






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0. 这篇文章干了啥?
单目深度估计从单张图像中推断出深度图。这是计算机视觉中的一项重要任务,在增强现实/虚拟现实(AR/VR)、自动驾驶和三维重建等领域有着广泛的应用。大多数方法通过从立体摄像机或激光雷达(LiDAR)收集的真实数据来监督模型。最近,自监督深度估计因其能够从海量未标记的RGB视频中扩展深度学习的潜力而备受关注。
经典的运动恢复结构(SfM)方法也从未标记的RGB视频中重建场景深度。尽管与之相关,但SfM很少被应用于自监督深度学习中。我们概述了两个可能的原因。首先,SfM是一种现成的算法,与深度估计器无关。尺度模糊性使得SfM的位姿和深度与深度模型的尺度不同。其次,自监督学习具有明确定义的训练方案,可以与通用的未标记视频一起工作。它通过计算相邻帧内的光度损失进行反向传播,如图1中的红色轨迹所示。相比之下,SfM对输入视频的选择性更强。它需要具有不同视图变化的图像(如图1中的绿色轨迹所示),当应用于小帧窗口时,其准确性和稳定性较差。

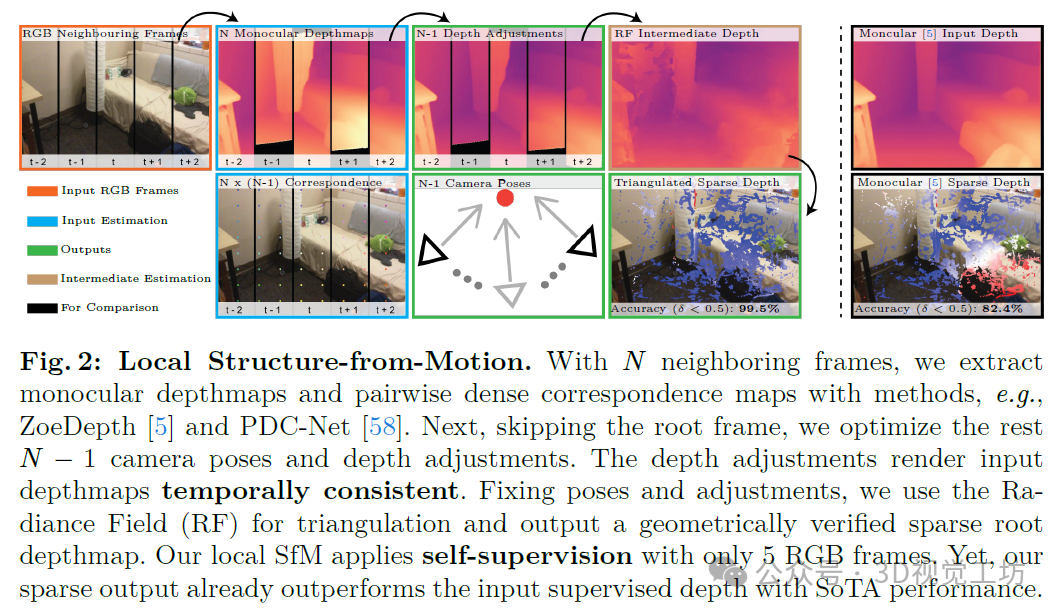
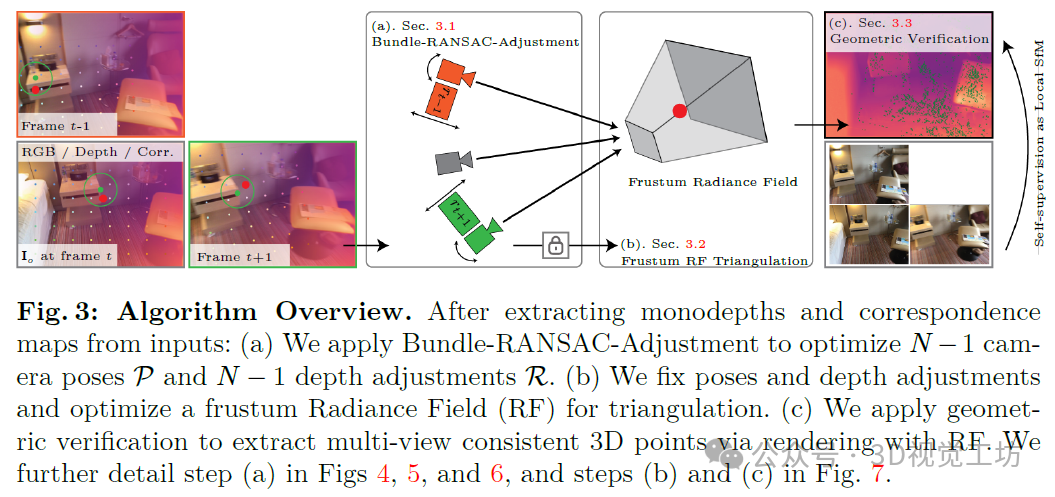
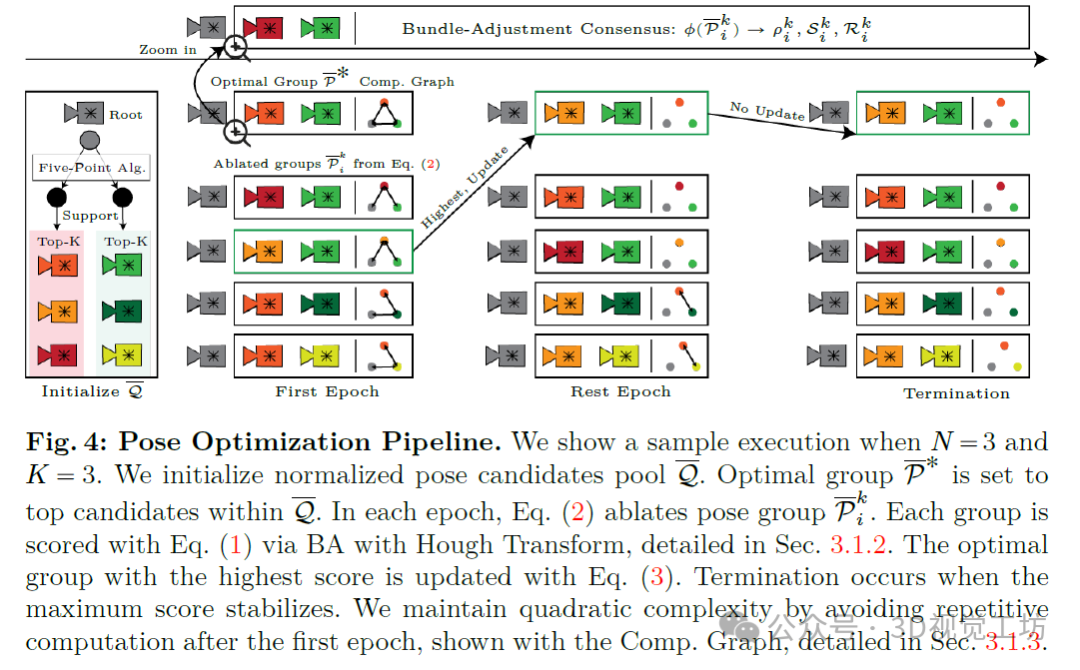
这项工作将自监督与运动恢复结构(SfM)相结合。我们用完整的SfM流程替换了自监督损失,该流程保持了对局部窗口的鲁棒性。如图2所示,以N帧作为输入,我们的算法输出了N-1个相机位姿、N-1个深度调整以及稀疏三角化点云。在初始化阶段,我们推断出N个单目深度图和N个(N-1)对对应关系图。接下来,我们提出了一种Bundle-RANSAC-Adjustment位姿估计算法,该算法保持了长达两秒视频的准确性。