







目录
0.1 参数量化(Parameter Quantization)
0.3 神经网络结构搜索(Network Architecture Search, NAS)
0.4 低秩分解(Low-Rank Factorization)
0.5 知识蒸馏(Knowledge Distillation)
1 2006年——"Model Compression"——Cristian Bucila、Rich Caruana、Alexandru Niculescu-Mizil
2 2015年——"Distilling the Knowledge in a Neural Network"——Geoffrey Hinton、Oriol Vinyals、Jeff Dean
2.3.3 Teacher Model和Student Model
2.3.8 在高温极限下,蒸馏相当于最小化logits的均方误差(不经过softmax的输入)
2.3.12 为啥学生模型训练时(soft target那个分支)T要大于1?而用于推理时温度要为1。
2.4.1 Pretrain Teacher Networks
EXP0. Baseline (without Knowledge Distillation)
EXP3. Effect of Temperature Scaling
3 2015年——"Fitnets: Hints for thin deep nets"——Adriana Romero、Nicolas Ballas...
4 2017年——"Paying More Attention to Attention"——Sergey Zagoruyko、Nikos Komodakis
5 2017年——A Gift from Knowledge Distillation——Junho Yim、Donggyu Joo...
6 2018年——"Paraphrasing Complex Network"——Jangho Kim、SeongUk Park
7 2018年——"Deep mutual learning CVPR 2018"——Ying Zhang、Tao Xiang...
8 2019年——"A Comprehensive Overhaul of Feature Distillation"——Byeongho Heo、Jeesoo Kim
9 2019年——"On the efficacy of knowledge distillation, ICCV 2019"——Jang Hyun Cho、Bharath Hariharan
11 2019年——"Training deep neural networks in generations"——Chenglin Yang、Lingxi Xie
12 2019年——"Distillation-Based Training for Multi-Exit Architectures"——Mary Phuong、AmCampus1
13 2019年——"Similarity-Preserving Knowledge Distillation"——Frederick Tung、Greg Mori
13 2019年——"Be Your Own Teacher"——Linfeng Zhang、Jiebo Song...
14 2020年——"Online Knowledge Distillation via Collaborative Learning"——Qiushan Guo、Xinjiang Wang
15.2.1 Logits(Response)-based Knowledge优缺点总结
15.2.2 Feature/Relation-based Knowledge优缺点总结
16.1 DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter 2019
16.2 TinyBERT: Distilling BERT for natural language understanding 2019
17.2 Are bigger models better teachers?
17.3 Is a pretrained teacher important?
17.4 Single teacher vs multiple teachers
0 前言:
You have to know the past to understand the present. —— Carl Sagan
KD属于模型压缩算法的一种。
模型压缩(Model Compression)是指通过一系列技术手段,降低深度学习模型的参数量、计算量和内存占用,以便能够在硬件资源有限的设备(如移动设备、嵌入式设备等)上高效运行。
常见的模型压缩算法主要包括以下几种:
- 参数量化(Parameter Quantization)
- 参数剪枝(Parameter Pruning)
- 神经网络结构搜索(Network Architecture Search, NAS)
- 低秩分解(Low-Rank Factorization)
- 知识蒸馏(Knowledge Distillation)等
在正式介绍知识蒸馏(Knowledge Distillation)完整发展历程之前,我们有必要先简单了解一下这几种常见的模型压缩算法。
0.1 参数量化(Parameter Quantization)
参数量化(Parameter Quantization)是将神经网络中的浮点数权重(通常是32位浮点数)转换为较低位数表示(如8位、16位整数)。通过减少每个参数占用的比特数,量化可以显著减小模型的内存占用和计算量。
- 量化方法:常见的量化方法包括权重量化(Weight Quantization)、激活量化(Activation Quantization)、梯度量化(Gradient Quantization)等。量化通常通过寻找最优的量化比例来保持精度和压缩效果的平衡。
- 优点:量化可以显著减少模型的内存消耗,并提高推理速度,尤其是在具有低精度计算支持的硬件上(如量化计算加速器)。
- 挑战:量化可能导致精度损失,特别是在低位数量化时。为此,一些技术(如训练后量化、量化感知训练等)可以在压缩的同时保持模型的性能。
0.2 参数剪枝(Parameter Pruning)
参数剪枝(Parameter Pruning)是通过删除模型中冗余或不重要的权重,从而减少模型的参数数量。通常,剪枝的目标是将参数数量减少到原始模型的一小部分。
- 剪枝策略:剪枝可以基于不同的准则,例如根据权重的大小(小权重被认为对模型性能影响较小)、基于梯度(剪枝那些对损失函数影响较小的参数)等。剪枝可以是全局的,也可以是层级的。
- 剪枝的类型:主要有结构化剪枝和非结构化剪枝。非结构化剪枝通过剪掉个别的权重来减少模型参数,而结构化剪枝则是删减整个神经元、卷积核或网络层等更大的结构单元。
- 优点:剪枝可以显著减少模型的存储需求和计算成本,尤其适用于硬件加速器(如GPU、TPU)上的推理加速。
- 挑战:剪枝后可能导致模型的性能下降,因此需要在剪枝和精度之间进行权衡,并且剪枝后通常需要进一步的微调。
0.3 神经网络结构搜索(Network Architecture Search, NAS)
神经网络架构搜索(NAS)是指通过自动化算法搜索最优的神经网络结构,旨在找到一种既能保持高性能又能压缩计算量的网络结构。
