






作者:紫川科技(已授权转载),计算机视觉life整理
原文链接:https://zhuanlan.zhihu.com/p/645564160
一、前言
不知不觉已经拖更了这么久了,近期忙于写提升VIO精度的新算法(将嵌入在viobot的下一个大版本更新中),而提到精度,也跟精度这一话题密切相关,请各位看官耐心阅读。
本专栏面向小白,所以文风主打极致的通俗易懂,难免有失严谨,在可能含歧义的地方我会安排引用以供参考。
另外强调,本专栏主要是发表阿达 @空格同学 bEary 的个人观点,紫川科技概不负责。
 进入正题。这届的slam技术论坛在厦大思明校区举办,不得不说,厦大的环境令人心生羡艳。
进入正题。这届的slam技术论坛在厦大思明校区举办,不得不说,厦大的环境令人心生羡艳。
 随手一拍,城堡般的宿舍楼
随手一拍,城堡般的宿舍楼
作为国内SLAM行业最大的盛会,这次论坛的规模比前三届都要大,到场的嘉宾规模也是前所未有,从大咖面对面的规模就可见一斑。
业界各路大咖甚至一些深居简出的隐藏大佬都亲临现场,还有引领SLAM前进的TUM的Daniel Cremers教授都做了线上报告,属实是面子里子都给到位了。我也不多废话,进入主题

二、论坛内容的简述
会上的每篇工作都是非常优秀的,但受限于篇幅,我就只挑我个人最感兴趣的工作做下简单的记录(涉猎少的也不讲,讲错了老脸挂不住),也即更多的是传统几何方法VSLAM相关。
1、周晓巍----LoFTR及其延续工作
 LoTTR是周老师组的经典工作了。VSLAM前端,说白了就是追踪不同图像帧之间的同一个点,传统算法像经典的ORB,会先提角点后计算描述子,然后通过最近邻方法匹配描述子[1]来匹配角点。
LoTTR是周老师组的经典工作了。VSLAM前端,说白了就是追踪不同图像帧之间的同一个点,传统算法像经典的ORB,会先提角点后计算描述子,然后通过最近邻方法匹配描述子[1]来匹配角点。
但多多少少都会存在误匹配,所以通常会用RANSAC、鲁棒核函数之类的手段滤去错误的匹配。
进一步,学习(Learning-Base)方法像基于端到端图卷积神经网络魔法的SuperGlue[2],则使用来自同一团队的工作SuperPoint[3]提取的特征点与描述子,把匹配与过滤误匹配打包一块做了,匹配准确性与鲁棒性更上一台阶。
近几年一些针对不同天气不同季节的同一场景下的回环检测工作就很爱用SuperPoint配合SuperGlue,效果拔群。但事情总不是完美的,比如当两帧之间缺乏共同视野的时候SuperGlue仍会强行匹配,这对后端来说自然是毁灭性的打击
