







本笔记仅记录《统计学习方法》中各个章节算法|模型的简要概述,比较泛泛而谈,用于应对夏令营面试可能会问的一些问题,不记录证明过程和详细的算法流程。大佬可自行绕路。
更多章节内容请参阅:李航《统计学习方法》学习笔记-CSDN博客
目录
统计学习概述:
定义:
统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。
特点:
数据驱动,数据分为由连续变量和离散变量表示的类型。
三要素:
模型(学习模型的集合)+策略(模型选择的准则)+算法(求解最优模型的算法)
统计学习的分类:
监督学习:
输入变量与输出变量均为连续变量的预测问题是回归问题;均为离散变量的预测问题是分类问题;均为变量序列的预测问题是标注问题。
监督学习的基本假设:X和Y具有联合概率分布。
联合概率:X,Y作为一个整体(X,Y)的概率分布
独立同分布:随机过程中,任何时刻的取值都为随机变量,服从同一分布且相互独立。
无监督学习:
本质是学习数据中的统计规律或潜在结构。可以实现对数据的聚类、降维和概率估计。
强化学习:
是指智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。
智能系统的目标不是短期奖励的最大化,而是长期累积奖励的最大化。强化学习过程中,系统不断地试错,以达到学习最优策略地目的。
强化学习方法中有基于策略地、基于价值的,这两个属于无模型的方法,还有有模型的方法。
半监督学习:
通常有少量标注数据、大量未标注数据。旨在利用未标注数据中的信息,辅助标注数据,进行监督学习。
主动学习:
机器不断主动给出实例让教师进行标注,通常的监督学习使用给定的标注数据,往往是随机得到的,可以认为是“被动学习”,主动学习就是找出对学习最优帮助的实例让教师进行标注,以较小的标注代价,达到较好的学习效果。
其他分类方式:
1:概率模型(以决策树、朴素贝叶斯为代表)和非概率模型(以感知机、支持向量机为代表)
2:线性模型和非线性模型(决策函数是否是线性函数)
3:参数化模型和非参数化模型(模型参数的维度是否固定)
4:在线学习与批量学习(每次接受的样本规模)
5:贝叶斯学习和核方法(按照技巧进行分类)
内积:计算两个相连给的相似度,计算公式为|a||b|cosα,若正交则代表相似度为0。
外积:求两个向量确定平面的法向量或者求其围成的平行四边形面积,计算公式为|a||b|sinα
三要素之策略:
损失函数与风险函数:
损失函数度量模型一次预测的好坏,而风险函数(代价函数)度量平均意义下模型预测的好坏。
常用的损失函数包括:①0-1损失函数;②平方损失函数;③绝对损失函数;④对数损失函数。
经验风险最小化与结构风险最小化:
经验风险最小化就等于极大似然估计,样本量多的时候,一般采用经验风险最小化就可以取得很好的效果。
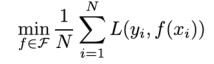
结构风险最小化就等于正则化,样本量小的时候,采用经验风险最小化可能会出现“过拟合”现象,结构风险最小化在经验风险最小化加入了表示模型复杂度的正则化项或罚项。
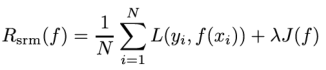
其实质就是在模型性能和复杂度之间寻求平衡。
正则化与交叉验证:
正则化:
正则化项可以取不同的形式。
例如回归问题中,损失函数是平方损失,正则化项可以是参数向量的L2范数,也可以是L1范数:
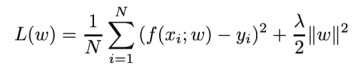
L2范数:各个向量元素平方和的平方根。
L1范数:各个向量元素绝对值之和。
交叉验证:
在给定数据是不充足的情况下,交叉验证的思想是重复地使用数据。
最常用的交叉验证方式是S折交叉验证,基本思想是:将数据随机分为S个互不相交、大小相同的子集;然后利用S-1个子集用于训练,剩下的一个用于验证。将这一个过程对S种选择重复进行,最后选出S次测评中平均测评误差最小的模型。
需要注意每次交叉验证都是基于原始模型进行训练的,而非迭代进行不断优化。
生成模型与判别模型:
生成方法:
由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,典型的例子包括朴素贝叶斯模型以及隐马尔可夫模型。
优点:①可以还原出联合概率分布,判别则不能;②收敛速度更快,尤其是样本容量较多的时候;③:存在隐变量时仍然可以用生成,判别则不行。
“隐变量”或“潜变量”指的是在数据中未直接观测到的变量
判别方法:
由数据直接学习洁厕函数或者条件概率分布作为预测的模型,典型的例子包括K近邻、感知机等。
优点:①直接面对预测,学习的准确率更高;②可以对数据进行各种程度上的抽象,因此可以简化学习问题。
监督学习的应用:
分类问题:
对于二分类问题评价指标可以选用混淆矩阵(包括精确率,召回率,F1分数)。
标注问题:
标注常用的方法有:隐马尔可夫模型、条件随机场。
一个经典例子是对句子的词性进行标注。
回归问题:
回归学习最常用的损失函数是平方损失函数,可以用著名的最小二乘法进行求解。
最大似然估计和贝叶斯估计:
区别就是最大似然估计完全根据样本信息,而贝叶斯估计不仅根据样本信息,还根据先验信息。
若样本量大,先验信息帮助不大,可以用最大似然估计;若样本量小,先验信息帮助较大,贝叶斯估计不会出现极端情况。
















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









