









 本文介绍了一种基于深度学习的新型工具DeepSuccinylSite,专门用于预测蛋白质中的琥珀酰化位点。通过对比实验数据和使用one-hot编码与嵌入层,研究发现嵌入编码在性能上优于传统方法,尤其是在窗口大小33和嵌入尺寸21时。模型在独立测试中表现出显著的提升,优于现有模型,为琥珀酰化位点的快速、经济检测提供了有效手段。
本文介绍了一种基于深度学习的新型工具DeepSuccinylSite,专门用于预测蛋白质中的琥珀酰化位点。通过对比实验数据和使用one-hot编码与嵌入层,研究发现嵌入编码在性能上优于传统方法,尤其是在窗口大小33和嵌入尺寸21时。模型在独立测试中表现出显著的提升,优于现有模型,为琥珀酰化位点的快速、经济检测提供了有效手段。
论文解读:《DeepSuccinylSite:a deep learning based approach for protein succinylation site prediction》
文章地址:https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-020-3342-z
Doi:https://doi.org/10.1186/s12859-020-3342-z
数据及代码:https://github.com/dukkakc/DeepSuccinylSite
略缩词补充
AUC:Area under ROC curve
CNN:Convolutional Neural Network
DL:Deep learning
LSTM:Long short-term memory
MCC:Mathew correlation coefficient
PTM:Post translational modification
ReLU:Rectified linear unit
RNN:Recurrent neural network
ROC:Receiver operator characteristics
1.文章概括
蛋白质琥珀酰化最近已出现为赖氨酸残基上发生的重要且常见的翻译后修饰(PTM)。琥珀酰化的大小(例如,在100Da时,它是较大的化学PTM之一)以及在生理pH下将修饰的赖氨酸残基的净电荷从+1改变为-1的能力均值得注意。琥珀酰化后蛋白质中发生的总体局部变化已显示出与基因活性变化相对应,并受到柠檬酸循环缺陷的干扰,这些观察结果与琥珀酸在细胞呼吸过程中作为代谢中间体生成的事实一起,提示了琥珀酸蛋白可能在细胞代谢与重要细胞功能之间的相互作用中发挥作用。例如,琥珀酰化可能代表基因组调节和修复的重要方面,并且可能在许多疾病状态的病因学中产生重要影响。在这项研究中,作者开发了DeepSuccinylSite,这是一种新颖的预测工具,它使用深度学习方法以及嵌入技术来基于蛋白质的一级结构识别蛋白质中的琥珀酰化位点。使用实验确定的琥珀酰化位点的独立测试集,作者的方法在灵敏度,特异性和MCC方面分别获得了79%,68.7%和0.48的效率得分,且接收者操作员特征(ROC)曲线下的面积为0.8。在与先前描述的琥珀酰化预测因子的并排比较中,DeepSuccinylSite代表了琥珀酰化位点预测的总体准确性的显着提高。
2.背景
蛋白质翻译后修饰(PTM)是蛋白质合成后发生的重要细胞调节过程。 PTM通过将功能性部分共价添加到蛋白质,调节性亚基的蛋白水解切割,增加了蛋白质组的功能多样性,并在信号传递整个蛋白质的降解中起重要作用。 PTM包括磷酸化,糖基化,泛素化和相对较新描述的修饰,例如琥珀酰化。琥珀酰化是通过在目标赖氨酸残基的ε-氨基上添加一个琥珀酰基(-CO-CH2-CH2-CO2H)而发生的PTM。
蛋白PTM已通过多种实验技术进行了检测,包括质谱[MS],液相色谱,放射性化学标记和免疫学检测,例如染色质免疫沉淀和蛋白质印迹。通常,对PTM进行实验分析需要耗时,费力和资金的技术,并需要使用危险/昂贵的化学试剂。由于PTM在疾病状态和正常生物学功能中的重要性,因此必须投资开发可快速,经济高效地筛选蛋白质的潜在PTM位点的选择。
近年来,机器学习已成为预测不同PTM站点的一种经济高效的方法。一些基于机器学习的琥珀酰化位点预测方法是iSuc-PseAAC、iSuc-PseOpt、pSuc-Lys、SuccineSite、SuccineSite2.0 、GPSuc和PSuccE。尽管结果不错,但由于手动选择特征以及可能不存在有助于琥珀酰化的未知特征,因此存在潜在的偏倚,而且这些方法的预测性能还不足以用于高通量研究。
近来,已经开发了深度学习(DL)方法来阐明细胞蛋白中假定的PTM位点。例如,MusiteDeep和DeepPhos已被开发用来预测磷酸化位点,而Fu等人和Wu等人则是使用基于DL的方法分别识别推定的泛素化和乙酰化位点。这些DL方法在方法性能的总体度量(例如曲线下面积(AUC)和马修斯相关系数(MCC))方面已取得了相对的改进。通常,这些模型将单次热编码和提取的特征的某种组合用作输入,主要是在尝试避免依赖手动特征提取。据作者所知,DL模型以前尚未用于琥珀酰化位点的预测。在这项研究中,作者基于使用Keras库的卷积神经网络(CNN)深度学习框架,开发了一个称为DeepSuccinylSite的琥珀酰化位点预测子。
3.方法
3.1 基准数据集
使用了与从实验中得出的赖氨酸琥珀酰化位点相同的训练和独立数据集,如Hasan等人和Ning等人所述。Ning等人使用Hasan等人的UniProtKB / Swiss-Prot数据库和NCBI蛋白质序列数据库,创建琥珀酰化数据集。使用CD-HIT去除序列同一性超过30%的蛋白质后,剩下5009个琥珀酰化位点和53,542个未知的琥珀酰化位点。其中,将4755个琥珀酰化位点和50565个非琥珀酰化位点用于训练集,并将254个琥珀酰化位点和2977个非琥珀酰化位点用于独立测试。此外,对于我们的方法,最佳窗口大小为33,并且某些序列具有其他特征,我们在训练集中损失了5个(4755个中)阳性位点。
对于训练和测试集,使用欠采样来平衡数据。最终训练数据集包含4750个阳性和4750个阴性位点,而独立测试数据集在平衡后包含254个阳性和254个阴性位点。

