






下载模型
1、 从魔塔上下载qwen2.5-7B-Instruct
看官方文档
看了几个官方文档,主要关注最后两个
GitHub主页面
GitHub中微调介绍
Qwen文档
2、 看官方发布在GitHub上的Qwen2.5介绍,上面写了finetuning部分
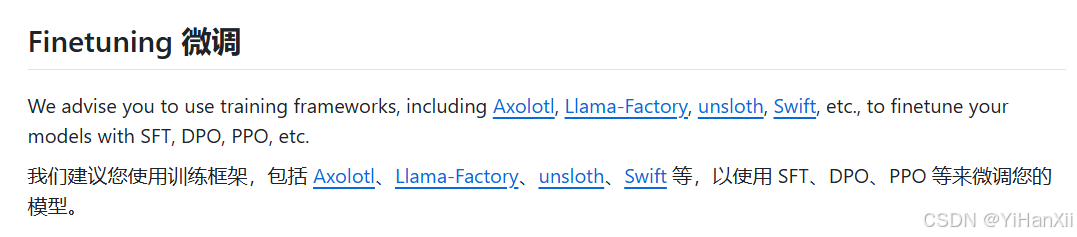
这里没详细介绍,所以我又看了Qwen文档,文档里面介绍的FT部分详细一些。
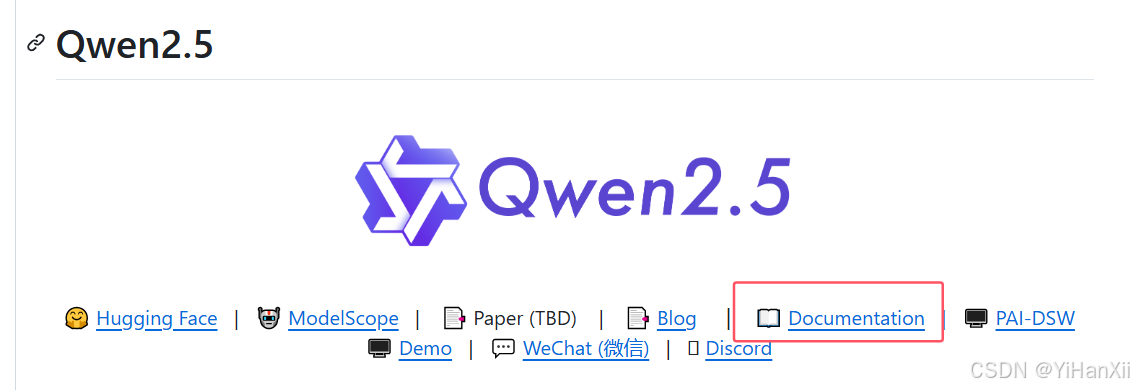
下载微调训练框架
3、 介绍文档里面训练介绍的是LLaMA-Factory,所以我又从GitHub下载这个框架
按照要求配置虚拟环境,python=3.11
cd LLaMA-Factory
pip install -e ".[torch,metrics]"//安装依赖项
准备数据集
4、 准备数据集
我想自己下数据集,用的商品文案描述生成。(这个数据集用代码下,总下不成功,所以我是手动下的)下载的csv格式数据需要转为为合适的格式。按照Qwen文档要求,要改成alpaca 和 sharegpt格式。
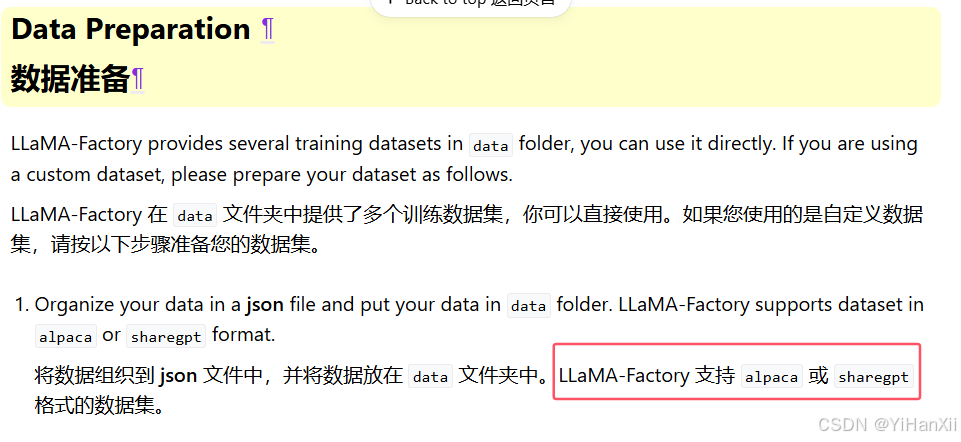
我选择的数据集就单论对话,所以打算在转换成alpaca格式。
设置数据集相关路径、格式
5、 我发现还有个GitHub微调介绍文档,官方文件夹这个路径的文件Qwen2.5/examples/llama-factory/finetune-zh.md。

文档中提到准备好训练数据之后还需要把 一些信息添加到LLaMA-Factory文件夹下的data/dataset_info.json文件中里,但是这里介绍的是用sharegpt格式。而我用的alpaca格式。所以不能照着这个来