该算法利用来自单目深度图的3D先验信息来补偿相机视图的不足。相应地,我们优化了N-1个深度调整,以通过时间对齐到根帧深度来缓解深度尺度模糊性。Bundle-RANSAC-Adjustment将两视图RANSAC扩展到多视图束调整(BA)。该算法具有二次复杂度,设计用于并行GPU计算。我们随机采样并假设一组归一化位姿。在一致性检查中,我们应用BA来评估多视图图像上的鲁棒内点计数评分函数。在BA过程中确定相机尺度和深度调整,以最大化评分函数。
接下来,我们固定优化后的位姿,并采用辐射场(RF),即没有神经网络的NeRFF[40],来进行三角测量。我们优化RF以在共享的3D视锥体内实现多视角深度图和对应一致性。对于输出,我们应用几何验证来提取多视角一致的点云,即稀疏的根深度图。
图1将我们的方法与先前的自监督深度估计和运动恢复结构(SfM)方法进行了对比。据我们所知,尚未有先前的工作显示基于几何的自监督深度估计对监督模型有益。然而,自监督学习理应通过未标记数据来增强监督模型。在图2中,我们独特的流程给出了首个明显的结果,即仅使用5帧的自监督学习就已经对监督模型产生了积极影响。
除了深度估计外,我们的多视角RANSAC位姿在稳健的评分函数下证明了其全局最优性。它在基于优化的、基于学习的和基于NeRF的位姿算法中均表现优异。除了位姿和深度估计外,我们的方法还具有多种应用。我们的深度调整方法提供了经验上一致的深度图,这对于AR图像合成至关重要。在给定RGB-D输入的情况下,我们的方法能够实现自监督对应估计。我们准确的位姿估计提供了比最先进的监督对应输入更好的投影对应。
下面一起来阅读一下这项工作~
1. 论文信息
标题:Revisit Self-supervised Depth Estimation with Local Structure-from-Motion
