






1.问题引入
线性支持向量机模型假设其训练样本是线性可分的,即存在一个超平面将两个类完全分开。然而在现实任务中,或许样本空间根本就不存在一个超平面能进行分类。下图是不存在分类超平面的例子:
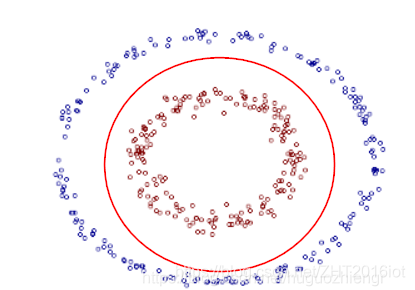
为了解决这个问题,可以将样本从原始空间映射到一个更高的特征空间,使得样本在高维的特征空间变得线性可分。映射到高维一定能线性可分吗?幸运地是,如果原始空间是有限的,则一定存在一个特征高维空间使得样本线性可分。
我们定义映射
ϕ
(
x
)
\phi(x)
ϕ(x)将
x
x
x从m维空间映射到n维空间(n>m),于是在特征空间的超平面表示为:
f
(
x
)
=
w
T
ϕ
(
x
)
+
b
\begin{aligned} f(x) = w^T\phi(x)+b \end{aligned}
f(x)=wTϕ(x)+b
在特征空间的线性SVM模型为:
m
i
n
[
w
,
b
]
1
2
∣
∣
w
∣
∣
2
s
.
t
.
y
i
(
w
T
ϕ
(
x
i
)
+
b
)
≥
1
,
i
∈
[
1
,
m
]
\begin{aligned} &min_{[w,b]}\enspace \cfrac{1}{2}||w||^2 \\\\ &s.t.\enspace y_i(w^T\phi(x_i)+b) \geq 1,i\in[1,m] \end{aligned}
min[w,b]21∣∣w∣∣2s.t.yi(wTϕ(xi)+b)≥1,i∈[1,m]
其对偶问题为:
m
a
x
[
α
]
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
ϕ
(
x
i
)
T
ϕ
(
x
j
)
s
.
t
.
∑
i
=
1
m
α
i
y
i
,
α
i
≥
0
,
i
∈
[
1
,
m
]
\begin{aligned} &max_{[\alpha]}\enspace\sum_{i=1}^m \alpha_i- \cfrac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j\phi(x_i)^T\phi(x_j) \\\\ &s.t.\enspace \sum_{i=1}^m \alpha_i y_i,\enspace\alpha_i \geq0,\enspace i \in[1,m] \end{aligned}
max[α]i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjϕ(xi)Tϕ(xj)s.t.i=1∑mαiyi,αi≥0,i∈[1,m]
从上述表达式中发现,样本向高维空间映射后,难度在于计算
ϕ
(
x
i
)
T
ϕ
(
x
j
)
\phi(x_i)^T\phi(x_j)
ϕ(xi)Tϕ(xj),因为特征空间可能维度很高,甚至是无穷维。故而,我们定义这样一个函数:
k
(
x
i
,
x
j
)
=
ϕ
(
x
i
)
T
ϕ
(
x
j
)
\begin{aligned} k(x_i,x_j) = \phi(x_i)^T\phi(x_j) \end{aligned}
k(xi,xj)=ϕ(xi)Tϕ(xj)
这就是核函数。引入核函数,我们可以避免高维空间的计算,也不用知道
ϕ
(
.
)
\phi(.)
