







在自然语言处理中,文本向量化(Text Embedding)是很重要的一环,是将文本数据转换成向量表示,包括词、句子、文档级别的文本,深度学习向量表征就是通过算法将数据转换成计算机可处理的数字化形式。
概念
从不同文本级别出发,文本向量化包含以下方法:
词级别向量化:将单个词汇转换成数值向量
-
独热编码(One-Hot Encoding):为每个词分配一个唯一的二进制向量,其中只有一个位置是1,其余位置是0。
-
TF-IDF:通过统计词频和逆文档频率来生成词向量或文档向量。
-
N-gram:基于统计的n个连续词的频率来生成向量。
-
词嵌入(Word Embeddings):如Word2Vec, GloVe, FastText等,将每个词映射到一个高维实数向量,这些向量在语义上是相关的。
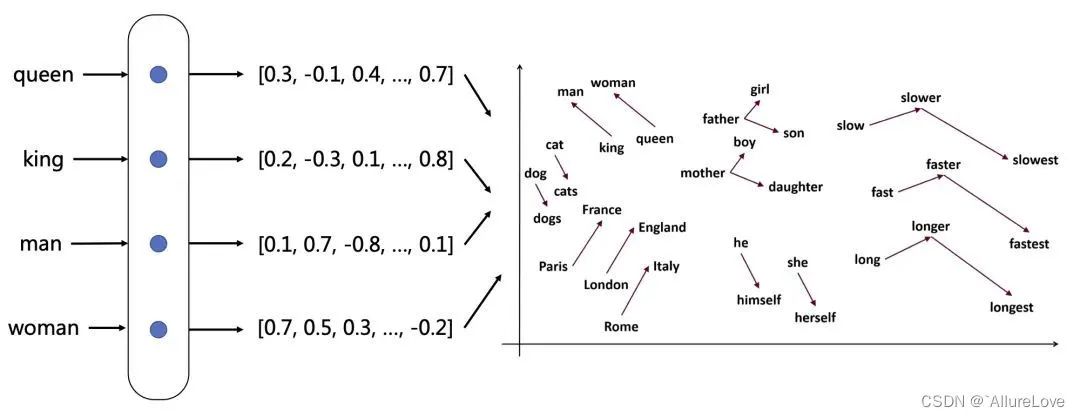