- 搜索空间:NAS的搜索空间包括网络的层数、每层的神经元数量、卷积核的大小、网络中的连接方式等。
- 搜索方法:NAS通常采用强化学习(Reinforcement Learning)、进化算法(Evolutionary Algorithm)、梯度下降(Gradient-based Search)等方法来进行搜索。
- 优点:NAS可以设计出具有高效结构的神经网络,并且可以在满足特定硬件要求(如延迟、内存)下优化网络的性能。
- 挑战:NAS的计算开销非常大,尤其是在搜索空间巨大时,搜索过程可能需要消耗大量的计算资源和时间。
0.4 低秩分解(Low-Rank Factorization)
低秩分解(Low-Rank Factorization)通过将网络中的矩阵分解成多个低秩矩阵的乘积来压缩模型。这种方法主要用于减少模型中的权重矩阵的参数数量。
- 方法:常见的低秩分解方法包括SVD(奇异值分解)、Tensor decomposition等。通过将大的权重矩阵分解为多个小矩阵,低秩分解能有效减少计算量和存储需求。
- 优点:低秩分解能够在减少计算复杂度的同时,保持较高的模型精度。
- 挑战:低秩分解有时可能会导致计算精度损失,尤其是在分解精度不够的情况下。此外,分解过程可能需要额外的计算开销。
0.5 知识蒸馏(Knowledge Distillation)
知识蒸馏(Knowledge Distillation)是一种将复杂模型(教师模型)中包含的知识传递给较简单模型(学生模型)的技术。通过学习教师模型的输出,学生模型能够获得与教师相似的性能,而同时保持较小的模型规模。
- 方法:知识蒸馏可以基于不同类型的知识传递,包括基于响应的知识(logits)、基于特征的知识(中间层特征)、基于关系的知识(特征之间的关系)等。
- 优点:知识蒸馏通常能有效地提高学生模型的性能,并且能够压缩模型,适用于多种应用场景,尤其在迁移学习中有较好的表现。
- 挑战:蒸馏过程中可能会出现精度损失,特别是在学生模型和教师模型之间存在较大差距时。
那么接下来让我们开始正式了解一下“知识蒸馏(Knowledge Distillation)的前世今生”。
1 2006年——"Model Compression"——Cristian Bucila、Rich Caruana、Alexandru Niculescu-Mizil
1.1 论文链接
1.2 摘要
通常,表现最好的监督学习模型是由成百上千个基级分类器组成的集成。然而,存储这么多分类器所需的空间以及运行时执行它们所需的时间,限制了它们在一些应用中的使用,尤其是在测试集非常大的情况下(例如Google)、存储空间有限的情况下(例如PDAs),以及计算能力有限的情况下(例如助听器)。我们提出了一种方法,通过“压缩”大规模、复杂的集成模型,转换成更小、更快速的模型,通常在性能上不会有显著的损失。
1.3 核心思想
这篇论文发表于2006年,当时还没有深度神经网络,只有一些浅层的人工神经网络,当时的主流模型是用集成学习搭建的传统机器学习模型。但由于这种集成模型所需的空间和时间开销都比较大,作者就提出了一个想法——将复杂的集成模型(由多个基础分类器组合而成)压缩成一个更小、更快的模型(人工神经网络),同时尽量保持相似的性能。具体步骤如下:
-
集成选择法:这篇论文提到的“集成选择”方法(Ensemble Selection)是一种集成学习方法,通过选择多个不同的分类器来提高模型的准确性。但这种方法需要存储大量的分类器,并且运行时需要较长的时间,适用场景有限。
-
神经网络模拟集成模型:为了将复杂的集成模型变得更小、更快,作者提出使用神经网络来模拟集成模型的行为。神经网络有一个特性:它们是“通用逼近器”,意思是只要给足够的训练数据和合适的网络结构,神经网络可以逼近任何复杂的函数。因此,作者希望通过训练一个神经网络,使其学习到与原来集成模型相似的预测结果。
-
训练过程:为了训练这个神经网络,作者并不直接使用原始的小规模训练数据集,而是使用集成模型对一个更大的未标记数据集进行标注,然后用这个大的标注数据集来训练神经网络。这样,训练出来的神经网络不仅能模仿集成模型的输出,而且比在原始训练集上训练的神经网络表现更好。
-
生成合成数据:在某些领域,可能没有足够的未标记数据,这时作者提出了一种生成合成数据的方法,称为MUNGE,这种方法可以生成与原始训练数据分布相似的数据。使用这种方法,可以在没有大量真实数据的情况下,依然训练出效果相近的神经网络。
-
压缩效果:通过这种方法,作者成功地训练出了比原来的集成模型小一千倍、速度快1000倍的神经网络,并且它们的性能几乎与复杂的集成模型一样好。
1.4 实验结果
1.4.1 三种生成伪数据的方法
作者实验了三种生成伪数据的方法:
1. 随机生成(RANDOM):独立从边缘分布中生成属性值。
2. 朴素贝叶斯估计(NBE):估计属性的联合分布并从中采样。
3. 融合采样(MUNGE):直接从非参数的联合分布估计中采样。
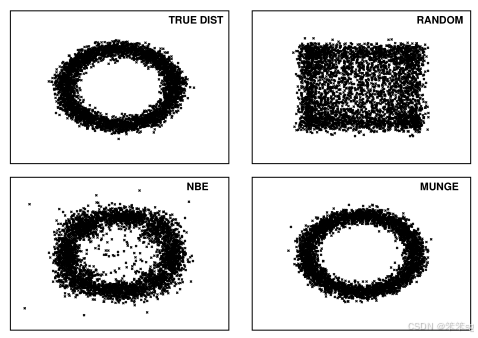
实验结果发现融合采样(MUNGE)的效果最好,生成的数据和原始真实数据的分布最为一致。
1.4.2 训练集尺寸和RMSE的关系
下图显示了这8个测试问题的平均RMSE性能。RMSE越低表示性能越好。图中顶部的水平线显示了我们在原始4k训练集上训练的最佳神经网络的性能。底部的水平线表示在相同数据上训练的集成选择的性能。
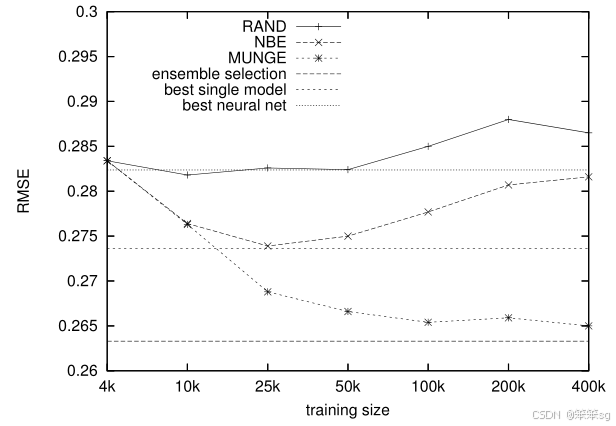
注意,用集成选择训练的模型比神经网络模型表现得好得多。中间的水平线是在选择集成之前,来自集成选择库的最佳单个基本级别模型的平均性能。这条线代表了我们使用以下任何一种学习方法所能达到的最佳性能:支持向量机、袋装树、增强树、增强树桩、简单决策树、随机森林、神经网络、逻辑回归、k近邻和朴素贝叶斯。
上图中的其他行显示了在集成模型标记的不同数量的伪数据上训练的模拟神经网络的性能。RANDOM、NBE和MUNGE的线条对应于具有128个隐藏单元的神经网络,这些隐藏单元是在使用1.4.1中描述的三种方法生成的伪数据上训练的。图从4k开始,没有伪数据添加到训练集。正因为如此,这三种方法的性能与我们在原始训练集上训练的最佳神经网络的性能相似。模拟网络的性能略差,因为它们仅限于使用128个隐藏单元,这并不总是最佳的。
随着训练集数据的大小超过4k,更多的伪数据被添加到训练集中。在400k时,训练集包含396k的伪数据和原始的4k训练数据。对于使用RANDOM生成的伪数据训练的模拟网络,在10k时性能略有提高,而在100k及以上时,性能比仅使用原始4k训练集训练的神经网络更差。在NBE生成的伪数据上训练的模拟神经网络表现更好,尽管总体模式与RANDOM的图相似。当训练集包含大约20k的伪数据和4k的原始数据时,NBE训练网络的性能达到峰值,然后随着更多的人工数据添加到训练集中而下降。
使用MUNGE生成的伪数据训练的模拟神经网络优于使用RANDOM和NBE数据训练的网络。此外,使用MUNGE的性能不会随着向伪训练集添加更多数据而降低。平均而言,一旦伪训练集包含100k或更多数据,模拟神经网络的表现就会比集成库中最好的单个模型好得多,并且几乎与目标集成本身一样好。
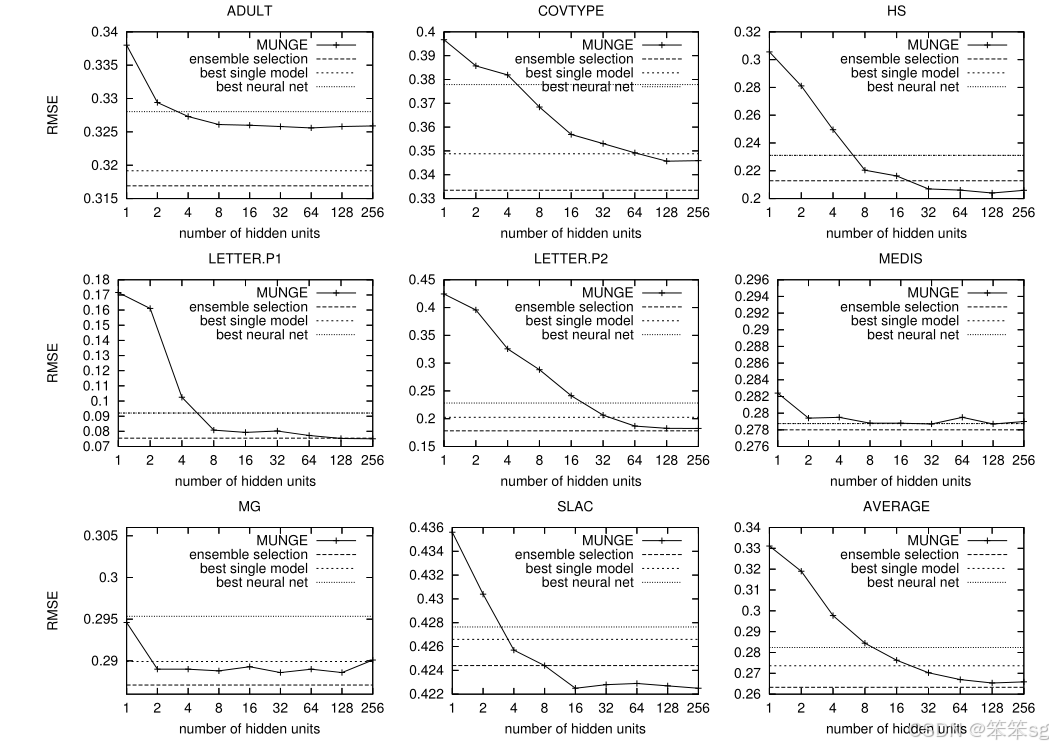
1.4.3 在8个数据集上hidden units数量和RMSE的关系
实验结果表明,在MUNGE数据上训练的模拟网络的性能随着隐藏单元和伪数据的增加而提高。模拟神经网络的性能与集成模型的性能一样好,甚至更好,这是值得注意的,因为模拟神经网络是比集成学习模型小100-10万倍,执行速度快100到1万倍。