ϕ(.)的具体形式。
2. 核函数
核函数形式如下:
k
(
x
i
,
x
j
)
=
ϕ
(
x
i
)
T
ϕ
(
x
j
)
\begin{aligned} k(x_i,x_j) = \phi(x_i)^T\phi(x_j) \end{aligned}
k(xi,xj)=ϕ(xi)Tϕ(xj)
我们举个例子来说明核函数的强大:
令
X
=
(
x
1
,
x
2
)
T
Y
=
(
y
1
,
y
2
)
T
ϕ
(
X
)
=
(
x
1
2
,
2
x
1
x
2
,
x
2
2
)
T
ϕ
(
Y
)
=
(
y
1
2
,
2
y
1
y
2
,
y
2
2
)
T
k
(
X
,
Y
)
=
ϕ
(
X
)
T
ϕ
(
Y
)
=
x
1
2
y
1
2
+
2
x
1
x
2
y
1
y
2
+
x
2
2
y
2
2
‘
=
(
x
1
y
1
+
x
2
y
2
)
2
=
(
X
T
Y
)
2
\begin{aligned} 令 X=&(x_1,x_2)^T \\ Y=&(y_1,y_2)^T \\ \phi(X)=&(x_1^2,\sqrt{2}x_1x_2,x_2^2)^T \\ \phi(Y)=&(y_1^2,\sqrt{2}y_1y_2,y_2^2)^T \\ \\ k( X,Y)=&\phi(X)^T\phi(Y) \\=&x_1^2y_1^2+2x_1x_2y_1y_2+x_2^2y_2^2` \\=&(x_1y_1+x_2y_2)^2 \\= &(X^TY)^2 \end{aligned}
令X=Y=ϕ(X)=ϕ(Y)=k(X,Y)====(x1,x2)T(y1,y2)T(x12,2x1x2,x22)T(y12,2y1y2,y22)Tϕ(X)Tϕ(Y)x12y12+2x1x2y1y2+x22y22‘(x1y1+x2y2)2(XTY)2
本来
ϕ
(
X
)
T
ϕ
(
Y
)
\phi(X)^T\phi(Y)
ϕ(X)Tϕ(Y)是高维空间的计算,但是
(
X
T
Y
)
2
(X^TY)^2
(XTY)2是低维空间的计算。所以,只要知道核函数的具体形式,就不用知道特征映射
ϕ
(
x
)
\phi(x)
ϕ(x)的具体形式,也不用在高维空间中计算
ϕ
(
X
)
T
ϕ
(
Y
)
\phi(X)^T\phi(Y)
ϕ(X)Tϕ(Y)。那么,所有的函数都能当做核函数使用吗?不是,要满足核函数存在定理。
核函数存在定理: 令
R
R
R是输入空间,
k
(
⋅
,
⋅
)
k(\cdot,\cdot)
k(⋅,⋅)是定义在
R
∗
R
R*R
R∗R上的对称函数,则k是核函数当且仅当其核矩阵
K
K
K是半正定的(特征值大于等于0)。其中
K
K
K如下:
[
k
(
x
1
,
x
2
)
⋅
⋅
⋅
k
(
x
1
,
x
m
)
.
⋅
⋅
⋅
.
.
⋅
⋅
⋅
.
.
⋅
⋅
⋅
.
k
(
x
m
,
x
1
)
⋅
⋅
⋅
k
(
x
m
,
x
m
)
]
\begin{aligned} \begin{bmatrix} k(x_1,x_2)&\cdot\cdot\cdot&k(x_1,x_m) \\ .&\cdot\cdot\cdot&. \\ .&\cdot\cdot\cdot&. \\ .&\cdot\cdot\cdot&. \\k(x_m,x_1)&\cdot\cdot\cdot&k(x_m,x_m) \end{bmatrix} \end{aligned}
⎣⎢⎢⎢⎢⎡k(x1,x2)...k(xm,x1)⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅k(x1,xm)...k(xm,xm)⎦⎥⎥⎥⎥⎤
言下之意,只要一个对称函数的核矩阵是半正定的,它就能当核函数使用。常见核函数如下:
| 名称 | 表达式 | 参数 |
|---|---|---|
| 线性核函 | k ( x i , x j ) = x i T x j k(x_i,x_j)=x_i^Tx_j k(xi,xj)=xiTxj | no |
| 多项式核 | k ( x i , x j ) = ( x i T x j ) d k(x_i,x_j)=(x_i^Tx_j)^d k(xi,xj)=(xiTxj)d | d ≥ 1 d \geq 1 d≥1 |
| 高斯核 | k ( x i , x j ) = e x p ( − ∥ x i − x j ∥ 2 2 σ 2 ) k(x_i,x_j)=exp(-\cfrac{\|x_i-x_j\|^2}{2\sigma^2}) k(xi,xj)=exp(−2σ2∥xi−xj∥2) | σ > 0 \sigma>0 σ>0 |
| 拉普拉斯核 | k ( x i , x j ) = e x p ( − ∥ x i − x j ∥ 2 σ ) k(x_i,x_j)=exp(-\cfrac{\|x_i-x_j\|^2}{\sigma}) k(xi,xj)=exp(−σ∥xi−xj∥2) | σ > 0 \sigma>0 σ>0 |
4.非线性SVM模型求解
引入核函数后,对偶问题为:
m
a
x
[
α
]
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
k
(
x
i
,
x
j
)
s
.
t
.
