






 本文介绍了RAG(检索增强生成)技术,一种利用外部知识库提高大模型回答准确性的方法,以及茴香豆的知识构建过程,包括茴香豆架构、部署和实践中的挑战。重点讲述了如何通过茴香豆构建知识库并解决向量数据库配置问题。
本文介绍了RAG(检索增强生成)技术,一种利用外部知识库提高大模型回答准确性的方法,以及茴香豆的知识构建过程,包括茴香豆架构、部署和实践中的挑战。重点讲述了如何通过茴香豆构建知识库并解决向量数据库配置问题。
一、RAG(Retrival Augument Generation)
大模型遇到未知的问题是,可能出现无法回答、幻觉问题,传统方法有更新知识库,但可能会有知识更新太快、语料知识库太大,训练成本高、语料难以收集等问题。RAG就是为了解决这个问题,可以在没有额外训练的情况下帮助大模型处理
(1)RAG是什么
检索增强生成技术,利用外部知识库来
涉及从外部知识源检索信息,让这些信息指导语言模型生成更准确丰富的回答。
RAG可看作一个搜索引擎,将用户输入的内容作为索引,在外部知识库中搜寻相关内容,结合大语言模型的能力生成回答。
实现外部记忆,
(2)RAG的原理
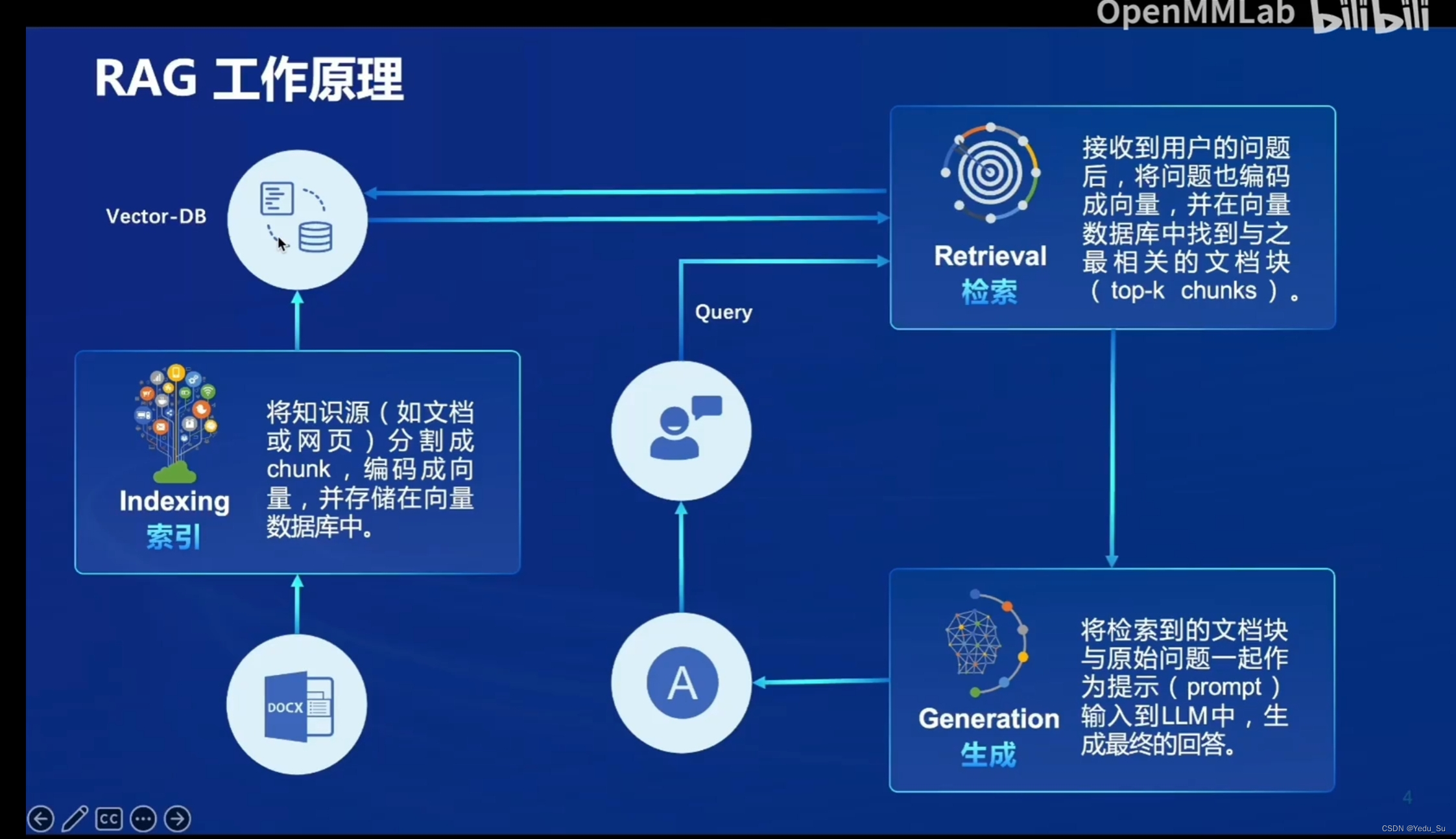
(3)RAG vs. Fine-tune
(4)RAG架构
(5)向量数据库
(6)评估和测试