表 1显示了平衡后用于训练和独立测试的最终数据集。为了生成蛋白质的局部表示并优化模型,围绕每个目标赖氨酸(K)设置了一个窗口参数。如果K的左侧或右侧小于窗口大小的一半,则使用伪残基“-”以保留所有正位。
3.2 编码方式
与传统的机器学习方法相比,我们基于DL的方法直接将窗口形式的序列数据作为输入,从而减少了手工提取特征的需求。这种方法的先决条件是,序列数据必须以我们的DL模型可以读取的形式进行编码。因此,我们利用了两种类型的编码:(i)one-hot编码;(ii)嵌入层。与用于其他类型的翻译后修饰位点预测的其他DL方法相比,主要区别之一是我们的嵌入编码。
3.3 one-hot编码
one-hot编码将类别变量转换为相应的二进制变量。为了将20个常见氨基酸和伪残基“-”转换为数值,以类似于MusiteDeep方法,将21个字符转换为0到20的整数。每个氨基酸都由由零和a组成的二进制代码表示单数形式,其位置编码氨基酸的身份,二进制表示是根据字母顺序完成的。例如,丙氨酸(A)表示为100000000000000000000,精氨酸(R)表示为010000000000000000000,依此类推。因此,在模型中,大小为N的窗口对应于输入向量大小N×21,一键式编码的主要缺点之一是映射是完全统一的。因此,具有相似特性的氨基酸不会在向量空间中放置在一起。
3.4 嵌入层
第二种类型的编码,利用的是嵌入编码,嵌入可以找到氨基酸序列的最佳表示形式,如DeepGO,以克服one-hot的缺点。首先将20个氨基酸残基和1个伪残基转换为0到20的整数,这是作为嵌入层的输入提供的,该层位于DL体系结构的开头,用随机权重初始化嵌入层;然后,该层在训练过程中学习具有后续历元的更好的基于矢量的表示,每个向量化都是另一个维度的正交表示,因此保留其身份。因此,使其比静态一键编码更具动态性。在我们的研究中,K的嵌入编码(单词到vec)为:[-0.03372079,0.01156038,-0.00370798,0.00726882,-0.00323456,-0.00622324,0.01516087,0.02321764,0.00389882,-0.01039953,-0.02650939,0.01174229,-0.0204078,- 0.06951248,-0.01470334,-0]。训练后在21维向量空间中的[03336572,0.01336034,-0.00045607,0.01492316,0.02321628,-0.02551141]。嵌入组通常在向量空间中共同出现。必须在嵌入层中指定两个关键参数。这些是:
- output_dim:向量空间的大小。
- input_length:输入的大小,即窗口大小。
3.5 训练和测试数据集
训练数据集进一步细分为80%训练和20%验证集,使用80%的训练数据对模型进行训练,并在每个时期使用剩余的20%的训练数据集进行验证。执行此验证方法是为了跟踪培训进度并确定过度拟合。当验证精度开始下降而训练精度继续提高时,发现过拟合。利用Checkpointer根据验证准确性从各个时期中选择最佳模型;这种方法还有助于最大程度地减少潜在的过度拟合。然后将生成的模型用于具有独立测试数据集的独立测试。
3.6 输入值
与传统的机器学习方法相比,使用DL的主要优势是排除了手动特征提取。DL方法的输入是FASTA格式的序列窗口。例如,对于33的窗口大小,one-hot编码的输入尺寸为33×21。对于相同窗口大小的嵌入,嵌入尺寸为21的输入尺寸为33×21。
3.7 DeepSuccinylSite
DeepSuccinylSite的总体架构如下图所示:

