







 本文通过多种机器学习和深度学习方法对文本进行分类实验,包括TF-IDF、词向量、CNN、GRU等,并对比了不同模型的效果。
本文通过多种机器学习和深度学习方法对文本进行分类实验,包括TF-IDF、词向量、CNN、GRU等,并对比了不同模型的效果。
文章目录
前言
上篇文本分类实验结果
本篇首发日期:2020-9-27
本篇实验详细结果及代码
本篇python版本:3.7.4
本篇sklearn版本:0.21.3
本篇keras版本:2.3.1
语料
统计
| 类别 | 数量 | 类别 | 数量 |
|---|---|---|---|
| science | 2093 | car | 2066 |
| finance | 2052 | sports | 2017 |
| military | 2007 | medicine | 2000 |
| entertainment | 1906 | politics | 1865 |
| education | 1749 | fashion | 1712 |
待测数据是否已知?
- 实际工作中,待测数据可能已知,也可能未知,其监督学习方法可以有所不同
- 此实验待测数据已知
代码
TFIDF+【贝叶斯、逻辑回归、决策树、随机森林】
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
import jieba, warnings
from segment import tk
from data10 import load_xy
warnings.filterwarnings('ignore') # 不打印警告
DISCARD_FLAG = {'c', 'd', 'e', 'o', 'p', 'r', 'u', 'uv', 'y', 'NUM'} # 词性排除
N = 25000 # 最大词数
def cut1(text):
for word in tk.cut(text):
if tk.get_flag(word) not in DISCARD_FLAG:
yield word
def cut2(text):
words = tk.lcut(text)
for i in range(len(words) - 1):
yield words[i]
yield words[i] + words[i + 1]
yield words[-1]
def cut_flag(text):
for word in tk.cut(text):
flag = tk.get_flag(word)
if tk.get_flag(word) not in DISCARD_FLAG:
yield word
yield flag
def experiment(test_size=.5, random_state=7):
x, (train, test, y_train, y_test) = load_xy(test_size, random_state)
vec_ls = (
CountVectorizer(tokenizer=tk.cut, max_features=N),
CountVectorizer(tokenizer=cut1, max_features=N),
CountVectorizer(tokenizer=cut2, max_features=N),
CountVectorizer(tokenizer=cut_flag, max_features=N),
CountVectorizer(tokenizer=jieba.cut, max_features=N),
TfidfVectorizer(tokenizer=tk.cut, max_features=N),
TfidfVectorizer(tokenizer=cut1, max_features=N),
TfidfVectorizer(tokenizer=cut2, max_features=N),
TfidfVectorizer(tokenizer=cut_flag, max_features=N),
TfidfVectorizer(tokenizer=jieba.cut, max_features=N),
)
clf_ls = (
MultinomialNB(),
LogisticRegression(solver='liblinear'),
DecisionTreeClassifier(),
RandomForestClassifier(),
SVC(kernel='linear'),
)
for x_fit in (train, x):
for vec in vec_ls:
vec.fit(x_fit)
x_train = vec.transform(train)
x_test = vec.transform(test)
for clf in clf_ls:
t0 = tk.second
clf.fit(x_train, y_train)
print(clf.__class__.__name__, tk.second - t0, clf.score(x_test, y_test))
tk.yellow(vec)
experiment()
词向量+TFIDF+【贝叶斯、逻辑回归、决策树、随机森林、SVM】
from gensim.models import Word2Vec
from math import log10
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
import numpy as np, copy, warnings
from segment import tk, clean
from data10 import load_xy
warnings.filterwarnings('ignore') # 不打印警告
DISCARD_FLAG = {'c', 'd', 'e', 'o', 'p', 'r', 'u', 'uv', 'y', 'NUM'}
def cut1(text):
for word in tk.cut(text):
if tk.get_flag(word) not in DISCARD_FLAG:
yield word
class Word2Vector:
def __init__(self, cut, size=75, window=7, min_count=3):
self.size = size
self.window = window
self.min_count = min_count
self.cut = cut
self.wv = None
self.vectors = None
self.w2i = None
def unit_vector(self):
self.vectors = self.vectors / np.linalg.norm(self.vectors, axis=1).reshape(-1, 1)
def idf(self, texts):
texts = [set(self.cut(t)) for t in texts]
lent = len(texts)
self.vectors = self.vectors * np.array(
[[log10(lent / (sum((w in t) for t in texts) + 1))] for w in self.wv.index2word])
def fit(self, texts):
sentences = [list(self.cut(s)) for t in texts for s in clean.text2clause(t)] # 文本切分
