






https://zhuanlan.zhihu.com/p/104393915
Attention Is All You Need (Transformer) 论文精读
原创 | Attention is all you need 论文解析(附代码)
self-attention没有位置感知能力的证明self attention是permutation equivariant(置换等变),带有latent query的self-attention是permutation invariant(置换不变)
transformer主要提出了一个模型,和以往的CNN和RNN都不同,也可以对序列化进行学习。
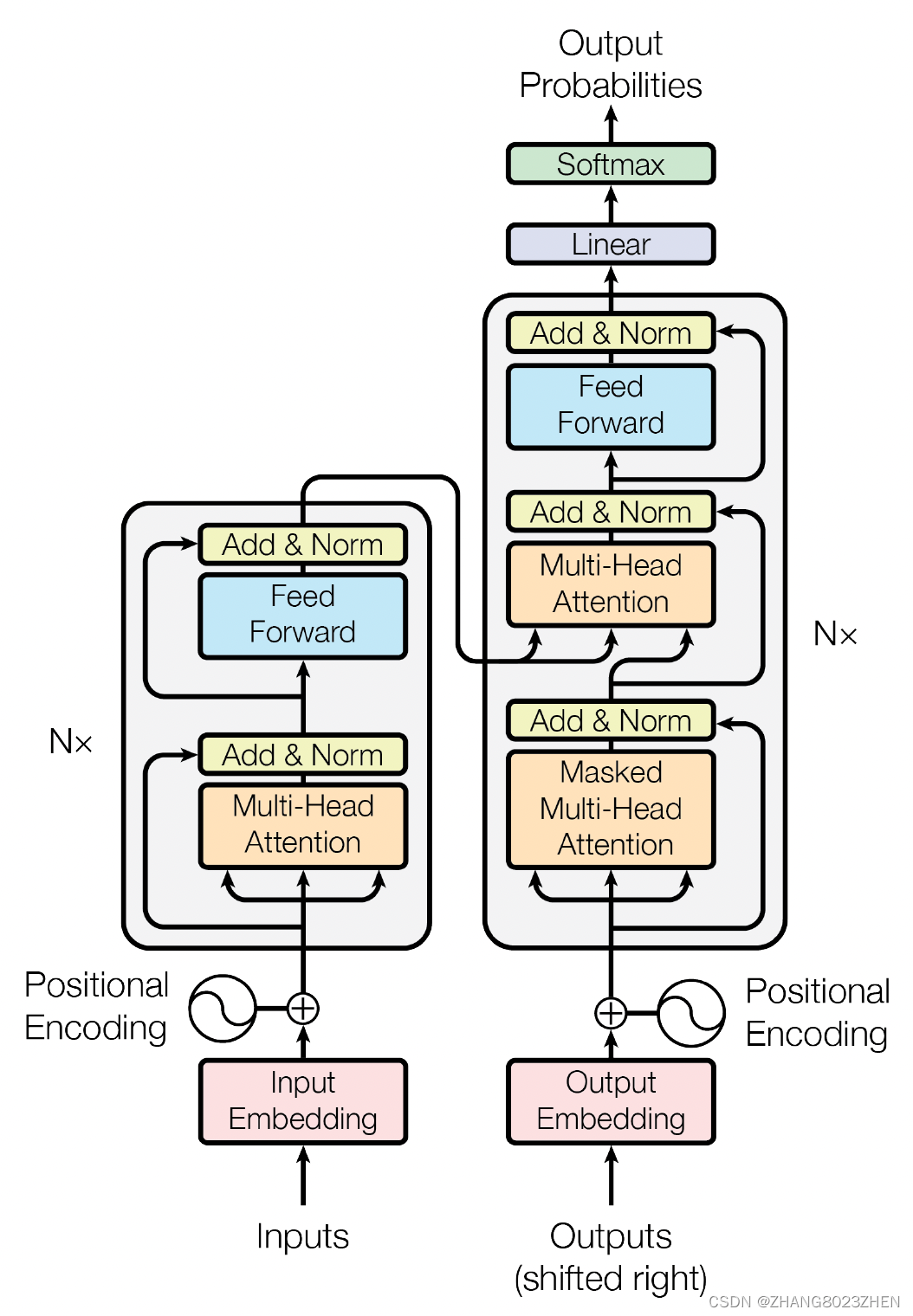
这里N_x = 6, decoder中的输入是将上一轮output向右移一个,可以让embedding只与已知的输出有关。为了防止产生自回归现象,使用一下masked multi-head attention
