





这几年,自动驾驶的技术流派可谓“神仙打架”:从早期的一体化端到端,到火遍全网的 VLA,再到如今炙手可热的世界模型(World Model),几乎每一家做自动驾驶的公司,都在强调自己那条“独一份”的技术路线。
但如果把这些名词的“包装”撕开,会发现一个很朴素的共性——
不管叫“一段式端到端”、VLA,还是 WA(World Model–Action),
本质上都是在做同一件事:用数据驱动的方式,把传感器的感知输入,转换成车辆的控制信号。
遗憾的是,目前大多数自动驾驶综述在梳理技术路线时,往往把端到端和 VLA 当成两条平行、割裂的路线来讲,很少从统一视角去对比分析。
这就导致一个问题:研究者很难在同一坐标系下,同时看清“传统端到端”和“VLA 范式”之间到底有何本质差异、又在哪些方面殊途同归。
为了解决这个认知断层,上海交通大学 AutoLab 团队联合滴滴,参考了 200 余篇相关工作,撰写了最新综述《广义端到端自动驾驶的综述:统一视角》。
论文中,作者提出了“广义端到端”(GE2E)的概念:只要是通过一个整体模型,将原始传感器输入直接映射为规划轨迹或控制动作的方式,都可以被视为 GE2E——至于中间架构是否引入视觉语言大模型,并不是本质区分。
在这一统一框架下,论文把三类看似分散的技术路线收拢到了一张图谱中:
传统端到端(Conventional E2E),
以视觉语言模型为核心的端到端(VLM-centric E2E),
以及两者深度融合的混合式端到端(Hybrid E2E)。
由此构建出一套相对完整、可对比的技术版图,为后来者提供了一个更清晰的“总览视角”。
🧭 1. 引言:从模块化到“通用端到端”
自动驾驶(Autonomous Driving, AD)是一项极其复杂的任务,需要车辆在真实道路环境中进行精确感知、合理预测、可靠规划与安全控制。传统自动驾驶大多采用模块化架构:
感知(检测车、人、灯、路等)
预测(预测其它交通体的未来运动)
规划与控制(生成自车轨迹和控制指令)
这些模块分别设计、分别训练,再通过工程手段组合成一个完整系统。这种方式的优点是可解释、易调试,工程上成熟;但也存在结构性缺陷:
模块之间信息割裂,中间结果丢失细节
误差在流水线上逐级放大(Error Propagation)
各模块优化目标不统一,整体性能受限
随着大规模驾驶数据和深度学习的发展,学界和工业界开始转向端到端(End-to-End, E2E)自动驾驶:直接从传感器输入(图像、激光雷达、导航信息等)预测车辆未来轨迹或控制信号。
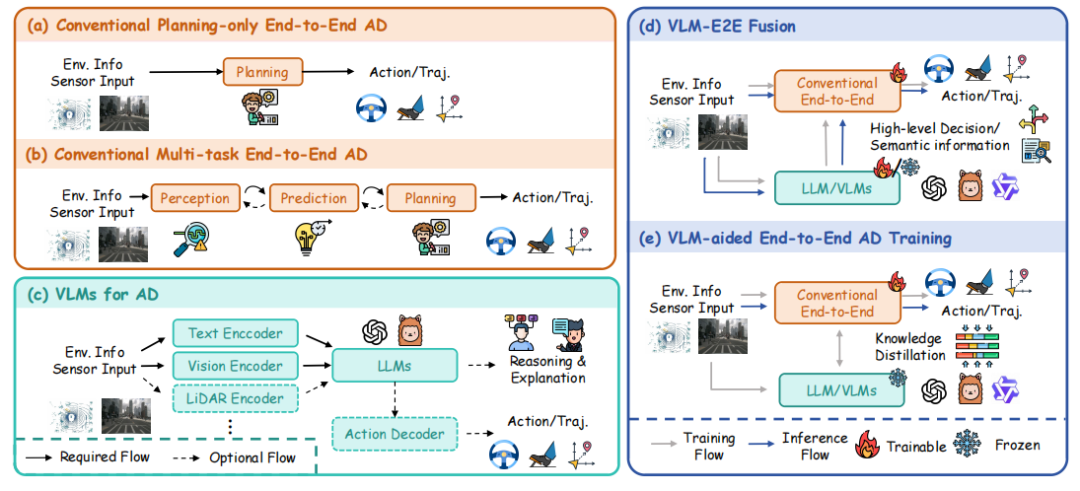
近几年,端到端自动驾驶发展出了三条看似不同、实则内在统一的技术路线,如上图:
传统端到端(Conventional E2E)
基于视觉/激光雷达,学习结构化场景表示(如 BEV 占据栅格、向量化地图、对象轨迹等),在统一网络中联合感知、预测和规划。
VLM 中心范式(VLM-centric E2E)
以大规模视觉语言模型(VLM / VLA)为核心,将驾驶问题转化为“语言空间中的推理与决策”,由大模型提供高层认知与解释能力。
混合范式(Hybrid E2E)
将传统端到端系统的精确、安全与高效率,与 VLM 的开放世界知识与强泛化能力结合起来。
本文提出一个统一概念:General End-to-End Autonomous Driving(GE2E)通用端到端自动驾驶
——只要系统从原始传感输入出发,通过一个整体模型,直接输出规划轨迹或控制信号,无论中间是否显式使用 VLM,都属于 GE2E 范畴。在这个统一视角下,本文系统梳理:
三大范式的典型架构与设计哲学
主流数据集与评测基准
各类方法在开放/闭环指标上的性能对比
共性挑战与未来技术趋势
为了方便读者阅读,作者绘制了以下思维导图,展示了全文的脉络:
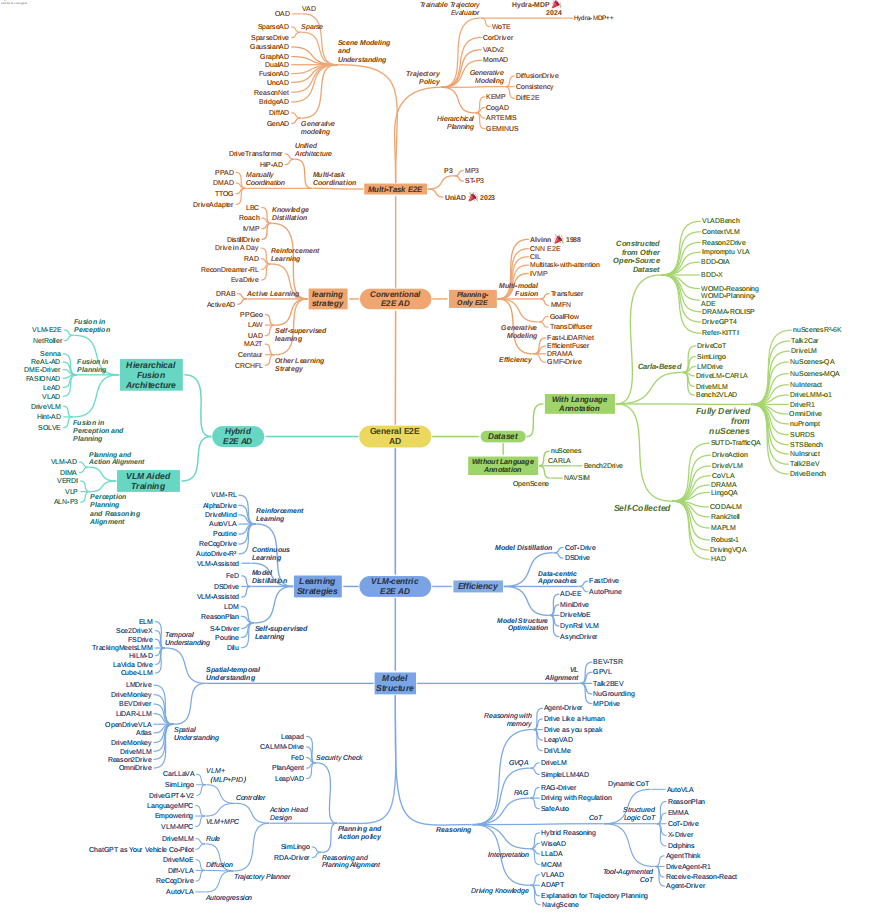
图 2 GE2E全文脉络 🔍 2. 传统端到端自动驾驶
传统端到端方法,希望在统一模型中联合优化感知、预测、规划,避免模块化带来的信息损失与误差累积。根据是否显式设计中间任务,主要可分为:
仅规划端到端(Planning-only E2E)
多任务端到端(Multi-task E2E)
此外,在学习策略上,多数方法以模仿学习为主,也开始融入知识蒸馏、强化学习、自监督、主动学习等手段。
2.1 仅规划端到端(Planning-only E2E)