句子向量化:将整个句子转换为一个数值向量。
-
简单平均/加权平均:对句子中的词向量进行平均或根据词频进行加权平均。
-
递归神经网络(RNN):通过递归地处理句子中的每个词来生成句子表示。
-
卷积神经网络(CNN):使用卷积层来捕捉句子中的局部特征,然后生成句子表示。
-
自注意力机制(如Transformer):如BERT模型,通过对句子中的每个词进行自注意力计算来生成句子表示;再比如现在的大模型,很多都会有对应的训练好的tokenizer,直接采用对应的tokenizer进行文本向量化。
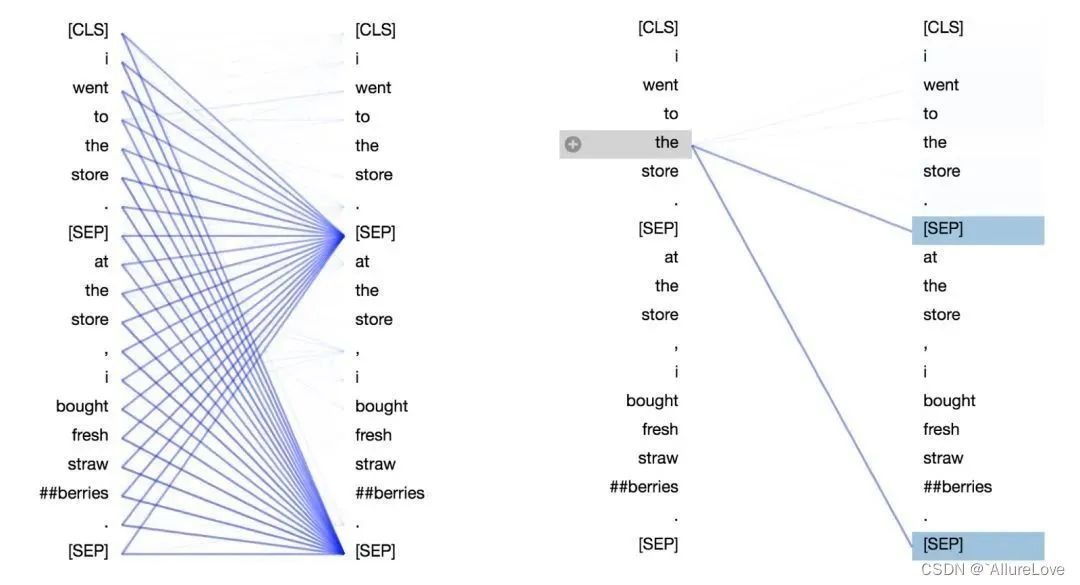
文档向量化:将整个文档(如一篇文章或一组句子)转换为一个数值向量。
-
简单平均/加权平均:对文档中的句子向量进行平均或加权平均。
-
文档主题模型(如LDA):通过捕捉文档中的主题分布来生成文档表示。
-
