






 |  |
|---|
项目demo效果非常惊艳,仔细看了之后又发现工作量很大,Pipeline很复杂,即使Supplementary Material中补充了很多信息,但具体细节估计需要详细看代码才能清楚了。看文章的排版和挂到arxiv的时间,应该是投CVPR2024了,可以期待一下完整代码。
摘要:实际视频模拟在从虚拟现实到电影制作的多样化应用中显示出巨大的潜力,特别是在现实世界环境中拍摄视频不切实际或成本过高的情况下。现有的视频模拟方法常常无法准确地模拟光照环境、表现物体几何形状或达到高水平的照片级真实感。在这篇论文中,提出了一个名为“任何物体在任何场景”(Anything in Any Scene)的新型通用视频模拟框架,它能够无缝地将任何物体插入到现有的动态视频中,强调物理真实性。文章提出的通用框架包括三个关键过程:1) 将逼真的物体整合到给定场景视频中,并进行适当放置以确保几何真实性;2) 评估天空和环境光分布,并模拟逼真的阴影以增强光照真实性;3) 使用风格转换网络优化最终视频输出,以最大化照片级真实感。我们通过实验证明,“任何物体在任何场景”框架能够生成具有极高几何真实性、光照真实性和照片级真实感的模拟视频。通过显著减轻与视频数据生成相关的挑战,该方法为获取高质量视频提供了一个高效且成本效益的解决方案。此外,它的应用远不止于视频数据增强,还在虚拟现实、视频编辑以及其他许多以视频为中心的应用中显示出了有希望的潜力。
CODE(未完全开源):https://anythinginanyscene.github.io/
Pipeline:
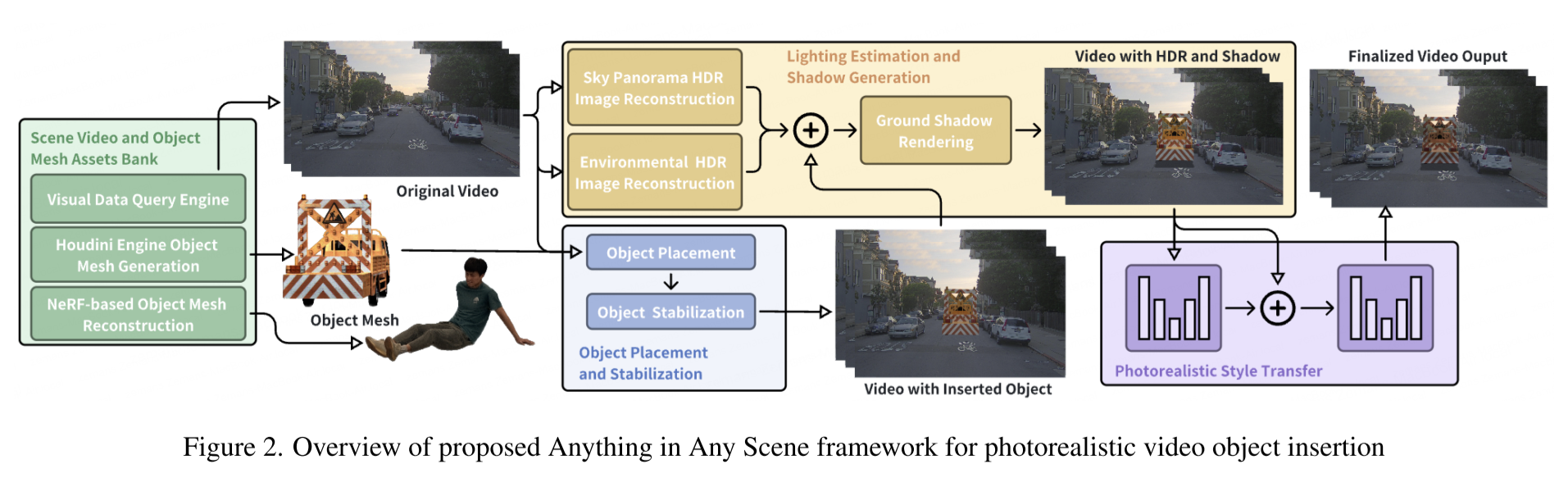
1. Assets Bank
根据video的场景和内容检索匹配的object,并获取带mesh的模型。
2. object placement & stabilization
a. Placement
这一步的目标是确定object放置的坐标,使其处于合理位置并且不遮挡当前帧内已经存在的object。
首先,对场景进行3D重建,这样做一方面是3D场景中进行选取坐标可以更不容易被视角限制,另一方面为了后续在不同帧内对同一object不同视角更好的保持一致性。将世界坐标系
O
w
=
[
0
,
0
,
0
,
1
]
O_w=[0,0,0,1]
Ow=[0,0,0,1]的点转换到像素坐标系的一点