1.5 这篇论文和知识蒸馏的关系
乍一看,这篇论文又没采用深度学习,感觉和我们之前了解的KD没啥关系。但之所以要讲它是因为它提出的模型压缩方法与知识蒸馏的核心思想非常相似。
在这篇论文中,作者通过使用神经网络(学生模型)来模仿复杂的集成模型(教师模型),从而压缩模型的大小并提高计算效率。这实际上与知识蒸馏的思想一致,即通过训练一个较小的学生模型来模仿一个大型、复杂的教师模型,使得学生模型能够在存储和计算上更高效,同时尽量保留教师模型的性能。
具体来说,知识蒸馏和这篇论文的相似之处包括:
-
教师-学生模型架构: 在论文中,复杂的集成模型(由多个基模型组成的集成选择模型)作为教师模型,而训练的神经网络(较小的模型)则是学生模型,模仿教师模型的预测行为。
-
软目标: 论文通过生成伪数据并使用集成模型为这些数据打标签,这与知识蒸馏中的“软目标”概念类似。知识蒸馏的核心就是将教师模型的输出概率分布(软目标)作为学生模型的目标,而不是传统的硬标签(真实标签)。在论文中,集成模型的预测(作为“软标签”)被用于训练神经网络,目标是使学生模型尽可能模仿教师模型的行为。
-
压缩和性能保持: 通过这种方式,论文展示了在不显著损失性能的情况下将复杂模型压缩成更小、更高效的模型,这正是知识蒸馏在不同任务中的应用目标。
2 2015年——"Distilling the Knowledge in a Neural Network"——Geoffrey Hinton、Oriol Vinyals、Jeff Dean
2.1 论文链接
Distilling the Knowledge in a Neural Network
2.2 摘要
一种非常简单的提升几乎任何机器学习算法性能的方法是,在相同的数据上训练多个不同的模型,然后对它们的预测结果进行平均[3]。然而,使用整个模型集群进行预测是繁琐的,并且可能过于计算密集,以至于无法部署到大量用户,特别是当个体模型是大型神经网络时。Caruana及其合作者已经证明,可以将集群中的知识压缩成一个单一的模型,这样就更容易部署,我们通过使用不同的压缩技术进一步发展了这种方法。我们在MNIST数据集上取得了一些令人惊讶的结果,并展示了通过将一个集群模型的知识蒸馏成一个单一模型,我们可以显著改善一个广泛使用的商业系统的声学模型。我们还介绍了一种新的集群类型,由一个或多个完整模型和许多专门模型组成,这些专门模型学习区分完整模型混淆的细粒度类别。与专家混合模型不同,这些专门模型可以快速并行地训练。
2.3 核心思想
2.3.1 提出背景
这篇论文发表于2015年,在这篇论文中,Hilton et al. 第一次正式定义Distillation,并提出相应的训练方法。

上边这个是Hinton原文的Introduction,在开头的时候就做了一个很形象的比喻,引用昆虫记里面的话:“蝴蝶以毛毛虫的形式吃树叶积攒能量逐渐成长,最后变换成蝴蝶这一终极形态来完成繁殖。”

当今,在训练网络和使用网络时候存在一个矛盾,简单来说training的时候我们总喜欢ensemble(集成),但是这样网络太大,对using的时候很不友好,也就是Hinton说的ensemble are bad at test time所以就有了我们的Distilling。
人们在直觉上会觉得,要保留相近的知识量,必须保留相近规模的模型。也就是说,一个模型的参数量基本决定了其所能捕获到的数据内蕴含的“知识”的量。
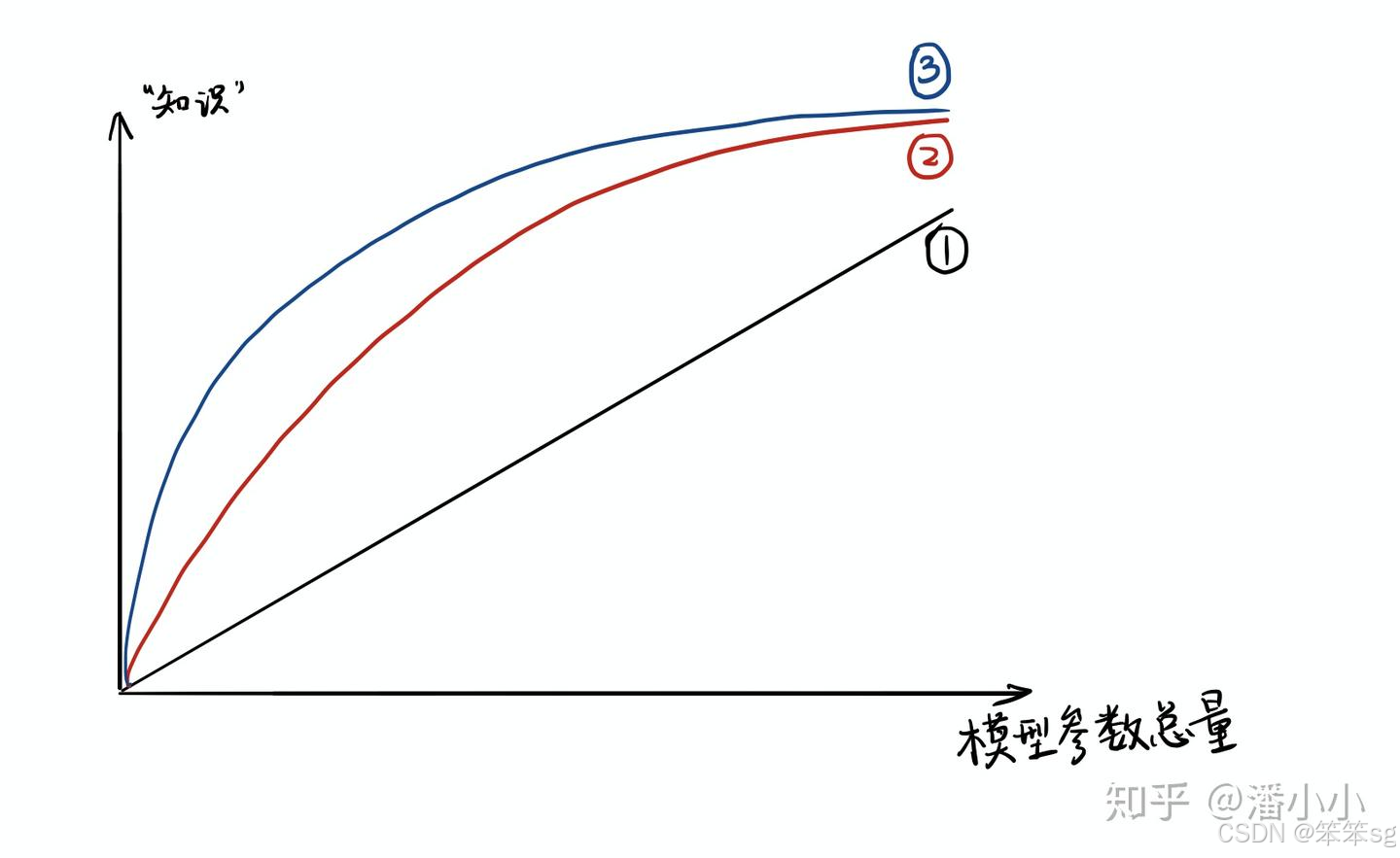
2.3.2 模型的参数量和其所能捕获的“知识”量的关系
人们在直觉上会觉得,要保留相近的知识量,必须保留相近规模的模型。也就是说,一个模型的参数量基本决定了其所能捕获到的数据内蕴含的“知识”的量。
这样的想法是基本正确的,但是需要注意的是:
- 模型的参数量和其所能捕获的“知识“量之间并非稳定的线性关系(下图中的1),而是接近边际收益逐渐减少的一种增长曲线(下图中的2和3)
- 完全相同的模型架构和模型参数量,使用完全相同的训练数据,能捕获的“知识”量并不一定完全相同,另一个关键因素是训练的方法。合适的训练方法可以使得在模型参数总量比较小时,尽可能地获取到更多的“知识”(下图中的3与2曲线的对比).
2.3.3 Teacher Model和Student Model
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练: 训练"Teacher模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练"Student模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
在本论文中,作者将问题限定在分类问题下,或者其他本质上属于分类问题的问题,该类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。
在知识蒸馏时,由于我们已经有了一个泛化能力较强的Net-T,我们在利用Net-T来蒸馏训练Net-S时,可以直接让Net-S去学习Net-T的泛化能力。
那么具体如何让Net-S去学习Net-T的泛化能力呢?我们继续往下走
2.3.4 KD的训练过程和传统的训练过程的对比
- 传统training过程(hard targets): 对ground truth(真实标签)求极大似然
- KD的training过程(soft targets): 用large model的class probabilities(分类概率)作为soft targets
那么为啥要这样子做呢?这是因为softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,KD的训练方式使得每个样本给Net-S带来的信息量大于传统的训练方式。
【举个例子】
在手写体数字识别任务MNIST中,输出类别有10个。

假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率为0.1,而其他负标签对应的值都很小,而另一个"2"更加形似"7","7"对应的概率为0.1。这两个"2"对应的hard target的值是相同的,但是它们的soft target却是不同的,由此我们可见soft target蕴含着比hard target多的信息。并且soft target分布的熵相对高时,其soft target蕴含的知识就更丰富。
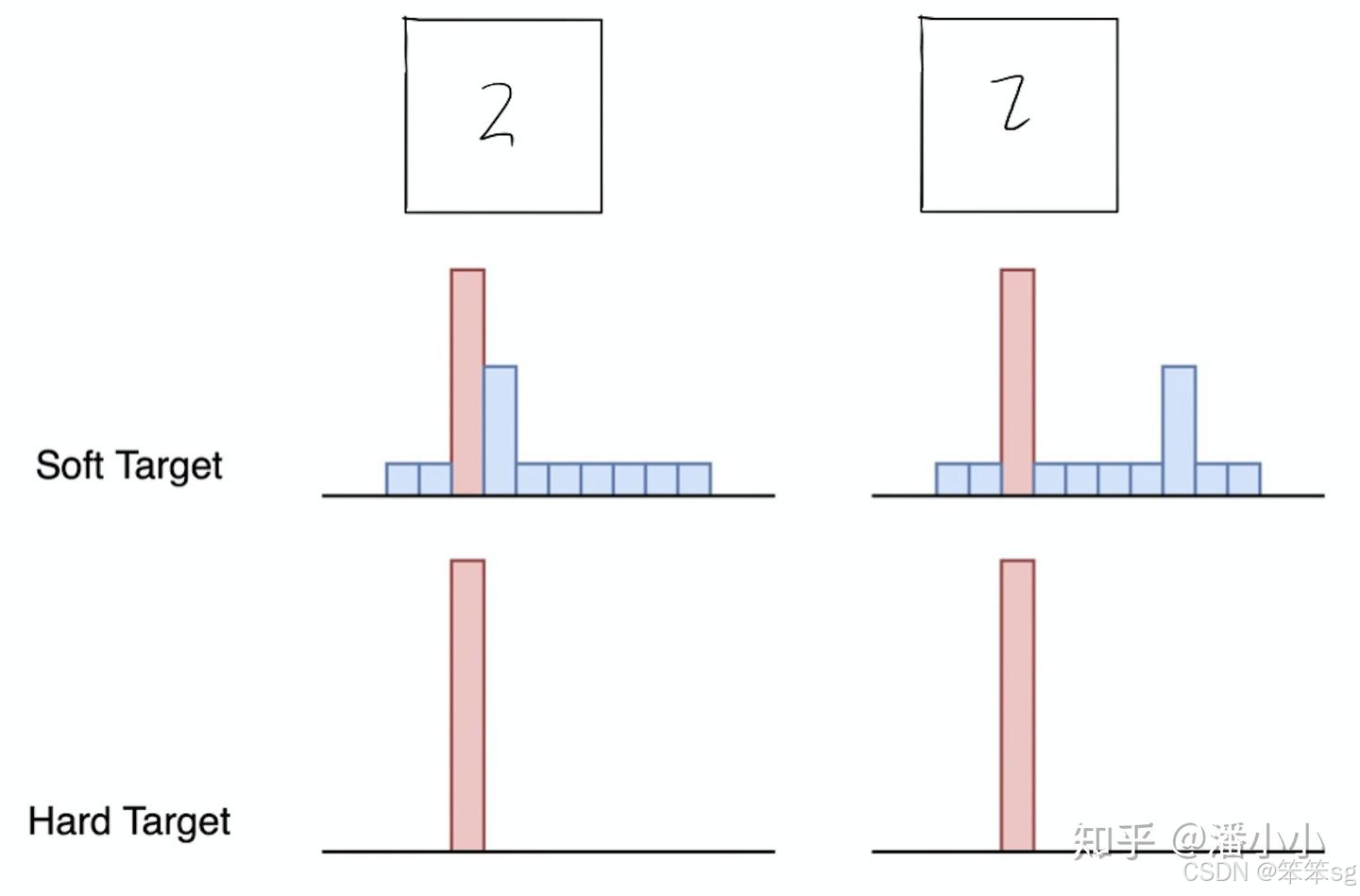
这就解释了为什么通过蒸馏的方法训练出的Net-S相比使用完全相同的模型结构和训练数据只使用hard target的训练方法得到的模型,拥有更好的泛化能力。
2.3.5 softmax函数的改进——温度T的引入
先回顾一下原始的softmax函数:
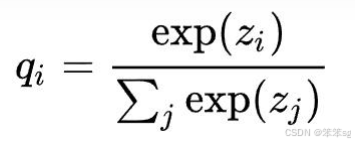
但要是直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计,即使用softmax层的输出作为soft target模型也不能学到更多的信息。因此"温度"这个变量就派上了用场。
下面的公式时加了温度这个变量之后的softmax函数:
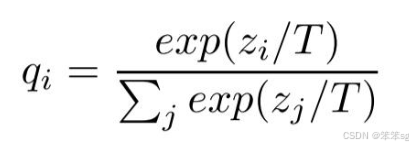
- 这里的T就是温度。
