






目录
前言
在语义分割任务的编程实现中,通常会用到膨胀卷积(Dilated convolution),或者说是空洞卷积。那么什么是膨胀卷积呢?Gridding Effect是什么?以及常见的Hybird Dilated Convolution (HDC)膨胀因子如何设计?
1. 什么是膨胀卷积?
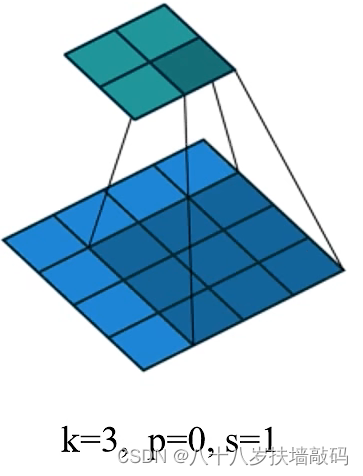
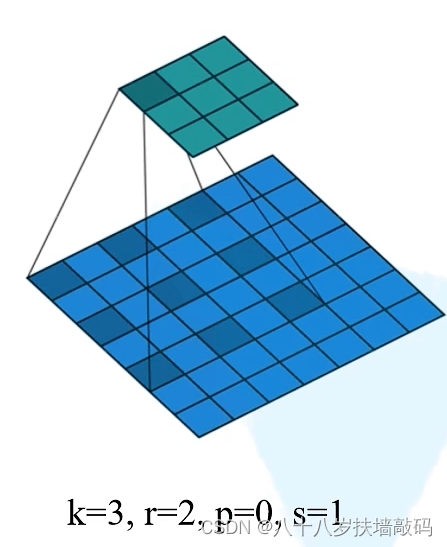
对比普通卷积,在膨胀卷积的Kernel之间存在着间隙,间隙的大小即为膨胀因子,称为r。如下图所示,当r=1时为普通卷积;当r=2时为膨胀卷积。
2. 为什么在语义分割任务中需要用膨胀卷积?
在语义分割任务中,通常会使用分类网络作为backbone,在backbone中会对图片进行一系列的下采样。通过backbone之后,会使用一系列的上采样恢复原来的图片大小。如果特征图的高宽下采样倍率太大的话,还原到原来尺寸后,图片将丢失很多细节信息。
例如,在VGG网络中,通过max pooling层进行池化,这降低了特征图的高度和宽度,也丢失了一些细节信息,而丢失的信息无法通过上采样进行还原,在语义分割任务中将导致分割的效果不理想。而如果去掉max pooling层,将导致特征图的感受野变小。
利用膨胀卷积,既能增大感受野,又能保持输入输出特征图的高和宽不发生变化,解决了上述问题。但是,是否无脑堆叠膨胀卷积就可以了呢?
参考论文Understanding Convolution for Semantic Segmentation,在膨胀卷积使用过程中,会出现gridding effect的问题。
3. Gridding Effect是什么?
考虑以下三个实验。初始化一张
31
×
31
31 \times 31
31×31大小的网格图,每一个格子代表输入layer1上的一个像素,格子内的数字代表经过连续三次膨胀卷积得到layer4后,layer1中该像素总共被使用的次数。