二、茴香豆
(1)茴香豆介绍
(2)茴香豆的特点
(3)茴香豆架构
(4)构建步骤
三、实践演示
(1)茴香豆Web版演示
打开茴香豆Web版网址:应用中心-OpenXLab
创建一个属于自己的知识库,直接命名并输入密码即可。
按需上传知识库,这里我随便找了一篇脑机接口领域的中文综述文件。
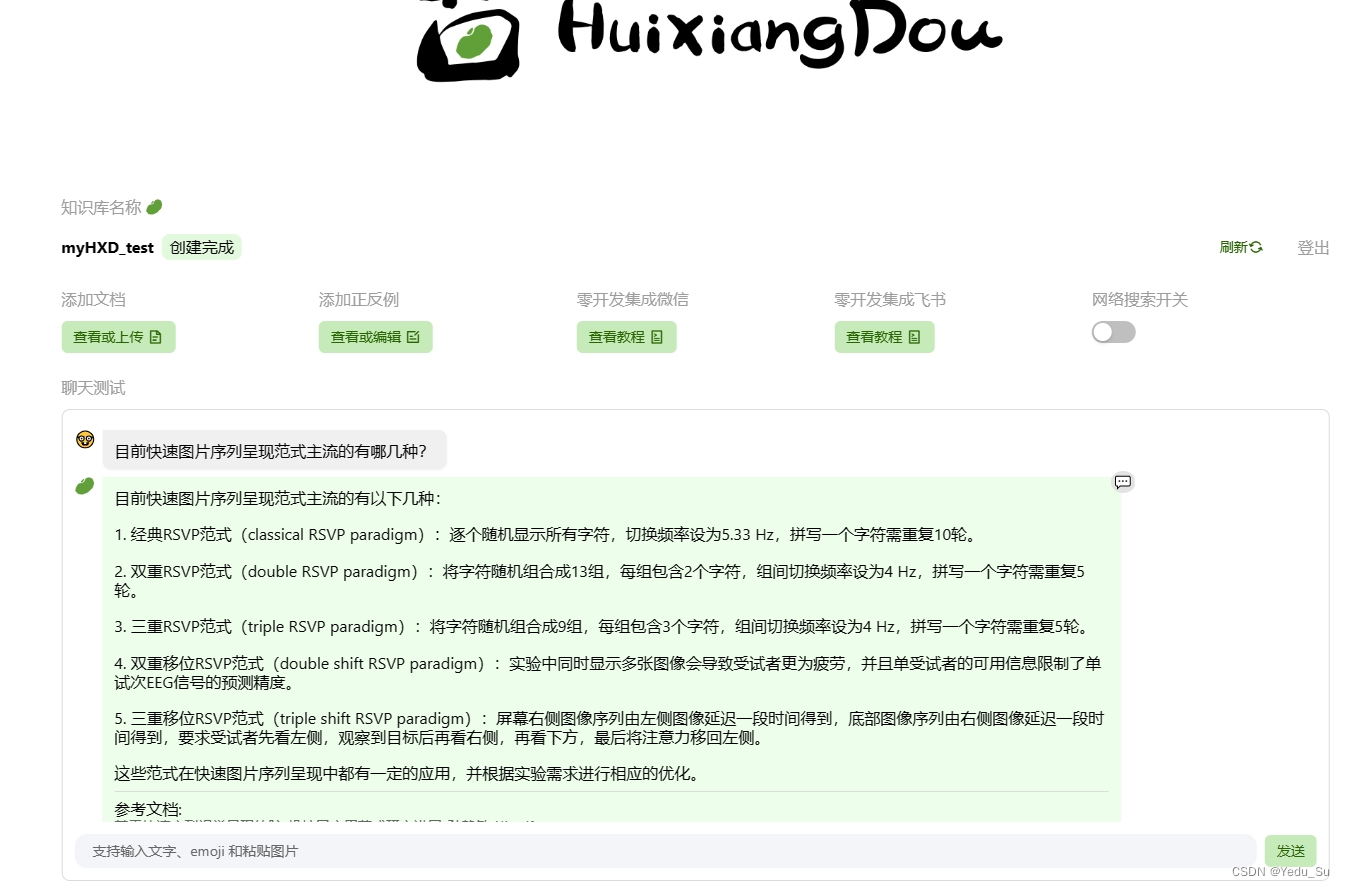
可以看到根据问题,茴香豆从参考文献中构建了回答。
试一试在日常问答中,输入一些茴香豆提前设置好的不回答的问题。

接下来试一试输入反例:
这里我输入的反例不知道是不是输入方式不对,茴香豆回答的有一些问题。之后又试了几种方式,效果也不是很好,可能是我调用的方式不对。




(2)Intern Studio部署茴香豆知识助手
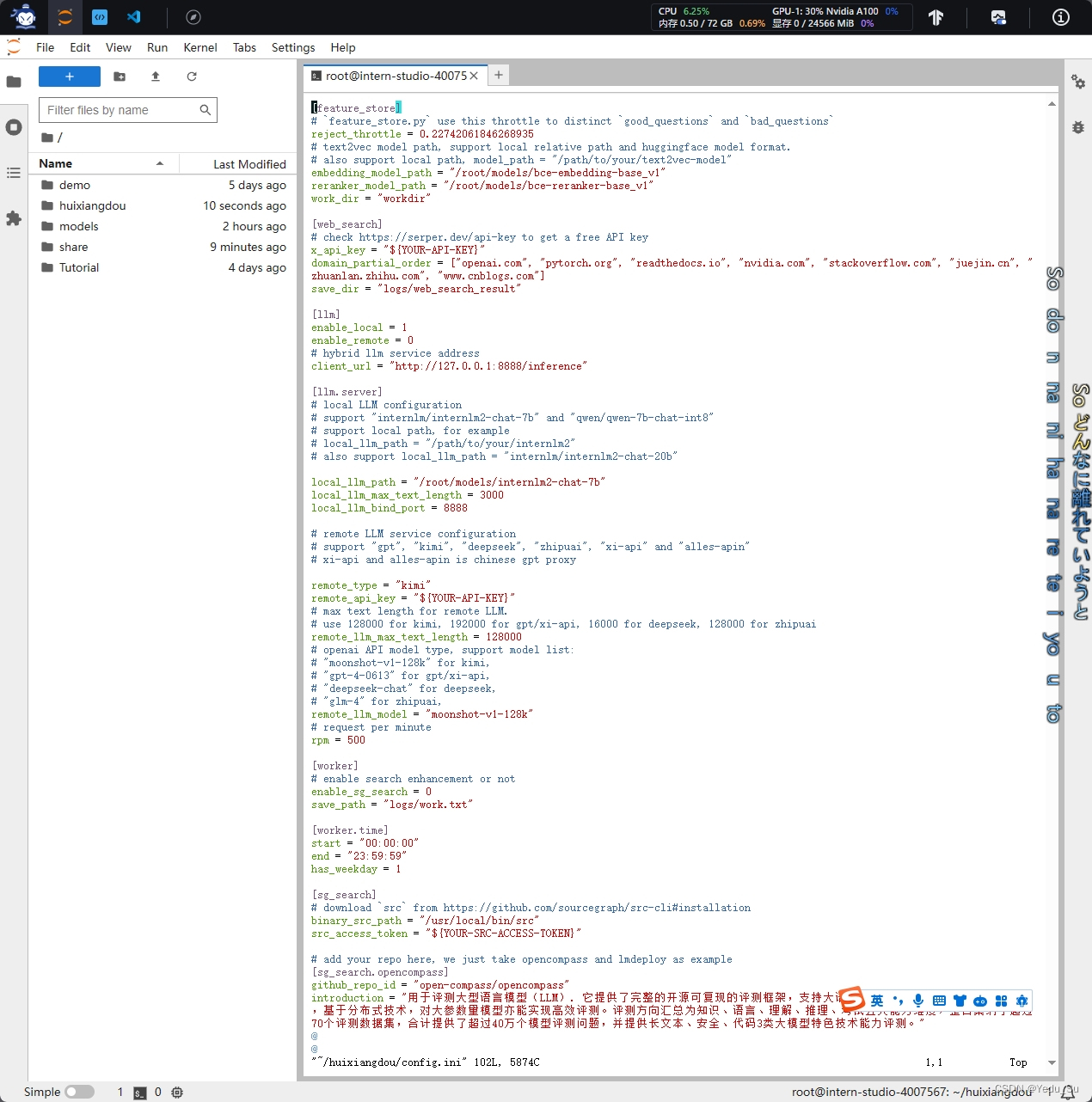
2.1 修改配置文件
用已下载模型的路径替换 /root/huixiangdou/config.ini 文件中的默认模型,需要修改 3 处模型地址,分别是:
命令行输入下面的命令,修改用于向量数据库和词嵌入的模型
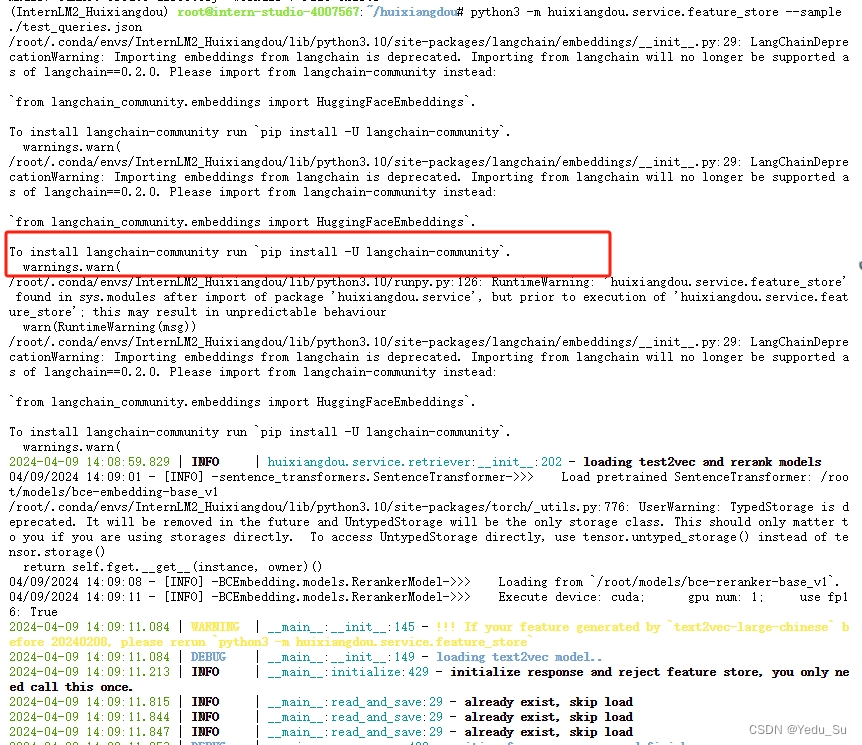
这里有一个坑,出现了断言错误,需要我们手动去把最大长度从1000设置成10000.

