






来源丨arXiv每日学术速递
今天,我们介绍的是快手Y-tech入选CVPR 2021的工作之一,Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration。本文的主要贡献是利用语义聚合与多维度配准实现了相机空间的手部三维重建。

https://arxiv.org/pdf/2103.02845.pdf
https://github.com/SeanChenxy/HandMesh
一、背景
针对虚拟交互任务,我们对手部三维重建进行了研究,称为hand mesh recovery。mesh包含pose和shape两层含义。人体本身是一种很强的先验条件,在这种条件下,2D-to-3D任务是一个十分有价值的研究方向,其核心问题不再是进行某种3D测量,而是建立图像特征与几何形状以及人体运动学之间的关系。同时,由于生活中少有multi-view image或者3D sensor,2D-to-3D任务有较强的应用价值。
二、动机
基于单目图像预测绝对3D尺度是一个歧义问题。并且,在人体三维重建任务中,有两种“绝对3D尺度”:1)某一点在相机空间中的绝对坐标;2)人体骨骼长度。它们都是3D测量问题,原理上不可解,于是通常采取一些方法来回避。对于问题1),通常预设一个root(对于人体而言一般是盆骨,对于人手而言一般是手腕),并在root-relative空间中进行3D几何形状的预测。对于问题2),如有groundtruth,可以利用 Procrustes analysis来求解,该方法也成为了该领域的evaluation中不可缺少的一部分。我们认为,hand-object交互等高阶任务中需要绝对的3D信息,并且,由于人体骨骼长度不会发生剧烈的变化,问题1)相对问题2)而言更加重要。因此,我们思考如何在相机空间中实现hand mesh recovery。实际上,只需预测root在相机空间中的位置即可,称为root recovery。