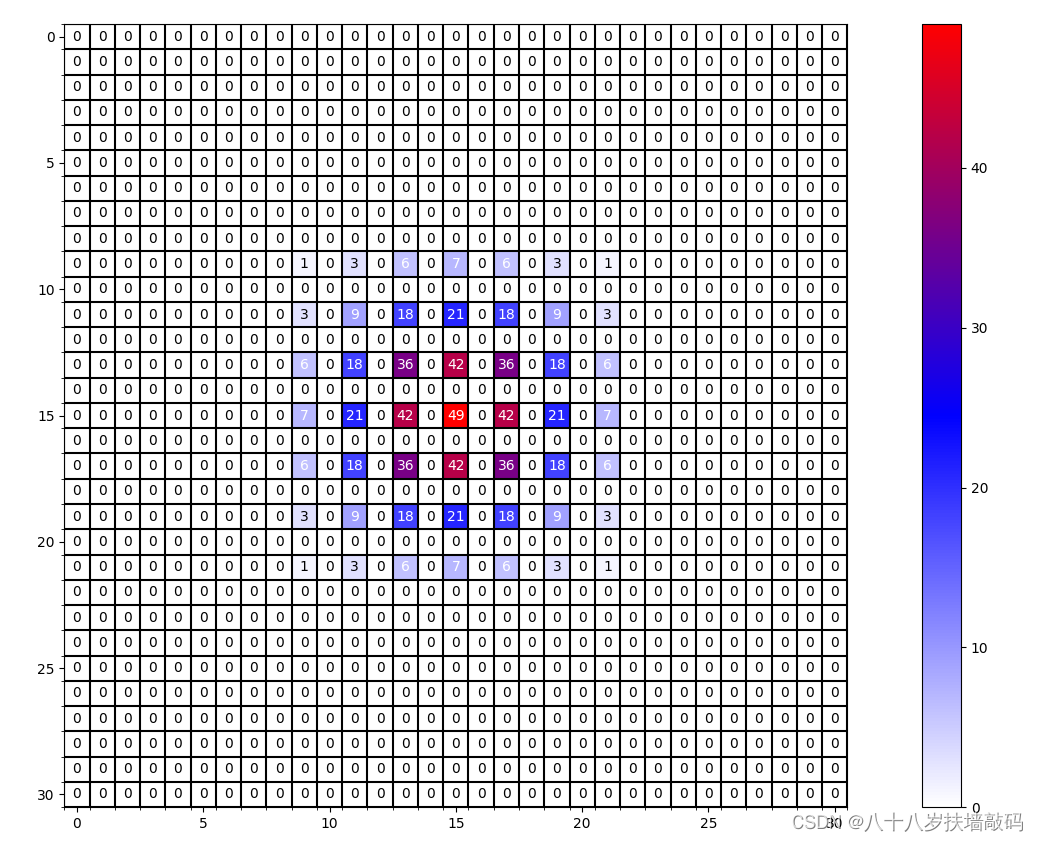
3.1 实验一
连续使用三个膨胀卷积层,卷积核大小是3x3,膨胀因子全部设置为r=2。可以看到,layer4利用到了layer1中 13 × 13 13 \times 13 13×13个像素。但是layer4能够利用到layer1数据并不是连续的,在每个非零元素之间都是有一定间隔的。这就是Griding Effect。
也就是说,layer4并没有利用到layer1上所有的像素值,而只是利用到了其中的一部分,这就会导致丢失一部分细节信息,因此我们在使用膨胀卷积时应尽量避免出现Griding Effect。
3.2 实验二
连续使用三个膨胀卷积层,卷积核大小为3x3,膨胀因子分别设置为r=1、r=2、r=3。可以发现layer4上可以利用到layer1上
13
×
13
13 \times 13
13×13个像素,但是,利用到的数据之间是连续的。

3.3 实验三
连续使用三个膨胀卷积层,卷积核大小为3x3,膨胀因子全部设置为r=1。也就是连续使用三个普通卷积。可以看到在layer4上使用到了layer1中 7 × 7 7 \times 7 7×7个像素,像素之间是连续的。
由于卷积核大小相同,以上三种情况的参数数量是相同的。对比实验二和实验三,可以看到在使用膨胀卷积后,感受野增大了很多。