wv = Word2Vec(sentences, size=self.size, window=self.window, min_count=self.min_count).wv # 词向量
self.w2i = {w: i for i, w in enumerate(wv.index2word)}
self.vectors = wv.vectors
self.wv = wv
def text2vector(self, texts):
return [[self.vectors[self.w2i[w]] for w in self.cut(t) if w in self.w2i] for t in texts]
def vector_sum(self, texts):
return [np.sum(v, axis=0) if v else np.zeros(self.size) for v in self.text2vector(texts)]
def vector_mean(self, texts):
return [np.mean(v, axis=0) if v else np.zeros(self.size) for v in self.text2vector(texts)]
def experiment(test_size=.5, random_state=7):
x, (train, test, y_train, y_test) = load_xy(test_size, random_state)
vec_ls = (
Word2Vector(tk.cut),
Word2Vector(cut1),
Word2Vector(tk.cut, 150),
Word2Vector(cut1, 150),
)
clf_ls = (
LogisticRegression(solver='liblinear'),
DecisionTreeClassifier(),
RandomForestClassifier(),
SVC(kernel='linear', max_iter=500),
SVC(max_iter=1000),
)
for x_fit in (train, x):
for vec in vec_ls:
vec.fit(x_fit)
# sum
tk.yellow('*****sum')
x_train, x_test = vec.vector_sum(train), vec.vector_sum(test)
for clf in clf_ls:
t0 = tk.second
clf.fit(x_train, y_train)
print(clf.__class__.__name__, tk.second - t0, clf.score(x_test, y_test))
# mean
tk.yellow('*****mean')
x_train, x_test = vec.vector_mean(train), vec.vector_mean(test)
for clf in clf_ls:
t0 = tk.second
clf.fit(x_train, y_train)
print(clf.__class__.__name__, tk.second - t0, clf.score(x_test, y_test))
# sum unit_vector
tk.yellow('*****sum unit_vector')
vec1 = copy.deepcopy(vec)
vec1.unit_vector()
x_train, x_test = vec1.vector_sum(train), vec1.vector_sum(test)
for clf in clf_ls:
t0 = tk.second
clf.fit(x_train, y_train)
print(clf.__class__.__name__, tk.second - t0, clf.score(x_test, y_test))
# mean unit_vector
tk.yellow('*****mean unit_vector')
x_train, x_test = vec1.vector_mean(train), vec1.vector_mean(test)
for clf in clf_ls:
t0 = tk.second
clf.fit(x_train, y_train)
print(clf.__class__.__name__, tk.second - t0, clf.score(x_test, y_test))
del vec1
# sum idf
tk.yellow('*****sum idf')
vec.idf(x_fit)
x_train, x_test = vec.vector_sum(train), vec.vector_sum(test)
for clf in clf_ls:
t0 = tk.second
clf.fit(x_train, y_train)
print(clf.__class__.__name__, tk.second - t0, clf.score(x_test, y_test))
# mean idf
tk.yellow('*****mean idf')
x_train, x_test = vec.vector_mean(train), vec.vector_mean(test)
for clf in clf_ls:
t0 = tk.second
clf.fit(x_train, y_train)
print(clf.__class__.__name__, tk.second - t0, clf.score(x_test, y_test))
experiment()
CNN、GRU、LSTM、双向GRU、双向LSTM
from keras.utils import to_categorical
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense, LSTM, GRU, Bidirectional, Conv1D, MaxPool1D, GlobalMaxPool1D, Embedding
from keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
import collections, warnings
from segment import tk, clean
from data10 import load_xy
warnings.filterwarnings('ignore')
"""配置"""
N = 25000 # 最大词数
input_dim = N + 1 # 词库大小
output_dim = 150 # 词嵌入维度
kernel_size = 7 # 卷积核大小
units = filters = 64 # RNN神经元数量、卷积滤波器数量
maxlen = 200 # 序列长度
batch_size = 128 # 每批数据量大小
epochs = 999 # 训练最大轮数
verbose = 2 # 训练过程展示
patience = 1 # 没有进步的训练轮数
callbacks = [EarlyStopping('val_acc', patience=patience)]
DISCARD_FLAG = {'c', 'd', 'e', 'o', 'p', 'r', 'u', 'uv', 'y', 'NUM'}
C = ['science', 'car', 'finance', 'sports', 'military', 'medicine', 'entertainment', 'politics', 'education', 'fashion']