那么用的alpaca格式的话,该怎么修改data/dataset_info.json文件呢?Qwen文档有写,我截图在下面了。

我准备的数据集中没有query、system、history部分,因此我修改的后的dataset_info.json内容部分我写在下面的代码块
{
.......
"starcoder_python": {
"hf_hub_url": "bigcode/starcoderdata",
"ms_hub_url": "AI-ModelScope/starcoderdata",
"columns": {
"prompt": "content"
},
"folder": "python"
}, ##添加下面这些内容时,这里得加 “,” 逗号
###以下是添加的内容
"qwen_train_data": {
"file_name": "/home/zhengyihan/project/finetuning/LLaMA-Factory/mydata/product_descriptions.json",
"columns": {
"prompt": "instruction",
"response": "output" ##这里没有 “,” 逗号
}
}
###以上是添加的内容
}
开始微调
6、开始微调, 从GitHub上下载这两个文件,然后放在合适的路径下,我把它放到LLaMA-Factory这个文件夹里了
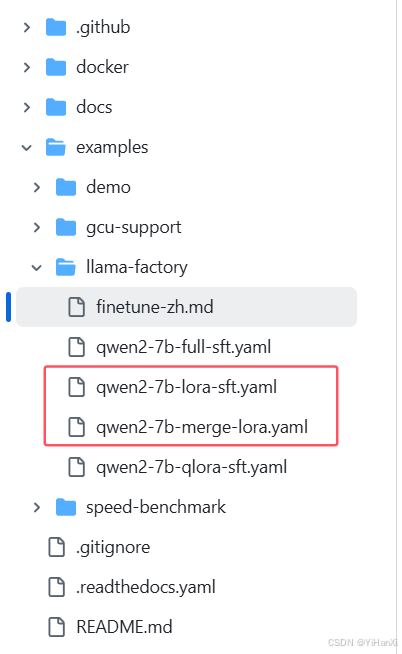
这两个文件下载之后还要修改一些参数,看GitHub中微调介绍,微调用的是qwen2-7b-lora-sft.yaml文件,所以先修改这里面的内容。
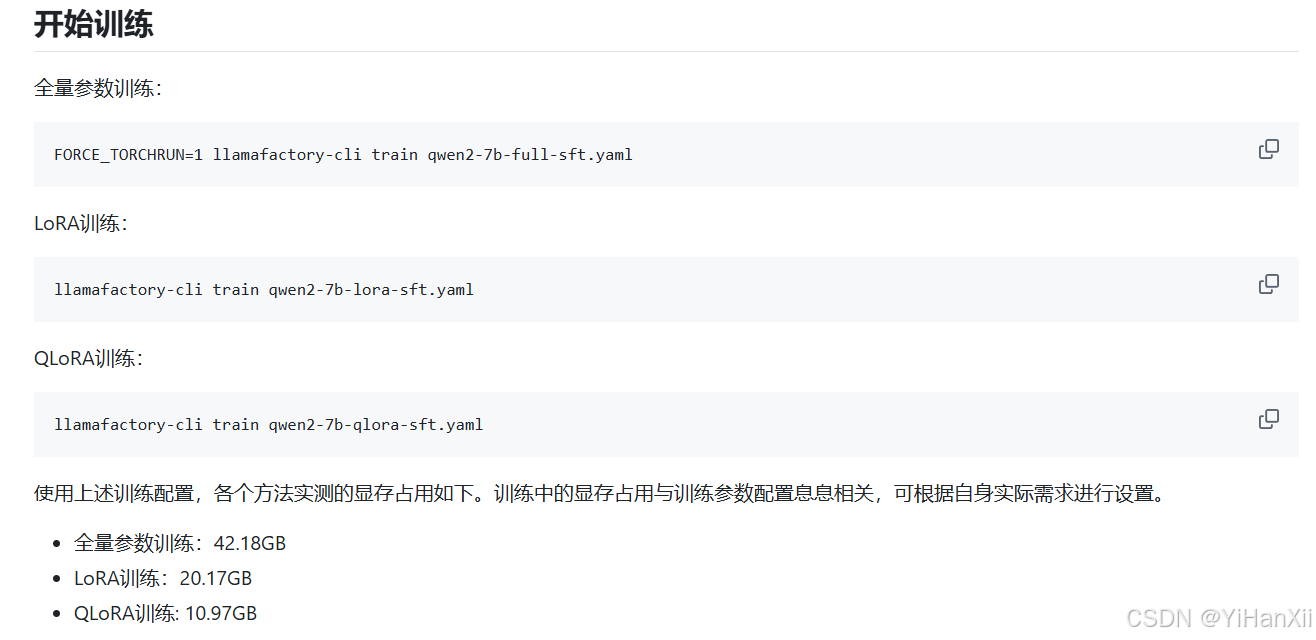