attention和multi-head attention的形式如下所示,所以self-attention和cross-attention的形式都如下所示,区别是QKV,是否属于同一个输入源。multi-head attention就是将输入拆开均匀分配到各个head中,最后再concat起来,这样可以节省算力。
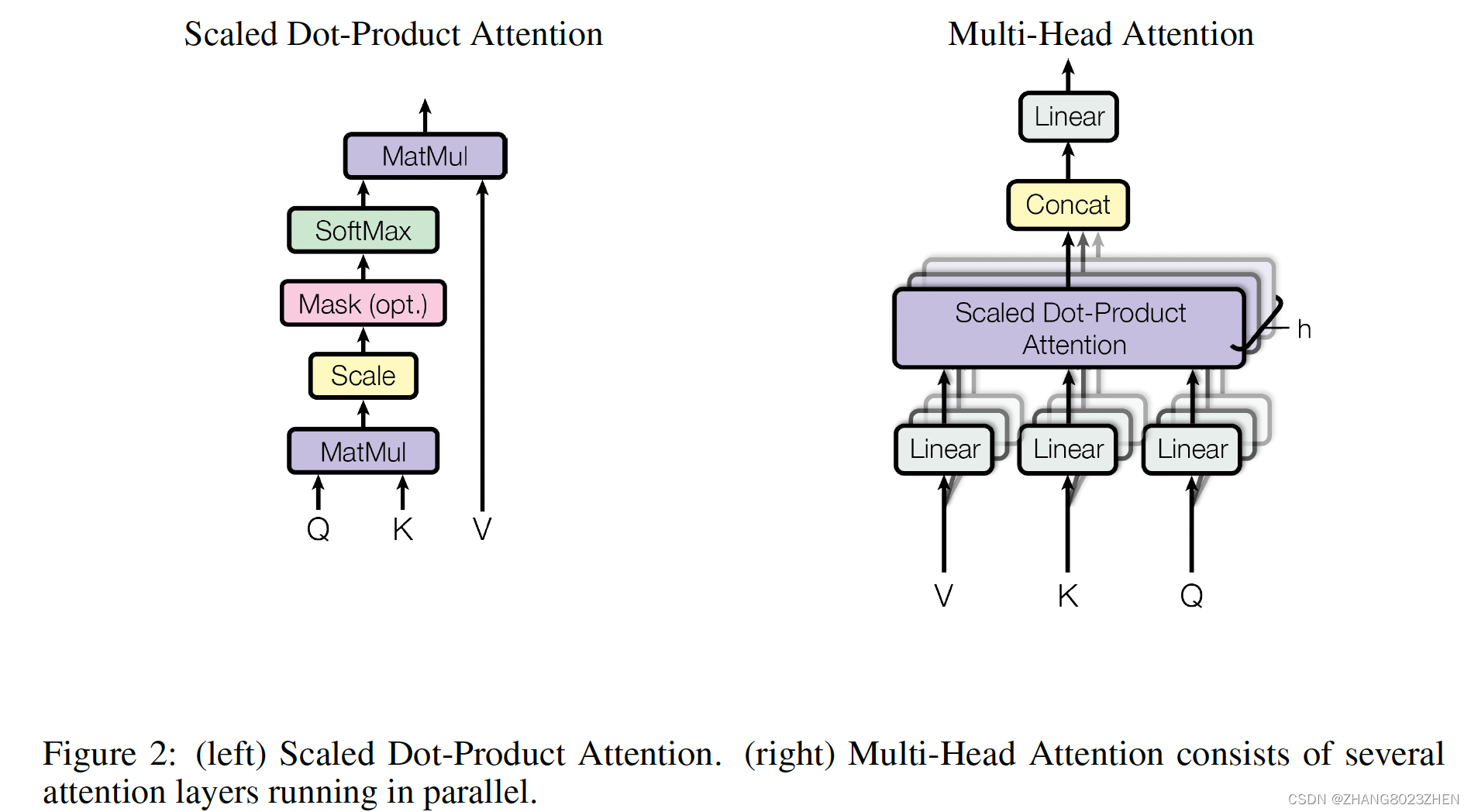
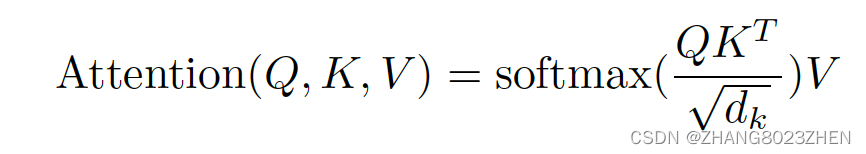
最后输出的大小和Q相同

Positional Encoding的使用方法
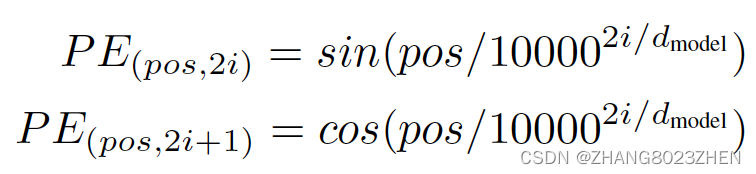
Attention的优势
- 降低了计算的复杂度
- 可以使用multi-head并行计算
- 在长距离关联和理解上面效果更好














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