 无共视关系还硬匹配,我称之为赛博形式主义
无共视关系还硬匹配,我称之为赛博形式主义
接着LoFTR[4]横空出世,其基于 带自注意层和交叉注意层的Transformer 另一种魔法,创新之处在于其匹配并不针对单一特征点,而是一群点。
尽管如此,其匹配精度却仍能达到亚像素级真是见了鬼了。但也得益于批量点匹配的策略,面对缺乏纹理的区域,LoFTR仍然能做到高质量的匹配。
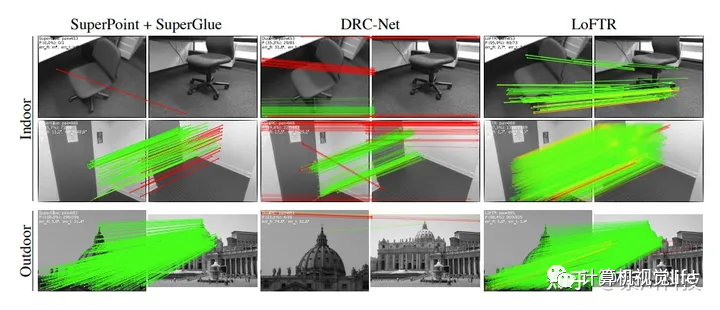
但成也萧何败也萧何。LoFTR的匹配不针对单一特征点,这也导致其匹配难以在多帧图像间持续,而传统的SfM方法三维重建恰恰非常依赖于对空间中同一点尽可能多帧的连续追踪。
周老师团队对此的思路是:解决不了问题就解决问题的来源(请不要将这一思路应用到人际交往中),从SfM本身下手,提出了基于LoFTR的SfM[5]。
具体的操作是先舍弃LoFTR高精的优点,将降低精度后数值接近的匹配都归为同一匹配,以此解决跟踪不连续的问题,做一次比较粗糙的SfM,见下图左。
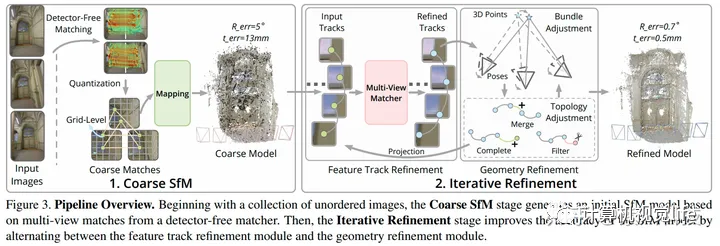 说它粗糙我没冤枉它吧
说它粗糙我没冤枉它吧
紧接着再使用Feature Track Refinement与Geometry Refinement两种Transformer模型,前者优化跟踪精度,后者优化位姿精度,最后就能得到上图右的精美建模了。
最能表现其性能优越的就是该方法取得了Image Matching Challenge 2023第一名的优秀成绩。
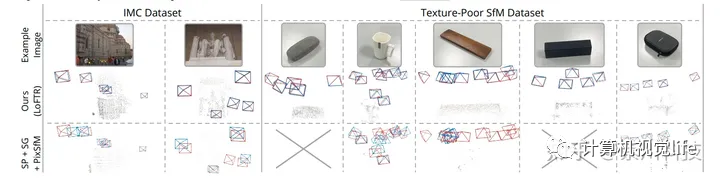
这种方法完美继承了LoFTR高鲁棒的优点,对弱纹理对象诸如下图的眼镜盒、纯白色水杯、纯黑色盒子的重建效果令人称奇,具体表现可观看这条视频,看完对周老师团队的工作无比佩服。
值得一提的是,周老师在SLAM论坛现场的讲解,思路清晰,语言流畅,PPT做得尤为精美,丝毫没有因为这是一场严肃的学术会议而让人昏昏欲睡,着实是一场令人非常享受的报告。
2、SLAM竞赛引出的思考
SLAM竞赛环节上,一个来自中科院自动化研究所的方案中,一个叫“中值绝对偏差MAD”的方法让我非常惊喜,因为他们关注到了SLAM中的系统误差的来源。
这个团队注意到了信息矩阵----也即视觉在VIO系统中的权重----并不精准,于是使用如下策略对其做了一个精修,使其更逼近真实值,后续的实验也表明精度得到了显著的提高。