- 原来的softmax函数是T = 1的特例。 T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
【举个例子】

让我们算一下各自的熵值(熵值越大模型学到的知识越多,如果不考虑噪音的话):
import torch
import torch.nn.functional as F
# 示例数据
y_true = torch.tensor([0]) # 类别标签
y_pred = torch.tensor([[0.653, 0.233, 0.114]]) # softmax预测值,注意这是一个二维张量
# y_pred = torch.tensor([[0.347, 0.311, 0.342]])
# 计算交叉熵损失
loss = F.cross_entropy(y_pred, y_true)
print(f"交叉熵损失值: {loss.item()}")
0.8066446781158447(T=1时)
1.0850719213485718 (T=10时)
因此,温度T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大(越不确定),反之熵值就越小(越确定)。
2.3.6 知识蒸馏的具体流程
第一步是训练Net-T;第二步是在高温T下,蒸馏Net-T的知识到Net-S
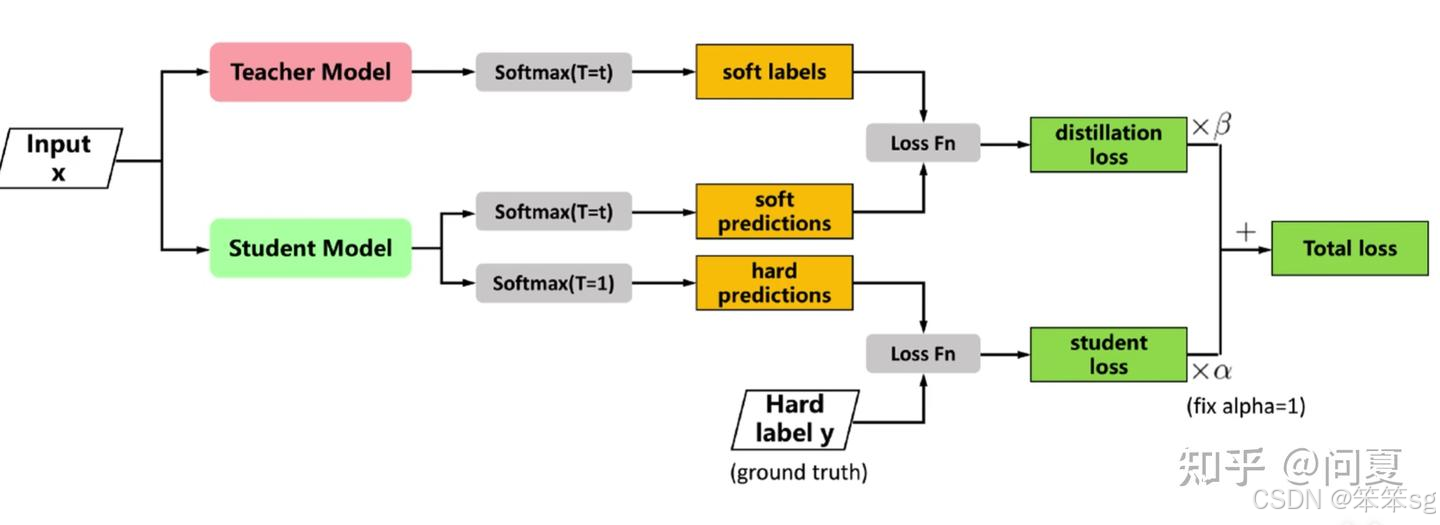
训练Net-T的过程很简单,下面详细讲讲第二步:高温蒸馏的过程。
高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。示意图如上。
L=α*Lsoft+β*Lhard

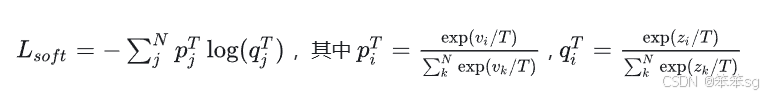
Net-S在T=1的条件下的softmax输出和ground truth的cross entropy就是Loss函数的第二部分
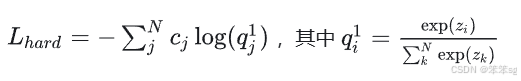
第二部分 Lhard 的必要性其实很好理解: Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
2.3.7 α和β的取值问题
实验发现第一部分Lsoft所占比重比较小的时候(也即α较小的时候),能产生最好的结果,这是一个经验的结论。一个可能的原因是,由于soft target产生的gradient与hard target产生的gradient之间有与 T 相关的比值。原论文中只是一笔带过,我在下面补充了一些简单的推导。(ps. 下面推导可能有些错误,如果有读者能够正确推出来请私信我~)

默认α + β=1 , 初始设置 α = β = 0.5,但是实验中 α << β ,结果较好。
【注意】 在Net-S训练完毕后,做inference时其softmax的温度T要恢复到1.
2.3.8 在高温极限下,蒸馏相当于最小化logits的均方误差(不经过softmax的输入)

具体的推导过程可以参见:
Distilling the Knowledge in a Neural Network 理论推导 - 知乎
2.3.9 关于"温度"的讨论
【问题】 我们都知道“蒸馏”需要在高温下进行,那么这个“蒸馏”的温度代表了什么,又是如何选取合适的温度?
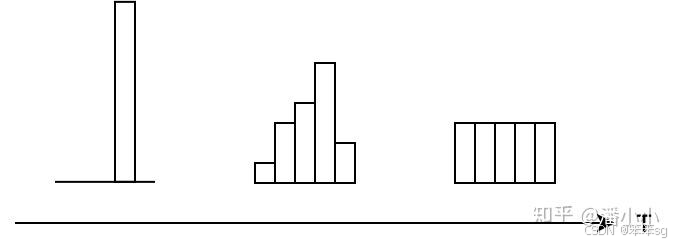
1)温度的特点:
在回答这个问题之前,先讨论一下温度T的特点
- 原始的softmax函数是 T=1 时的特例, T<1 时,概率分布比原始更“陡峭”, T>1 时,概率分布比原始更“平缓”。
- 温度越高,softmax上各个值的分布就越平均(思考极端情况: (i) T=∞ , 此时softmax的值是平均分布的;(ii) T→0,此时softmax的值就相当于 argmax , 即最大的概率处的值趋近于1,而其他值趋近于0)
- 不管温度T怎么取值,Soft target都有忽略相对较小的 pi 携带的信息的倾向
2)如何选取合适的温度?
温度的高低改变的是Net-S训练过程中对负标签的关注程度: 温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Net-S会相对多地关注到负标签。
实际上,负标签中包含一定的信息,尤其是那些值显著高于平均值的负标签。但由于Net-T的训练过程决定了负标签部分比较noisy,并且负标签的值越低,其信息就越不可靠。因此温度的选取比较empirical,本质上就是在下面两件事之中取舍:
- 从有部分信息量的负标签中学习 --> 温度要高一些
- 防止受负标签中噪声的影响 -->温度要低一些
总的来说,T的选择可以从下面2个方面综合考虑:
- 和Net-T的大小有关,针对teacher较大时,温度T应该较大;teacher较小时,温度T应该较小。温度T其实可以理解为蒸馏能力,好的老师使用大T,蒸馏出更多的知识更学生,而差的老师使用小T,仅做稍微辅导,而不做过多干预学生,以防带偏学生。
- 和Net-S的大小有关,Net-S参数量比较小的时候,相对比较低的温度就可以了(因为参数量小的模型不能capture all knowledge,所以可以适当忽略掉一些负标签的信息)
2.3.10 该技术为什么叫“知识蒸馏”?蒸馏体现在哪里?
知识蒸馏的“蒸馏”体现在从大模型提取知识(如类别之间的概率分布)并浓缩到小模型中,类似化学蒸馏提取精华。通过软目标和温度调节,学生模型学习教师模型的丰富信息结构。
2.3.11 知识蒸馏有必要吗?为什么不直接训练小模型?
有必要。直接训练小模型可能泛化能力不足,无法利用类别之间的关系信息。知识蒸馏能提升小模型性能,减少对数据量的依赖,同时优化计算资源,更适合复杂任务和有限数据场景。
2.3.12 为啥学生模型训练时(soft target那个分支)T要大于1?而用于推理时温度要为1。
高温(T > 1)的 softmax 会生成“平滑的概率分布”,更关注类别之间的相对关系,用于训练时提取知识。
而在推理时,在高温下,softmax 输出的概率分布不准确,无法真实反映模型对样本的最终判断。如果推理阶段也用高温,会导致分类边界模糊,不利于决策。因此,将温度恢复为 1 符合正常推理需求。
-
升高温度(T > 1):模型的高温 softmax 输出使得知识被提取出来,尤其是类别之间的相对关系和细微的模式信息被放大,就像蒸馏过程中蒸汽携带了原液的精华。
-
恢复低温(T = 1):在推理阶段,学生模型在正常温度下输出稳定的类别概率分布,就像冷凝后提纯的精华液体可以直接使用。
这种通过温度调整来提取知识的过程,不仅体现了方法的优雅性,还形象地对应了蒸馏的精髓——将“精华”浓缩并传递到更精简的模型中。确实令人感叹:“蒸馏”这个比喻实在是妙不可言!
2.4 动手验证
如果你对实现这个感兴趣,可以参见下面这个仓库:
PyTorch implementation of "Distilling the Knowledge in a Neural Network"
实验环境为:
Dataset: CIFAR10
Teacher Network: VGG16
Student Network: CNN with 3 convolutional blocks
实验结果如下:
2.4.1 Pretrain Teacher Networks
可以看到教师模型在该数据集上的准确率为91.90%。
- Result: 91.90%
- SGD, no weight decay.
