










2023年5月来自华盛顿大学、斯坦福大学、韩国KAIST和Meta的论文“REPLUG: Retrieval-Augmented Black-Box Language Models“。
REPLUG(retrieval-and-plug),这是一个检索增强的语言建模框架,它将语言模型(LM)视为一个黑盒子,并用可调的检索模型对其进行增强。与先前的检索增强LM不同,前者训练具有特殊交叉注意机制的语言模块来对检索的文本进行编码,REPLUG只是将检索的文档预先放到冻结黑盒子LM的输入中。这种简单的设计可以很容易地应用于任何现有的检索和语言模型。此外,证明LM可以用于监督检索模型,然后可以找到帮助LM做出更好预测的文档。实验表明,带有可调优检索器的REPLUG,显著在GPT-3(175B)语言建模上的性能提高了6.3%,在五样本MMLU(Massive Multitask Language Understanding)基准上Codex的性能提高5.1%。
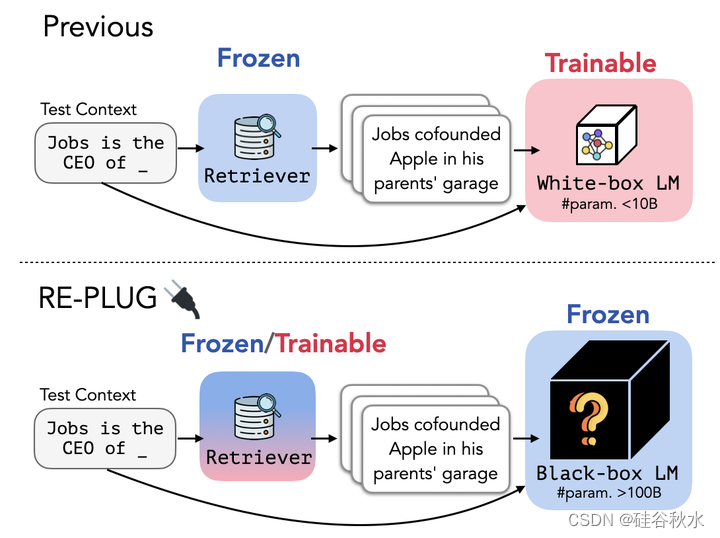
如图所示:与之前通过更新LM参数来增强语言模型的检索增强方法(Borgeud 2022)不同,REPLUG将语言模型视为黑匣子,并用冻结或可调优的检索器对其进行增强。这种黑盒子假设使REPLUG适用于大型LMs(即>100B参数),这些LMs通常通过API提供服务。
还有REPLUG-LSR(REPLUG with LM-Supervisored Retrieval),这是一种训练方案,可以利用黑盒子语言模型的监督信号进一步改进REPLUG中的初始检索模型。关键思想是使检索器适应LM,这与之前让语言模型适应检索器的工作(Borgeud2022)形成了鲜明对比。用一个训练目标,其倾向于检索能够改善语言模型复杂度(perplexity)的文档,同时将LM视为一个冻结的黑盒子评分函数。
如图所示,在给定输入上下文的情况下,REPLUG首先用检索器从外部语料库中检索一小批相关文档。然后,通过LM的并行工作,每个检索文档和输入上下文的连接传递下去,并集成预测概率。
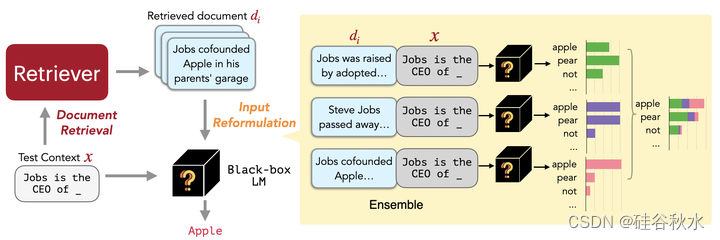
不再仅仅依赖于现有的神经密集检索模型(Karpukhin2020a;Izacard2022a;Su2022),作者而是进一步提出REPLUG LSR(REPLUG with LM Supervisored retrieval),用LM本身来提供对应检索哪些文档的监督,从而调整REPLUG中的检索器。
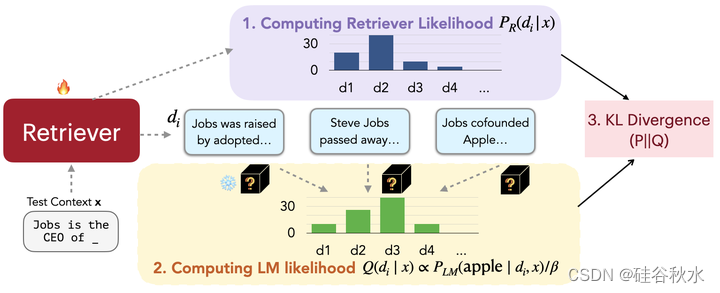
受(Sachan2022)的启发,本文方法可以被视为调整检索文档的概率,匹配语言模型输出序列复杂度的概率。换句话说,希望检索器能够找到导致复杂度得分较低的文档。如图所示,该训练算法由四个步骤组成:(1)检索各文档并计算检索似然,(2)通过语言模型对检索文档进行评分,(3)最小化检索似然和LM得分分布之间的KL divergence,更新检索模型参数,以及(4)数据存储索引的异步更新。















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









