






前言
SINet来自于CVPR2020的一篇文章,在伪装目标语义分割任务中取得了SOTA的效果。截至2023年3月,其改进版本SINet-V2仍然在CAMO数据集上保持SOTA的效果。
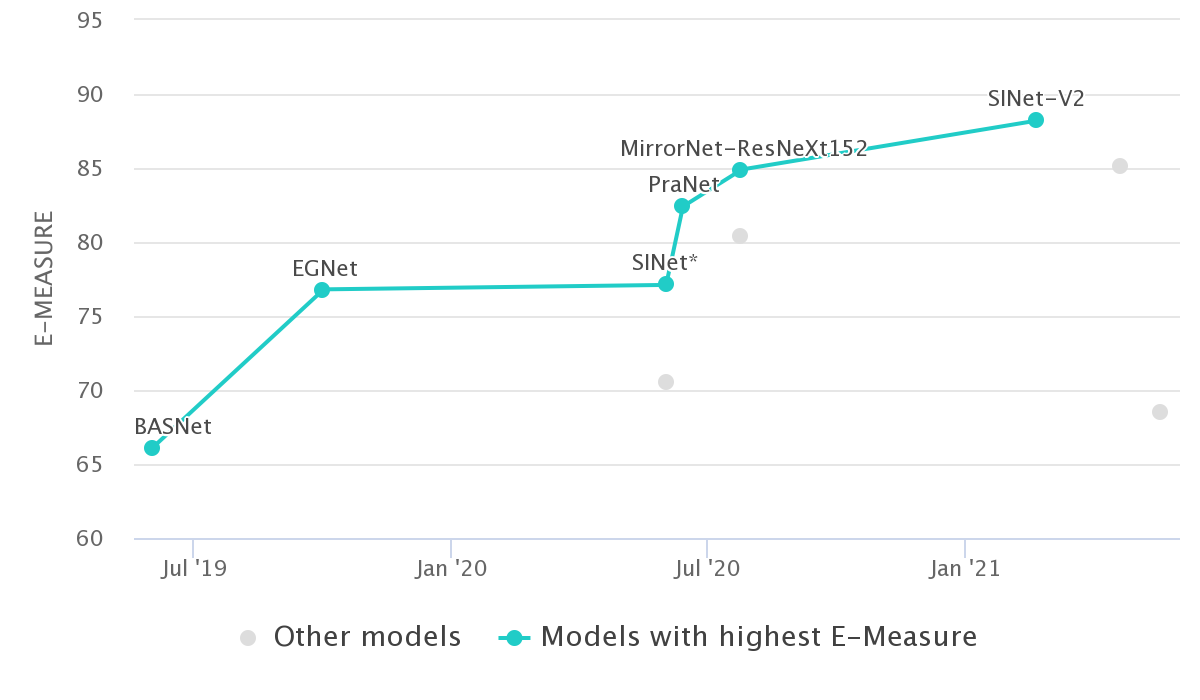
受到自然界中捕食者狩猎过程的启发,SINet框架包括两个主要的模块:
- 搜索模块(SM):负责搜索伪装物体(寻找猎物)
- 识别模块(IM):用于精确探测伪装物体(识别目标动物)
网络结构如下所示:
1. 搜索模块(SM)
1.1 整体结构
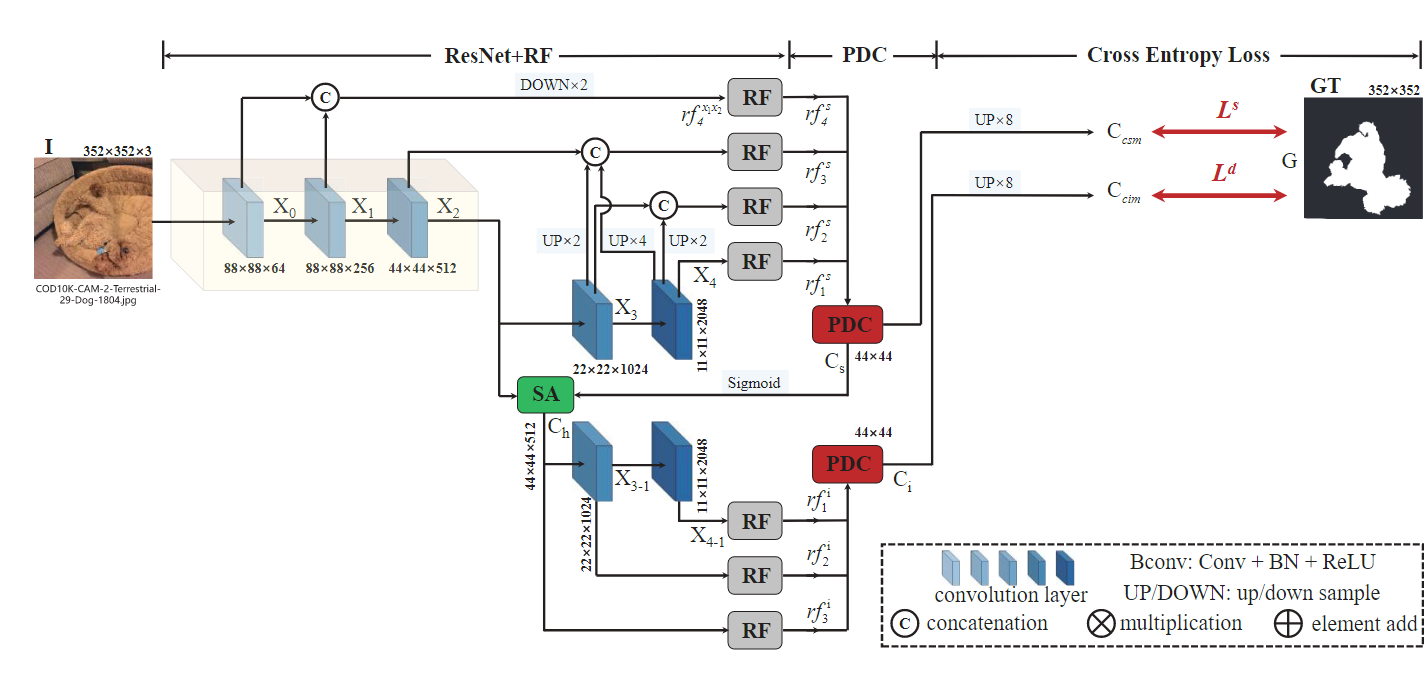
搜索模块整体结构如下图所示。主要由ResNet50的backbone和RF(Receptive Fields)组成。其中,对ResNet50进行了简单修改。
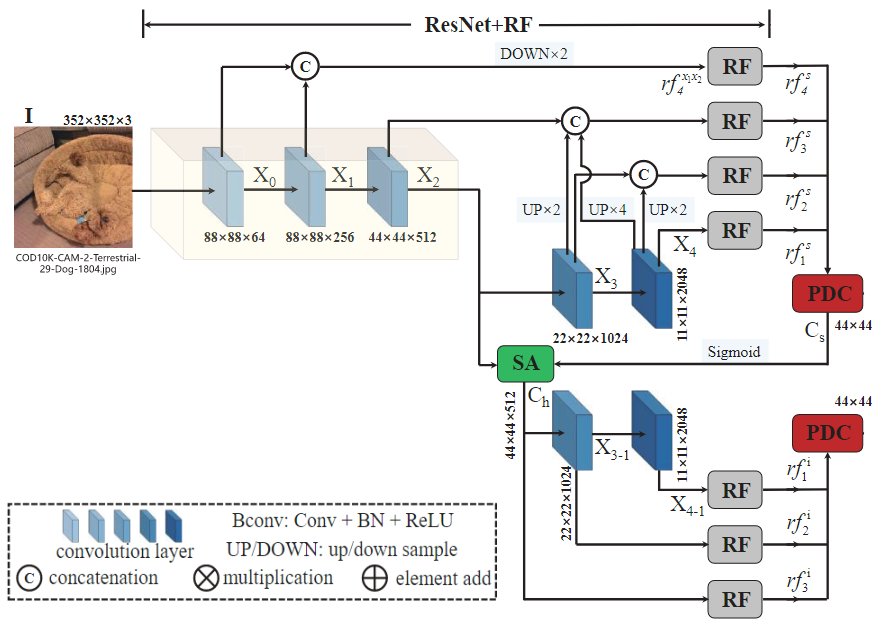
具体来说,对于 I ∈ R W × H × 3 I \in \mathbb R^{W \times H \times 3} I∈RW×H×3的输入图像,利用ResNet50提取一组4个不同维度的特征 { X k } k = 0 4 \lbrace X_k \rbrace ^4_{k=0} {Xk}k=04。为了保留更多的信息,将步距修改为 stride=1 ,这样第二层输出特征图和第一层保持了相同大小的尺寸。每层特征图的尺寸大小可以表示为 { [ H k , H k ] , k = 4 , 4 , 8 , 16 , 32 } \lbrace [\frac{H}{k}, \frac{H}{k}], k=4,4,8,16,32 \rbrace {[kH,kH],k=4,4,8,16,32}。
由于浅层中的低级特征保留了构建对象边界的空间细节,而深层中的高级特征保留了定位对象的语义信息,因此将提取的特征分为低级 { X 0 , X 1 } \lbrace X_0, X_1 \rbrace {X0,X1},中级 { X 2 } \lbrace X_2 \rbrace {X2},高级 { X 3 , X 4 } \lbrace X_3, X_4 \rbrace {X3,X4}。通过连接、上采样和下采样操作对不同层级的特征进行组合,然后使用改进的RF组件来扩大感受野。