






作者丨一个普通的求学者@知乎
来源丨https://zhuanlan.zhihu.com/p/482785806
编辑丨3D视觉工坊

原文标题
背景
大规模人工标注的点云数据集由于其不规则性,在三维物体的分类、分割和检测等任务往往是费力的。Self-supervised学习,无需人为标注,是解决该问题的一个非常有前景的方法。在现实世界中,人类能够将从2D图像中学习到的视觉概念映射到3D世界中。受此启发,于是作者提出了CrossPoint,一种简单的跨模态对比学习方法,用于学习可转移的3D点云表示。
论文主要贡献
(1)使用2D-3D数据在自监督学习上做对比学习,有利于网络对点云的特征学习
(2)提出了端到端的自监督学习的目标封装intra-model以及cross-model损失函数,这使得2D图像特征能更好的嵌入到3D特征中,从而有效避免特定增强的偏差。
(3)将CrossPoint广泛应用到各种下游任务中,效果优于原先的无监督学习。
(4)在CIFAR-FS数据集上执行了少镜头的图像分类,以证明从CrossPoint调优预处理后的图像性能优于标准基线。(就是说加了图片对于点云后续任务更好)
相关工作
1. 点云的表征学习
由于点云的不规则结构以及在处理点数据时所需要的置换不变性,这使得对于点云的表征学习相对于其它的表征学习(例如图像)更为困难,有了深度学习在点云上直接应用的先锋——PointNet,众多点云深度学习网络诞生。尽管网络表现性能很好,但其依赖于有着人为标注信息的数据集,这类数据集是难以获取的。于是,CrossPoint的诞生,就是为了从一大堆无标注信息的数据中提取可转移的特征信息,并将其应用于下游任务——分类以及分割。
2. 点云上的自监督学习
首先要对自监督学习有一个概念,众所周知,机器学习分为三类,有监督,无监督以及自监督,前两种定义十分明确,这里从论文原文简单说明自监督学习。
自监督学习分为两类,Generative Method(包括GNN以及AE,目的是重建给定的数据集);Contrastive Method(对比学习,论文使用的架构),这里可以学习Siamese neural network(孪生神经网络:https://zhuanlan.zhihu.com/p/35040994)
我感觉,其实就是通过两个共享权值的网络,通过对同类输入的输出进行距离最小化,反类输入进行距离最大化来进行更新参数,至于距离度量的选择,就是一个叫Contrastive Loss的东西了。