- Learning rate adjustment
0.1for epoch[1,150]0.01for epoch[151,250]0.001for epoch[251,300]
python -m pretrainer --optimizer=sgd --lr=0.1 --start_epoch=1 --n_epoch=150 --model_name=ckpt
python -m pretrainer --optimizer=sgd --lr=0.01 --start_epoch=151 --n_epoch=100 --model_name=ckpt --resume
python -m pretrainer --optimizer=sgd --lr=0.001 --start_epoch=251 --n_epoch=50 --model_name=ckpt --resume
2.4.2 Student Networks
- We use Adam optimizer for fair comparison.
- max epoch:
300 - learning rate:
0.0001 - no weight decay for fair comparison.
- max epoch:
EXP0. Baseline (without Knowledge Distillation)
- Result: 85.01%
python -m pretrainer --optimizer=adam --lr=0.0001 --start_epoch=1 --n_epoch=300 --model_name=student-scratch --network=studentnet
EXP1. Effect of loss function
- Similar performance.
python -m trainer --T=1.0 --alpha=1.0 --kd_mode=cse # 84.99%
python -m trainer --T=1.0 --alpha=1.0 --kd_mode=mse # 84.85%
EXP2. Effect of Alpha
- alpha = 0.5 may show better performance.
python -m trainer --T=1.0 --alpha=1.0 --kd_mode=cse # 84.99%
python -m trainer --T=1.0 --alpha=0.5 --kd_mode=cse # 85.38%
python -m trainer --T=1.0 --alpha=1.0 --kd_mode=mse # 84.85%
python -m trainer --T=1.0 --alpha=0.5 --kd_mode=mse # 84.92%
EXP3. Effect of Temperature Scaling
- Higher the temperature, better the performance. Consistent results with the paper.
python -m trainer --T=1.0 --alpha=0.5 --kd_mode=cse # 85.38%
python -m trainer --T=2.0 --alpha=0.5 --kd_mode=cse # 85.27%
python -m trainer --T=4.0 --alpha=0.5 --kd_mode=cse # 86.46%
python -m trainer --T=8.0 --alpha=0.5 --kd_mode=cse # 86.33%
python -m trainer --T=16.0 --alpha=0.5 --kd_mode=cse # 86.58%
EXP4. More Alpha Tuning
- alpha=0.5 seems to be local optimal.
python -m trainer --T=16.0 --alpha=0.1 --kd_mode=cse # 85.69%
python -m trainer --T=16.0 --alpha=0.3 --kd_mode=cse # 86.48%
python -m trainer --T=16.0 --alpha=0.5 --kd_mode=cse # 86.58%
python -m trainer --T=16.0 --alpha=0.7 --kd_mode=cse # 86.16%
python -m trainer --T=16.0 --alpha=0.9 --kd_mode=cse # 86.08%
EXP5. SGD Testing
python -m trainer --T=16.0 --alpha=0.5 --kd_mode=cse --optimizer=sgd-cifar10 # 87.04%
python -m pretrainer --model_name=student-scratch-sgd-cifar10 --network=studentnet --optimizer=sgd-cifar10 # 86.34%
可以看到经过不断努力,使用KD的学生模型最佳的表现为87.04%, 而不使用KD的学生模型表现为85.01%,还是有一点提升的,虽然不多。这也暗示着后人后续要不断提出新方法来不断改进KD
3 2015年——"Fitnets: Hints for thin deep nets"——Adriana Romero、Nicolas Ballas...
3.1 论文链接
Fitnets: Hints for thin deep nets
3.2 摘要
尽管更深的网络通常能够提高模型性能,但深度网络也会使基于梯度的训练更加困难,因为深度网络往往表现出更强的非线性特性。最近提出的知识蒸馏方法旨在获得小型且执行速度快的模型,并且研究表明,学生网络可以模仿较大教师网络或网络集成的软输出。在本文中,我们将这一思想扩展到训练比教师网络更深但更窄的学生网络,同时利用教师网络学习到的中间表示作为提示,以改进学生网络的训练过程和最终性能。由于学生网络的中间隐藏层通常比教师网络的中间隐藏层更小,因此引入了额外的参数,将学生隐藏层映射到教师隐藏层的预测。这种方法允许训练更深的学生网络,使其能够更好地泛化或运行更快,而这种权衡由所选择的学生模型容量来控制。例如,在 CIFAR-10 数据集上,一个深度的学生网络参数量减少了约 10.4 倍,却超过了更大的、最先进的教师网络的性能。
3.3 核心思想
2015年出现了FitNets: hint for Thin Deep Nets(发布于ICLR'15),除了KD的损失,FitNets还增加了一个附加项。它们从两个网络的中点获取表示,并在这些点的特征表示之间增加均方损失。
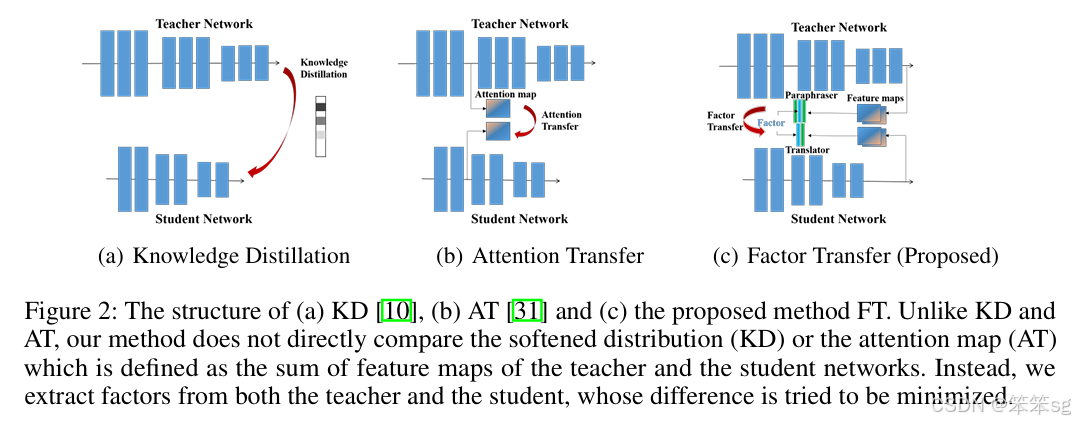
经过训练的网络提供了一种新的学习-中间-表示让新的网络去模仿。这些表示有助于学生有效地学习,被称为hints。这是典型的Feature-based的KD方法。
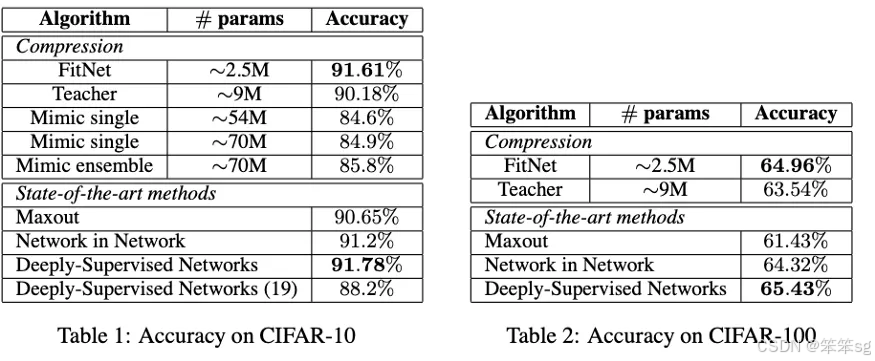
回过头看看,使用单点给出hints的选择不是最优的。随后的许多论文都试图改进这些hints。
4 2017年——"Paying More Attention to Attention"——Sergey Zagoruyko、Nikos Komodakis
4.1 论文链接
4.2 摘要
注意力在人的视觉体验中起着至关重要的作用。此外,最近的研究表明,在将人工神经网络应用于计算机视觉和自然语言处理等领域的各种任务时,注意力也可以发挥重要作用。在这项工作中,我们展示了,通过为卷积神经网络(CNN)正确定义注意力,我们实际上可以利用这种信息,通过迫使学生 CNN 网络模仿强大的教师网络的注意力图,从而显著提高学生网络的性能。为此,我们提出了几种新的注意力迁移方法,并在多种数据集和卷积神经网络架构上展示了一致的性能提升。我们的实验代码和模型已公开,地址为:
Improving Convolutional Networks via Attention Transfer (ICLR 2017)
4.3 核心思想
Paying more attention to attention: Improving the performance of convolutional neural networks via Attention Transfer发布于ICLR 2017。
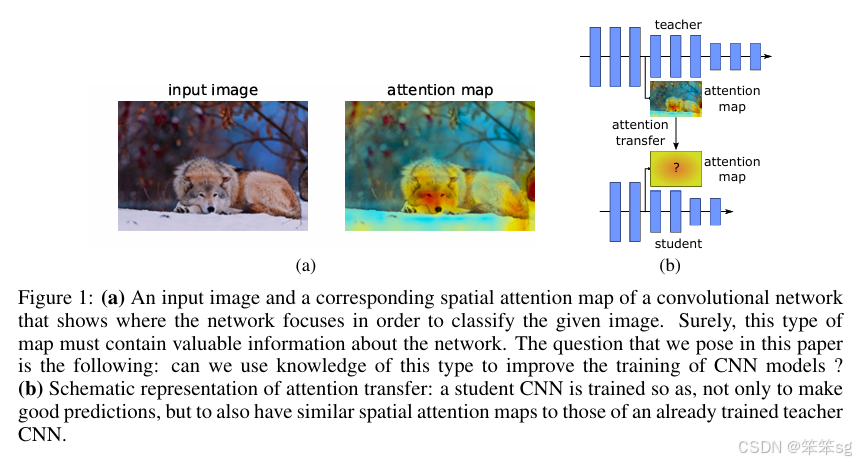
它们的动机与FitNets类似,但它们不是使用网络中某个点的表示,而是使用注意力图作为hints。(老师和学生的注意力图)。它们还使用网络中的多个点来提供hints,而不是FitNets中的单点hints。
这是典型的Feature-based的KD方法。
5 2017年——A Gift from Knowledge Distillation——Junho Yim、Donggyu Joo...