层次化模型:如Doc2Vec,它扩展了Word2Vec,可以生成整个文档的向量表示。
代码实战
经典向量化模型
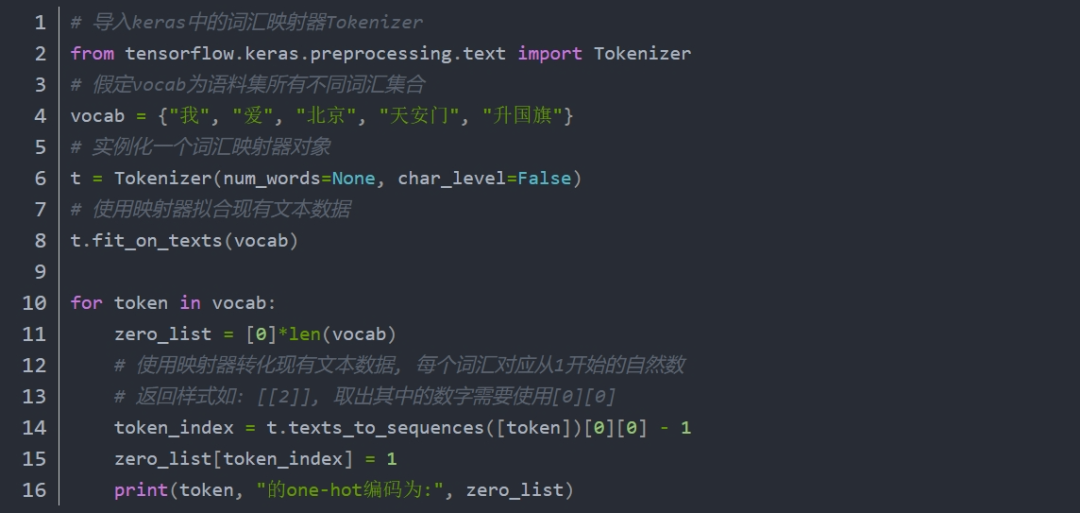
One-Hot编码
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数。One-Hot编码的缺点是完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,且较为稀疏,占据大量内存。
词袋模型(Bag Of Words,BOW)
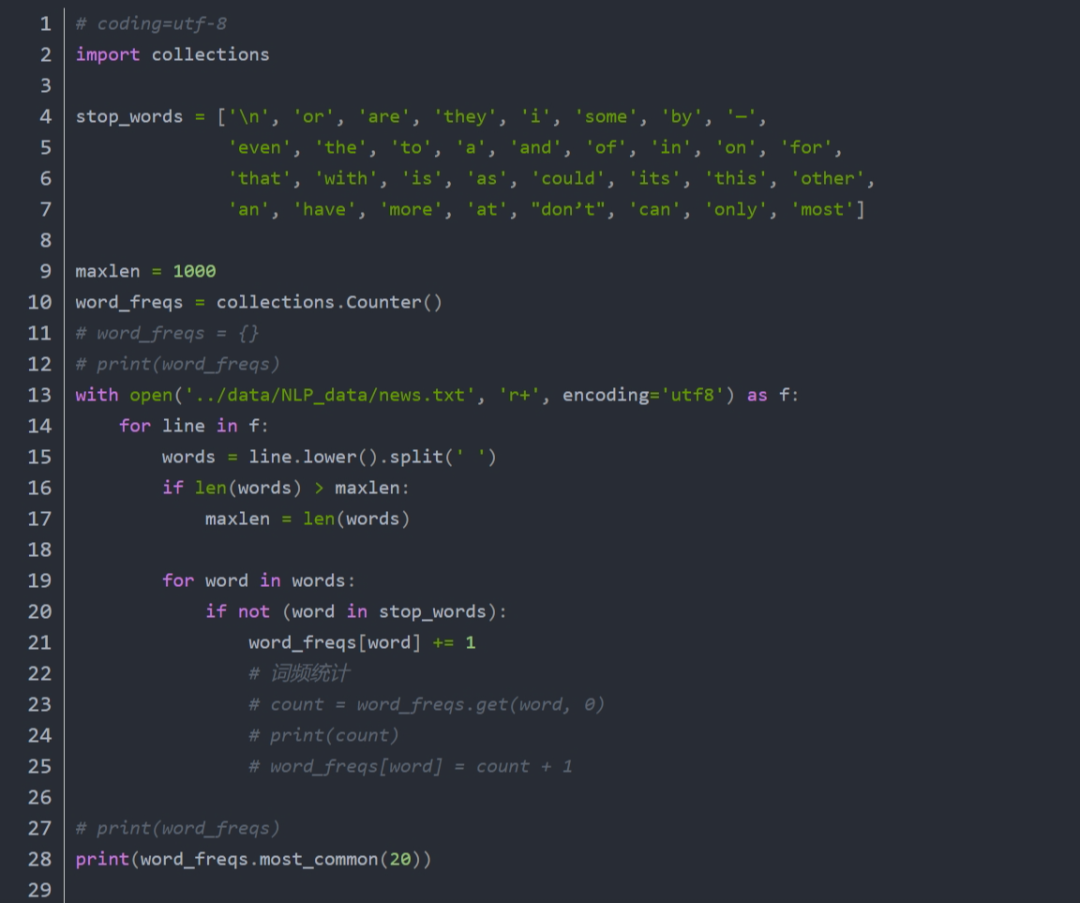
词袋是指把一篇文章进行词汇的整理,然后统计每个词汇出现的次数,由前几名的词汇猜测全文大意。具体做法包括:
分词:将整篇文章中的每个词汇切开,整理成生字表或字典。英文一般以空白或者句点隔开,中文需要通过特殊的方法进行处理如jieba等。