早期 E2E 模型较为简洁,只包含一个从图像 → 控制信号的网络,例如:
ALVINN:三层小型网络,从摄像头+激光输入预测转向角
NVIDIA CNN E2E:从前向摄像头图像直接预测方向盘转角
此类方法有明显优势:结构极简、易部署。但很快暴露出局限:3D 场景理解能力不足、决策缺乏多样性、解释性差。后续研究在三个方向上演进:
(1)多模态融合:增强 3D 场景理解
单摄像头难以充分获取空间信息,因此出现多模态融合方法:
TransFuser:利用 Transformer 融合图像与激光雷达
MMFN:进一步融合摄像头、雷达、HD Map 等
通过更丰富的 3D 信息,规划结果更安全、鲁棒性更高。
(2)生成式建模:应对轨迹多模态性
现实中,同一场景往往存在多种合理驾驶行为: 例如前车缓慢行驶时,可以减速跟车,也可以安全变道。
传统回归式预测会产生“平均轨迹”(既不跟车也不果断变道,反而不安全)。因此,出现基于生成模型的规划:
使用扩散模型 / Flow Matching等对轨迹分布进行建模
例如:
GoalFlow:先预测目标点,再在约束下生成多模态轨迹
TransDiffuser / DiffusionDrive / DiffAD 等:将规划视为条件轨迹生成问题
这样可以显式建模“多种备选动作”,并在其上进行选择。
(3)效率优化:面向车载部署
真实车辆上计算资源有限,延迟受安全约束较为严格。为此,一些工作专注于效率:
Fast-LiDARNet:针对激光雷达进行高效建模和硬件友好优化
EfficientFuser:用轻量化 EfficientViT 提高融合效率
DRAMA、GMF-Drive、MambaFusion:使用 Mamba 等结构降低时序建模复杂度
这类方法在保持性能的同时,显著降低了延迟和算力开销。
纯规划端到端的固有缺陷
尽管在工程上简洁,规划-only E2E 有两大结构性问题:
解释性差(Black-box)
直接从原始输入到轨迹,不输出中间结构化结果
出错时很难定位“是感知错了、预测错了,还是规划策略有问题”
监督信号稀疏
只使用最终轨迹监督,未利用丰富的 3D 标注(检测、分割、预测等)
模型难以学到真正的“驾驶因果逻辑”,容易出现安全隐患
因此,最新的主流研究逐渐转向多任务端到端架构。
2.2 多任务端到端(Multi-task E2E)
多任务 E2E 将感知、预测、规划 显式建模为多个子任务,但不再作为完全独立模块,而是在统一框架中联合优化。
研究主要聚焦三个问题(可以对应理解为三层能力):
场景建模与理解(Scene Modeling & Understanding)
多任务协同(Multi-task Coordination)
轨迹规划策略(Trajectory Policy)
2.2.1 场景建模与理解
目标:构建对自动驾驶友好的高效、全局、时序感知的场景表示。
unsetunset(1)高效场景表示unsetunset
早期方法(如 UniAD、P3 系列)多采用稠密 BEV 栅格表示:
优点:结构直观,便于统一对接下游任务
缺点:计算量大、实例级结构信息弱(物体边界、关系不够明确)
因此,出现了更稀疏、实例化的表示:
VAD:向量化表示关键场景元素(车道线、边界等),减少占据图的冗余
SparseAD / SparseDrive:直接对 BEV 上的对象实例建模,不再构建全局稠密 BEV
GaussianAD:用 3D 语义高斯云表征场景,实现“稠密语义 + 稀疏结构”兼具
核心思想:
不再把整张 BEV 当图片处理,而是把“有用的对象”提炼出来,节省算力并提升决策针对性。
unsetunset(2)空间理解与推理unsetunset
安全驾驶不仅需要知道“有什么”,还需要理解“谁和谁之间在互动、有什么约束”:
GraphAD:用图结构建模“车–车”、“车–路”之间关系
DualAD:将动态目标与静态地图的建模解耦,分别优化
FusionAD:融合 LiDAR + Camera 提升空间几何理解
UncAD:显式建模环境不确定性,利用不确定度指导预测与规划,增强长尾场景的鲁棒性
unsetunset(3)时间融合与时序推理unsetunset
除了空间,需要理解动态变化:
传统:多帧特征叠加,对齐再融合(如 BEVFormer 系列)
新方法:
ReasonNet:用长期记忆库 + Transformer 对历史信息进行全局推理
BridgeAD:显式对齐历史轨迹信息与当前时刻