o
~
n
\widetilde{o}_n
o
n, 并且只选取mask内的区域(使用训好分割模型,分割出不会遮挡其他物体的合理区域
M
^
1
\hat{M}_1
M^1)。即下述公式:
o
~
n
=
K
[
R
n
∣
t
n
]
O
w
\tilde{o}_n = K[R_n | t_n]O_w
o~n=K[Rn∣tn]Ow

b. Stabilization
考虑同一object在不同帧内的坐标(frame间的时域信息),使object在不同帧之间的位置更稳定。
优化像素坐标系到世界坐标系的两个变换矩阵-旋转矩阵
R
n
R_n
Rn和 转换向量
t
n
t_n
tn,使通过变换得到的坐标
p
^
n
\hat{p}_n
p^n(利用物体的世界坐标得到的估计量) 与利用光流进行tracking(使用下一帧计算光流) 得到
p
^
n
\hat{p}_n
p^n 之间的error:
(
R
n
,
t
n
)
=
arg
min
(
R
n
,
t
n
)
∑
i
=
1
M
(
p
^
i
−
p
n
)
2
=
arg
min
(
R
n
,
t
n
)
∑
i
=
1
M
(
p
^
i
−
K
[
R
n
∣
t
n
]
P
w
)
2
(R_n, t_n) = \arg\min_{(R_n, t_n)} \sum_{i=1}^{M} (\hat{p}_i - p_n)^2 = \arg\min_{(R_n, t_n)} \sum_{i=1}^{M} (\hat{p}_i - K[R_n | t_n]P_w)^2
(Rn,tn)=arg(Rn,tn)mini=1∑M(p^i−pn)2=arg(Rn,tn)mini=1∑M(p^i−K[Rn∣tn]Pw)2
3. Lighting Estimation and Shadow Generation
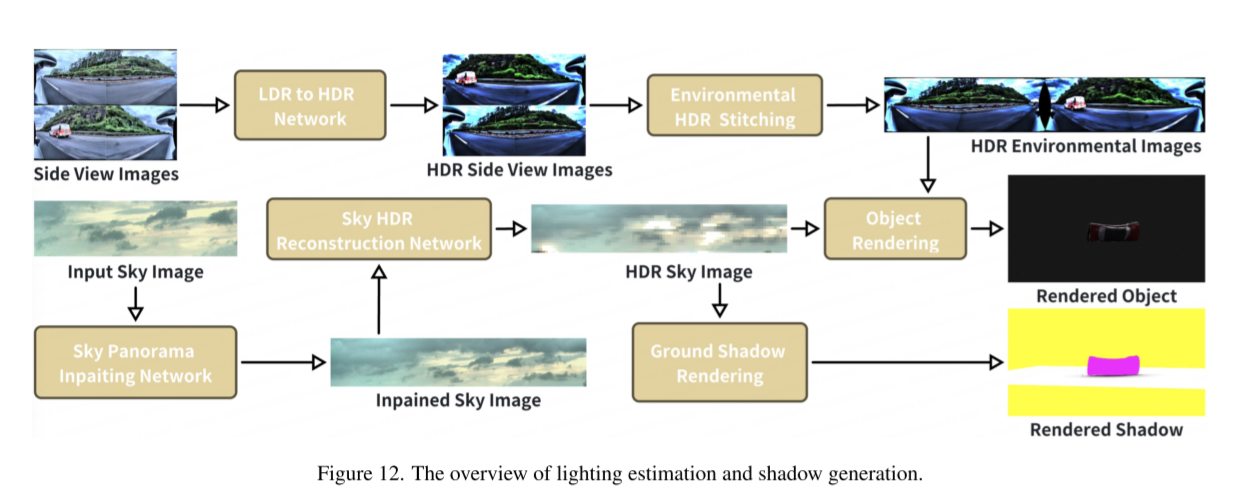
为了得到更真实的光照效果与阴影效果,需要对场景内的光源进行估计,分为太阳光源与环境光源两部分,并基于光源分布对阴影进行渲染。
a. 光源分布估计
第一步,由于input的可视范围较小,可能会忽略掉周围一些光源信息从而影响渲染的结果,所以首先使用Inpainting(使用了image-to-image的diffusion model)得到包含更多的光源信息的全景图片.