前置处理:先将词汇做词性还原,转换成小写。词性还原和转换小写都是为了避免,词汇统计出现分歧。
去除停用词:be动词、助动词、介词、冠词等不具有特殊意义的词汇称为停用词在文章中是大量存在的,需要将它们剔除,否则统计结果都是这些词汇。
词频统计:计算每个词汇在文章中出现的次数,由高到低进行排序。

TF-IDF
BOW方法十分简单,效果也不错,不过他有个缺点,有些词汇不是停用词,但是在文章中经常出现,但对全文并不重要,比如only、most等,对猜测全文大意没有太多的帮助,所以提出了改良算法tf-idf,他会针对跨文件常出现的词汇给与较低的分数,如only在每一个文件中都出现过,那么tf-idf对他的评分就会很低。


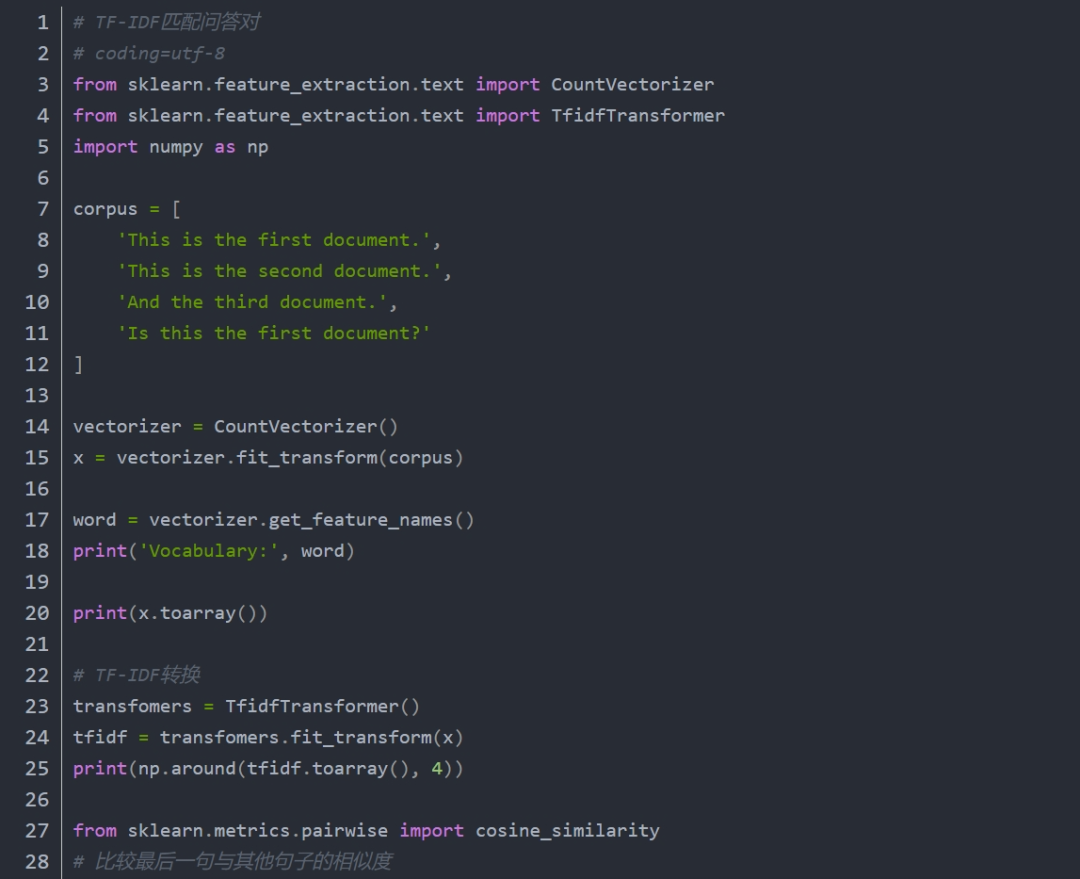
这里需要注意的是sklearn计算tf-idf公式有些许区别:

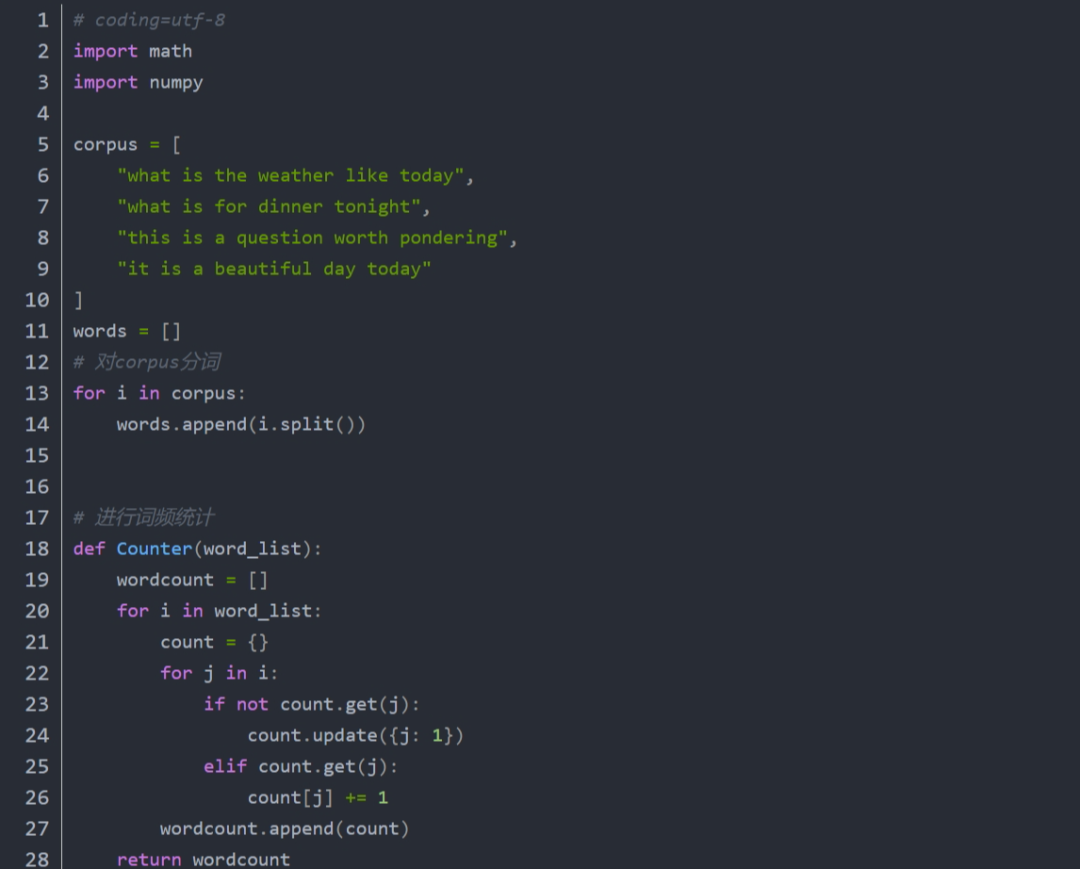
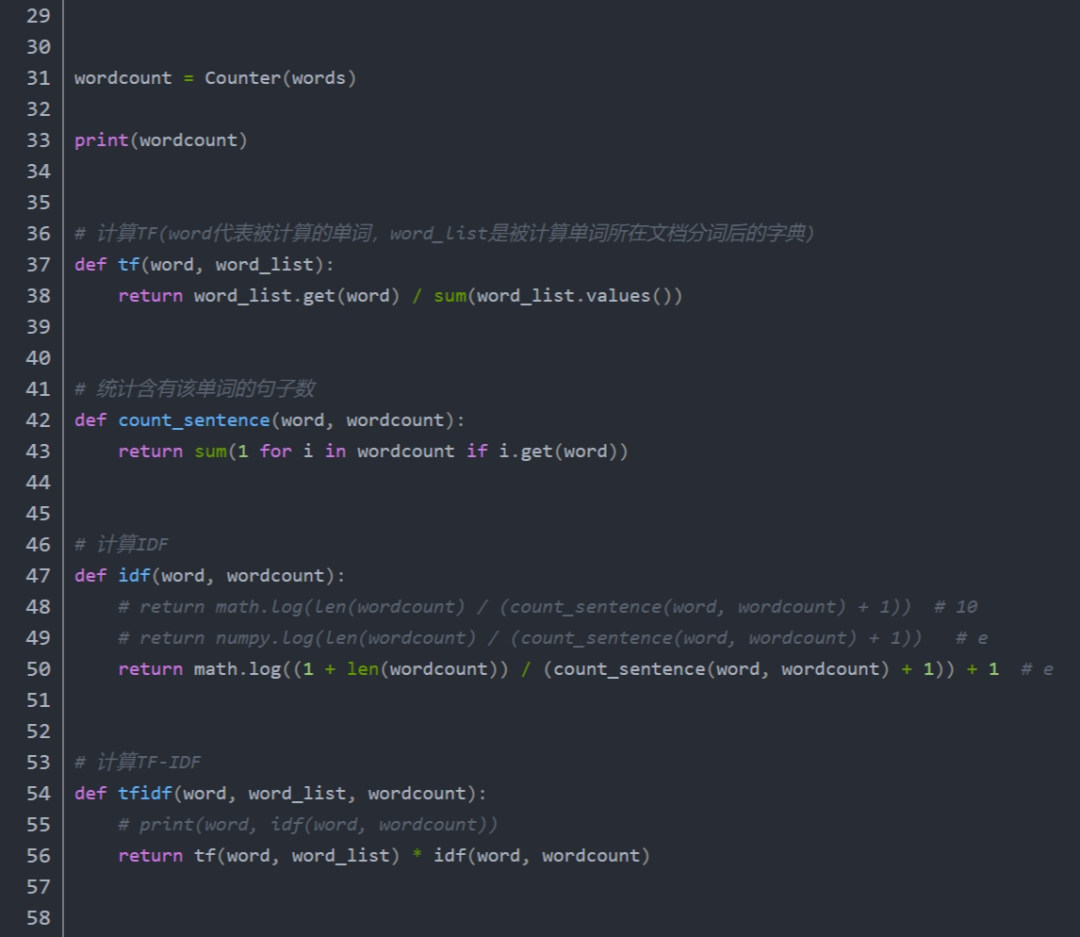
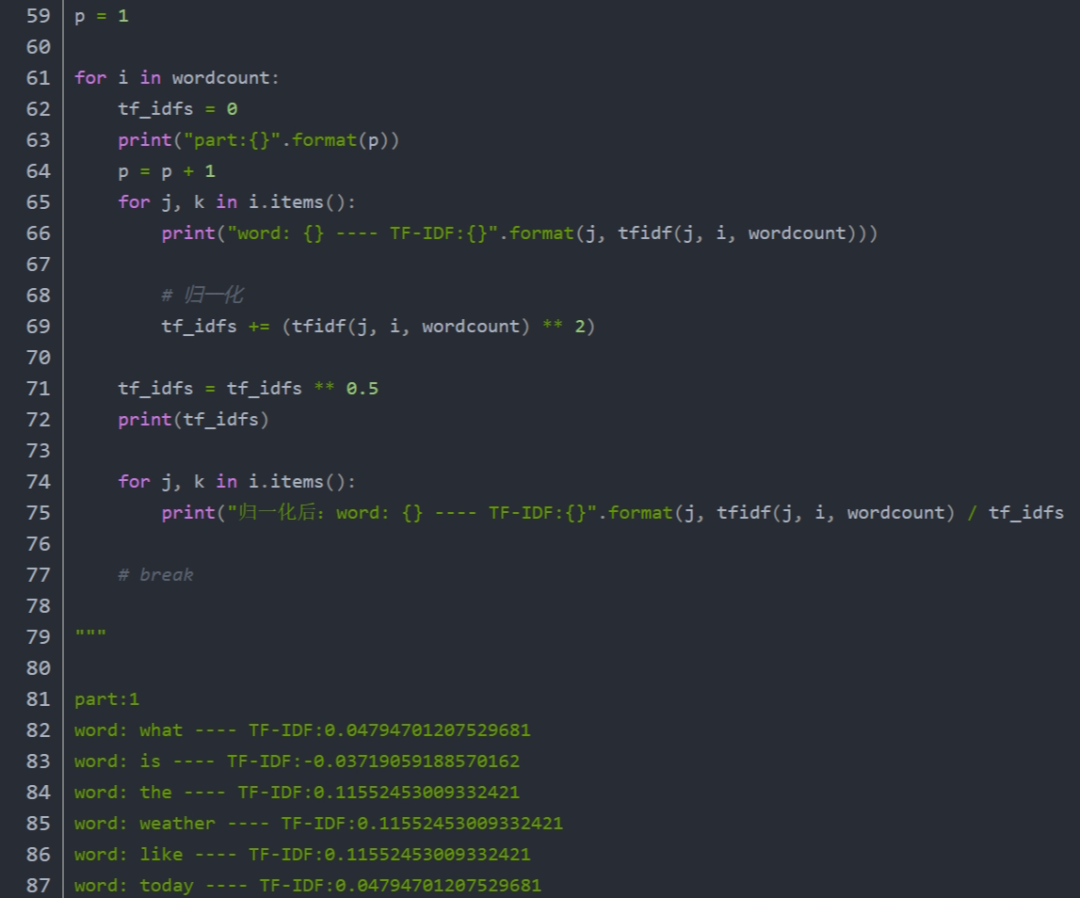
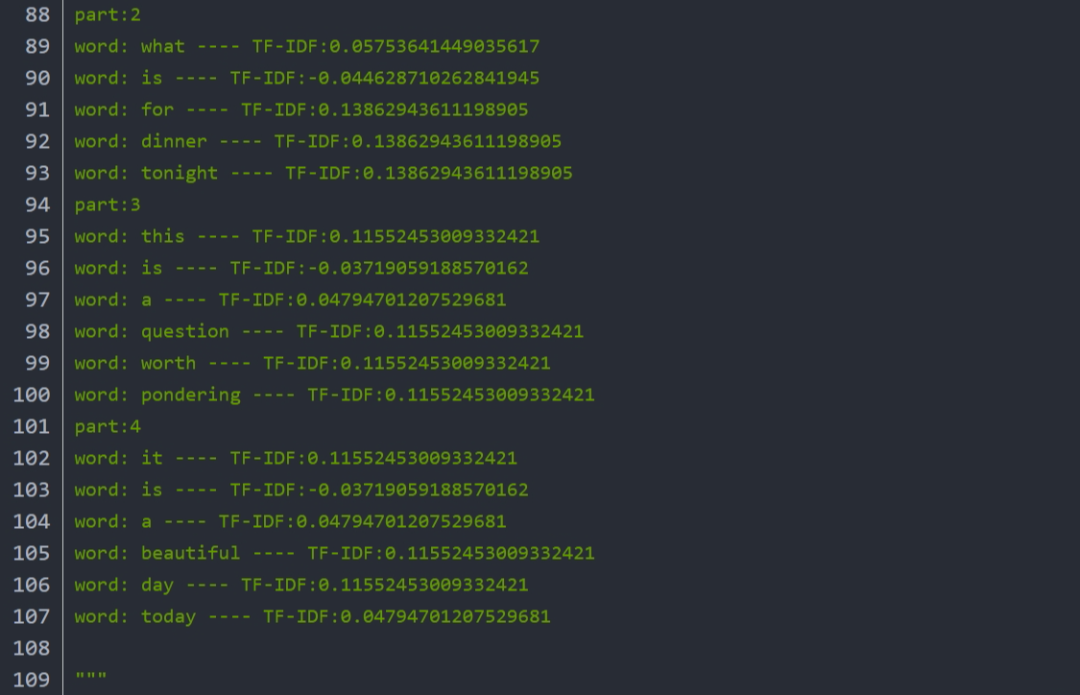
手动实现tf-idf完整代码:
注意 :分子分母同时增加1 为了平滑处理、增加了归一化处理计算平方根。
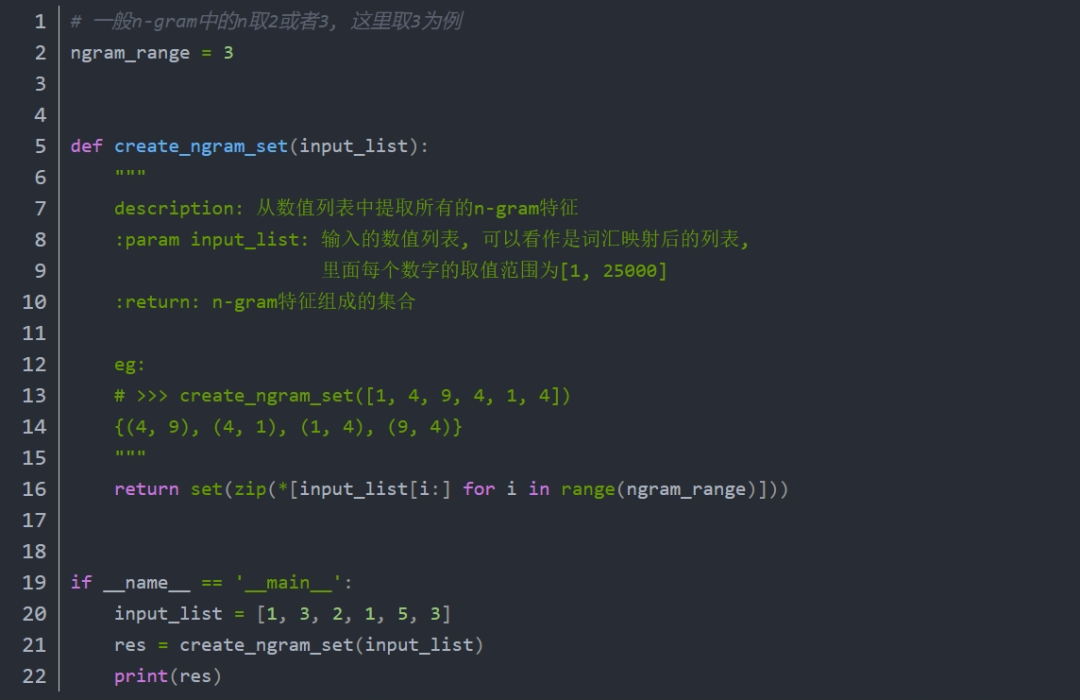
N-元模型(n-gram)
给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3。
word2vec
BOW和TF-IDF都只着重于词汇出现在文件中的次数,未考虑语言、文字有上下文的关联,针对上下文的关联,Google研发团队提出了词向量Word2vec,将每个单子改以上下文表达,然后转换为向量,这就是词嵌入(word