需要修改的内容主要如下,看不懂这两个是什么路径的就使劲敲自己脑袋
然后在黑框里运行这条命令就开始训练了!!!!
llamafactory-cli train qwen2-7b-lora-sft.yaml
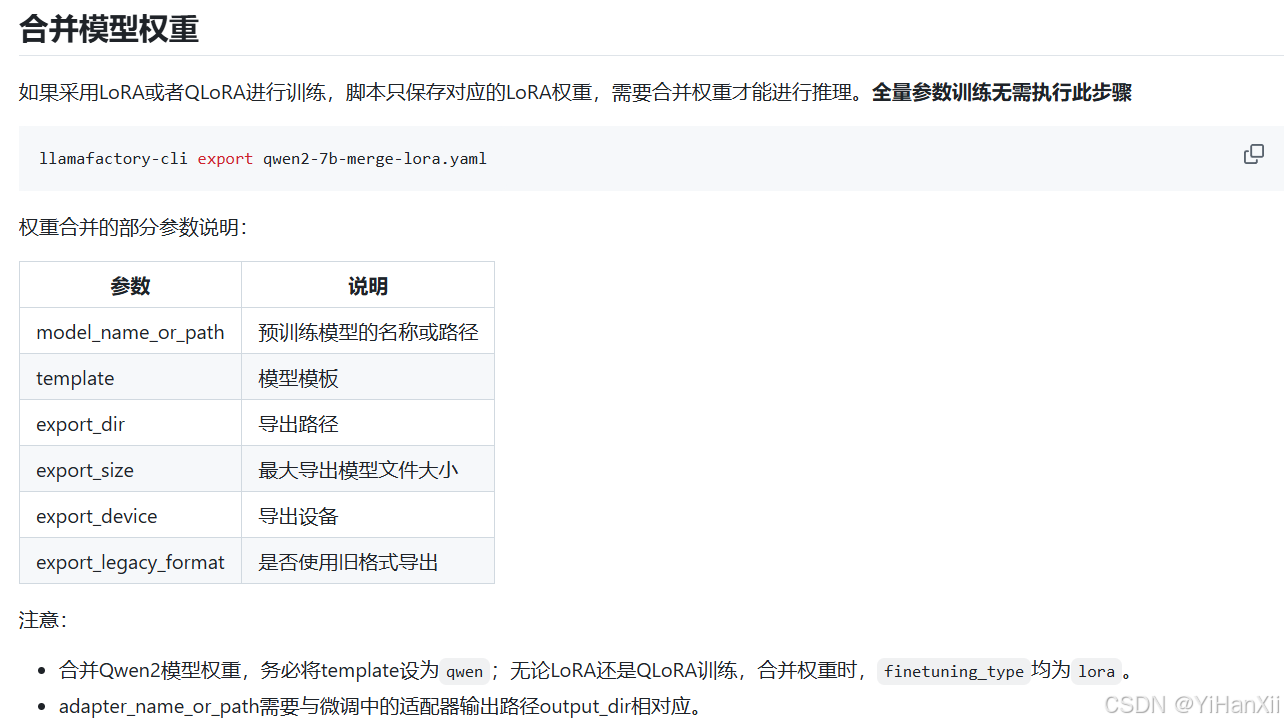
合并模型权重
GitHub中微调介绍
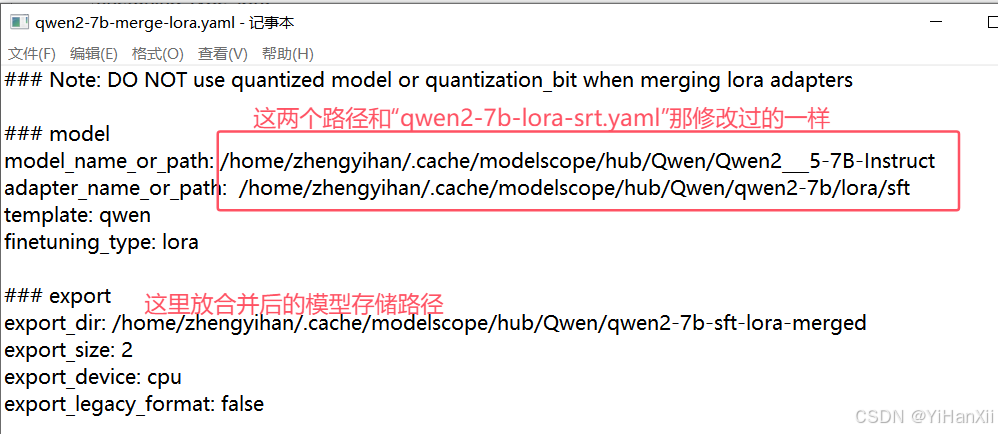
先修改qwen2-7b-merge-lora.yaml文件内容
然后在黑框里运行这条命令就开始合并权重了!!!!
llamafactory-cli export qwen2-7b-merge-lora.yaml
训练完成,测试模型
训练完成,合并模型权重之后,即可加载完整的模型权重进行推理, 推理的示例脚本如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # the device to load the model onto
model_name_or_path = "/home/zhengyihan/.cache/modelscope/hub/Qwen/qwen2_7b-sft-lora-merged"
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
prompt = "水溶C,饮料,营养,维生素,健康,酸甜,可口"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)


















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