第二步,Luminance Distribution Estimation太阳光源分布估计,输入全景LDR(Low Dynamic Dange)图片,输出HDR map
L
L
L。采用GAN训练的U-net,HDR map由sky region luminance distribution与sun region luminance distribution组成,前者采用Resnet做backbone,后者采用VGG16。

第三步,Environmental HDR Image Reconstruction环境光源分布估计,使用视频连续帧作为场景不同视角,得到HDR全景多视角图片,能够为渲染提供全方位的光照信息。

b. 阴影渲染
HDR天空和环境图像被集成在一起,以便在渲染过程中对插入的对象实现逼真的光照效果。此外,我们利用估算出的HDR天空图像为插入的对象渲染阴影,为此使用了3D图形应用程序Vulkan。
4. 真实风格转换
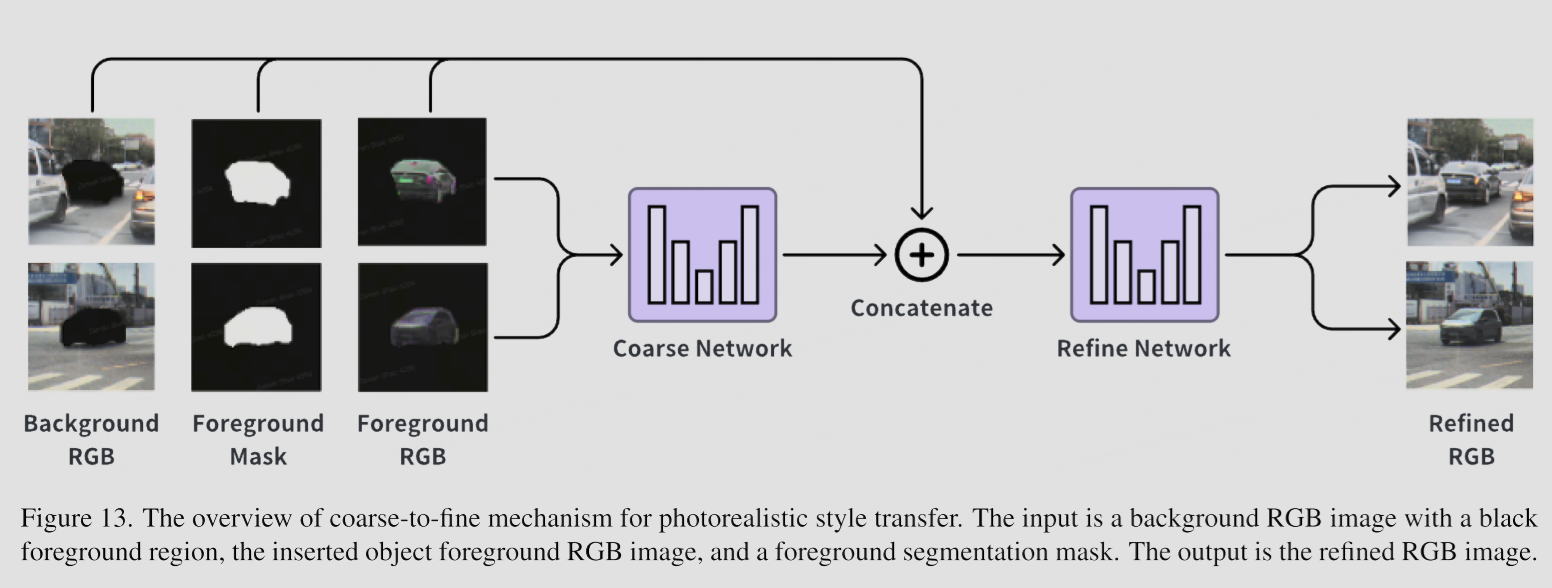
采用coarse-to-fine的模式,用类似inpainting的方式进行实现(只需要对插入的foreground object进行 style transfer, background不用改变)。输入包括三部分:Background、mask、foreground,首先将这三部分输入送入coarse network得到coarse output,再将三部分输入与coarse output一起输入Refine network得到最终结果。
这里有一个疑问,输入object应该是和当前background风格不一致的,再使用object的真实风格作为gt进行训练,那么输入的object风格是如何得到的,文中并没有提到。
实验
实验部分,除了大量的可视化结果展示以外,除了常用的FID指标以外,作者还进行A/B test,从人类的主观判断准确性来评价方法的效果。
Human score定义为:
t
i
m
e
s
o
f
r
e
s
u
l
t
s