embedding),与TF-IDF输出的是稀疏向量不同,词嵌入的输出是一个稠密的样本空间。
Doc2Vec
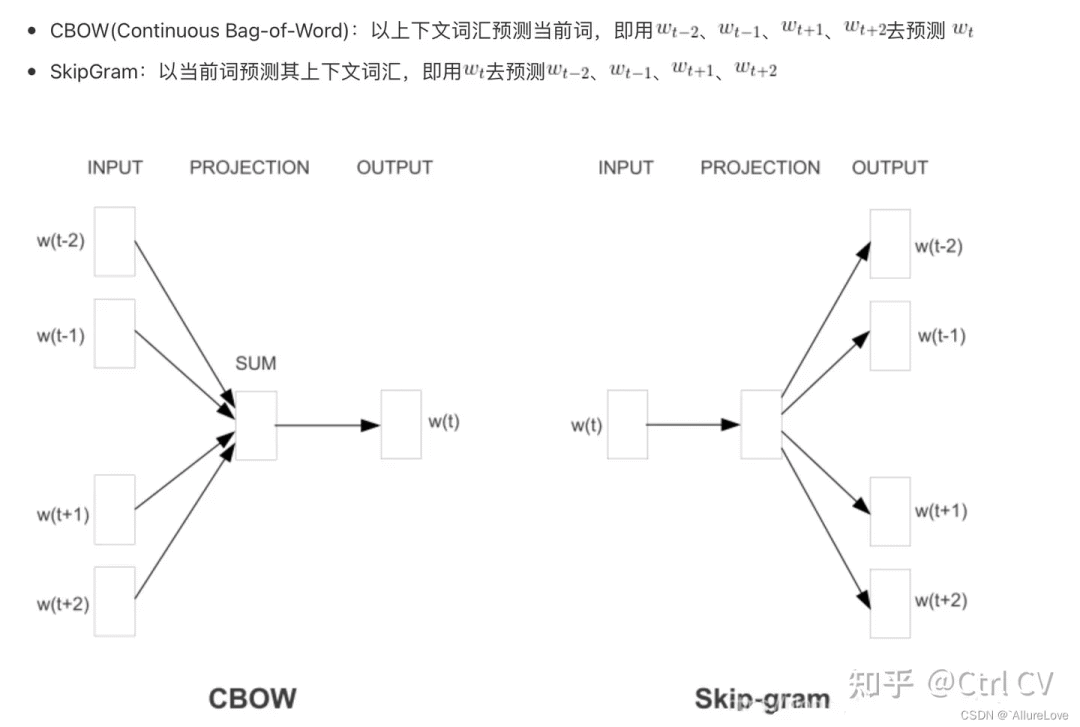
Doc2vec模型是受到了Word2Vec模型的启发。Word2Vec里预测词向量时,预测出来的词是含有词义的,Doc2vec中也是构建了相同的结构,所以Doc2vec克服了词袋模型中没有语义的缺点。假设现在存在训练样本,每个句子是训练样本,和Word2Vec一样,Doc2vec也有两种训练方式,一种是分布记忆的段落向量(Distributed Memory Model of Paragraph Vectors , PV-DM)类似于Word2Vec中的CBOW模型,另一种是分布词袋版本的段落向量(Distributed