







 本文详细介绍了线性回归、感知机、逻辑回归和SVM的基础知识和原理。线性回归通过最小化均方误差进行参数学习;感知机基于误分类点到超平面的总距离进行优化;逻辑回归引入sigmoid函数解决二分类问题,最大化似然估计;SVM选择最能分离两类样本的超平面,损失函数为合页函数,重点关注支持向量。四种方法在处理问题上有其独特之处,各有侧重。
本文详细介绍了线性回归、感知机、逻辑回归和SVM的基础知识和原理。线性回归通过最小化均方误差进行参数学习;感知机基于误分类点到超平面的总距离进行优化;逻辑回归引入sigmoid函数解决二分类问题,最大化似然估计;SVM选择最能分离两类样本的超平面,损失函数为合页函数,重点关注支持向量。四种方法在处理问题上有其独特之处,各有侧重。
线性回归
线性回归是一个回归问题,即用一条线去拟合训练数据。
模型:根据训练数据学习一个特征的线性组合,作为预测函数。

学习策略:最小化均方误差损失函数,求解参数w;(注意与感知机的区别,此处误分类点与坐标轴垂直)


求解方法: 最小二乘法,梯度下降法(两者的区别)
最小二乘法:对目标损失函数求导,导数为零的点对应的参数,就是待求参数:
均方误差函数:
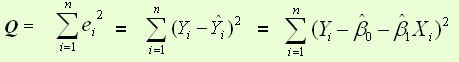
目标函数对参数的偏导:
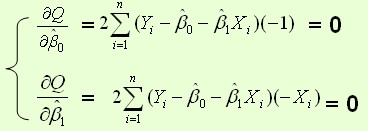
导数为零的点,就是极值点:
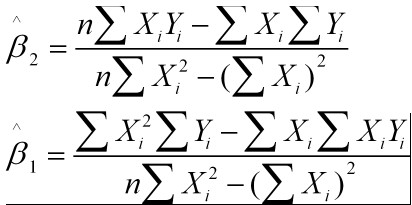
梯度下降法:
曲面上沿着梯度的方向是函数值变化(增大)最快的方向,因此要得到J(w)最小值,应该沿着梯度的反方向,使用沿着梯度的反方向进行权重的更新,可以有效的找到全局的最优解。

更新过程:

梯度下降(batch gradent):W的每一次更新,使用所有的样本。计算得到的是一个标准梯度。更新一次的幅度较大,样本不大的情况,收敛速度可以接受;但是若样本太大,收敛会很慢。
随机梯度下降(stochastic gradient decsent ):随机 — 每次使用训练数据中的一个样本更新,因而随机梯度下降是会带来一定的问题,因为计算得到的并不是准确的一个梯度,容易陷入到局部最优解中。一直不会收敛,只是在最小值附近波动。
批量梯度下降(mini-batch):批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的样本。即:每次更新w使用一批样本。
步长太小,收敛速度太慢
步长太大,会在最佳收敛点附近徘徊
最小二乘法与梯度下降法的异同:
实现实现不同:最小二乘法是直接对 Δ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9866
9866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