∑
i
=
1
m
α
i
y
i
,
α
i
≥
0
,
i
∈
[
1
,
m
]
\begin{aligned} &max_{[\alpha]}\enspace\sum_{i=1}^m \alpha_i- \cfrac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_jk(x_i,x_j) \\ &s.t.\enspace \sum_{i=1}^m \alpha_i y_i,\enspace\alpha_i \geq0,\enspace i \in[1,m] \end{aligned}
max[α]i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjk(xi,xj)s.t.i=1∑mαiyi,αi≥0,i∈[1,m]
求解后得到模型为:
f
(
x
)
=
w
T
ϕ
(
x
)
+
b
=
∑
i
=
1
m
α
i
y
i
ϕ
(
x
i
)
T
ϕ
(
x
)
+
b
=
∑
i
=
1
m
α
i
y
i
k
(
x
i
,
x
)
+
b
\begin{aligned} f(x) = &w^T\phi(x)+b\\=&\sum_{i=1}^m\alpha_iy_i\phi(x_i)^T\phi(x)+b\\=&\sum_{i=1}^m\alpha_iy_ik(x_i,x)+b \end{aligned}
f(x)===wTϕ(x)+bi=1∑mαiyiϕ(xi)Tϕ(x)+bi=1∑mαiyik(xi,x)+b
实际上我们只用求解
α
\alpha
α就能得到b,在这里我们任然采用smo算法。前文线性支持向量机已经推导过smo算法,得到迭代式:
α
2
n
e
w
=
α
2
o
l
d
+
y
2
(
E
1
−
E
2
)
η
其
中
K
i
j
=
k
(
x
i
,
x
j
)
η
=
(
K
11
+
K
22
−
2
K
12
)
E
i
=
f
(
x
i
)
−
y
i
=
∑
j
=
1
m
α
j
y
j
K
i
j
+
b
−
y
i
更
新
b
和
α
1
α
1
n
e
w
=
α
1
o
l
d
+
y
1
y
2
(
α
2
o
l
d
−
α
2
n
e
w
)
b
1
n
e
w
=
b
o
l
d
−
E
1
+
y
1
K
11
(
α
1
o
l
d
−
α
1
n
e
w
)
+
y
2
K
12
(
α
2
o
l
d
−
α
2
n
e
w
)
b
2
n
e
w
=
b
o
l
d
−
E
2
+
y
1
K
21
(
α
1
o
l
d
−
α
1
n
e
w
)
+
y
2
K
22
(
α
2
o
l
d
−
α
2
n
e
w
)
\begin{aligned} \alpha_2^{new}=&\alpha_2^{old}+\cfrac{y_2(E_1-E_2)}{\eta} \\\\ 其中\enspace K_{ij}=&k(x_i,x_j) \\ \eta=&(K_{11}+K_{22}-2K_{12}) \\ E_i=&f(x_i)-y_i =\sum_{j=1}^m\alpha_jy_jK_{ij}+b-y_i \\更新b和\alpha_1\\ \alpha_1^{new}=&\alpha_1^{old}+y_1y_2(\alpha_2^{old}-\alpha_2^{new}) \\ b_1^{new}=&b^{old}-E_1+y_1K_{11}(\alpha_1^{old}-\alpha_1^{new})+y_2K_{12}(\alpha_2^{old}-\alpha_2^{new}) \\ b_2^{new}=&b^{old}-E_2+y_1K_{21}(\alpha_1^{old}-\alpha_1^{new})+y_2K_{22}(\alpha_2^{old}-\alpha_2^{new}) \end{aligned}
α2new=其中Kij=η=Ei=更新b和α1α1new=b1new=b2new=α2old+ηy2(E1−E2)k(xi,xj)(K11+K22−2K12)f(xi)−yi=j=1∑mαjyjKij+b−yiα1old+y1y2(α2old−α2new)bold−E1+y1K11(α1old−α1new)+y2K12(α2old−α2new)bold−E2+y1K21(α1old−α1new)+y2K22(α2old−α2new)
代码实现:
首先需要一些辅助函数:
#封装smo参数的数据结构
class dataStruct:
def __init__(self,X,Y):
self.X = X
self.Y = Y#行向量
self.m = X.shape[0]
self.b= 0
self.alphas = np.zeros(self.m)#行向量
#保存Ek中间计算结果的缓存,第一列是序号,第二列是实际值
self.eCache = np.zeros((self.m,2))
#高斯核函数