4. Hybird Dilated Convolution (HDC)
当需要连续使用多个膨胀卷积时,该如何设计膨胀系数?
假设我们要使用 N N N个膨胀卷积,卷积核大小为 K × K K \times K K×K,膨胀系数分别对应 [ r 1 , … , r i , … , r n ] [r_1,\ldots,r_i,\ldots,r_n] [r1,…,ri,…,rn]。HDC的目标是通过一系列膨胀卷积之后,可以是底层特征层中的每一个像素点都能参与到计算中,而没有空洞。
定义第
i
i
i层两个非零值之间的最大距离:
M
i
=
m
a
x
[
M
i
+
1
−
2
r
i
,
M
i
+
1
−
2
(
M
i
+
1
−
r
i
)
,
r
i
]
M_i = max[M_{i+1} - 2r_i, M_{i + 1}- 2(M_{i+1} - r_i), r_i]
Mi=max[Mi+1−2ri,Mi+1−2(Mi+1−ri),ri]
其中,最后一层有 M n = r n M_n = r_n Mn=rn。
第一个设计原则就是: M 2 ≤ K M_2 \leq K M2≤K且 r 1 = 1 r_1=1 r1=1。
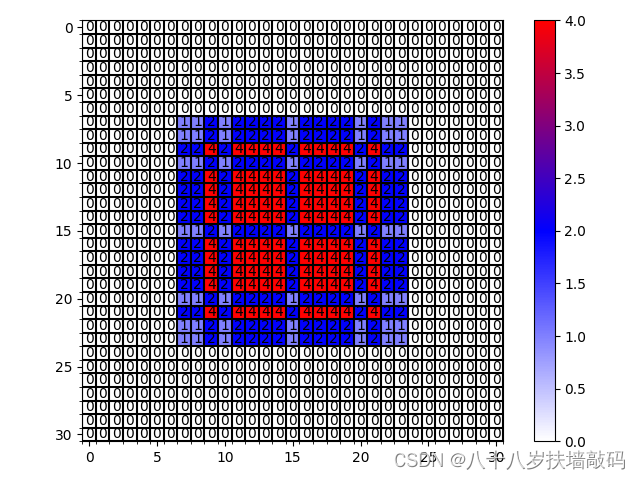
例如:当 K = 3 K=3 K=3, r = [ 1 , 2 , 5 ] r=[1,2,5] r=[1,2,5]时,有 M 3 = r 3 = 5 M_3=r_3=5 M3=r3=5, M 2 = m a x [ 1 , − 1 , 2 ] = 2 M_2 = max[1,-1,2]=2 M2=max[1,−1,2]=2,有 M 2 < 3 M_2<3 M2<3符合设计原则。
如下图,将所有像素值都使用到了。
当
K
=
3
K=3
K=3,
r
=
[
1
,
2
,
9
]
r=[1,2,9]
r=[1,2,9]时,有
M
3
=
r
3
=
9
M_3=r_3=9
M3=r3=9,
M
2
=
m
a
x
[
5
,
−
5
,
2
]
=
5
M_2 = max[5,-5,2]=5
M2=max[5,−5,2]=5,有
M
2
>
3
M_2>3
M2>3不符合设计原则。
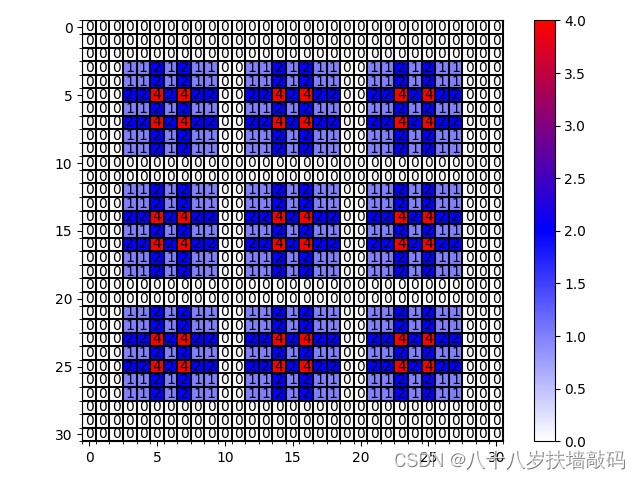
第二个设计原则就是:将膨胀因子r设置为锯齿结构,例如: [1, 2, 3, 1, 2, 3]
5. 效果对比

第一行是GT(Ground Truth),即人为标注的分割效果。
第二行是没有按照HDC设计准则设计的分割效果。在预测结果中很多细节信息保留得不是很好。
第三行是使用了HDC设计准则得分割效果。对比第二行明显效果要好一些。















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