3. Cross-Modal Learning
根据我的理解,作者是说利用跨模型来学习,分别是2D图像以及3D模型之间的特征迁移与嵌入,其中提到了一个叫pixel-to-point 的image features extractor
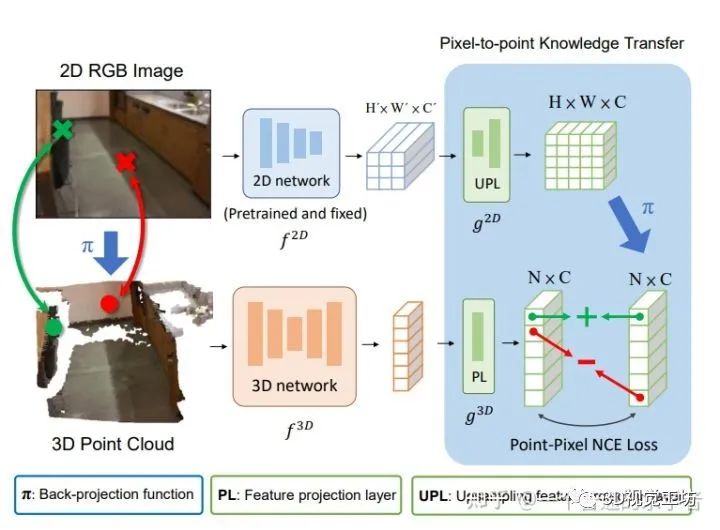
Learning from 2D原文网络架构
大概意思就是说利用一个backprojection function来对齐二维与三维之间的特征,此外,还设计了一个叫upsampling feature projection layer来学习细粒度的3D表示。然后使用二维图像对网络进行一个预训练,从而优化在下游任务的表现。
点云视频教程:面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
网络架构
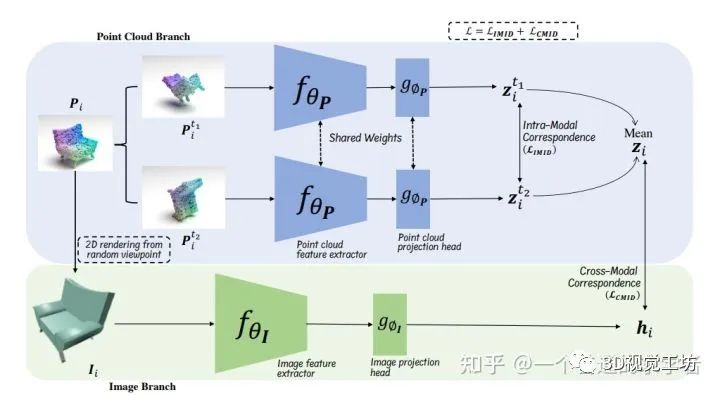
CrossPoint的网络架构
1. 整体分析

这里上半部分是有两个P输入的,作者称其为augmented versions。其实就是原始3D模型进行随机变换(如旋转,放缩以及平移),这里其实很类似于前文提到的Siamese neural network,两层网络都共享权重,最后得到的Z取两个的平均。
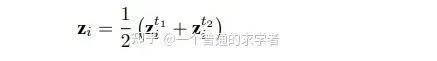
2. 损失函数

便于理解,我们不妨把上述公式做一个转换
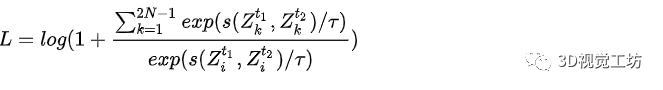
为了最小化 L,需要分母项增大而分子项减小(这里不是很明白为什么求和时两个都是k,按照原本的NT-Xent损失函数,比对的是该输出与batch中2N-2个样本之间的相似度,2N中一个是本身,一个是augmented version)。详情点击Normalized Temperature-scaled Cross Entropy Losss(https://paperswithcode.com/method/nt-xent)
而且从原文作者描述也能看到
 最后总Loss就是两个相加
最后总Loss就是两个相加
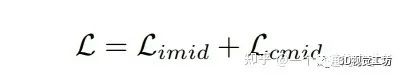
下游任务
1.1 2D渲染图数量的选择
 作者发现,一张图是效果最好的,因此后续实验都选择了一张渲染图片。
作者发现,一张图是效果最好的,因此后续实验都选择了一张渲染图片。