def kernel(x,y,sigma=0.98):
return math.exp(-1.0*(x-y)@(x-y).T/2*sigma*sigma)
#随机选择一个参数作为alpha_2
def selectJrand(i,m):
j = i
while j == i:
j = np.random.randint(0,m)
return j
#计算误差Ek
def calcEk(k,ds):
fxk = 0.0
for i in range(0,ds.m):
fxk += ds.alphas[i]*ds.Y[i]*kernel(X[i],X[k])
fxk += ds.b
return fxk - ds.Y[k]
#更新误差值
def updateEk(k,ds):
Ek = calcEk(k,ds)
ds.eCache[k] = [k,Ek]
def selectJ(i,Ei,ds):
#先更新Ei
ds.eCache[i] = [i,Ei]
#第二参数的下标
j = -1
max = 0
#有效的误差缓冲列表
validECache = np.where(ds.eCache[:,0] != 0)[0]
#若存在有效值,最大化|Ei - Ej|
if len(validECache) >1:
for k in validECache:
if k == i:continue
Ek = calcEk(k,ds)
if abs(Ei - Ek) > max:
j = k
max = abs(Ei-Ek)
return j
else:#没有,就随机选一个
return selectJrand(i,ds.m)
#计算模型的预测值
def predict(X,Y,x,alphas,b):
fx =0.0
for i in range(0,X.shape[0]):
fx+=alphas[i]*Y[i]*kernel(X[i],x)
return fx+b
smo算法主要的逻辑在内循环上:
#内循环操作
def innerLoop(i,ds):
Ei = calcEk(i,ds)
#若alphai违背KKT条件才进行更新
if (Ei*ds.Y[i] != 0 and ds.alphas[i]>0) or(Ei*ds.Y[i] <0 and ds.alphas[i] == 0):
#选取第二变量
j = selectJ(i,Ei,ds)
Ej = calcEk(j,ds)
#要用深拷贝
Jold = ds.alphas[j].copy()
Iold = ds.alphas[i].copy()
#计算eta
eta = kernel(X[i],X[i]) + kernel(X[j],X[j]) - 2*kernel(X[i],X[j])
#eta=0 不用更新
if eta ==0:return 0
#更新alphas_2
ds.alphas[j] += ds.Y[j] *(Ei - Ej) /eta
if ds.alphas[j] < 0:ds.alphas[j] = 0
updateEk(j,ds)
#alpha_2变化很小,则无需更新
if abs(ds.alphas[j] - Jold) < 1e-6:return 0
#更新alpha_1
ds.alphas[i] += ds.Y[i]*ds.Y[j]*(Jold -ds.alphas[j])
if ds.alphas[i] < 0:ds.alphas[i] = 0
updateEk(i,ds)
#更新b
b1 = ds.b - Ei +ds.Y[i]*(Iold - ds.alphas[i]) *kernel(ds.X[i],ds.X[i])+ds.Y[j]*(Jold - ds.alphas[j])*kernel(ds.X[i],ds.X[j])
b2 = ds.b - Ej +ds.Y[i]*(Iold - ds.alphas[i]) *kernel(ds.X[i],ds.X[j])+ds.Y[j]*(Jold - ds.alphas[j])*kernel(ds.X[j],ds.X[j])
if ds.alphas[i] > 0:
ds.b = b1
elif ds.alphas[j] > 0:
ds.b = b2
else:
ds.b = 1/2*(b1+b2)
return 1
else:return 0
外循环:
#smo算法主体
def smo(X,Y,maxIters):
iters = 0
m,n = X.shape
ds = dataStruct(X,Y)
#外循环
while iters < maxIters:
changed = 0
#内循环
for i in range(0,m):
iters += innerLoop(i,ds)
#迭代至收敛时,changed一定是0
if changed == 0:
iters+=1
return [ds.alphas,ds.b]
一个小小的案例:
#产生数据
n_samples = 100