输入FASTA格式的窗口大小为33。它被转换为整数,然后使用单热编码或嵌入层进行编码。这将是CNN图层的输入。b任何一种编码的输出然后作为输入馈入深度学习架构。最后,在平整并完全连接各层之后,我们得到最终输出,该输出包含两个节点,其中两个节点的输出为[0 1]表示正位置,[1 0]表示负位置。
对输入数据进行编码后,将编码后的数据馈入网络。两种编码方法使用相同的体系结构,不同之处在于在嵌入编码的情况下包括嵌入层和lambda层。
下一层是卷积层。以前的基于磷酸化位点的基于DL的模型(DeepPhos,MusiteDeep)使用1-D(1维)卷积层,而我们使用了2-D(维)卷积层,因此通过选择2-D可以提高灵活性。如果我们使用一维卷积层并执行相同的操作,那么将无法推断出许多特征信息,因为x轴是固定的(它将保持在21处),并且只会沿垂直方向移动;此后,还用2D选择其他层。使用了2D卷积层来优先考虑包含大小为17×3的过滤器(对于窗口大小为33的过滤器,PTM站点位于第17个位置),该过滤器将在每个跨步中包含PTM站点。使用此过滤器大小以及禁用填充功能,允许针对训练时间优化模型,而不会影响性能。使用较高的dropout=0.6以避免过拟合。此外,修正线性单元(ReLU)被用作所有层的激活函数,由于ReLU的稀疏激活,它被认为是最佳的激活函数,它使过度拟合的可能性最小化,并且使模型的预测能力最大化。使用了两个卷积层,一个max pooling(最大值池化)层,一个具有两个密集层的完全连接层以及一个输出层。表中给出了模型中使用的参数 从而最大程度地减少了过度拟合的可能性,并使模型的预测能力最大化。我们使用了两个卷积层,一个maxpooling层,一个具有两个密集层的完全连接层以及一个输出层。下表中给出了模型中使用的参数。