例如,通过连接操作融合低级特征 { X 0 , X 1 } \lbrace X_0, X_1 \rbrace {X0,X1},然后下采样将特征图尺寸减半,最后输入到RF组件中生成特征 r f 4 s {rf}^s_4 rf4s。如上图中所示,将 { X 0 , X 1 , X 2 , X 3 , X 4 , X 5 } \lbrace X_0, X_1,X_2, X_3,X_4, X_5 \rbrace {X0,X1,X2,X3,X4,X5}组合后,得到一组增强特征 r f k s , k = 1 , 2 , 3 , 4 {rf}^s_k, k=1,2,3,4 rfks,k=1,2,3,4。
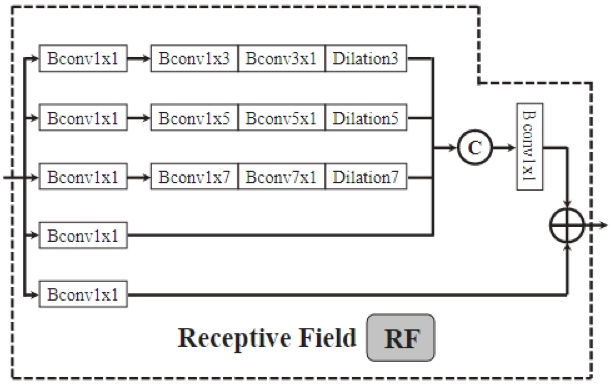
1.2 RF组件
其中,RF组件的具体结构图下图所示,借鉴了ECCV2018的论文RFB Net。模仿人类视觉系统中的空间阵列,具有多个不同的关注中心,并且距离视觉中心越近,其感受野越小、越关注局部特征;距离视觉中心越远,其感受野越大、越关注全局特征。由多个具有不同感受野的部分复合而成。相比于一般的CNN每层固定感受野,可以同时综合不同大小的视野。
大致思想就是通过调整膨胀卷积的膨胀率,来调节关注中心的位置和感受野的大小。例如 5 × 5 5 \times 5 5×5卷积的关注中心和全图中心的距离比 3 × 3 3 \times 3 3×3和 1 × 1 1 \times 1 1×1的更远、感受野也更大。然后,再将不同尺度的特征图连接起来。
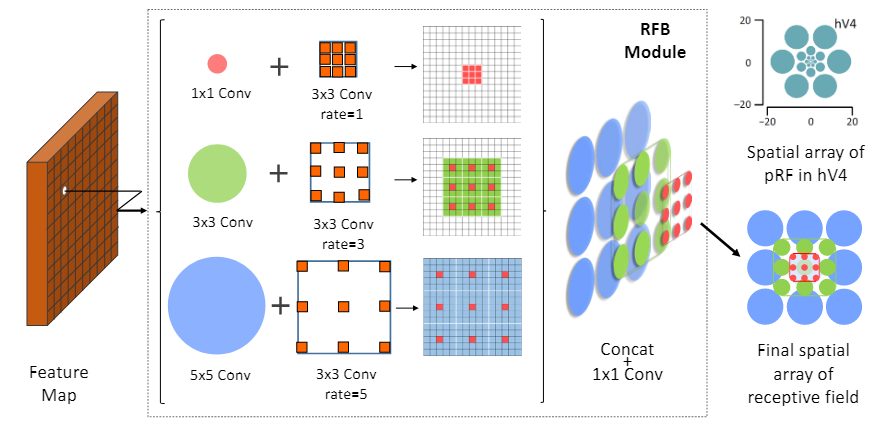
整体包含五个分支 { b k , k = 1 , … , 5 } \lbrace b_k, k=1, \ldots, 5 \rbrace {bk,k=1,…,5}。
第一个卷积核大小为 1 × 1 1 \times 1 1×1,将通道数减少到32。主要用于减少计算量和进行跨通道的信息融合。
然后是一个 ( 2 k − 1 ) × ( 2 k − 1 ) (2k-1) \times (2k-1) (2k−1)×(2k−1)的Bconv层和一个当 k > 2 k > 2 k>2时膨胀因子为(2k-1)的 3 × 3 3 \times 3 3×3膨胀卷积层。 1 × 3 1 \times 3 1×3和 3 × 1 3 \times 1 3×1卷积用于替代 3 × 3 3 \times 3 3×3卷积,同样用于减少参数量的目的。