GenAD / DiffAD:将“场景演化 + 预测 + 规划”统一为生成任务(例如生成未来 BEV 图像)
目标:
不只知道“现在是什么样子”,还要综合历史判断“将会发生什么”。
2.2.2 多任务协同(Task Coordination)
多任务 E2E 的优势在于:不同任务间可以互相“借力”。
早期多任务框架中,任务通常是按固定顺序串行执行(感知→预测→规划),任务间交互有限。后续研究主要探索两类协同方式:
(1)人工设计协同结构
根据任务之间的关系,重新设计任务组织方式,例如:
PPAD:将预测与规划交替执行,体现“自车规划会影响他车运动”的交互逻辑
TTOG:融合运动预测与规划,使规划可以直接从行为数据中获益
DriveAdapter:用 adapter 解耦感知 & 规划,避免传统行为克隆中“因果混淆”问题
DMAD:将语义学习与运动学习分离,减少负迁移,强化有益迁移
(2)统一多任务架构
另一条路线是:让网络自己学“谁影响谁”,不人为规定顺序:
DriveTransformer / HiP-AD:
将感知、预测、规划的 Query 放入一个统一模块中交互
每个任务的 Query 既与图像/雷达交互,也与其它任务 Query 和历史 Query 交互
最后通过任务专用 head 输出各自结果
这种架构便于扩展更多任务(如地图构建、行为解释),也更利于大规模训练与统一优化。
2.2.3 轨迹规划策略(Trajectory Policy)
即“如何生成安全、舒适、符合法规的轨迹”。在简单模仿学习的基础上,出现了几种重要思路:
(1)后处理优化
如 UniAD:先预测占据,再通过数值优化(牛顿法等)在占据约束下修正轨迹
优点:可利用 3D 几何信息进一步提高安全性
缺点:
破坏端到端的一体性
优化器本身不可学习,上限有限
依赖感知质量,错误会放大
因此出现了可微优化思路:把后处理写成可微层,合并进训练中,让优化过程也被学习。
(2)可训练轨迹评估器(候选选择)
另一类做法:先生成一批候选轨迹,再通过可学习评估器选择最优:
使用聚类等方法离线构建“轨迹词典”
模型从有限词典中选轨迹 ID,或在其基础上稍作修正
如:
Hydra-MDP / Hydra-MDP++:多头解码器预测多种候选,配合多指标评估
WoTE / World4Drive:基于世界模型预测未来环境状态,对轨迹进行前瞻性评估
这类方法兼顾可解释性与端到端训练能力。
(3)概率规划与扩散策略
针对“规划多模态性”的问题,除了生成模型,还可以在输出层直接预测概率分布:
VADv2:预测概率分布,并从中采样动作,显著提升闭环表现
DiffusionDrive / DiffAD / DiffE2E / Consistency 等:
将规划建模为扩散/一致性模型中的条件生成任务
面临的核心问题是:如何保证实时性
例如:DiffusionDrive 通过“截断扩散”大幅减少步骤,在 4090 上达 45FPS
(4)分层/层级规划
一部分研究认为“一次性生成全轨迹”难以适应环境动态变化,因此采用分层策略:
先生成高层意图(如 keyframe、意图路线),再细化为高频轨迹
代表方法:
KEMP:基于关键帧的分层预测
ThinkTwice:多解码器堆叠,利用空间–时间先验迭代细化
CogAD:粗到细的认知式规划(意图 → 精细轨迹)
ARTEMIS:自回归逐点输出,强时间依赖、鲁棒性高
2.3 学习策略:超越“纯模仿”的几条路
绝大多数 E2E 方法都基于行为克隆 / 模仿学习。但单纯模仿存在:
对长尾和危险场景泛化差
容易发生 Covariate Shift(偏离专家分布后不断累积错误)
因此,许多工作开始探索更丰富的学习策略。
2.3.1 知识蒸馏(Knowledge Distillation)
利用“特权教师” → “普通学生”的范式:
教师有额外信息或更强模型能力(如访问真值状态、使用强化学习训练)
学生模型则是车辆部署时实际使用的端到端网络
典型工作:
LBC:教师直接访问环境真值,学生只用视觉输入,通过蒸馏获得更强能力
Roach:RL 训练的特权 Agent 生成高质量轨迹,给 E2E 学生做监督
IVMP / DistillDrive:蒸馏多模态规划模型(包含光流、语义地图等中间任务)的表示
目标:弥补端到端模仿学习中监督信号的稀疏性与偏差。
2.3.2 强化学习(Reinforcement Learning, RL)
RL 能通过与环境交互获得新体验,对长尾场景与多目标优化尤其有价值:
Drive in a Day:早期将端到端驾驶建模为 MDP,用深度 RL 训练
RDMF / SAPO-RM:利用不确定度或安全约束(如控制屏障函数)指导探索,减少危险试错
RAD / ReconDreamer-RL / EvaDrive:
结合高保真 3D 场景重建 / 视频生成构建“虚拟世界”做 RL
以 3D Gaussian Splatting / Diffusion 等技术生成大量复杂场景
在此基础上做闭环强化,降低真实世界试错开销
2.3.3 自监督学习(Self-supervised Learning)
目标:大量无标注驾驶数据中挖掘规律,降低昂贵 3D 标注依赖:
PPGeo:先做几何自监督,再做策略预训练,少量标注即可适配多任务
LAW:训练“潜在世界模型”,自监督预测未来,提升场景表示与轨迹预测
UAD:只用 2D 无监督任务替代依赖 3D 标注的模块,在零 3D 标注下超过多种 SOTA
2.3.4 主动学习(Active Learning)
应对 covariate shift 的经典方法是 DAgger,但简单“采样+标注+混合训练”容易退化。
DARB:指出关键在于“样本质量”而非“数量”,提出关键状态采样——优先标注最信息量、更危险的状态
ActiveAD / SEAD:从数据多样性、场景信息、BEV 特征等角度设计样本选择策略,在少量标注下逼近甚至匹配全数据性能
2.3.5 其他策略
一些工作从鲁棒性与实用性出发,引入了更多训练机制:
对抗训练(如 MA2T):提升模型对恶意干扰的鲁棒性
测试时训练(TTT)(Centaur):部署时自适应修正
分层联邦学习(CRCHFL):面向车队与边缘计算场景的分布式训练
🧠 3. VLM 驱动的“认知型”端到端驾驶
传统端到端系统在开放世界理解和复杂推理上存在“天花板”:
假设封闭世界:只能识别预定义类别,难以应对新颖/长尾事件
结构上仍是“感知–预测–规划”流水线,不具备统一、可语言化的世界模型与因果推理能力
为弥补这一本质认知差距,近年兴起一类以大规模视觉语言模型(VLM)为核心的范式:
把自动驾驶 Agent 看作一个“认知体”:
能看(视觉编码)
能想(语言推理 + 场景建模)
能说(解释决策)
还能驱动规划模块完成精细控制
这一类方法通常采用类似结构(可理解为通用 VLM / VLA 框架的驾驶特化版):
视觉编码器 + 文本编码器
跨模态对齐模块(将视觉特征映射到语言空间)
大语言模型(LLM)作为“中枢大脑”
动作头(Action Head)或轨迹规划器输出驾驶行为
下面从架构、学习策略与效率优化三个层面,概述这一范式的关键设计。
3.1 模型结构
3.1.1 视觉–语言对齐(Vision–Language Alignment)
核心任务:将高维视觉特征转为 LLM 可以理解的“语义 token”。
两种主流路线:
直接投影(MLP / 线性层)
将视觉特征直接映射到 LLM 的嵌入空间
结构简单,诸多工作采用(DriveMLM、DriveGPT4v2、DriveMoE 等)
基于 Query 的压缩(如 Q-Former)
使用少数可学习 Query 向量,从视觉特征中“提取精华”
节省 token 数量,提升效率
此外,针对自动驾驶的空间特性,出现了任务定制化对齐方法:
BEV-TSR / GPVL:通过检索或 3D 任务预训练,对齐 BEV 特征与文本描述
MPDrive:避免让 LLM直接生成复杂坐标,改用可视化标记简化空间表述
Prompting Multi-Modal Tokens / Driving with LLMs:将 LiDAR 点云、向量化轨迹等结构化数据,以“伪 token”或“向量描述”形式输入 LLM
3.1.2 时空理解(Spatiotemporal Understanding)
自动驾驶是“四维问题”:3D 空间 + 时间。
unsetunset(1)增强 3D 空间理解unsetunset
几类典型思路:
显式 3D 建模:
OmniDrive:加入显式 3D 位置编码
Atlas:用 DETR 式结构直接 token 化 3D 场景
S4-Driver:用稀疏体素将多视角 2D 特征投影到 3D
多模态 3D 融合:
LiDAR-LLM、DriveMLM、LMDrive、BEVDriver 等,将 LiDAR 点云与图像融合提升几何准确性
对象中心先验:
Reason2Drive、MPDrive、DriveMonkey 等,将物体与空间关系结构化输入 VLM,提高对复杂交通互动的理解
隐式 3D:靠数据规模“涌现”
Cube-LLM 等工作尝试依靠大规模多视角数据,让模型自发习得 3D 直觉
unsetunset(2)时间维度建模unsetunset
Sce2DriveX、LaVida Drive:使用长时间视频片段 + BEV 全局信息,学习长时程交通事件
TrackingMeetsLMM:引入目标跟踪信息,为每个动态体建立时间连续的轨迹
ORION:设计基于 Query 的时间记忆模块(QT-Former),从历史帧中取出重要上下文
3.1.3 推理能力(Reasoning)
VLM 的真正价值,在于推理与解释,不仅是识别。
unsetunset(1)记忆增强推理unsetunset
长时记忆:
Drive Like a Human、DiLu、LeapVAD、LeapAD、Drive as You Speak 等
把“过去的驾驶经历、用户偏好、规则”存入记忆库,供未来决策参考
短时记忆:
Agent-Driver、DriVLMe 等,用记忆保持多轮交互的上下文,保证“前后说法一致、行动连续”
unsetunset(2)链式思维(Chain-of-Thought, CoT)unsetunset
将复杂决策拆解为有逻辑顺序的子步骤:
结构化逻辑 CoT:Dolphins、CoT-Drive、ReasonPlan、X-Driver、EMMA
时空 CoT:FSDrive 强调对“未来若干帧”进行逐步视觉推演
工具增强 CoT:Agent-Driver、AgentThink、Receive-Reason-React、DriveAgent-R1
动态 CoT:AutoVLA,能根据任务难度决定要不要“多想几步”
自反思 CoT:AutoDrive-R²,模型对自己的推理结果做自我审查
unsetunset(3)图式视觉问答(GVQA)unsetunset
将驾驶问题拆解为“对场景图的一系列问答”:
DriveLM、SimpleLLM4AD 等:
先构建场景图(对象及其关系)
再以问答链形式,按“感知→预测→规划”顺序推理
使决策过程更透明、可检查
unsetunset(4)检索增强生成(RAG)unsetunset
用外部知识库弥补单一参数模型的知识边界:
RAG-Driver:从历史驾驶案例中检索相似情况
Driving with Regulation:检索相关交通法规,辅助判定何种行为合规
unsetunset(5)嵌入驾驶知识unsetunset
Hybrid Reasoning、WiseAD 等,通过加入交通规则、物理约束等,提升安全性与可依赖性
unsetunset(6)面向可解释性的推理unsetunset
VLAAD、ADAPT、Explanation for Trajectory Planning 等,专门训练模型输出语言解释 + 行为,并保证两者一致性
3.1.4 行为与规划策略(Planning & Action Head)
VLM 输出的“高层决策”要落地为精确执行,常见有两类接口设计:
unsetunset(1)VLM + 控制器unsetunset
VLM + MLP + PID:如 LMDrive、CarLLaVA、SimLingo、DriveGPT4-v2
VLM + MPC:LanguageMPC、VLM-MPC
Empowering:让 LLM 输出安全约束,MPC 负责求解;再把 MPC 的可行性反馈给 LLM,形成闭环
unsetunset(2)VLM + 轨迹规划器unsetunset
规则式规划:DriveMLM、ChatGPT as Co-Pilot 等,用 VLM 决定高层策略,规则模块生成具体轨迹
生成式轨迹规划:DriveMoE、Diff-VLA、ReCogDrive 等,利用扩散或生成模型生成多条候选轨迹
unsetunset安全校验机制unsetunset
为缓解 VLM“幻觉”与不确定性,通常会在执行前增加安全检查:
事后验证/优化:
CALMM-Drive:多候选方案 + 分层筛选
PlanAgent:使用模拟评估轨迹安全性
LeapAD / LeapVAD:通过记忆与反思修正行为
训练阶段嵌入反馈:
FeD:引入语言化反馈,引导模型逐步纠正行为
unsetunset推理与规划对齐unsetunset
一个核心问题:解释逻辑(CoT)与最终行为是否一致?