作者:Shengjie Zhu, Xiaoming Liu
机构:Michigan State University
原文链接:https://arxiv.org/abs/2407.19166
2. 摘要
自监督深度估计和结构从运动恢复(Structure-from-Motion,SfM)均从RGB视频中恢复场景深度。尽管它们的目标相似,但这两种方法并不相关。自监督的先前工作通过反向传播相邻帧内定义的损失。与通过损失进行学习不同,本工作提出了一种通过执行局部SfM的替代方案。首先,使用校准后的RGB或RGB-D图像,我们采用深度和对应估计器来推断深度图和成对对应图。然后,一种新颖的bundle-RANSAC调整算法联合优化相机姿态和每个深度图的深度调整。最后,我们固定相机姿态,并使用神经辐射场(Neural Radiance Field,NeRF),但不使用神经网络,进行密集三角剖分和几何验证。相机姿态、深度调整和三角剖分稀疏深度是我们的输出。我们首次证明,在5帧内的自监督已经有利于最先进的监督深度和对应模型。
3. 主要贡献
我们总结了我们的贡献如下:
我们提出了一种新颖的带有Bundle-RANSAC-Adjustment的局部SfM算法。
我们首次展示了显著的结果,即使用少至5帧的自监督深度已经对最先进的监督模型产生了益处。
我们实现了最先进的稀疏视图位姿估计性能。
我们实现了自监督的时间一致深度图。
我们实现了使用5个RGB-D帧的自监督对应关系估计。
4. 基本原理是啥?
我们的方法是顺序运行的。从N张校准图像I中,我们提取出N个单目深度图D和N-1对密集对应关系C。我们将N张图像分为位于N帧窗口中心的1个根帧Io(其中o为tN-1到u的索引)和N-1个支撑帧Ii(其中i属于N-1的集合,即{1, ..., N-1, N+1, ..., u})。