人体2D-to-3D 任务中,对图像进行全图卷积处理产生了大量无关的2D特征。为进行特征选择,通常利用人体的2D joint landmark (骨骼关键点))或者silhouette(剪影,这个词指三维到二维的投影,可以不严谨地理解为分割)来进行特征选择。但是这些2D先验对3D任务的作用并没有得到清晰的分析。因此,我们探究2D先验对3D mesh 和3D root重建的影响及其原因,并尝试设计更好的2D先验。
三、 方法
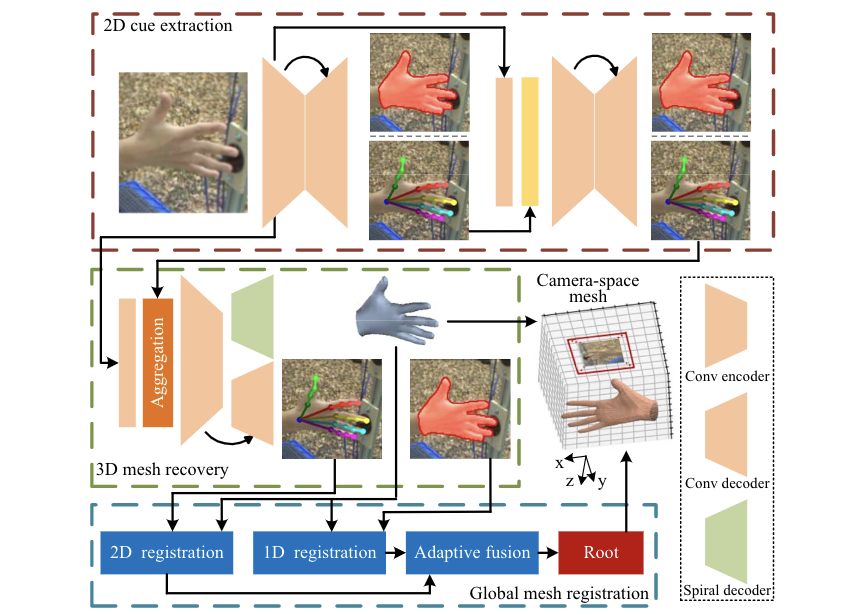
我们提出 camera-space mesh recovery(CMR)框架,分为三个阶段:
先验阶段(2D cue extraction):利用hourglass network设计一个2D encoder-decoder,输出手部的2D pose(包含21个关键点)和silhouette。
mesh生成阶段(3D mesh recovery):利用2D cues作为先验与图像的浅层特征融合,并再次下采样。利用两个decoder分别进行2D和3D解码,获得改良的2D属性和3D mesh。此时,mesh建立在root-relative空间中。
全局配准阶段(global mesh registration):利用2D和3D属性的空间关系优化root在相机空间中的绝对坐标。
其中,有三个关键设计:第二阶段中的语义聚合和3D螺旋解码器,以及第三阶段中的自适应2D-1D配准。
3.1 语义聚合
Silhouette可以看做是2D shape,用一个heatmap表示,相关工作认为它对3D shape的恢复具有先验意义。2D pose的预测通常采用基于heatmap的回归方法,每个joint landmark用一个heatmap进行建模。因此,每个joint信息就可以拆解为定位(locations)和语义(semantics)。同时,我们认为这种基于heatmap的回归丢失了joint之间的关联(尽管语义关系隐含在heatmap的排序中,但实际上网络难以学习出完整的有益信息),但高层语义关系对3D任务而言同样具有先验意义。于是,我们提出了一种语义聚合方法来探究不同的2D cues对3D mesh重建的作用,表示如下:
:关于2D pose的个 heatmap
:关于剪影的 heatmap
:级联的和
:把个的关键点用一个heatmap表示,即保留定位信息并丢失语义信息
:将与聚合的关键点heatmap级联

我们主要强调的是,认为这是一种更好的2D先验。motivation在于我们在实验中发现,即使仅使用,编码特征中依然会有多个joint被同时激活。这个现象表明encoder隐含地学习了joint landmark之间的关系,称之为sub-pose。于是,我们希望sub-pose能够显示地表达出来。图2展示了我们对sub-pose的设计:part-based,level-based,tip-based。基于part和level的聚合方式比较直观,体现了高层语义。设计基于tip聚合的动机有两点:
我们观察到在以为先验的实验中,网络自主表达出的sub-pose通常是tip聚合。
人手的运动被逆向运动学约束,因此末端的位置十分重要。
3.2 3D螺旋解码器
本节省略对螺旋卷积(SpiralConv)的介绍,如果想了解更多关于图卷积和SpiralConv的知识,请参考此前的文章,https://mp.weixin.qq.com/s/bYi8kSUQ7jHeSJ5fts9pJQ。
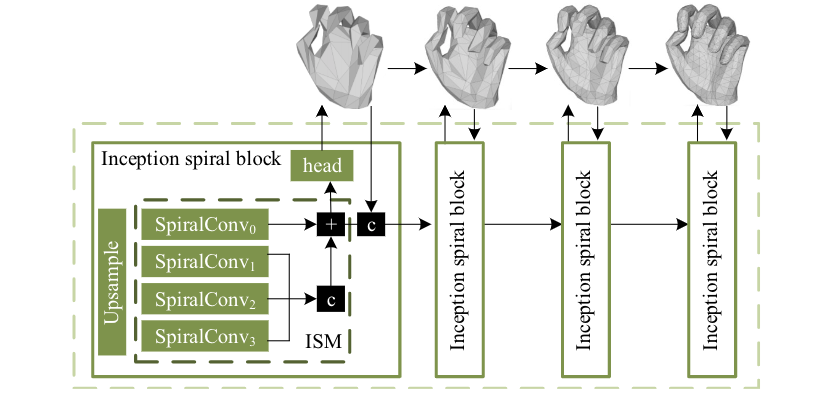
图3:螺旋解码器。包括ISM、多尺度机制和自回归
如图3所示,我们对解码器做了三点直观的改进:
1. Inception spiral module(ISM):利用SpiralConv设计了针对mesh数据的Inception layer,以增强感受野。
2. 多尺度融合/监督:构建了mesh的金字塔特征,在不同的尺度上对预测结果进行监督,相邻尺度的预测结果基于加法进行融合。
3. 自回归:每一个尺度的预测结果与该尺度的特征级联。
3.3 自适应的2D-1D配准
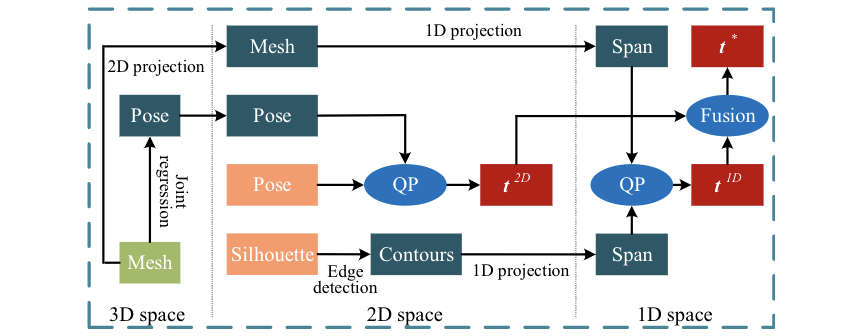
图4:自适应的2D-1D配准。QP表示二次规划