如Kingma等人先前所述,将Adam优化用作架构的优化器。Adam使用自适应学习率方法来计算每个参数的单独学习率,Adam与经典的随机梯度下降法不同之处在于,在训练过程中,随机梯度下降法可为所有体重更新保持单一,恒定的学习率。具体地说,Adam结合了自适应梯度算法和均方根传播的优点,从而可以有效地训练模型,由于这项研究是一个二元分类问题,因此使用二元交叉熵(与给定分布相关的不确定性度量)或对数损失作为损失函数。二进制交叉熵由下式给出:

其中y是标签( 1表示正,0表示负),并且
y
^
\widehat y
y
i是该站点对所有N个点均为正的预测概率。它会将log(
y
^
\widehat y
y
i)添加到损失中,即它为正值的对数概率;相反,对于每个负位点(y = 0),它添加log(1-
y
^
\widehat y
y
i),即它的对数概率为负。
完全连接的层包含两个分别具有768个和256个节点的密集层,最终输出层包含2个节点。
3.8 模型评估和性能指标
在这项研究中,使用10倍交叉验证来评估模型的性能。在10倍交叉验证中,数据被分为10个相等的部分。然后,将一部分留给验证,然后对其余9个部分进行训练。重复此过程,直到所有部分都用于验证为止。
混淆矩阵(CM),马修相关系数(MCC)和接收者操作特征曲线(ROC)曲线用作性能指标。ROC曲线是用于说明二元分类器的诊断能力的图形图,而曲线下面积(AUC)表示可分离性的程度或度量。由于琥珀酰化位点的识别是一个二元分类问题,因此混淆矩阵的大小为2×2,由真阳性(TP),真阴性(TN),假阳性(FP)和假阴性(FN)组成。使用这些变量计算出的其他指标是准确性,敏感性(即真实阳性率)和特异性(即真实阴性率)。

4.结果
4.1 最佳窗口大小和编码
最初,使用one-hot编码和嵌入测试了从9到45的窗口大小。例如,对于9的窗口大小,赖氨酸(K)残基设置在窗口的中间,上游4个氨基酸残基,下游4个氨基酸残基;窗口大小为33时,0ne-hot热编码和嵌入的MCC最高,窗口大小进一步增加,导致MCC减少(表 3)。同样,使用33的窗口大小可获得最高的特异性和AUC,而使用嵌入时灵敏度仅略微降低(表3和图 2)),因此,本研究将33的窗口大小视为最佳窗口大小。Wang等人也使用了33的窗口大小,one-hot编码预测磷酸化位点;值得注意的是,这项研究与Wang等人先前的研究在窗口大小上的一致性,与许多蛋白间氨基酸相互作用的已知范围相关,重要的是,除少数例外,对于每个测试的窗口大小,嵌入的性能都优于单热编码。因此,对于本研究,选择嵌入进行编码。

4.2 确定最佳嵌入尺寸
接下来,试图确定最佳的嵌入尺寸,为此,测试了从9到33的尺寸以进行嵌入。重要的是要注意,增加嵌入的尺寸将导致更高的计算成本,因此,作者旨在确定在所有指标之间取得平衡的最小维度。由于MCC通常被用作总体模型性能的替代品,因此其优先级略高于其他参数。虽然尺寸尺寸15和21都达到了这种平衡,但是尺寸尺寸21时,性能指标通常更好。实际上,尺寸尺寸21达到了最高的MCC,敏感性和特异性得分均在7%之内。在这些领域获得的最高分数(表 4)。一致的是,尺寸大小为15和21的AUC得分最高(图 3)。综上所述,这些数据表明使用我们的体系结构最佳尺寸为21。因此,选择21的尺寸用于模型开发。尺寸大小与每个载体中存在20个氨基酸残基和1个伪残基的事实一致。