num_classes = len(C)
def cut1(text):
for clause in clean.SEP45(text):
for word in tk.cut(clause):
if tk.get_flag(word) not in DISCARD_FLAG:
yield word
"""读数据"""
x, (x1, x2, y1, y2) = load_xy()
y1 = to_categorical([C.index(i) for i in y1], num_classes)
y2 = to_categorical([C.index(i) for i in y2], num_classes)
# 词编码
w2i = {wf[0]: e for e, wf in enumerate(collections.Counter(w for t in x for w in cut1(t)).most_common(N), 1)}
# pad
x1 = pad_sequences([[w2i[w] for w in cut1(t) if w in w2i] for t in x1], maxlen, dtype='float')
x2 = pad_sequences([[w2i[w] for w in cut1(t) if w in w2i] for t in x2], maxlen, dtype='float')
# 验证集切分
validation_size = .1
x11, x12, y11, y12 = train_test_split(x1, y1, test_size=validation_size)
def experiment():
for layer, layer_name in (
(LSTM(units), 'LSTM'),
(GRU(units), 'GRU'),
(Bidirectional(LSTM(units)), 'BiLSTM'),
(Bidirectional(GRU(units)), 'BiGRU'),
):
tk.cyan(layer_name)
# 建模
model = Sequential()
model.add(Embedding(input_dim, output_dim, input_length=maxlen, input_shape=(maxlen,)))
model.add(layer)
model.add(Dense(units=num_classes, activation='softmax'))
model.compile('adam', 'categorical_crossentropy', ['acc'])
# 训练、预测
history = model.fit(x11, y11, batch_size, epochs, verbose, callbacks, validation_data=(x12, y12))
e = len(history.history['acc'])
print(model.evaluate(x2, y2, batch_size, verbose), e)
# 验证集加入训练、预测
model.fit(x12, y12, batch_size, int(e * validation_size) + 1, verbose, callbacks)
tk.yellow(model.evaluate(x2, y2, batch_size, verbose))
# CNN
tk.cyan('CNN')
model = Sequential()
model.add(Embedding(input_dim, output_dim, input_length=maxlen, input_shape=(maxlen,)))
model.add(Conv1D(units, kernel_size * 2, padding='same', activation='relu'))
model.add(MaxPool1D(pool_size=2)) # strides默认等于pool_size
model.add(Conv1D(units * 2, kernel_size, padding='same', activation='relu'))
model.add(GlobalMaxPool1D()) # 对于时序数据的全局最大池化
model.add(Dense(num_classes, activation='softmax'))
model.compile('adam', 'categorical_crossentropy', ['acc'])
# 训练、预测
history = model.fit(x11, y11, batch_size, epochs, verbose, callbacks, validation_data=(x12, y12))
e = len(history.history['acc'])
print(model.evaluate(x2, y2, batch_size, verbose), e)
# 验证集加入训练、预测
model.fit(x12, y12, batch_size, int(e * validation_size) + 1, verbose, callbacks)
tk.yellow(model.evaluate(x2, y2, batch_size, verbose))
experiment()
词向量+【CNN、GRU、LSTM、双向GRU、双向LSTM】
from gensim.models import Word2Vec
from keras.utils import to_categorical
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense, LSTM, GRU, Bidirectional, Conv1D, MaxPool1D, GlobalMaxPool1D
from keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
import numpy as np, warnings
from math import log10
from segment import tk, clean
from data10 import load_xy
warnings.filterwarnings('ignore')
"""配置"""
size = 150 # 词向量维度
window = kernel_size = 7 # 词窗、卷积核大小
units = filters = 64 # RNN神经元数量、卷积滤波器数量
maxlen = 200 # 序列长度
batch_size = 128 # 每批数据量大小
epochs = 999 # 训练最大轮数
verbose = 2 # 训练过程展示
patience = 1 # 没有进步的训练轮数
callbacks = [EarlyStopping('val_acc', patience=patience)]
DISCARD_FLAG = {'c', 'd', 'e', 'o', 'p', 'r', 'u', 'uv', 'y', 'NUM'}
C = ['science', 'car', 'finance', 'sports', 'military', 'medicine', 'entertainment', 'politics', 'education', 'fashion']