以上方法将mesh重建在root-relative空间中。仅使用单目图像不足以预测相机空间的信息。但是,2D与3D的关系隐含在相机参数中,经典的PnP方法就可以利用2D与3D的关系推理相机空间中的旋转和平移。我们利用2D pose和silhouette与3D mesh的空间关系来优化root的绝对坐标,整体流程如图4所示。
定义root坐标为。基于相机参数、joint-vertex关系矩阵、root-relative空间中的mesh顶点,计算投影的2D 关键点 。和网络预测的2D pose 有一一对应关系。因此,2D空间中的优化目标为:
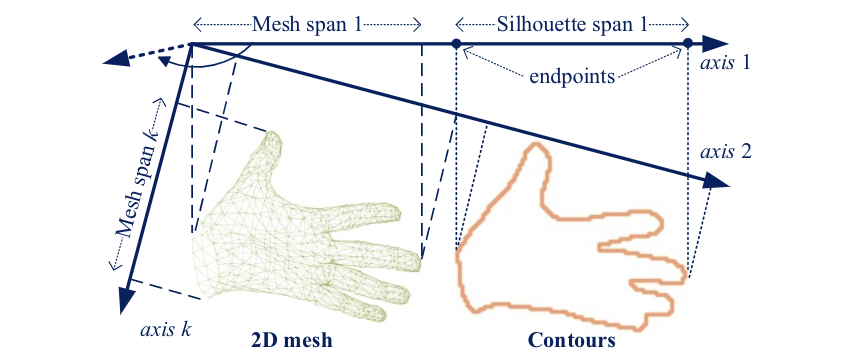 图5:1D投影
图5:1D投影
对于silhouette,已有silhouette loss可以表达它与3D mesh的匹配程度,即把mesh投影为silhouette再计算两者的相似性(L2或者IoU)。但silhouette loss的计算需要可微渲染,且它是一种关于全图的稠密计算,因此对于(移动端的)实时在线优化并不友好。另外,silhouette和mesh均包含了大量的点元素,且不存在明确的对应关系。因此,直接用点到点的方式配准2D mesh与silhouette也不可行。于是,我们提出了1D投影与1D配准方法。首先,利用投影得到2D mesh ,利用边缘检测从silhouette中提取2D轮廓 。如图5所示,我们均匀地设计12个1D axis ,并进行1D投影:
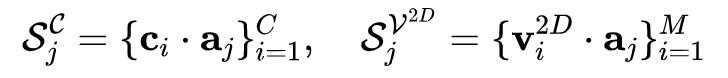
得到在1D axis上的span,并取端点作为该一维方向的表达。因此,1D 空间中的优化目标函数为:
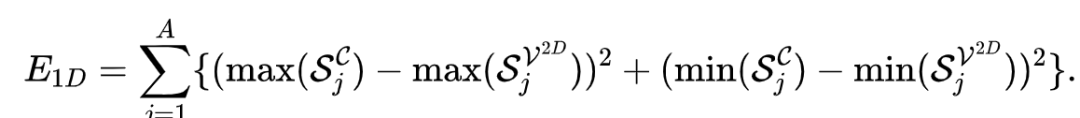
两个配准过程均为最小二乘问题,可用二次规划方法求解,获得与。为自适应地将两者融合,首先计算他们的距离,再进行线性加权融合:
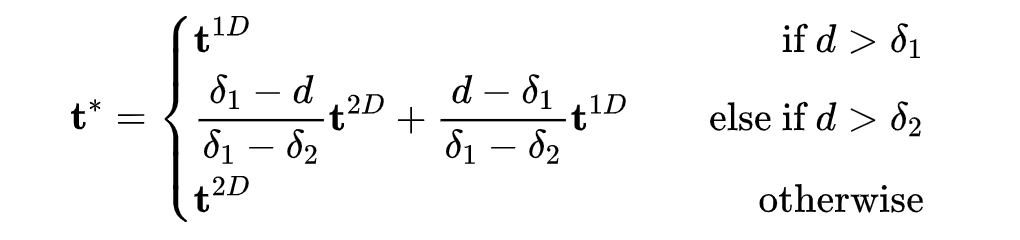
,这两个参数与3D尺度有关,但鲁棒性较强。我们没有做wide search,对手部使用,对人体使用。该自适应融合方法包含了以下含义:
1. d较小时,相信2D配准,因为其中的对应关系是完全准确的。
2. 2D pose的预测难度远远大于silhouette,因此当较大时,很可能是因为2D pose不够准确。
四、 实验
4.1 baseline
我们复现YoutubeHand作为baseline,并替换其3D解码器。

表1:所提3D解码器与baseline的对比
4.2 语义聚合
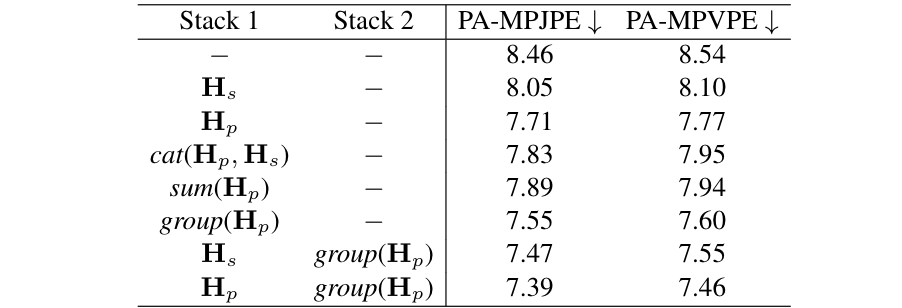
表2:2D先验的作用
如表2所示,:
比较,2D pose与silhouette 均有先验意义,但pose更重要。
比较,2D pose的语义很重要。
比较,2D pose与silhouette并不互补。
我们尝试从特征表达的角度观察以上现象

图6:基于2D先验的特征表达。和 表达整体手型和关键点定位。隐含地表达了关键点的语义关系,而能够带来更丰富的关系表达。
从图6中可以看出,派生出关键点的表达,派生出整体手型表达,并且:
同样能够派生出整体手型表达,这导致了2D pose与silhouette的互补性较弱。
的每一个heatmap包含独立的关键点定位和语义,但其派生的特征表达中往往包含多个同时激活的joint landmark,且几乎不表达独立的 joint。因此,我们认为joint的关系更加重要。由于带来的关系信息有限,我们设计了来显示地表达sub-pose。
从定量指标和sub-pose的多样性上看,均优于。
4.3 自适应的2D-1D配准
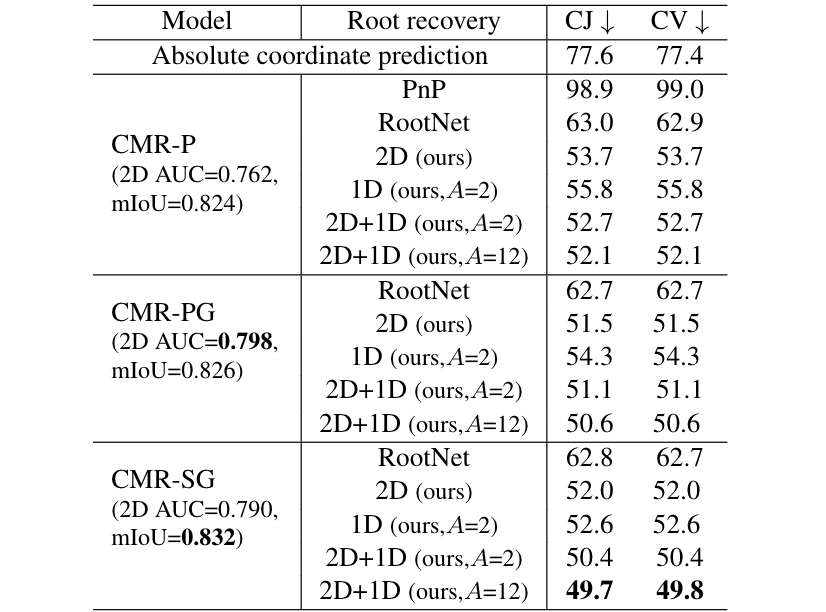
表3:2D-1D配准的作用
首先,我们直接预测相机空间的绝对坐标(该方法易过拟合),并作为该实验的baseline。将表2中的第3、7、8行命名为CMR-P、CMR-PG、CMR-SG。这三个模型预测的2D pose和silhouette质量不同,CMR-PG有最好的2D pose,CMR-SG有最好的silhouette。相应地,CMR-PG的2D配准更好,CMR-SG的1D配准更优,且2D+1D在各模型上均能产生更好的配准结果。