4.3 交叉验证和替代分类器
最终模型称为DeepSuccinylSite,它利用窗口和尺寸分别为33和21的嵌入。基于五次10倍交叉验证,DeepSuccinylSite表现出强大的鲁棒性和一致性的性能指标,平均MCC为0.519 +/- 0.023,AUC为0.823(表S3)。作者还实施了其他深度学习架构和不同的机器学习模型,其中输入是基于“物理化学”的手工功能,而不是单独的蛋白质序列,本质上,此实现将各种理化功能与XGBoost结合使用以提取突出的功能。在计算特征时,用“-”排除了任何序列;然后,使用XGBoost提取了突出的特征,这些特征提供了更好的准确性,并在0.00145的阈值下获得了总共160个特征。有趣的是,使用这些方法的方法的性能不如DeepSuccinylSite出色,后者仅输入蛋白质序列(表S2)。有关作者提出模型性能的更多信息,请参见附加文件(图S1:中显示了基于功能的深度学习架构的结果)。



4.4 与其他深度学习架构的比较
其他DL体系结构,例如递归神经网络(RNN)和长期短期记忆(LSTM),以及组合模型LSTM-RNN,也已实现了单次热编码(DeepSuccinylSite one_hot)并与DeepSuccinylSite的独立测试结果进行比较(表 5))。此外,作者实现了附加的DL体系结构,其中输入内容包括一级氨基酸序列以外的其他功能。具体而言,该实施方式利用了以下组合:(1)物理化学特征,例如伪氨基酸组成(PAAC),“ k间隔氨基酸对”(AAP);(2)自相关特征,例如Moreau-Broto自相关和组成,过渡和分布(CTD)特征;(3)熵特征,例如Shannon熵,相对熵和信息增益。在计算特征时,用“-”排除了任何序列。然后,使用XGBoost提取了突出的特征,这些特征提供了更好的准确性,并在阈值0.00145处获得了总共160个特征。使用功能的算法版本称为基于DeepSuccinylSite功能。

为了公平地比较,作者对33个窗口大小和这三种DL架构的一键编码使用了相同的平衡训练和测试数据集。结果示于表5,ROC曲线示于图 4。还显示了嵌入的DL模型(DeepSuccinylSite)的结果。这些模型的详细架构,包括其他窗口大小的结果,在附加文件1中进行了讨论,而这些方法的性能在附加文件1:表S1中进行了介绍。对于one-hot编码,DeepSuccinylSite获得了比其他DL架构更好的MCC和AUC分数。同样,使用嵌入的最终模型在所有模型中均获得了最高的MCC和AUC评分(表5)

4.5 与现有模型的独立测试比较
使用较早的基准数据集中提到的独立测试集,将DeepSuccinylSite的性能与其他琥珀酰化位点预测变量进行了比较。在这些分析中,一些用于琥珀酰化位点预测的最广泛使用的工具,例如iSuc-PseAAC、iSuc-PseOpt、pSuc-Lys、SuccineSite 、SuccineSite2.0、GPSuc 和PSuccE被考虑。所有这些方法都使用与表6中相同的训练和独立测试数据集 。这些先前发布的方法的性能指标主要来自其各自的手稿,主要是基于PSuccE中的比较。