SimLingo:引入语言–动作对齐机制
RDA-Driver:用对比学习让“正确行为–合理解释”成为正对,其他为负对
ORION:使用统一潜在空间,让推理结果可以直接指导轨迹生成,实现语义空间与数值空间的深度对齐
3.2 学习策略(VLM 场景)
与传统 E2E 类似,VLM 场景中也广泛使用:
知识蒸馏:FeD、VLM-assisted 等
强化学习:AlphaDrive、Poutine、ReCogDrive、AutoVLA 等
数据高效学习:LDM、ReasonPlan、S4-Driver 等通过自监督及少量标注获得接近全监督性能
3.3 效率问题与优化思路
VLM / VLA 能力强,但大而慢是现实约束。优化路径大致三条:
模型蒸馏:如 CoT-Drive、DSDrive,把大模型的推理能力压缩到小模型
架构优化:
早退(AD-EE)、动态分辨率(DynRsl-VLM)、MoE(DriveMoE)
异步推理(AsyncDriver):让规划高频运行,LLM 低频决策
数据与 Token 优化:
结构化表达(FastDrive、ReCogDrive、Senna、VERDI 等)
Token Pruning(AutoPrune 等)
🔗 4. VLM × 传统 E2E:混合范式
传统 E2E 像一个反应迅速、动作精准的“身体”,但在开放世界理解和复杂推理上有限;
VLM 像一个知识丰富、善于推理的“头脑”,但在数值控制与实时性能方面存在“行动鸿沟”。混合范式就是在两者之间搭建“认知–执行桥梁”。
主要有两大技术路线:
在线协同(Online Coordination):VLM 在推理时参与决策
离线知识迁移(VLM-Aided Training):VLM 只在训练时做“老师”,推理时只保留高效 E2E 模型
4.1 在线协同:分层融合架构
整体思路:
VLM 负责“想清楚干什么”,E2E 负责“怎么精细完成”。
融合位置主要有三种:
4.1.1 感知层融合
目标:利用 VLM 的语义能力,增强 E2E 感知模块的语义与注意力。
VLM-E2E:用 VLM 生成与驾驶相关的文本提示,将其与 BEV 特征融合
NetRoller:提出“即时首 token 全层获取”机制,快速获取 VLM 中间层信息,提高融合实时性
核心挑战在于:
如何在不大幅增加延迟的前提下,将 VLM 的高维、长时语义有效注入到 E2E 的高频感知流程中?
4.1.2 规划层融合
目前最常见的方式 —— VLM 输出高层命令/策略,E2E 负责输出实际轨迹。
代表工作:
DriveVLM / Senna:VLM 生成高层指令(meta-action,如“变道超车”),下游规划器条件化生成轨迹
DME-Driver:引入人类决策逻辑
FASIONAD:启发自《快思慢想》,设计快/慢两种思考模式
VLAD / LeAD:在系统架构和更新节奏上做进一步优化(如多时钟频率)
4.1.3 感知 + 规划协同融合
进一步的工作尝试实现“双向信息流与架构共享”:
DriveVLM:感知输出由 VLM 进行语义校验,VLM 提供的“建议轨迹”反哺规划模块
SOLVE:共享视觉编码器,VLM 对规划模块进行“初始化与指导”
Hint-AD:将 E2E 的中间结果输入到 VLM,生成对齐解释,使整体系统更可解释
可以看到,混合架构正从“简单串联”向“深度耦合、互相依赖”演化。
4.2 离线知识迁移:VLM 辅助训练
这种方法的特点是:
训练阶段:使用 VLM 作为“教师”,提供额外监督信号(高层动作、语言解释、链式推理等)
推理阶段:仅保留传统 E2E 模型,不引入任何 VLM 计算
优点:
不增加部署复杂度和延迟
能将 VLM 的认知能力“固化”到 E2E 模型参数中
缺点:
性能受限于 Teacher VLM 的知识覆盖和 Student 的容量
如何保证蒸馏后的策略在开放世界中仍然可靠,仍是难题