很多工作,包括会上被提到的LoFTR,还是IMU的预积分,都是为了降低SLAM系统的偶然误差----前端误匹配导致的数据源污染。
前端跟后端的许多工作包括鲁棒核函数、滑窗滤波都是为了尽可能大地降低数据源污染所带来的影响。
但大家却很少关注到SLAM系统的系统误差----对噪声的高斯假设。
我们知道,传统几何方法中的SLAM最常用的非线性优化手段,本质上就是假设系统的噪声满足零均值的高斯分布,通过贝叶斯法则,让原本是非线性的系统可以使用正规方程进行近似求解。
也就是说,如果这一假设不满足或满足得不充分,那么最大似然估计、Bundle Adjustment将统统不成立。
 做SLAM的噩梦
做SLAM的噩梦
说白了,SLAM(Simultaneous Localization and Mapping)实际上并不是真的在“计算”,而是在“猜测”,猜测什么样的位姿变化可能性最大(Localization),当前观测最有可能来自怎样的环境(Mapping)。
正如下图所示,非线性优化得到的的位姿是存在零空间的,零空间所代表的范围,就是留给我们“猜测”的范围,SLAM要猜测,真实的位姿究竟在这个范围内的哪。
而如果没有额外的约束的话,位姿的范围,也即系统的不确定度会越来越大,所谓“一步错步步错”就是在形容这种现象。
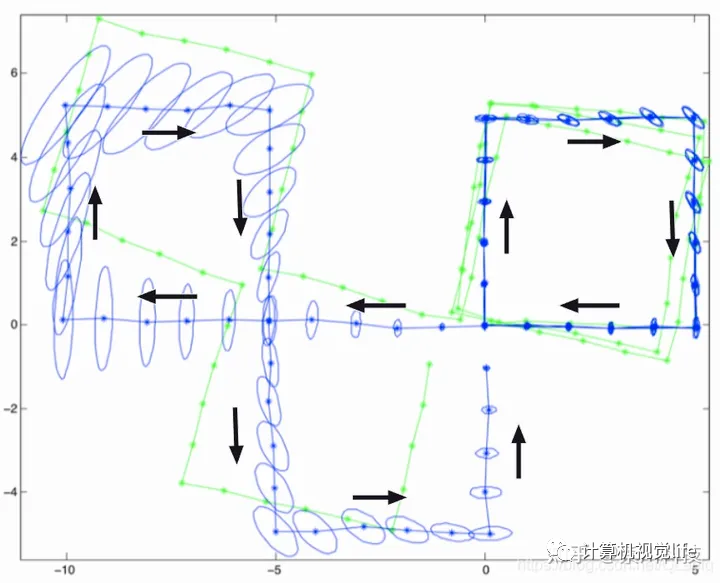 绿色轨迹代表后端优化前的轨迹,蓝色轨迹代表真实轨迹,蓝色椭圆代表零空间的范围,也可理解为误差范围
绿色轨迹代表后端优化前的轨迹,蓝色轨迹代表真实轨迹,蓝色椭圆代表零空间的范围,也可理解为误差范围
既然是基于高斯假设的猜测,那么自然提供给SLAM系统的“线索”,也就是用于统计的样本越多,系统猜得越准。
所以我们会看到(一定范围内)所有帧打包算的SfM它就是算的比只打包其中几帧的滑窗滤波SLAM准,滑窗大的的就是比滑窗少的准,前端提取到的点多的就是比点少的准。
目前压缩零空间大小的思路比较主流的是引入更多的约束,包括更多的传感器(GNSS、IMU、ToF)以及对画面更多的特征的利用(线、面、体、灭点),但同时也引入了更多的不确定因素,而且本质上,零空间依旧存在。
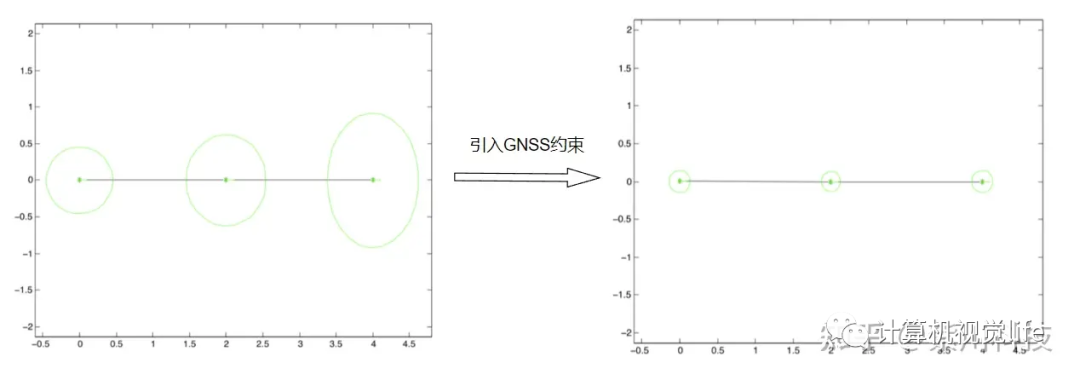
所以请以后如果,看到各路SLAM算法演示视频中,轨迹精准地回到原点的时候,请一定不要当真,因为绝大多数情况下那都是回环检测的功劳,不然就是调了一套数据集专用参,将其归结为“巧合”也不冤枉,误差永远是客观存在的。
在我看来,评判一份算法好坏的指标从来都不是其演示里面的准头,而应该是其被同类论文里面精度被“吊打”的次数。就比如,看下ORB、VINS、DSO这些经典算法,哪个不是三天两头被哪个自称SOTA的论文吊打,这影响它们在行内的地位了吗?