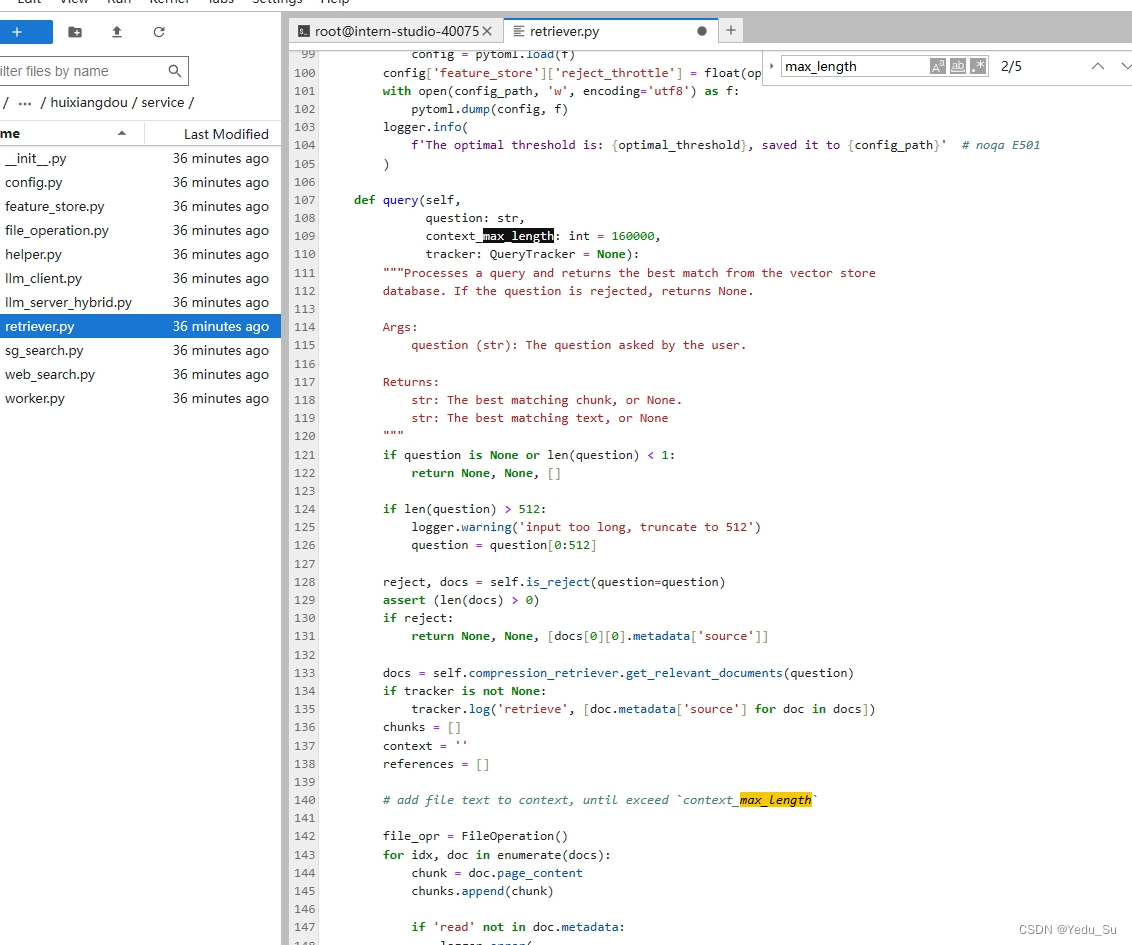
2.2 创建知识库
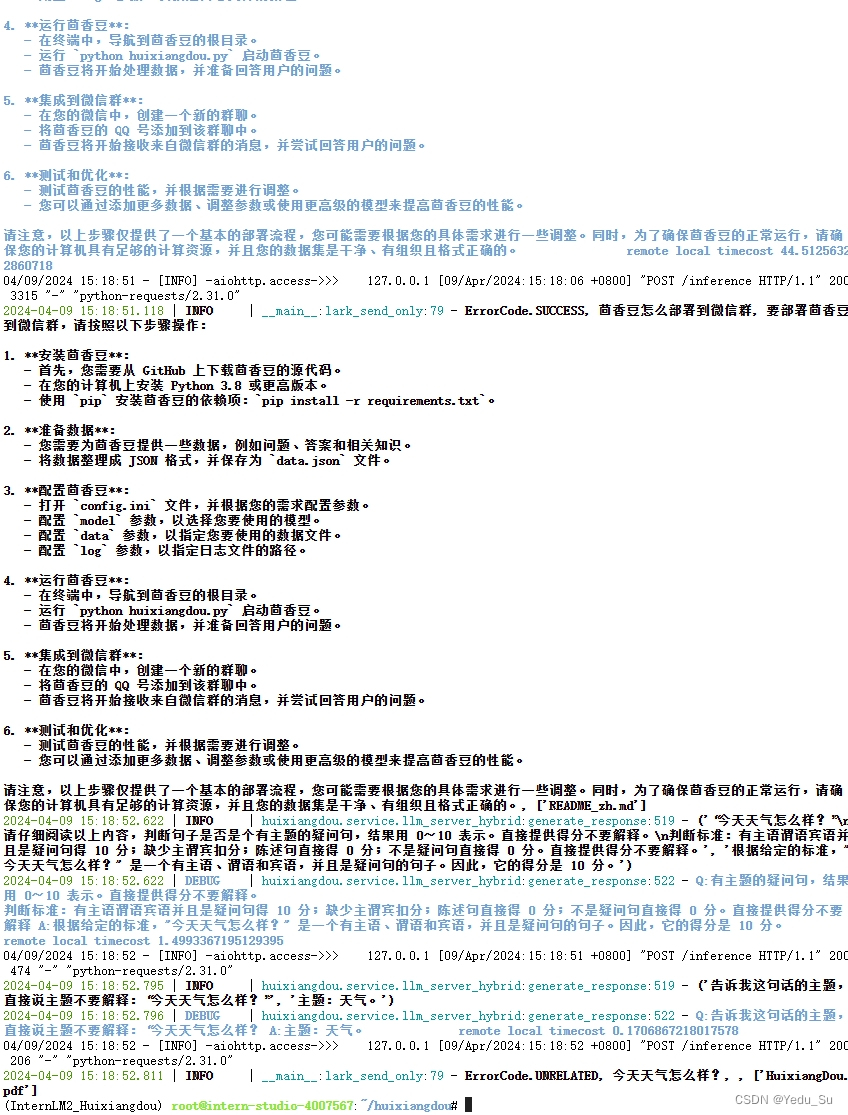
本示例中,使用 InternLM 的 Huixiangdou 文档作为新增知识数据检索来源,在不重新训练的情况下,打造一个 Huixiangdou 技术问答助手。
首先,下载 Huixiangdou 语料:
cd /root/huixiangdou && mkdir repodir git clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou
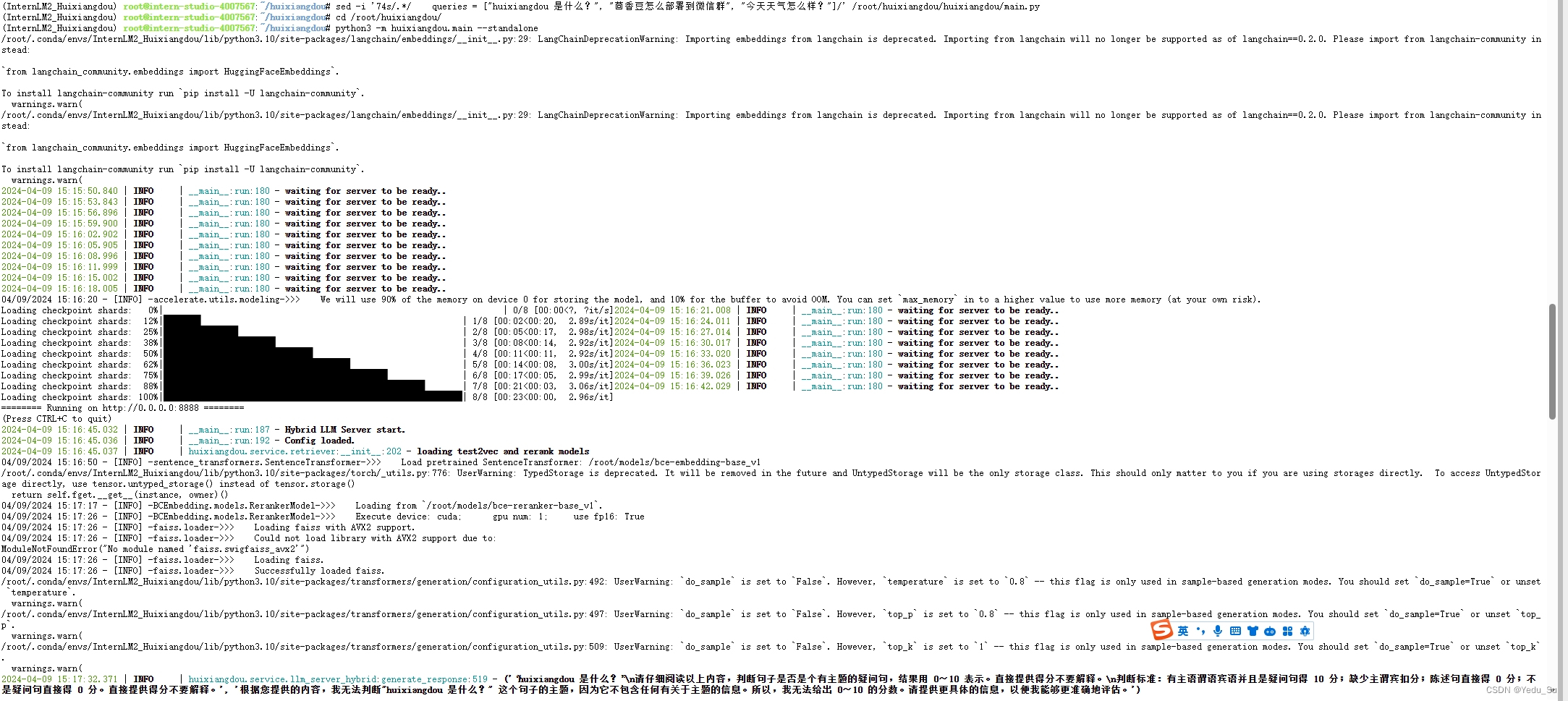
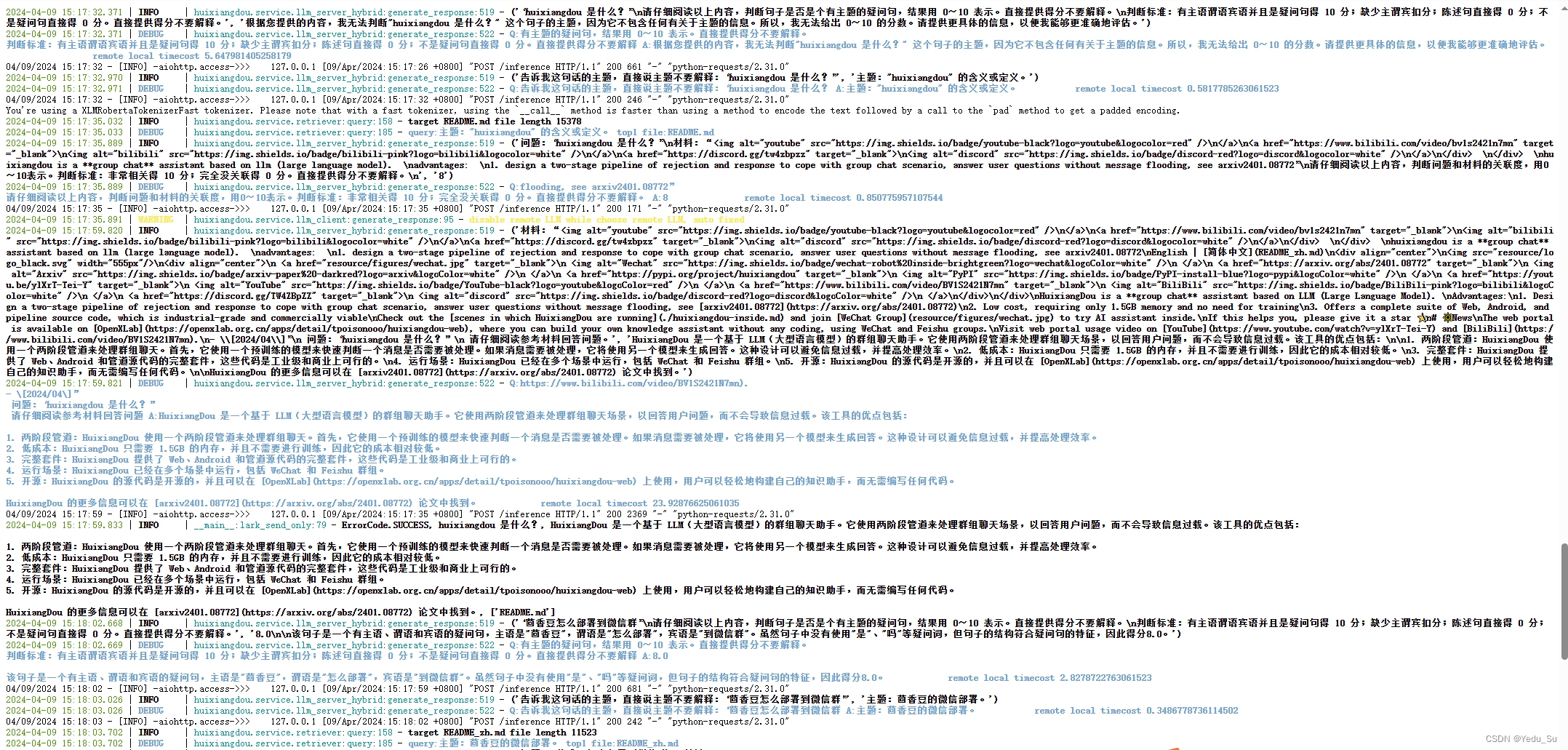
提取知识库特征,创建向量数据库。数据库向量化的过程应用到了 LangChain 的相关模块,默认嵌入和重排序模型调用的网易 BCE 双语模型,如果没有在 config.ini 文件中指定本地模型路径,茴香豆将自动从 HuggingFace 拉取默认模型。
除了语料知识的向量数据库,茴香豆建立接受和拒答两个向量数据库,用来在检索的过程中更加精确的判断提问的相关性,这两个数据库的来源分别是:
- 接受问题列表,希望茴香豆助手回答的示例问题
- 存储在
huixiangdou/resource/good_questions.json中
- 存储在
- 拒绝问题列表,希望茴香豆助手拒答的示例问题
- 存储在
huixiangdou/resource/bad_questions.json中 - 其中多为技术无关的主题或闲聊
- 如:"nihui 是谁", "具体在哪些位置进行修改?", "你是谁?", "1+1"
- 存储在
















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