b
y
m
e
t
h
o
d
A
s
e
l
e
c
t
e
d
t
o
t
a
l
t
i
m
e
s
o
f
r
e
s
u
l
t
s
b
y
m
e
t
h
o
d
A
a
n
d
B
s
e
l
e
c
t
e
d
\frac{times\ of\ results\ by\ method\ A\ selected}{total\ times\ of\ results\ by\ method\ A\ and\ B\ selected}
total times of results by method A and B selectedtimes of results by method A selected
主要体现method A 对比baseline method B 在人类判断下有多大提升。
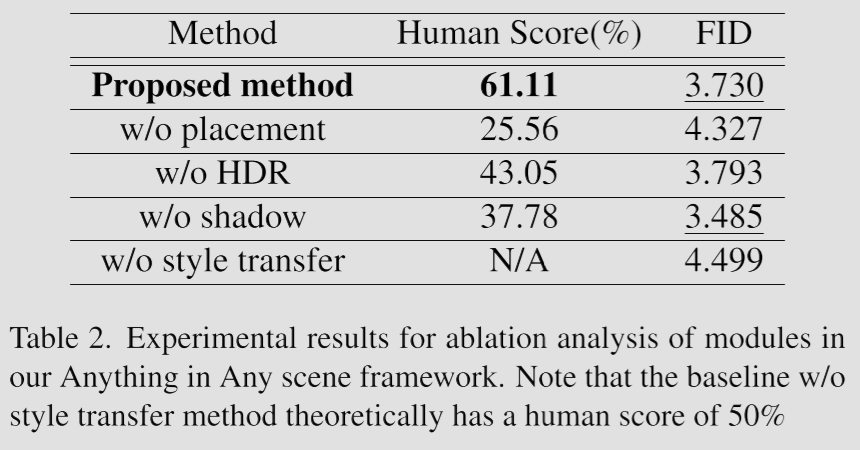

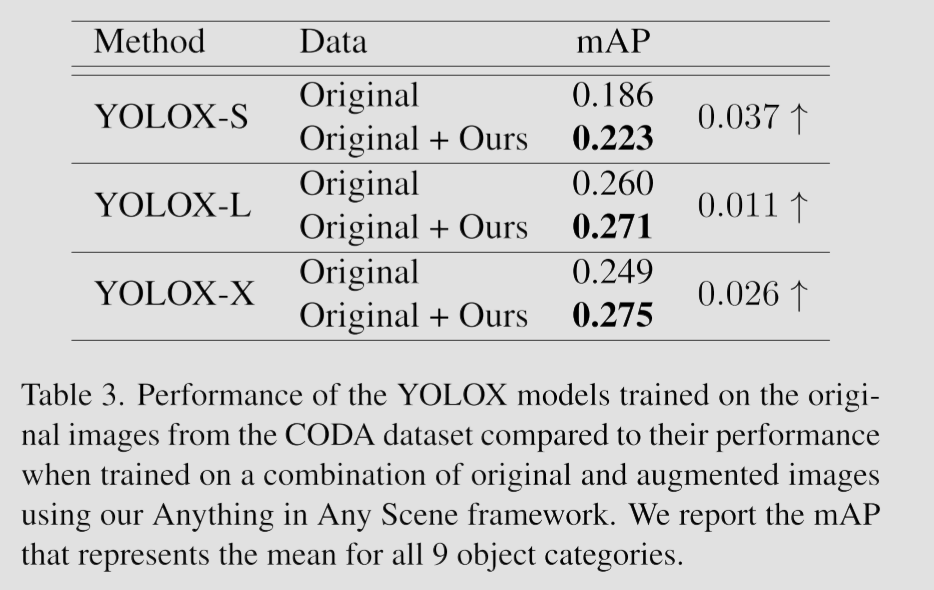
同时,也验证了方法作为数据增强对下游感知任务性能的提升。
总结
文章的工作非常扎实,效果又很不错,作为自动驾驶大厂的工作确实非常有水平。观察demo可以发现,位置和阴影确实感觉很不错了,但由于没引入帧间style的稳定机制,可以发现object在不同帧的style(颜色纹理)感觉略有变化,感觉对于人类观察者这是最容易发现插入object的特点。
于没引入帧间style的稳定机制,可以发现object在不同帧的style(颜色纹理)感觉略有变化,感觉对于人类观察者这是最容易发现插入object的特点。
视频任务的潜力确实很大,利用视频提供的丰富场景信息进行object插入,作为数据增强来说,相比图片级Copy Paste确实感觉效果好很多,但若考虑消耗的资源不知道会怎样?另一方面,感觉这种真实的3D物体插入方法可能在AR/MR会有很大潜力?















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