datasets = [make_moons(n_samples=n_samples, noise=0.2, random_state=0)]
#数据准备
X=np.array(datasets[0][0])
Y=np.array(datasets[0][1])
Y=np.where(Y==0,-1,Y)#0替换成-1
#训练
alphas,b = smo(X,Y,50)
print(alphas)
print(b)
图形绘制:
def figure2D(X,Y,alphas,b):
cls_1x = X[np.where(Y==1)]
cls_2x = X[np.where(Y!=1)]
#画出数据点
plt.scatter(cls_1x[:,0].flatten(), cls_1x[:,1].flatten(), s=30, c='r', marker='s')
plt.scatter(cls_2x[:,0].flatten(), cls_2x[:,1].flatten(), s=30, c='g')
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
#产生网格
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
x = np.c_[xx.ravel(), yy.ravel()]
# SVM的分割超平面
Z=np.zeros(x.shape[0])
for i in range(0,x.shape[0]):
Z[i] = predict(X,Y,x[i],alphas,b)
zz = Z.reshape(xx.shape)
#画出分界面的等高线
plt.contour(xx,yy, zz, cmap='hot', alpha=0.8)
plt.tight_layout()
plt.show()
def figure3D(X,Y,alphas,b):
#数据按分类分割
cls_1x = X[np.where(Y==1)]
cls_2x = X[np.where(Y!=1)]
cls_1y = np.zeros(cls_1x.shape[0])
cls_2y =np.zeros(cls_2x.shape[0])
#计算第三维映射值
for i in range(0,cls_1x.shape[0]):
cls_1y[i] = predict(X,Y,cls_1x[i],alphas,b)
for i in range(0,cls_2x.shape[0]):
cls_2y[i] = predict(X,Y,cls_2x[i],alphas,b)
#绘制3D图形
fig = plt.figure()
ax = Axes3D(fig)
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
#产生网格
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
x = np.c_[xx.ravel(), yy.ravel()]
# SVM的分割超平面
Z=np.zeros(x.shape[0])
for i in range(0,x.shape[0]):
Z[i] = predict(X,Y,x[i],alphas,b)
zz = Z.reshape(xx.shape)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.set_zlim(Z.min()-0.1,Z.max()+0.1)
#画散点图
ax.scatter(cls_1x[:,0].flatten(), cls_1x[:,1].flatten(),cls_1y,c='b')
ax.scatter(cls_2x[:,0].flatten(), cls_2x[:,1].flatten(),cls_2y,c='g')
#画曲面图
ax.plot_wireframe(xx, yy, zz, rstride=30,
cstride=30, linewidth=0.5,
color='orangered')
plt.show()
figure2D(X,Y,alphas,b)
figure3D(X,Y,alphas,b)
平面等高线图:
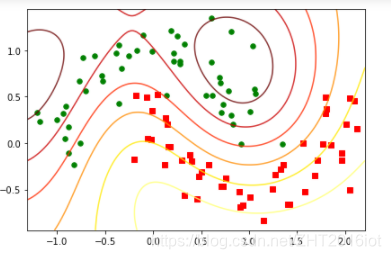
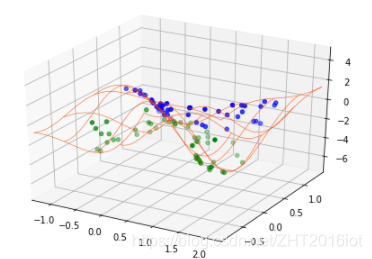
三维空间图:
上面的实验结果是采用高斯核函数得到的,我们现在采用多项式核函数再做一次,得到如下结果:
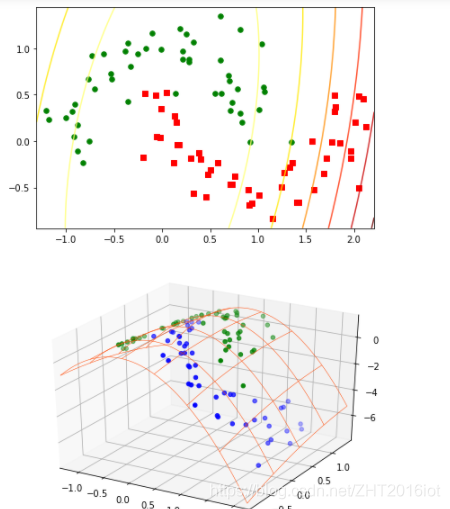
注意: 非线性支持向量机对核函数的选择很敏感,所以选择适当的核函数才能很好的进行分类。















 1724
1724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