5.1 论文链接
A Gift From Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
5.2 摘要
我们提出了一种用于知识迁移的新技术,其中来自预训练深度神经网络(DNN)的知识被提炼并迁移到另一个DNN中。由于DNN通过多个层级顺序地将输入空间映射到输出空间,我们将待迁移的提炼知识定义为层间流量,该流量通过计算两层特征的内积来衡量。当我们将学生DNN与同样大小但未使用教师网络训练的原始网络进行比较时,提出的以层间流量为形式进行知识迁移的方法展现了三个重要现象:(1) 学生DNN学习提炼知识的优化速度比原始模型快得多;(2) 学生DNN的性能优于原始DNN;(3) 学生DNN可以从训练于不同任务的教师DNN中学习提炼知识,并且学生DNN的性能优于从零开始训练的原始DNN。
5.3 核心思想
同年,A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning发布于CVPR 2017。
这和FitNets和注意力转移的论文也很类似。但是,与中间表示和注意力图不同的是,它们使用Gram矩阵给出了hints。
Gram矩阵是一种用来表示特征之间相互关系的矩阵,常用于计算机视觉中。它通过计算特征向量之间的内积来捕捉特征的相关性或样式信息。在深度学习中,尤其是风格迁移任务中,Gram矩阵通常用来描述某一层特征图的样式,其值反映了不同通道(特征图)之间的关系,而与空间位置信息无关。通过比较不同图像的Gram矩阵,可以衡量它们在样式上的相似性。
他们在论文中对此进行了类比:
“如果是人类的话,老师解释一个问题的解决过程,学生学习解决问题的过程。学生DNN不一定要学习具体问题输入时的中间输出,但可以学习遇到具体类型的问题时的求解方法。通过这种方式,我们相信演示问题的解决过程比讲授中间结果提供了更好的泛化。”
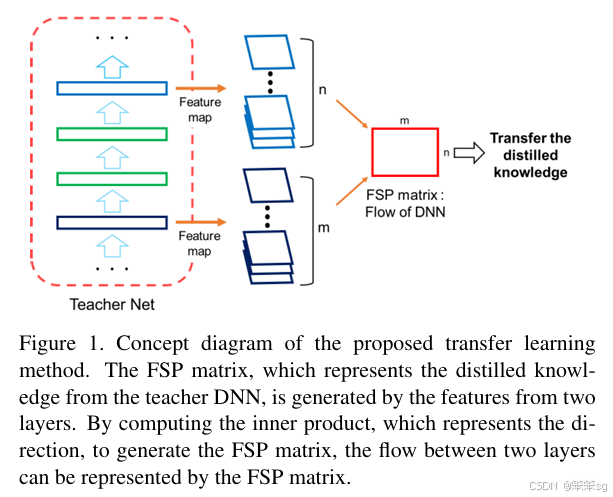
为了度量这个“解决流程”,他们在两个层的特征图之间使用了Gram矩阵。因此,它没有使用FitNets中的中间特征表示作为hints,而是使用特征表示之间的Gram矩阵作为hints。这是典型的基于Relation-based的方法。
5.4 该模型和之前介绍过的模型的不同之处
转自:如何评价CVPR17中A Gift from Knowledge Distillation一文?
下面是某个答主的回答,解释的比较生动
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
扫了一眼,抛砖引玉。本人不做 CV,说得不对的地方还请指正。
大致历史是这样的:
1、Knowledge Distillation 先是 Hinton 搞出来的,大意是说:小模型在分类的时候,光用训练集里的 one-hot label 不好,因为这种标注把类别间的关系割裂开了。而如果让小模型跟着大模型输出的概率分布去学的话,就相当于给出了类别之间的相似性信息,提供了额外的监督信号,因此学起来更容易。比如说识别手写数字,同时标签为 3 的图片,可能有的比较像 8,有的比较像 2,one-hot labels 区分不出来这个信息,但是一个 well-trained 大模型可以给出。因此,修改一下损失函数,让小模型在拟合训练数据的 ground truth labels 的同时,也要拟合大模型输出的概率分布。这个方法叫做 KD Training (Knowledge Distillation Training)。
2、然后 Romero 又搞出了 FitNet,大意是说:直接让小模型在输出端模仿大模型,这个对于小模型来说太难了(模型越深越难训,最后一层的监督信号要传到前面去还是挺累的)。解决方案就是说,不如在中间加一些监督信号。于是训练的方法就是所谓的 hint training,把网络中间的输出也拿出来,让大模型和小模型中间层的输出也要尽量接近,让小模型去学习大模型做预测时的中间步骤。
实际做的时候是用两阶段法:先用 hint training 去 pretrain 小模型前半部分的参数,再用 KD Training 去训练全体参数。这感觉就好像是,我们的目的是让学生做高考题,那么就先把初中的题目给他教会了(先让小模型用前半个模型学会提取图像底层特征),然后再回到本来的目的、去学高考题(用 KD 调整小模型的全部参数)。
“Paying More Attention to Attention”那篇论文和这个类似,这种方法通过让学生网络学习教师网络的特征表示(尤其是注意力特征)来提高其表现。
3、终于进入正题了。之前的文章都是把大模型的输出当成小模型要去拟合的目标,而这篇文章画风清奇地说,不用啊,我不拟合大模型的输出,而是去拟合大模型层与层之间的关系,这才是我要转移和蒸馏的知识!这个关系是用层与层之间的内积来定义的:假如说甲层有 M 个输出通道,乙层有 N 个输出通道,就构建一个 M*N 的矩阵来表示这两层间的关系,其中 (i, j) 元是甲层第 i 个通道 和 乙层第 j 个通道的内积(因此此方法需要甲乙两层 feature map 的形状相同)。
文中把这个矩阵叫 FSP (flow of solution procedure) 矩阵,其实这也是一种 Gram 矩阵,之前一篇很有名的文章 Neural Style 里也有成功的应用:用 Gram 矩阵来描述图像纹理,从而实现风格转换。
如果要打比方的话,我的感觉是这样的:如果做一道平面几何题,题目要证两线段相等,做法是先要做一条辅助线,再证三角形 X 和 Y 全等,最后证明原题结论。那么前面 Romero 的方法就是,中间每一步都盯着你做,你必须和我做的一样,我教你这道题的辅助线该怎么连,然后证哪两个三角形全等;而本文的方法是说,你要先学会『辅助线->三角形全等->线段相等』这种做题的套路,而不是去学一个具体的题目里辅助线到底怎么连,我把一般的解题方法教给你,具体每一题每一步到底怎么证你自己琢磨琢磨就会了。最后训练的时候同样也是用二阶段法:先根据大模型的 FSP 矩阵调整小模型参数,使得小模型层间关系也和大模型的层间关系类似;然后直接用原损失函数(如交叉熵)继续精调小模型参数。感觉这种学习方法比较高屋建瓴,用人类学知识的过程来比喻的话,就是先学抽象的道,培养对于问题的宏观认识,培养整体观念,了解这个问题分为需要几大块,各个块之间的关系是什么样的;然后再学具体的术,填充完善知识细节。
6 2018年——"Paraphrasing Complex Network"——Jangho Kim、SeongUk Park
6.1 论文链接
Paraphrasing Complex Network: Network Compression via Factor Transfer
6.2 摘要
许多研究人员一直在寻找模型压缩的方法,以减少深度神经网络(DNN)的大小,同时尽量减少性能下降,从而使DNN能够在嵌入式系统中使用。在模型压缩方法中,一种叫做知识迁移的方法是通过一个更强的教师网络来训练学生网络。本文提出了一种新颖的知识迁移方法,该方法使用卷积操作来转述教师的知识,并将其传递给学生。这是通过两个卷积模块实现的,分别称为“转述器”和“翻译器”。转述器以无监督方式训练,提取教师网络的因子,这些因子被定义为教师网络的转述信息。位于学生网络中的翻译器提取学生因子,并通过模仿教师因子来帮助翻译教师的知识。我们观察到,使用这种因子迁移方法训练的学生网络,比传统的知识迁移方法训练的网络表现更好。代码可以通过以下链接获取。
6.3 核心思想
然后到了2018年,Paraphrasing Complex Network: Network Compression via Factor Transfer发布于NeurIPS 2018。
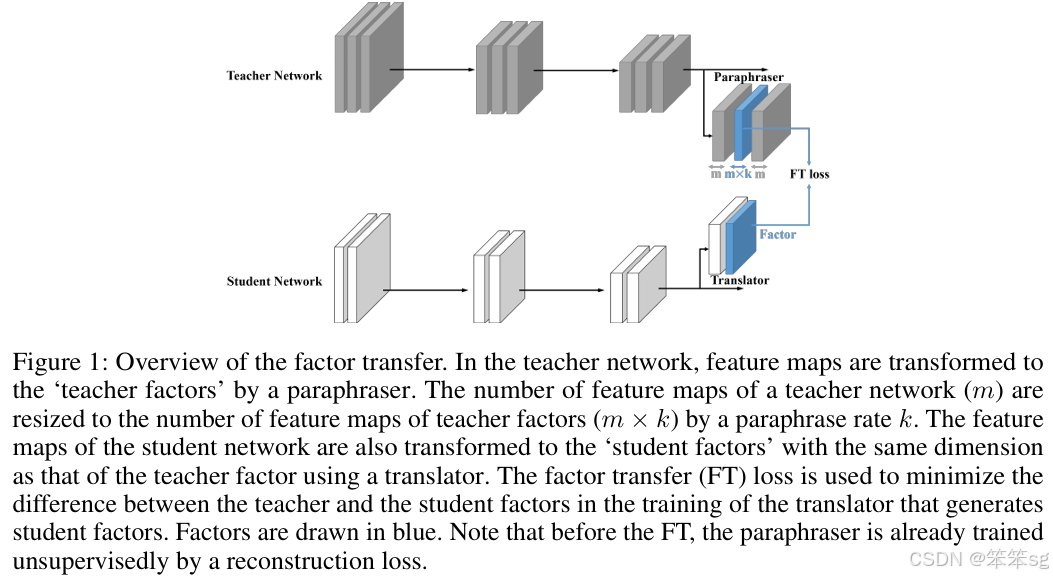
他们在模型中增加了另一个模块,他们称之为paraphraser。它基本上是一个不减少尺寸的自编码器。从最后一层开始,他们又分出另外一层用于reconstruction loss。
学生模型中还有另一个名为translator的模块。它把学生模型的最后一层的输出嵌入到老师的paraphraser维度中。他们用老师潜在的paraphrased 表示作为hints。
学生模型应该能够为来自教师网络的输入构造一个自编码器的表示。
7 2018年——"Deep mutual learning CVPR 2018"——Ying Zhang、Tao Xiang...
