术做trade-off的结果,在model serving过程中对几百万个候选集逐一跑一遍模型的时间开销显然太大了,因此在通过candidate generation model得到user 和 video的embedding之后,通过最近邻搜索的方法的效率高很多。我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。
3、Youtube的用户对新视频有偏好,那么在模型构建的过程中如何引入这个feature?
为了拟合用户对fresh content的bias,模型引入了“Example Age”这个feature,文中其实并没有精确的定义什么是example age。按照文章的说法猜测的话,会直接把sample log距离当前的时间作为example age。比如24小时前的日志,这个example age就是24。在做模型serving的时候,不管使用那个video,会直接把这个feature设成0。大家可以仔细想一下这个做法的细节和动机,非常有意思。
当然我最初的理解是训练中会把Days since Upload作为这个example age,比如虽然是24小时前的log,但是这个video已经上传了90小时了,那这个feature value就是90。那么在做inference的时候,这个feature就不会是0,而是当前时间每个video的上传时间了。
我不能100%确定文章中描述的是那种做法,大概率是第一种。还请大家踊跃讨论。
文章也验证了,example age这个feature能够很好的把视频的freshness的程度对popularity的影响引入模型中。
在引入“Example Age”这个feature后,模型的预测效力更接近经验分布;而不引入Example Age的蓝线,模型在所有时间节点上的预测趋近于平均,这显然是不符合客观实际的。
4、在对训练集的预处理过程中,Youtube没有采用原始的用户日志,而是对每个用户提取等数量的训练样本,这是为什么?
为了减少高度活跃用户对于loss的过度影响。
5、Youtube为什么不采取类似RNN的Sequence model,而是完全摒弃了用户观看历史的时序特征,把用户最近的浏览历史等同看待,这不会损失有效信息吗?
这个原因应该是YouTube工程师的“经验之谈”,如果过多考虑时序的影响,用户的推荐结果将过多受最近观看或搜索的一个视频的影响。YouTube给出一个例子,如果用户刚搜索过“tayer swift”,你就把用户主页的推荐结果大部分变成tayer swift有关的视频,这其实是非常差的体验。为了综合考虑之前多次搜索和观看的信息,YouTube丢掉了时序信息,讲用户近期的历史纪录等同看待。
但RNN到底适不适合next watch这一场景,其实还有待商榷,@严林 大神在上篇文章的评论中已经提到,youtube已经上线了以RNN为基础的推荐模型, 参考论文如下:
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46488.pdf
看来时隔两年,YouTube对于时序信息以及RNN模型有了更多的掌握和利用。
6、在处理测试集的时候,Youtube为什么不采用经典的随机留一法(random holdout),而是一定要把用户最近的一次观看行为作为测试集?
只留最后一次观看行为做测试集主要是为了避免引入future information,产生与事实不符的数据穿越。
7、在确定优化目标的时候,Youtube为什么不采用经典的CTR,或者播放率(Play Rate),而是采用了每次曝光预期播放时间(expected watch time per impression)作为优化目标?
这个问题从模型角度出发,是因为 watch time更能反应用户的真实兴趣,从商业模型角度出发,因为watch time越长,YouTube获得的广告收益越多。而且增加用户的watch time也更符合一个视频网站的长期利益和用户粘性。
这个问题看似很小,实则非常重要,objective的设定应该是一个算法模型的根本性问题,而且是算法模型部门跟其他部门接口性的工作,从这个角度说,YouTube的推荐模型符合其根本的商业模型,非常好的经验。
我之前在领导一个算法小组的时候,是要花大量时间与Business部门沟通Objective的设定问题的,这是路线方针的问题,方向错了是要让组员们很多努力打水漂的,一定要慎之又慎。
8、在进行video embedding的时候,为什么要直接把大量长尾的video直接用0向量代替?
这又是一次工程和算法的trade-off,把大量长尾的video截断掉,主要还是为了节省online serving中宝贵的内存资源。当然从模型角度讲,低频video的embedding的准确性不佳是另一个“截断掉也不那么可惜”的理由。
当然,之前很多同学在评论中也提到简单用0向量代替并不是一个非常好的选择,那么有什么其他方法,大家可以思考一下。
9、针对某些特征,比如#previous impressions,为什么要进行开方和平方处理后,当作三个特征输入模型?
这是很简单有效的工程经验,引入了特征的非线性。从YouTube这篇文章的效果反馈来看,提升了其模型的离线准确度。
10、为什么ranking model不采用经典的logistic regression当作输出层,而是采用了weighted logistic regression?
因为在第7问中,我们已经知道模型采用了expected watch time per impression作为优化目标,所以如果简单使用LR就无法引入正样本的watch time信息。因此采用weighted LR,将watch time作为正样本的weight,在线上serving中使用e(Wx+b)做预测可以直接得到expected watch time的近似,完美。
推荐阅读
1、https://blog.csdn.net/xiongjiezk/article/details/73445835
2、https://zhuanlan.zhihu.com/p/52169807
3、https://zhuanlan.zhihu.com/p/52504407















 1865
1865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