将根帧设置为恒等姿态后,我们使用Bundle-RANSAC-Adjustment来优化N-1个姿态P和N-1个深度调整R。接下来,我们通过优化视锥体辐射场(RF)V(即没有网络的NeRF)来进行三角测量。最后,我们通过从RF中渲染出多视角一致的3D点来进行几何验证。图3给出了一个概览。
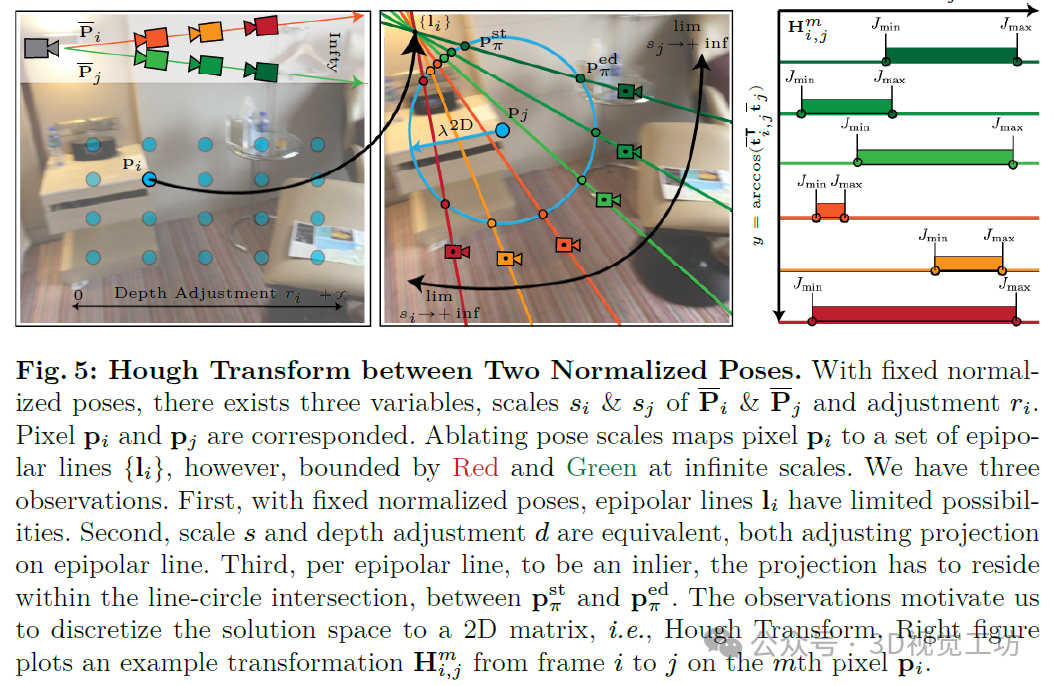
5. 实验结果
在表1中,我们的点云密度为2.6%至9.1%,这相当于在480x640的图像上有10至30k个点。在准确性方面,我们对两个数据集的所有监督模型都有了一致性的提升。特别是,我们在ScanNet上的ZoeDepth和KITTI360上的Metric3D这两个强基线模型上表现更佳。
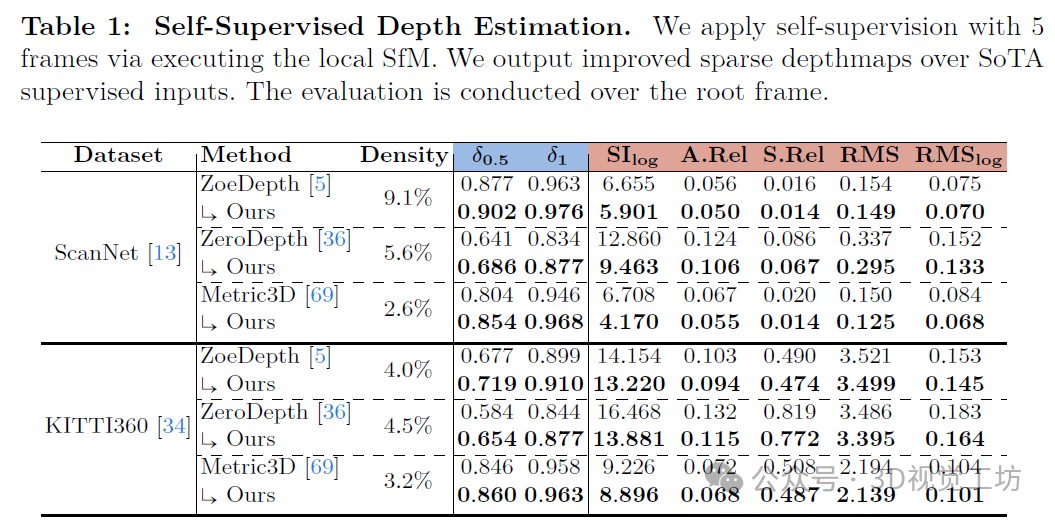
我们在ScanNet上进行了评估。时间一致的深度对于增强现实(AR)应用至关重要。表2反映了通过调整将支持帧与根帧对齐所获得的性能提升,这些调整与相机姿态是联合估计的,如图2和图3所示。
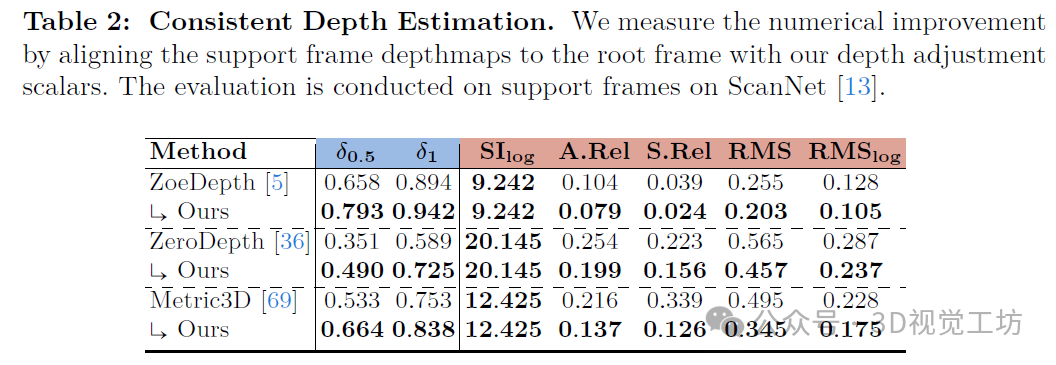
与基于优化和基于学习的姿态估计的比较。以往的研究要么评估两视图姿态,要么评估类似SLAM的里程计。在表4中,LightedDepth和我们的方法都使用了PDC-Net对应关系和ZoeDepth单目深度。COLMAP也使用了PDC-Net对应关系。在评估时,我们将预测的姿态与真实姿态(GT poses)进行对齐。在表4中,我们的零样本姿态精度显著优于所有先前技术,包括在ScanNet或ScanNet++训练集上训练的。
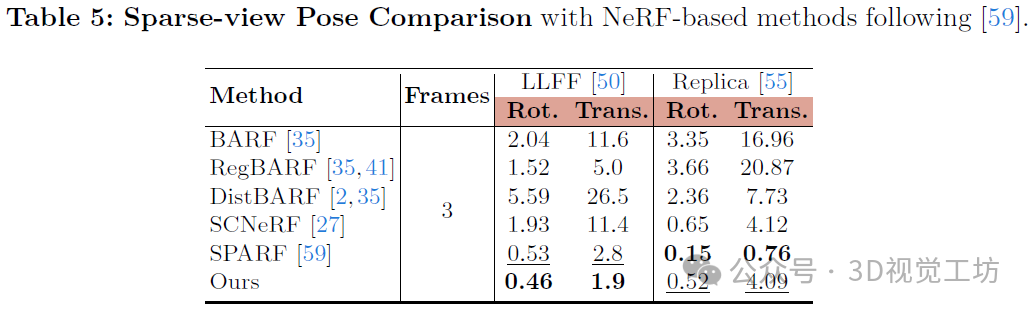