将前四个分支的输出特征图连接起来,通过 1 × 1 1 \times 1 1×1的卷积操作将通道数减少到32。源代码中,连接操作实际上是将四个分支的输出特征图在channel方向连接,然后使用一个输入通道数为 4 × c h a n n e l 4 \times channel 4×channel、输出通道数为 c h a n n e l channel channel、大小为 3 × 3 3 \times 3 3×3的卷积核完成。
class RF(nn.Module):
def __init__(self, in_channel, out_channel):
···
self.conv_cat = BasicConv2d(4*out_channel, out_channel, 3, padding=1)
···
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x_cat = self.conv_cat(torch.cat((x0, x1, x2, x3), dim=1))
x = self.relu(x_cat + self.conv_res(x))
return x
最后与第五个分支的输出相加,作为shortcut操作避免反向传播过程中梯度爆炸或梯度消失。将结果输入到ReLU函数,得到特征 r f k {rf}_k rfk。
2. 识别模块(IM)
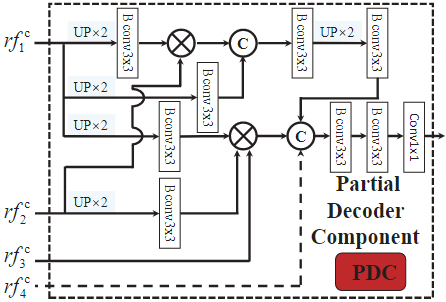
将搜索模块输出的四个特征 r f k {rf}_k rfk输入到部分解码器组件(PDC)中,得到一个粗略的伪装图 C s C_s Cs:
C s = P D s ( r f 1 s , r f 2 s , r f 3 s , r f 4 s ) C_s={PD}_s({rf}_1^s,{rf}_2^s,{rf}_3^s,{rf}_4^s) Cs=PDs(rf1s,rf2s,rf3s,rf4s)
部分解码器组件(PDC)的结构如下所示。给定搜索和识别阶段的特征 { r f k c , k ∈ [ m , … , M ] , c ∈ [ s , i ] } \lbrace {rf}_k^c, k \in [m,\ldots,M],c \in [s,i] \rbrace {rfkc,k∈[m,…,M],c∈[s,i]},进行上采样、连接、元素乘法、卷积等一系列操作后得到融合后的输出特征 C i C_i Ci或 C s C_s Cs。