4.2.1 规划与动作对齐
代表工作:
VLM-AD:让 VLM 生成结构化动作标签(如转弯、变道),作为附加标签监督 E2E 模型
DIMA:将学生模型的潜在表示对齐到“教师模型理解下的结构化空间”
本质是:
让 E2E 模型内部表示“带上语言语义”,使其决策更加可解释、行为更加稳定。
4.2.2 感知–预测–规划全链路对齐
更进一步的方法希望对整个决策链条进行对齐:
VERDI:用 VLM 的推理链对感知、预测、规划的中间特征分别施加监督
VLP:对齐 BEV 表征与“理想 BEV 表征”的语义空间
ALN-P3:提出统一的“感知–预测–规划”联蒸馏框架,要求从输入到输出整条链路都与 VLM 的语言推理一致
目标可以概括为:
不仅要“做对”,还要“想明白为什么要这么做”。
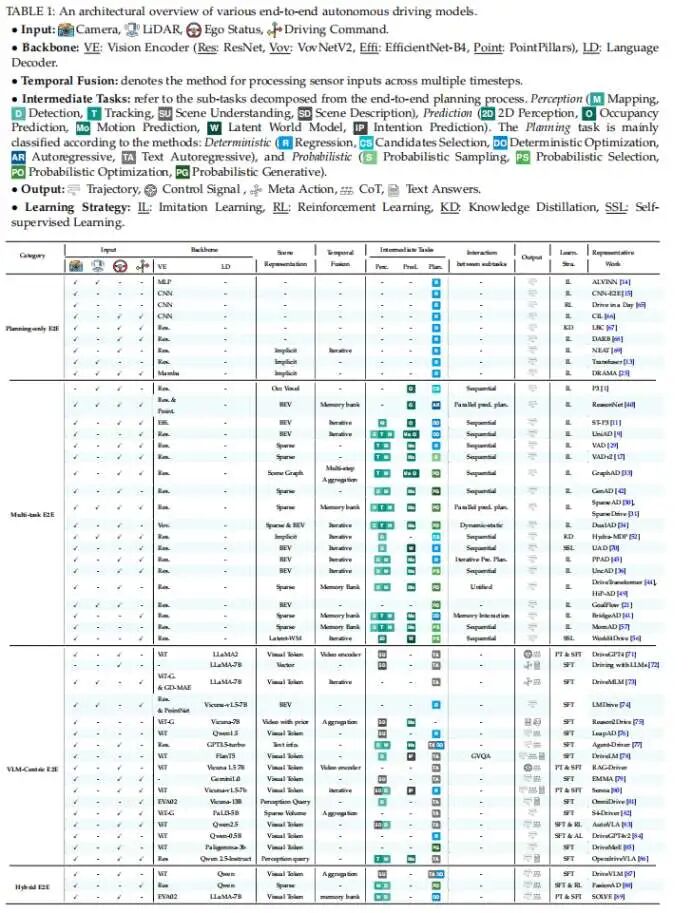
为了更直观地理解各流派的异同,作者整理了主流模型的输入、骨干网络、中间任务及输出形式,欢迎查阅。
📊 5. 数据集与评测基准
GE2E 研究需要同时覆盖:
不带语言标注的传统自动驾驶数据集
带语言标注的视觉语言自动驾驶数据集
5.1 无语言标注数据集:规划评测
主要用于评估规划与闭环控制:
nuScenes:多模态感知 + 短时规划,主要用于开放环(Open-loop)评测
指标包括 L2 误差、碰撞率等
CARLA / Bench2Drive:可控制天气、交通密度、路况,多用于闭环仿真评测
指标:Route Completion、Infraction Score、Driving Score
NAVSIM:介于开放与闭环之间,通过模拟预测评估真实世界表现,兼顾可靠性与效率
5.2 含语言标注数据集:VLM / VLA 专用
近年来,基于 LLM 辅助构建的数据集大量涌现,用于:
场景理解(QA / Caption)
行为解释(为何刹车、为何变道)
语言指令驱动控制
CoT 推理、图问答等
按数据来源大致可分为四类:
完全基于 nuScenes 构建(Talk2Car、DriveLM、NuScenes-QA、NuPrompt、SURDS 等)
基于其他开源数据集(KITTI、WOMD、BDD、DRAMA 等)
自采真实数据(LingoQA、MAPLM、CoVLA、DriveAction、DrivingVQA 等)
CARLA 仿真生成(DriveMLM、DriveLM-CARLA、DriveCoT、Bench2ADVLM、SimLingo 等)
为了帮助研究者快速上手,我们在综述原文(Table 2)中系统梳理了现有 VL 数据集的规模、任务类型、数据来源及标注方式,如图3所示。
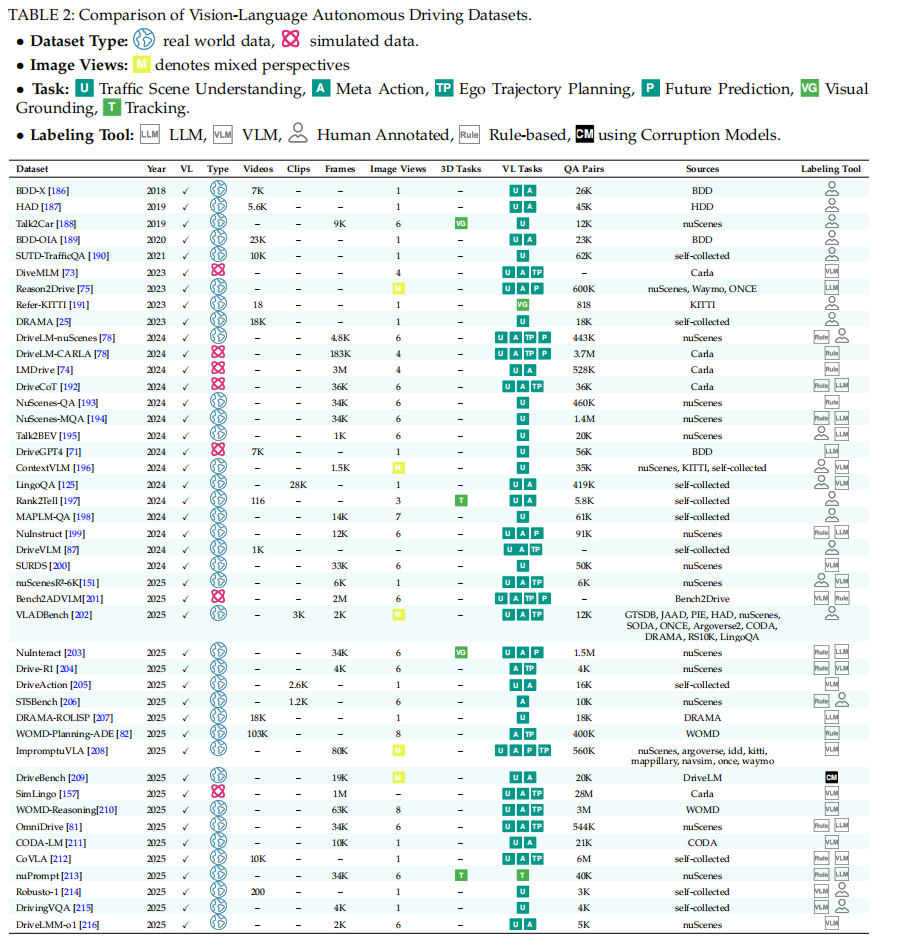
图 3 VL数据集总结 5.3 性能对比与趋势
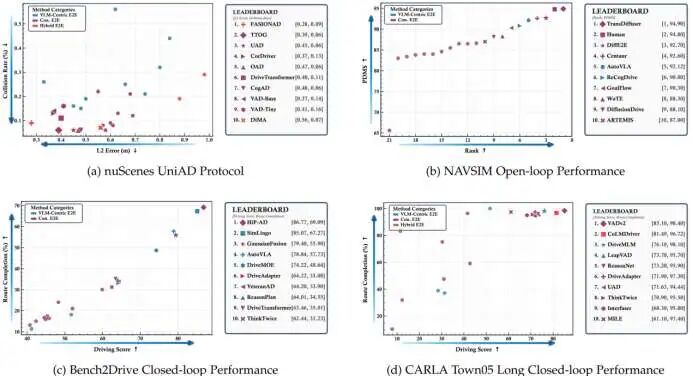
图 4 规划性能对比图 从图4的公开排行榜来看:
Open-loop(nuScenes, NAVSIM):
顶尖方法中传统 E2E 占主导
但带 VLM 的混合 / VLA 方法在某些指标上逐渐追平甚至超越
NAVSIM 上已有模型在综合指标上超越人类司机表现
Closed-loop(Bench2Drive, CARLA Town05):
传统 E2E 在稳定性和路线完成率上仍然有明显优势
当前 VLA/VLM 方法在“轨迹数值精度 + 对环境反作用的建模”上还有提升空间
整体趋势:
传统 E2E:数值精度高、闭环性能好
VLM/VLA:泛化能力强、解释能力好、在开放世界中表现出色
混合范式:有望在两者之间找到更好的平衡点
⚠️ 6. 核心挑战
从 GE2E 统一视角来看,三大范式共同面临以下关键挑战:
6.1 长尾数据分布
现实道路中,大多数数据是“平淡”场景,真正危险或复杂的场景极少:
模型在长尾场景表现差