num_classes = len(C)
def cut1(text):
for word in tk.cut(text):
if tk.get_flag(word) not in DISCARD_FLAG:
yield word
"""读数据"""
x, (x1, x2, y1, y2) = load_xy()
y1 = to_categorical([C.index(i) for i in y1], num_classes)
y2 = to_categorical([C.index(i) for i in y2], num_classes)
"""词向量"""
sentences = [list(cut1(s)) for t in x for s in clean.text2clause(t)] # 文本切分
wv = Word2Vec(sentences, size=size, window=window, min_count=3, sg=1).wv
vectors = wv.vectors
texts = [set(cut1(t)) for t in x]
lent = len(texts)
vectors = vectors * np.array([[log10(lent / (sum((w in t) for t in texts) + 1))] for w in wv.index2word]) # idf
w2i = {w: i for i, w in enumerate(wv.index2word)}
# pad
x1 = pad_sequences([[vectors[w2i[w]] for w in cut1(t) if w in w2i] for t in x1], maxlen, dtype='float')
x2 = pad_sequences([[vectors[w2i[w]] for w in cut1(t) if w in w2i] for t in x2], maxlen, dtype='float')
# 验证集切分
validation_size = .1
x11, x12, y11, y12 = train_test_split(x1, y1, test_size=validation_size)
def experiment():
for layer, layer_name in (
(LSTM(units), 'LSTM'),
(GRU(units), 'GRU'),
(Bidirectional(LSTM(units), input_shape=(maxlen, size)), 'BiLSTM'),
(Bidirectional(GRU(units), input_shape=(maxlen, size)), 'BiGRU'),
):
tk.cyan(layer_name)
# 建模
model = Sequential()
model.add(layer)
model.add(Dense(units=num_classes, activation='softmax'))
model.compile('adam', 'categorical_crossentropy', ['acc'])
# 训练、预测
history = model.fit(x11, y11, batch_size, epochs, verbose, callbacks, validation_data=(x12, y12))
e = len(history.history['acc'])
print(model.evaluate(x2, y2, batch_size, verbose), e)
# 验证集加入训练、预测
model.fit(x12, y12, batch_size, int(e * validation_size) + 1, verbose, callbacks)
tk.yellow(model.evaluate(x2, y2, batch_size, verbose))
# CNN
tk.cyan('CNN')
model = Sequential()
model.add(Conv1D(units, kernel_size * 2, padding='same', activation='relu'))
model.add(MaxPool1D(pool_size=2)) # strides默认等于pool_size
model.add(Conv1D(units * 2, kernel_size, padding='same', activation='relu'))
model.add(GlobalMaxPool1D()) # 对于时序数据的全局最大池化
model.add(Dense(num_classes, activation='softmax'))
model.compile('adam', 'categorical_crossentropy', ['acc'])
# 训练、预测
history = model.fit(x11, y11, batch_size, epochs, verbose, callbacks, validation_data=(x12, y12))
tk.yellow(model.evaluate(x2, y2, batch_size, verbose))
# 验证集加入训练、预测
model.fit(x12, y12, batch_size, len(history.history['acc']) - 1, verbose, callbacks)
tk.yellow(model.evaluate(x2, y2, batch_size, verbose))
experiment()
无监督
词向量+预设规则
from gensim.models import Word2Vec
from collections import Counter
from segment import tk, clean
DISCARD_FLAG = {'c', 'd', 'e', 'o', 'p', 'r', 'u', 'uv', 'y', 'NUM'} # 词性排除
THRESHOLD = .5
def cut(text):
for word in tk.cut(text):
if tk.get_flag(word) not in DISCARD_FLAG:
yield word
def texts2sentences(texts):
return [list(cut(s)) for t in texts for s in clean.text2clause(t)]
class Model:
def __init__(self, texts, keywords, themes):
# 加入词库
for word in keywords:
tk.add_word(word)
# 训练词向量
self.wv = Word2Vec(texts2sentences(texts), window=11, sg=1).wv
# 词库扩展
self.dt = {w: {w: 1} for w in keywords}
for word in keywords:
for w, s in self.wv.similar_by_word(word, 99):
if s < THRESHOLD:
break
self.dt[w] = dict({word: s ** 2}, **self.dt.get(w, dict()))
print(self.dt)
self.themes = themes
def ner(self, text):