PDC模块在搜索阶段(SM)和识别阶段(IM)的区别在于搜索阶段输入特征层有4层,而识别阶段只输入了3层。
有研究表明,注意力机制可以有效消除不相关特征的干扰,因此引入搜索注意力(SA)模块来增强中级特征 X 2 X_2 X2,这样就避免了因网络太深、下采样过多而损失浅层特征中对象边界信息,同时也融合了深层网络学习到的的语义信息。
获得增强的伪装图 C h C_h Ch:
C h = f m a x ( g ( X 2 , σ , λ ) , C s ) C_h=f_{max}(g(X_2,\sigma,\lambda),C_s) Ch=fmax(g(X2,σ,λ),Cs)
其中, g ( ⋅ ) g(\cdot) g(⋅)即为SA函数,实际上是一个典型的高斯滤波器,然后进行归一化运算。 f m a x ( ⋅ ) f_{max}(\cdot) fmax(⋅)是一个极大值函数,用以突出 C s C_s Cs的初始伪装区域。
源代码中,以SM阶段PDC的输出和中级特征 X 2 X_2 X2作为输入。将SM阶段PDC的输出及其高斯滤波后的结果作为注意力,对 X 2 X_2 X2进行处理。
首先对SM阶段PDC的输出做了sigmoid处理,作为一个attention注意力分布,大小[minibatch,in_channels,iH,iW] = [36, 1, 44, 44],使用大小[out_channels,in_channels,kH,kW] = [1, 1, 31, 31]的高斯滤波器对其做卷积运算。然后对其做离散标准化,将数据值映射到[0,1]之间。将其与原来输入的注意力分布比较,取较大值,再与中级特征 X 2 X_2 X2做元素乘法,得到输出。
class SA(nn.Module):
"""
holistic attention src
"""
def __init__(self):
super(SA, self).__init__()
gaussian_kernel = np.float32(_get_kernel(31, 4))
gaussian_kernel = gaussian_kernel[np.newaxis, np.newaxis, ...]