与基于NeRF的姿态估计的比较。稀疏视图NeRF方法将NeRF与相机姿态联合优化,这需要复杂且耗时的优化方案。例如,SPARF需要一天的时间来优化姿态和NeRF。通常,它们的姿态是用COLMAP进行初始化的。我们的方法提供了一种具有优越性能的替代初始化方案。在表5中,我们的初始化方法在姿态性能上优于或相当于当前最优方法,而我们的方法仅需要约3分钟。我们在Replica数据集上的性能较低可能是因为ZoeDepth没有在合成数据上进行训练。我们的工作表明,简单的“先姿态后NeRF”方案也适用于短视频。推荐学习:[第二期]彻底搞透视觉三维重建:原理剖析、代码讲解、优化改进
6. 总结 & 局限性
通过利用局部SfM进行自监督学习,我们首次展示了仅使用5帧图像的自监督深度估计就能超越当前最优的(State-of-the-Art, SoTA)监督模型。我们的方法在稀疏视图姿态估计上达到了当前最优的精度,适用于神经辐射场(Neural Radiance Field, NeRF)渲染。此外,我们的方法具有多种应用,包括自监督对应关系和一致深度估计。
然而,该方法也存在局限性。类似于NeRF的三角测量法限制了我们的方法在大规模自监督学习中的应用。其效率还有待提高。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

具身智能、3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉模组选型:www.3dcver.com

— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~


















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