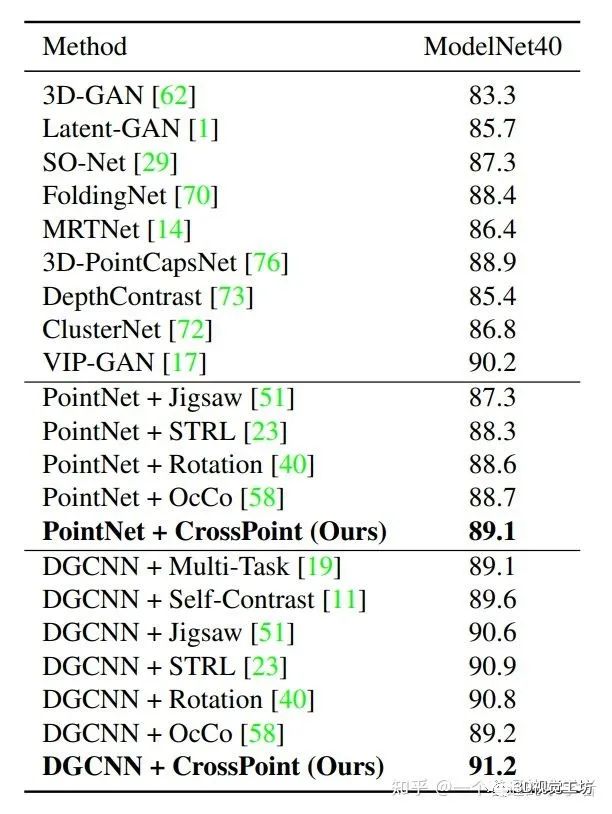
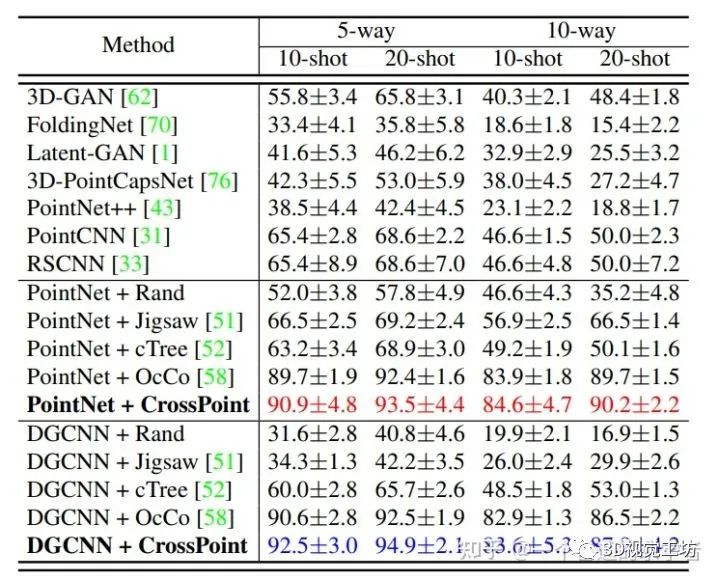
1.2 分类任务
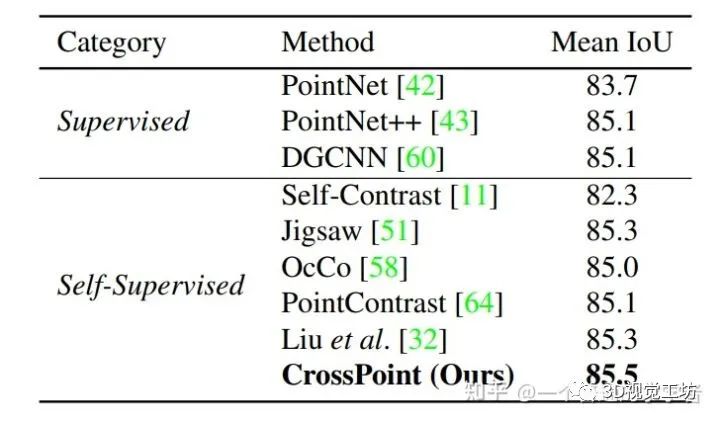
1.3 分割任务
1.4 IMID和CMID效果
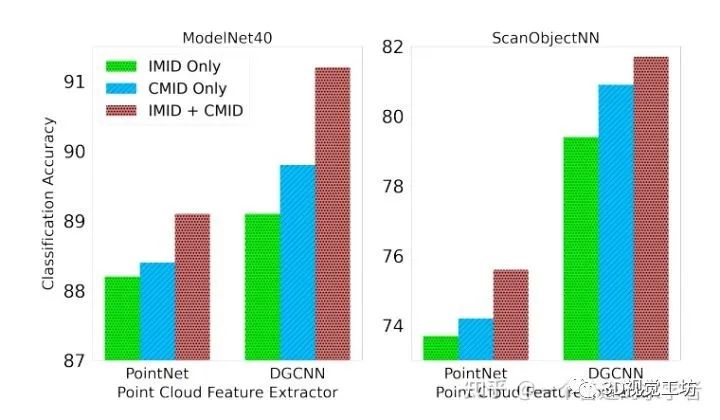
1.5 在CIFAR-FS上的少镜头分类
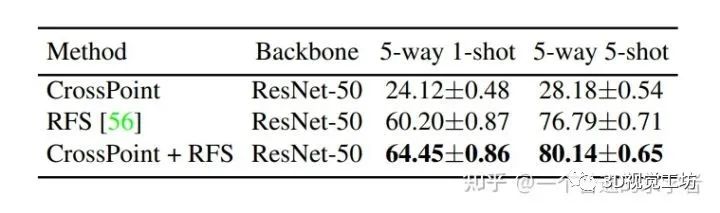 后续点云下游任务并未用到image的extractor,而单单把该extractor用来做分类,效果就不太理想了,原文作者说是因为原先使用的是3D点云模型的渲染图做预训练,并不能很好的泛化到CIFAR数据集上导致的(效果差异非常大)。
后续点云下游任务并未用到image的extractor,而单单把该extractor用来做分类,效果就不太理想了,原文作者说是因为原先使用的是3D点云模型的渲染图做预训练,并不能很好的泛化到CIFAR数据集上导致的(效果差异非常大)。
总结
这篇是在CVPR202203上的文章,还是非常新的深度学习点云学习,个人觉得亮点是引入了self-supervised learning中的contrastive learning做pretrain,值得一读,上述全为本人论文阅读笔记,如有不对请评论区指出。
参考
[1]. Learning from 2D: Contrastive Pixel-to-Point Knowledge Transfer for 3D Pretraining
[2]. Self-Supervised Learning 入门介绍
[3]. 对比式无监督预训练简介(Contrastive Pre-training)
[4]. Siamese network 孪生神经网络--一个简单神奇的结构
[5]. contrastive loss 详解
[6]. 余弦距离介绍
[7]. Normalized Temperature-scaled Cross Entropy Loss
[8]. CrossPoint
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 2439
2439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