回到正题,近几年深度学习方法在SLAM行业的蓬勃发展倒是充分证明了其在SLAM上的巨大潜力,虽然其泛化能力的不足与对算力贪得无厌的索取表明这类方法离广泛落地还为时尚早,但其确实为“天下苦高斯假设久矣”的现状提供了一个全新的思路。
一些深度学习方法也确实突破了一直压在几何方法头顶上的那个精度上限,例如其中比较经典的DROID-SLAM[6]。(两块RTX3090的实时运行需求也令人叹为观止)
目前我还没有看到能比非线性优化更好更优雅的数理几何方法被用于解决系统误差。希望本文能起到一个抛砖引玉的作用。
3、高翔----激光融合SLAM在码头的落地案例

正如高博本人在报告的一开始所说:”没有非常酷炫的技术“,他的报告非常朴实地了展示了一个SLAM在码头场景的落地方案。
但在我看来这种内容非常宝贵,尤其是对于参会者的主体----学生,因为他们大多数身处学术界,而对工业界相对陌生,这样做出来的研究搞不好就容易与实际应用场景严重脱节,报告里的内容反而是他们最为需要的。
回到报告本身。码头是个很特别的场景,有着大量的集装箱、龙门吊等,体积巨大,且位置经常出现变化。
我们知道动态环境对SLAM系统的重定位影响是巨大的,更不用说这些能动的庞然大物。对此高博团队的思路是将点云地图分为动态与静态两种,前者由车端实时建图并往后台更新,后者则固定在后台。非常朴素却行之有效的方法。
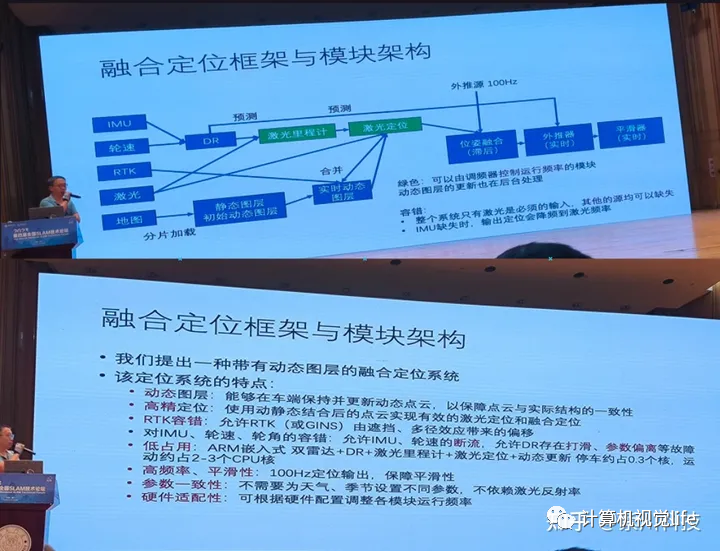
而对于多传感器的融合方案,高博团队做了非常详尽的思考,传感器间的延迟滞后、传感器的容错机制、对工控机有限性能的充分压榨等等,都让工程佬一本满足,光是这一场报告的这些工程技巧我都认为值回票价了。
激光里程计的选择是Lego-LOAM,之所以不是去年高博那惊艳四座的Faster-LIO,我想大概是出于对工程现场稳定性方面的考虑,毕竟IMU漂移引入的不确定因素还是太多了。
一套开源算法从实验室进入商用场景,是需要做出大量工程改动的,从PPT的内容可以看出还是下了不少心血的。

同时,由于现场对稳定性的要求极高,高博团队对系统的稳定性测试考虑得非常周全,包括使用大量离线数据对系统进行测试、对各类系统异常的容错机制等,种种细节无不体现高博对于算法落地丰富的经验。这份方案能在公开渠道放出来多少让人为甲方感到不甘。

提问环节上,这位观众掀起了激光与视觉之争----为何就连身为视觉SLAM界圣经作者的高博最后也选择了激光SLAM,视觉SLAM的前途究竟如何?

高博的回答大意为,面对自动驾驶这一严肃落地场景,稳定性的优先级高于一切,而在稳定性这一方面视觉----至少目前----跟激光方案比还是有一定差距的。
不过有很多场景下,视觉仍然是唯一的选择,譬如高速场景(高速行驶的车辆)、开阔场景(操场)、高反射率场景等。况且,视觉不作为主里程计,作为辅助里程计而言依然是堪当大任的。另外对于激光与视觉之争我在文末还会有一段我的论述,请读者耐心观看。
 晚宴里的一个小插曲,高博抽到了三等奖,可惜人不在场,一等奖是紫川Viobot哦
晚宴里的一个小插曲,高博抽到了三等奖,可惜人不在场,一等奖是紫川Viobot哦
由于篇幅太长,各位看官稍作休息,下一篇更精彩。
参考:
1.都传统方法了还不看《视觉slam十四讲》P150?
2.SuperGlue论文链接 https://arxiv.org/abs/1911.11763
3.SuperPoint论文链接 https://arxiv.org/abs/1712.07629
4.LoFTR链接 https://arxiv.org/abs/2104.00680
5.项目主页 https://zju3dv.github.io/DetectorFreeSfM/
6.droid-slam链接 https://papers
—END—高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。[三维重建方向]NeRF、colmap、OpenMVS等。除了这些,还有求职、硬件选型、视觉产品落地等交流群。大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
工业3D视觉方向课程:
[1](第二期)从零搭建一套结构光3D重建系统[理论+源码+实践]
SLAM方向课程:
[1]如何高效学习基于LeGo-LOAM框架的激光SLAM?
[2]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[3](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[4]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[5]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建
[1]彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进)
自动驾驶方向课程:
[1] 深度剖析面向自动驾驶领域的车载传感器空间同步(标定)
[2]面向自动驾驶领域目标检测中的视觉Transformer

















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