DeepSuccinylSite的灵敏度得分比第二高的模型高58.3%(表6),相反,我们的模型表现出了所有测试模型中最低的特异性得分,但DeepSuccinylSite获得的特异性得分仅比排名靠前的方法低22.2%。通过MCC测得,DeepSuccinylSite的性能显着提高。实际上,与次高的方法GPSuc相比,DeepSuccinylSite的MCC升高了约62%。综上所述,我们所描述的新型架构称为DeepSuccinylSite,显示出显着改善的性能,可用于精确,准确地预测琥珀酰化位点。
5.讨论
琥珀酰化是相对较新发现的PTM,由于引入大的(100Da)化学部分改变了修饰残基的电荷的生物学意义而引起人们的兴趣,琥珀酰化的实验检测是费力的并且昂贵的。由于包含4750个阳性站点的相对较大的数据集可供培训,因此我们有可能实现不同的DL体系结构。与文献中先前描述的模型相比,本文中描述的模型优化过程可显着改善琥珀酰化位点的精确预测。这项研究考虑了两种类型的编码,一种是one-hot编码,另一种是嵌入,结果表明,嵌入是一种最佳方法,
此外,DeepSuccinylSite证实了文献中的先前迹象,即33的窗口大小可以最佳地反映预测PTM部位的蛋白质中的局部化学相互作用,这是由于其在MCC等指标上的性能所致。重要参数之一是嵌入尺寸。DeepSuccinylSite的训练尺寸从9到33不等。随着尺寸的增加,训练时间也增加了,尽管尺寸大小15和21之间没有显着差异,但考虑到氨基酸残基的数量和稍微好些的结果,本研究选择21作为嵌入尺寸。最终,对于具有嵌入尺寸21的窗口大小33,DeepSuccinylSite的灵敏度,特异性和MCC的效率得分分别为0.79、0.69和0.48。
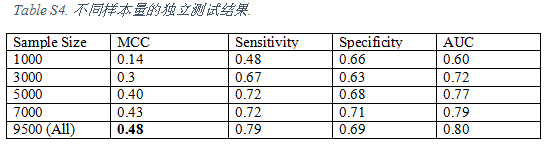
为了进行进一步的改进,我们可以提取以感兴趣的位点为中心的基于结构的窗口序列,而不是使用当前基于蛋白质序列的窗口序列,并将该窗口用作输入。当蛋白质结构不可用时,蛋白质结构预测管线如I-TASSER或ROSETTA,可以先用于预测结构。由于蛋白质的结构比序列更保守,因此我们希望更好地捕获进化信息,从而获得更好的预测准确性。此外,我们还可以通过使用基于序列的窗口,基于结构的窗口,理化特性创建多个模型,然后使用表决方法来提高方法的性能。最后,如在DeepPhos中所做的那样,使用我们的编码技术进行多窗口输入可以提高性能。但是,这些方案需要更多的数据集,一旦有更多的实验数据可用,我们可以更详细地进行研究。我们还探讨了数据大小对预测性能的影响(附加文件1:表S4和附加文件1:图S2)。这些研究表明,最初,我们的模型的性能随着数据量的增加而增加,直到达到平稳状态。这在某种程度上与深度学习中的普遍共识相反,根据功率定律,性能随着数据大小的增长而不断提高。但是,随着将来可能会有更多的实验数据,我们可以对性能如何随着数据量的增加而扩展进行更全面的研究。也许,这也可能表明随着数据的增加,我们可能必须开发更复杂的深度学习模型。
利用本文描述的独特架构,DeepSuccinylSite模型显示出比现有模型更好的预测质量。该模型的实用性在于其预测可能被琥珀酰化的赖氨酸残基的能力。因此,该模型可用于优化用于琥珀酰化位点的实验验证的工作流程。具体来说,使用此模型可以大大减少识别这些站点的时间和成本。当PTM表示自己是观察到的生物学现象的可能解释时,该模型在假设生成中也可能具有一定的作用。
6.结论
在这项研究中,作者描述了DeepSuccinylSite的发展,DeepSuccinylSite是一种新颖且有效的深度学习架构,可用于预测琥珀酰化位点。与其他机器学习架构相比,使用此模型的主要优势是消除了特征提取。结果,其他PTM站点可以很容易地在此模型中应用。由于此模型仅利用两个卷积层和一个最大合并层来避免对当前数据的过度拟合,因此提供新的数据源可能会在将来允许对该模型进行进一步的修改。总之,DeepSuccinylSite是一种有效的深度学习架构,具有同类最佳的结果,可用于预测琥珀酰化位点,并有可能在一般PTM预测问题中使用。

















 3002
3002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