7.1 论文链接
7.2 摘要
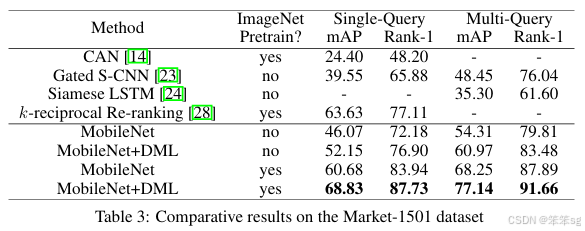
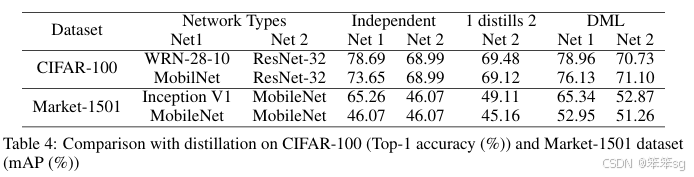
模型蒸馏是一种有效且广泛应用的技术,用于将知识从教师网络转移到学生网络。典型的应用是将一个强大的大型网络或网络集成的知识转移到一个小型网络上,以适应低内存或快速执行的需求。本文提出了一种深度互学(DML)策略,在这种策略中,不是通过静态预定义的教师网络向学生网络进行单向传递,而是让多个学生网络在训练过程中相互协作、互相教导。我们的实验表明,多种网络架构都能从互学中受益,并在CIFAR-100图像识别和Market-1501行人重识别基准测试中取得了令人信服的结果。令人惊讶的是,我们发现不需要事先强大的教师网络——一组简单学生网络的互学能够有效工作,并且在性能上超越了从更强大但静态的教师网络中进行蒸馏的结果。
7.3 核心思想
传统蒸馏模型是从功能强大的大型网络或集成网络转移到结构简单,运行快速的小型网络。本文打破这种预先定义好的“强弱关系”,提出DML,即让一组学生网络在训练过程中相互学习、相互指导,而不是静态的预先定义好教师和学生之间的单向转换通路。
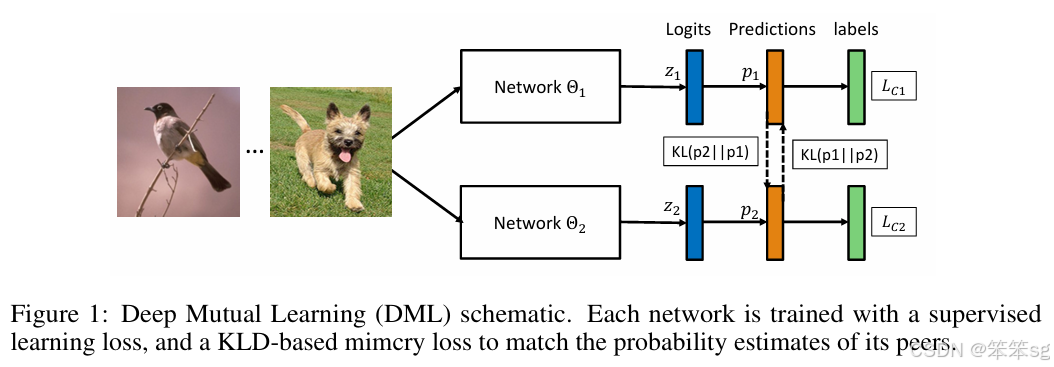
作者引入KL散度的概念来度量两个学生网络的输出概率p1和p2。相信了解过GAN网络的小伙伴对KL应该不会陌生,KL 散度是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大。作者采用KL散度,衡量这两个网络的预测p1和p2是否匹配。
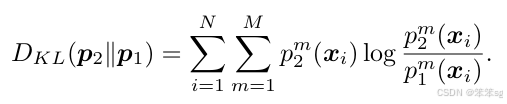
损失函数推导:

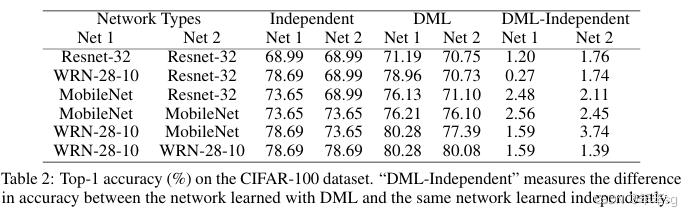
最后训练的loss函数是两个学生网络分别训练,各自的cross-entropy Loss和KL散度Loss之和。
试验结果,效果很明显,增幅很稳定,并且学生网络越多,效果也是线性上升。

8 2019年——"A Comprehensive Overhaul of Feature Distillation"——Byeongho Heo、Jeesoo Kim
8.1 论文链接
AComprehensive Overhaul of Feature Distillation
8.2 摘要
我们研究了实现网络压缩的特征蒸馏方法的设计方面,并提出了一种新颖的特征蒸馏方法,其中蒸馏损失被设计为在多个方面之间实现协同:教师变换、学生变换、蒸馏特征位置和距离函数。我们提出的蒸馏损失包括一个特征变换,采用了新设计的带有边缘ReLU的激活函数,一个新的蒸馏特征位置,以及一个部分L2距离函数,用于跳过冗余信息,从而避免对学生网络压缩产生不利影响。在ImageNet数据集上,我们的方法在ResNet50上取得了21.65%的Top-1错误率,超过了教师网络ResNet152的性能。我们的方法在图像分类、目标检测和语义分割等多种任务上进行了评估,并在所有任务中都取得了显著的性能提升。代码可通过如下链接获取:
8.3 核心思想
在2019年,A Comprehensive Overhaul of Feature Distillation发布于ICCV 2019。
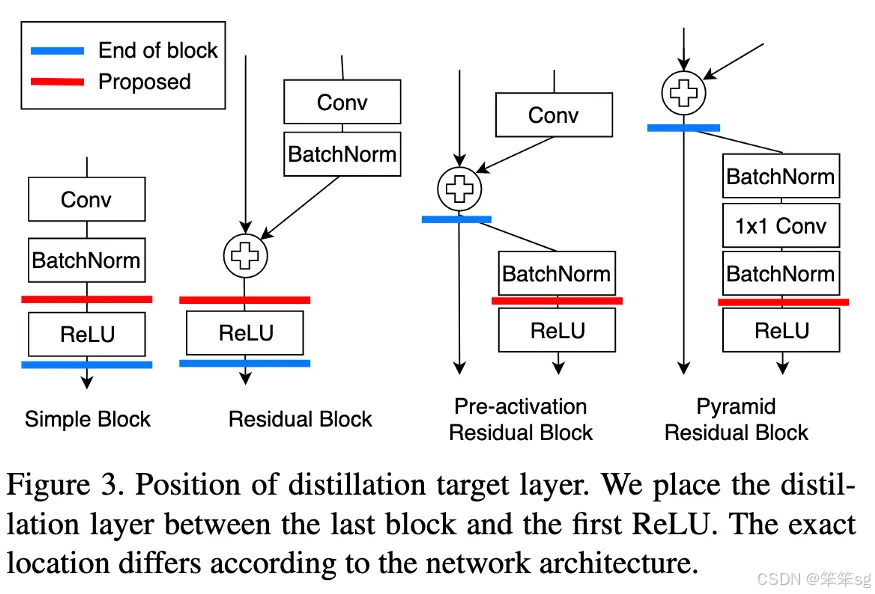
他们认为我们获取hints的位置不是最佳的。通过ReLU对输出进行细化,在转换过程中会丢失一些信息。他们提出了marginReLU激活函数(移位的ReLU)。“在我们的margin ReLU,积极的(有益的)信息被使用而没有任何改变,而消极的(不利的)信息被压制。结果表明,该方法可以在不遗漏有益信息的情况下进行蒸馏。“
他们采用了partial L2 distance函数,目的是跳过对负区域信息的蒸馏。(如果该位置的学生和老师的特征向量都是负的,则没有损失)
Contrastive Representation Distillation发表于ICLR 2020。在这里,学生也从教师的中间表示进行学习,但不是通过MSE损失,他们使用了对比损失。
9 2019年——"On the efficacy of knowledge distillation, ICCV 2019"——Jang Hyun Cho、Bharath Hariharan
9.1 论文链接
Onthe Efficacy of Knowledge Distillation
9.2 摘要
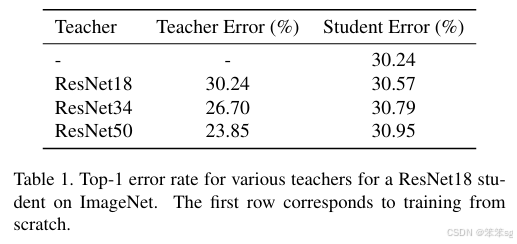
本文对知识蒸馏的效果及其对学生和教师架构的依赖性进行了全面评估。从观察到更准确的教师往往不是好的教师这一现象开始,我们尝试分析影响知识蒸馏性能的因素。我们发现,较大的模型并不总是更好的教师。我们表明,这是因为模型容量不匹配,小型学生网络无法有效模仿大型教师网络。我们还发现,通常的解决方法(如执行一系列知识蒸馏步骤)并没有效果。最后,我们展示了这一问题可以通过提前停止教师网络的训练来缓解。我们的结果在不同数据集和模型上具有普遍性。
9.3 核心思想
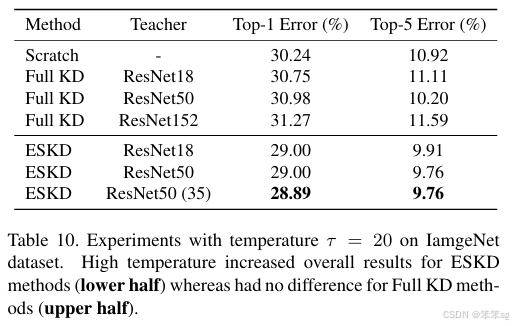
继续使用KD softed labels, 但是聚焦regularization。作者实验观察到,并不是性能越好的teacher就能蒸馏出更好的student;推测是容量不匹配的原因,导致student模型不能够mimic teacher,反而带偏了主要的loss;提出一种early-stop teacher regularization进行蒸馏,接近收敛时要提前停止蒸馏。如下图,teacher网络越深,student蒸馏效果并一定提升。