# 抽取扩展后的关键词
c1 = Counter(w for w in cut(text) if w in self.dt)
# 扩展后的关键词映射到原关键词
c2 = Counter()
for k1, v1 in c1.items():
for k2, v2 in self.dt[k1].items():
c2[k2] += v1 * v2
return c2.most_common()
def extract_theme(self, text):
themes = Counter()
for w, f in self.ner(text):
themes[self.themes[w]] += f
return themes and themes.most_common()[0][0]
# 读数据
from pandas import read_excel
ay = read_excel('data10/data10.xlsx').values
x, y = ay[:, 0], ay[:, 1]
WORDS = {
'车': 'car', '车型': 'car', '汽车': 'car',
'教育': 'education', '学生': 'education', '学校': 'education', '考生': 'education',
'娱乐': 'entertainment', '观众': 'entertainment', '饰演': 'entertainment', '演员': 'entertainment',
'电影': 'entertainment', '角色': 'entertainment', '影片': 'entertainment', '导演': 'entertainment',
'肌肤': 'fashion', '时尚': 'fashion', '搭配': 'fashion', '穿': 'fashion', '裙': 'fashion',
'珠宝': 'fashion', '装修': 'fashion', '保湿': 'fashion', '时髦': 'fashion', '面膜': 'fashion', '香水': '时尚',
'比赛': 'sports', '球队': 'sports', '队': 'sports', '球员': 'sports', '体育': 'sports', '赛季': 'sports',
'症状': 'medicine', '治疗': 'medicine', '临床': 'medicine',
'疾病': 'medicine', '患者': 'medicine', '综合征': 'medicine',
'科技': 'science', '研究': 'science', 'iPhone': 'science', '手机': 'science',
}
# 算法
model = Model(x, WORDS.keys(), WORDS)
y_predict = [model.ner(i) for i in x]
print(sum(y == y_predict) / len(y))
while True:
try:
x = x[int(input('输入数字').strip())]
print(x, '\n\033[033m{}\033[0m'.format(model.ner(x)))
except:
pass
主题模型
LDA是垃圾
LDA是垃圾
LDA是垃圾
LDA是垃圾
LDA是垃圾
LDA是垃圾
LDA是垃圾
主题模型是垃圾
主题模型是垃圾
主题模型是垃圾
主题模型是垃圾
主题模型是垃圾
主题模型是垃圾
主题模型是垃圾
主题模型是垃圾
from gensim import corpora, models
from segment import tk, clean
import numpy as np
DISCARD_FLAG = {'a', 'ad', 'c', 'd', 'e', 'f', 'i', 'l', 'nb', 'm', 'o', 'p', 'r', 'u', 'uv', 'y', 'NUM', 'NA'}
def cut(text):
for clause in clean.text2clause(text):
for word in tk.cut(clause):
if (tk.get_flag(word) not in DISCARD_FLAG) and (len(word) > 1):
yield word
def experiment(texts, themes):
words_ls = [list(cut(t)) for t in texts]
# 构造词典
dictionary = corpora.Dictionary(words_ls)
# 基于词典,使【词】→【稀疏向量】,并将向量放入列表,形成【稀疏向量集】
corpus = [dictionary.doc2bow(words) for words in words_ls]
# lda模型,num_topics设置主题的个数
lda = models.ldamodel.LdaModel(corpus=corpus, num_topics=10, id2word=dictionary)
# 打印所有主题,每个主题显示20个词
topics = lda.print_topics(num_words=20)
for topic in topics:
print(topic)
# 主题对应编号(手动输入)
dt = dict()
_themes = ['science', 'car', 'finance', 'sports', 'military', 'medicine',
'entertainment', 'politics', 'education', 'fashion']
for i in range(10):
print(topics[i])
j = int(input('{}'.format([k for k in enumerate(_themes)])).strip())
dt[i] = _themes[j]
del _themes[j]
# 主题推断
inference = np.argmax(lda.inference(corpus)[0], axis=1)
inference = [dt[i] for i in inference]
print(np.mean(themes == inference))
# 读数据
from pandas import read_excel
ay = read_excel('data10/data10.xlsx').values
x, y = ay[:, 0], ay[:, 1]
experiment(x, y)
实验结果和结论
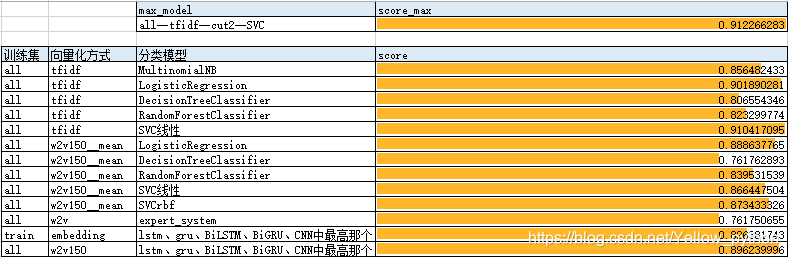
- 逻辑回归整体最优(最高准度第2,平均准度第1,结果稳定,速度ok)
- 独热编码优于词向量
- 独热编码tfidf优于count
- 线性svm训练时间过长,结果不稳定
- 独热tfidf+线性svm准度最优
- 深度学习的训练轮数不易确认,导致不稳定
- 数据量较少情况下深度学习的准确度较机器学习低
- 词向量相当于降维,低维空间上,逻辑回归和线性SVM效果一般,高斯核函数SVM效果更好但不稳定
- 无监督学习中,【词向量+专家系统】有76%的准确率
- 主题模型是垃圾!LDA是垃圾LDA是垃圾LDA是垃圾LDA是垃圾LDA是垃圾LDA是垃圾


















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