Bag of Words version of Paragraph Vector,PV-DBOW)类似于Word2Vec中的Skip-gram模型。
Glove
Glove由斯坦福大学所提出的另一套词嵌入模型,他们认为Word2vec并未考虑全局的概率分布,只以移动窗口内的词汇为样本,没有掌握全文的信息。因此,他们提出了词汇共现矩阵,考虑词汇同时出现的概率,解决Wordvec只看局部的缺陷以及BOW稀疏向量空间的问题。
基于神经网络的Tokenizer
这一类向量化工具都是基于海量语料库训练出来的,使用方便且功能强大:huggingface-tokenizer,下面仅列出三个作为参考,在选取tokenizer时可以去看模型训练的语料库是否和你的目标任务场景相契合,选取合适的向量化工具
Bert-Tokenizer
Bert向量化工具:BertTokenizer的使用方法(超详细);
https://blog.csdn.net/gary101818/article/details/129291852
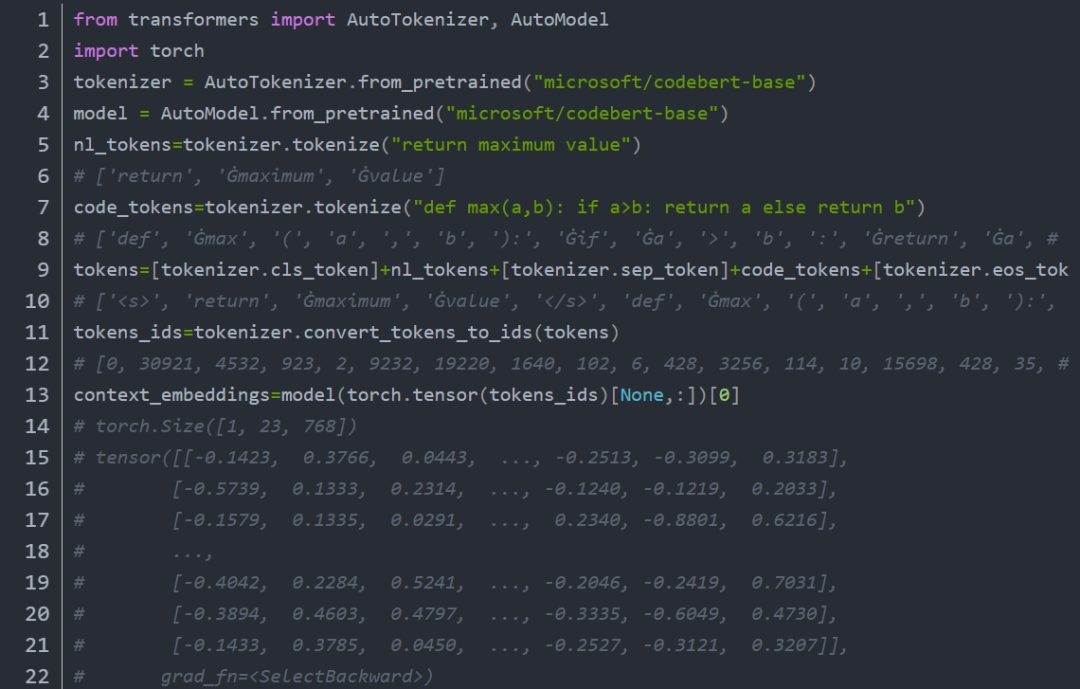
CodeBert-Tokenizer
CodeBert 语料库更注重于代码理解;
https://github.com/microsoft/CodeBERT
Claude-Tokenizer
Claude大模型的tokenizer,语料库包含多种语言,还包含代码语言
https://huggingface.co/Xenova/claude-tokenizer

如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 2042
2042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}