合成数据 / 仿真补长尾常有“仿真–现实域差”问题
VLM 即便有海量世界知识,在特定任务微调中也可能出现灾难性遗忘
目前方向包括:
生成长尾场景(仿真 + 生成模型)
强化学习探索罕见状态
终身学习 / 数据引擎持续挖掘“高价值失败案例”
6.2 可解释性
传统 E2E:
多依赖注意力可视化、检测结果等方式做“间接解释”
难以准确反映真正的内部因果逻辑
VLA:
具备天然“会说话”的优势,可用 CoT 输出推理过程
但“解释与行为可能不一致”的问题非常现实(Hallucination / 对齐不足)
如何确保“想的内容”与“做的事情”真正一致,仍是重要研究方向。
6.3 安全与法规保障
仅靠训练时加入安全约束,还不足以应对真实世界的复杂、不确定情况
推理时安全模块虽有帮助,却会:
破坏端到端简洁性
过于保守,降低效率和用户体验
如何在安全、效率、舒适性之间找到可量化、可调的平衡,是核心难题。
6.4 实时效率
特别是 VLM/VLA:
参数大、推理慢、生成式解码延迟高
各类压缩/裁剪/早退策略往往带来能力下降或可靠性损失
在低延迟约束下保持高鲁棒性,仍是开放问题。
🚀 7. 未来趋势与研究方向
综合全文,未来 GE2E 自动驾驶的关键方向包括:
强化学习 + 模仿学习的混合范式
先用模仿学习快速获得可用策略,再用 RL 在仿真/世界模型中进行安全的闭环优化
面向多目标(安全、舒适、效率、合规)的奖励建模与策略优化
自动驾驶基础模型(Driving Foundation Models)
大规模预训练 + 小样本场景微调
VLA 作为统一“感知–推理–规划”框架,通过世界知识提升对长尾事件的预判能力
智能体系统(Agent Systems)
LLM 作为“调度与决策中枢”,调用感知、地图、规划等专用子模型(Tools)
形成多模块协作的“认知–执行层级结构”,提升解释性与鲁棒性
世界模型(World Models)
在潜在空间里“模拟未来”,实现安全的离线探索和规划
把“预测未来场景演化”作为一个自监督任务,从海量视频中学习
跨模态融合(Vision + LiDAR + HD Map + 文本)
将 RGB 丰富语义与 LiDAR 精确几何、有结构地图高层规则有效融合
提升在复杂 3D 环境中的决策可靠性
数据引擎(Data Engine)与自动化闭环
从真实路测与用户数据中自动挖掘“模型失败样本”“不确定样本”
形成“采集 → 筛选 → 标注/合成 → 训练 → 上路 → 再采集”的闭环迭代体系
✅ 8. 小结
本文从统一的 GE2E 视角回顾并梳理了:
三大端到端自动驾驶范式:
传统 E2E
VLM 核心 E2E
混合 E2E
在架构设计、学习策略、数据与评测上的代表性工作
各类方法在开放/闭环场景中的优势与不足
面向未来的关键挑战与突破方向
可以看到,端到端自动驾驶正在从:
“只会模仿、不会解释的黑盒控制器”
逐步演化为
“既能看、能想、能说,又能安全开车的智能体系统”。在这个过程中,基础模型、世界模型、强化学习、VLM/VLA 与工程级数据引擎将是推动下一代自动驾驶系统走向真正“可靠、安全、可解释”的关键技术支柱。
欢迎感兴趣的读者查阅论文原文与开源项目,进一步深入这条正在快速演进的技术路线。
参考:
论文标题:Survey of General End-to-End Autonomous Driving: A Unified Perspective
单位:上海交通大学,滴滴出行
链接:https://doi.org/10.36227/techrxiv.176523315.56439138/v1
项目主页:https://github.com/AutoLab-SAI-SJTU/GE2EAD

















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