self.gaussian_kernel = Parameter(torch.from_numpy(gaussian_kernel))
def forward(self, attention, x):
soft_attention = F.conv2d(attention, self.gaussian_kernel, padding=15)
soft_attention = min_max_norm(soft_attention) # normalization
x = torch.mul(x, soft_attention.max(attention)) # mul
return x
为了整合高级特征,将 X 3 X_3 X3、 X 4 X_4 X4和 C h C_h Ch通过RF特征增强,再输入到PDC模块中获得最终伪装图 C i C_i Ci。
3. 损失函数
使用交叉熵损失函数对SINet进行训练,总体可表示为下式:
L = L C E s ( C c s m , G ) + L C E i ( C c i m , G ) L=L_{CE}^s (C_{csm},G)+L_{CE}^i (C_{cim},G) L=LCEs(Ccsm,G)+LCEi(Ccim,G)
其中, C c s m C_{csm} Ccsm和 C c i m C_{cim} Ccim是将[36, 1, 44, 44]的 C s C_s Cs和 C i C_i Ci上采样8倍到 352 × 352 352 \times 352 352×352大小后获得的两个伪装目标特征图。
def trainer(train_loader, model, optimizer, epoch, opt, loss_func, total_step):
model.train()
for step, data_pack in enumerate(train_loader):
···
cam_sm, cam_im = model(images)
loss_sm = loss_func(cam_sm, gts)
loss_im = loss_func(cam_im, gts)
loss_total = loss_sm + loss_im
···

















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