4.4 对比相关工作
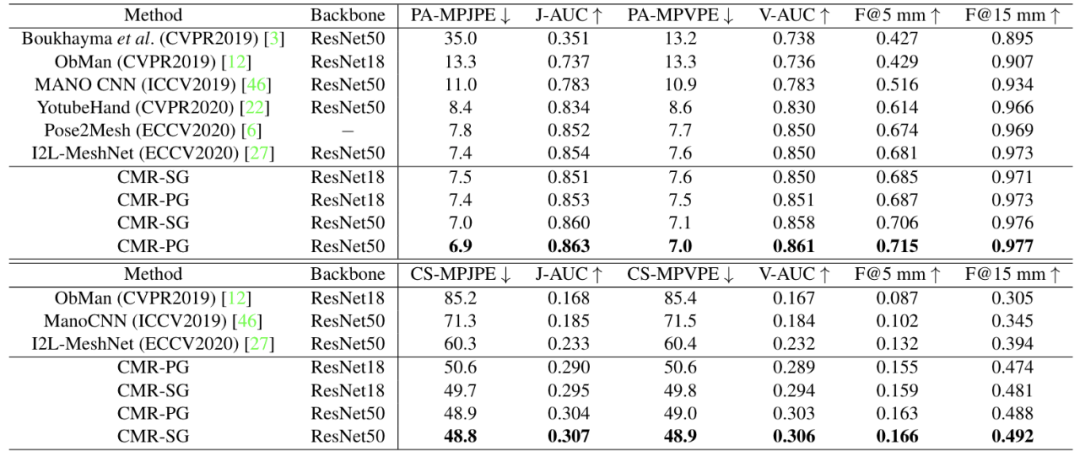
表4:基于FreiHAND的对比实验
图7:3D PCK对比
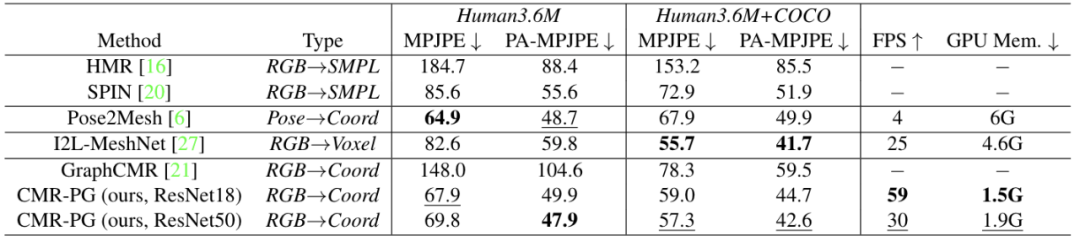
表5:基于Human3.6M的对比实验
我们在FreiHAND、RHD以及Human3.6M数据集上进行了对比实验,CMR均取了较好的性能。
4.5 可视化
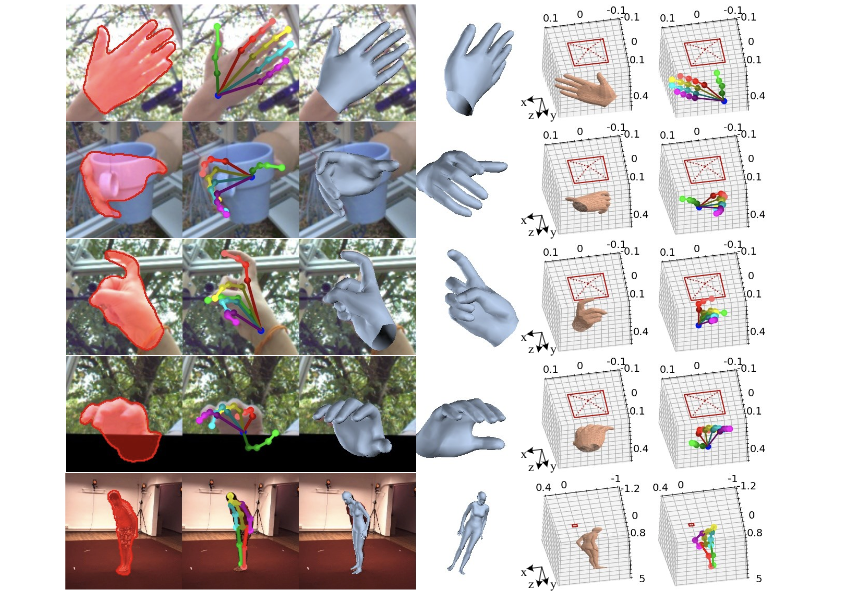
图8:预测结果可视化。包括silhouette、2D pose、配准的mesh、多视角mesh以及相机空间中的mesh和pose
五、未来方向
现有的三种主流pipeline(基于MANO、基于voxel、基于vertex)均没有实现轻量化,我们目前已针对移动端的轻量化方法展开了研究。
如何在2D空间中引入生物和物理约束是十分值得探究的科学问题。
我们观察到所提方法对3D数据的依赖较强,但3D数据难以采集且难以准确标注。弱监督方法或将成为未来的研究方向。
动力学是人体区别于物体的重要特性,探索动力学有助于3D人体任务的发展。
Reference
Xingyu Chen, Yufeng Liu, Chongyang Ma, Jianlong Chang, Huayan Wang, Tian Chen, Xiaoyan Guo, Pengfei Wan, and Wen Zheng. Camera-Space Hand Mesh Recovery via Semantic Aggregationand Adaptive 2D-1D Registration. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
图卷积:从谱域滤波到空域螺旋. https://mp.weixin.qq.com/s/bYi8kSUQ7jHeSJ5fts9pJQ
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