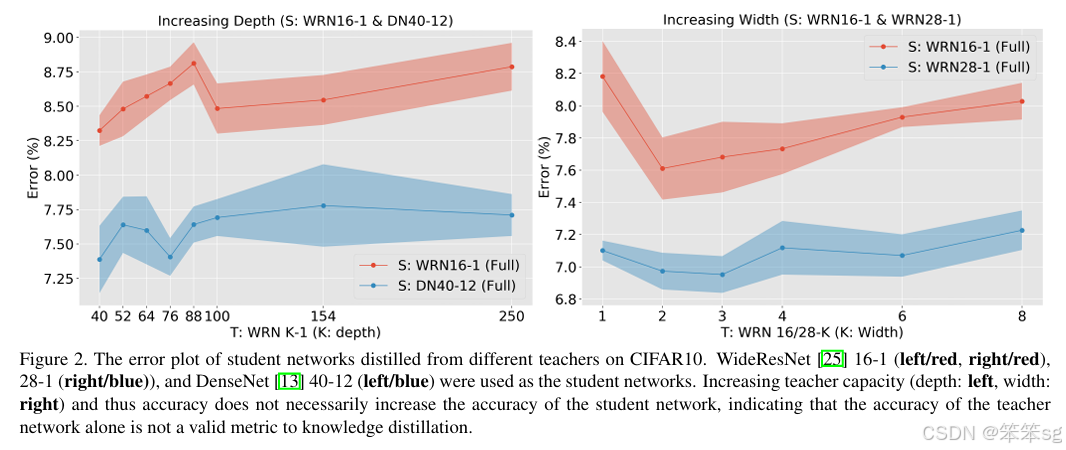
具体early-stop teacher regularization的策略作者没有写出来,但是可以推测到就是根据训练loss曲线,看是否接近收敛,如果接近收敛,则停止蒸馏。
实验结果如下:

10 2019年——"Self-training with Noisy Student improves ImageNet classification"——Qizhe Xie、Minh-Thang Luong
10.1 论文链接
Self-training with Noisy Student improves ImageNet classification
10.2 摘要
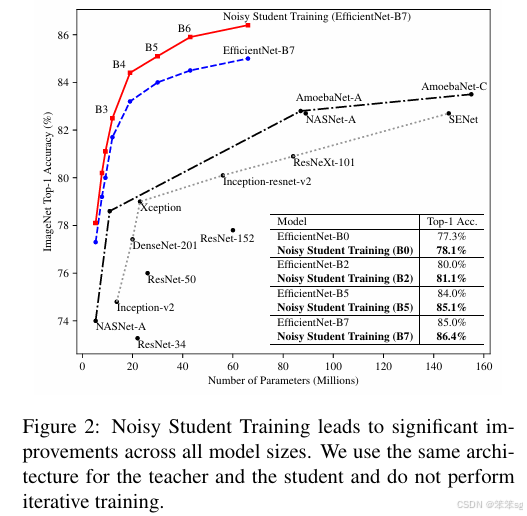
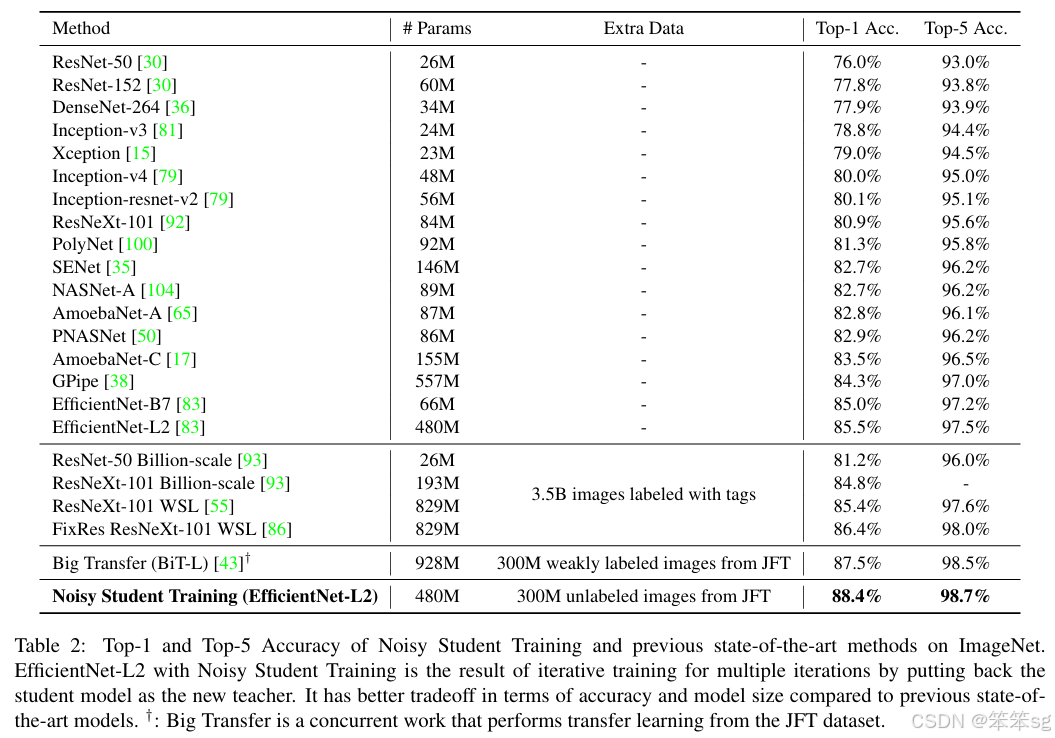
我们提出了Noisy Student Training,这是一种半监督学习方法,即使在标注数据充足的情况下也表现良好。Noisy Student Training在ImageNet上实现了88.4%的Top-1准确率,比依赖35亿弱标注Instagram图像的最新模型高出2.0%。在鲁棒性测试集上,它将ImageNet-A的Top-1准确率从61.0%提高到83.7%,将ImageNet-C的平均腐蚀误差从45.7降低到28.3,并将ImageNet-P的平均翻转率从27.8%降低到12.2%。
Noisy Student Training通过使用等于或更大的学生模型以及在学习过程中为学生添加噪声,扩展了自训练和蒸馏的概念。在ImageNet上,我们首先在标注图像上训练一个EfficientNet模型,并将其作为教师模型,为3亿张未标注图像生成伪标签。然后,我们将一个更大的EfficientNet作为学生模型,使用标注图像和伪标注图像的组合进行训练。我们通过将学生模型作为教师模型重复这一过程。在学生模型的学习过程中,我们注入噪声(如dropout、随机深度以及通过RandAugment进行的数据增强),以使学生模型的泛化能力优于教师模型。
10.3 核心思想
继续使用KD softed labels, 但是聚焦data issue,通过使用更大的噪声数据集来训练student模型。 大致思路:
- 首先在ImageNet上训练Teacher Network
- 再使用训练好的T网络(无噪音)来对另一个数据集JFT dataset生成尽可能准确的伪标签
- 之后使用生成伪标签的数据集JFT dataset和ImageNet一起训练Student Network
除此之外,作者还提到一些tricks:
- 在Student Network训练中,增加了模型噪音(DropOut 0.5、随机深度 0.8、随机增强 震级27 ),提高鲁棒性和泛化能力
- 数据过滤,将教师模型中置信度不高的图片过滤,因为这通常代表着域外图像
- 数据平衡,平衡不同类别的图片数量
- 教师模型输出的标签使用软标签
实验结果如下:
11 2019年——"Training deep neural networks in generations"——Chenglin Yang、Lingxi Xie
11.1 论文链接
Training Deep Neural Networks in Generations: AMoreTolerant Teacher Educates Better Students
11.2 摘要
我们专注于分代训练深度神经网络的问题。流程是首先训练一个具有相同架构的网络(教师网络),并在下一阶段为目标网络(学生网络)的优化提供部分监督信号。尽管这种策略可以提高准确率,但许多方面(例如,为什么教师-学生优化有效)仍需要进一步探索。
本文从控制教师网络训练严格性的角度研究了这个问题。现有方法大多在训练中使用硬分布(例如,独热向量),这会导致教师网络变得非常严格,并具有较高的准确率。但我们认为,教师网络需要更宽容,尽管这通常意味着较低的准确率。实现非常简单,仅需在教师网络中添加一个额外的损失项,从而促使一些次级类别出现并补充主类别。结果是,教师网络提供了较为温和的监督信号(分布峰值较低),使学生网络能够学习类别间的相似性,并潜在地降低过拟合风险。
我们在标准图像分类任务(CIFAR100和ILSVRC2012)上进行了实验。尽管教师网络表现较弱,但学生网络表现出持续的能力增长,最终在分类准确率上超过了其他竞争者。模型集成和迁移特征提取也验证了我们方法的有效性。
11.3 核心思想
继续使用KD softed labels, 但是在蒸馏过程中通过增加约束来达到优化目标,通常约束加在teacher或者student network。大致思路:作者发现除了ground Truth class, secondary class可以有效学习类间相似度,并且防止student network过拟合,取得好的效果。作者挑选了几个具有最高置信度分数的类,并假设这些类在语义上更可能与输入图像相似。设置了一个固定的整数K,代表每个图像语义上合理的类的数量,包括ground Truth类。然后计算ground Truth类与其他得分最高的K-1类之间的差距。
【举个例子】
-
选择最可能的类别:对于每张图片,挑选出置信度最高的几个类别(包括正确答案,比如猫,以及其他几个高置信度的次级类别,比如狗和兔子)。假设有一个固定整数 K,表示每张图片要选出几个“语义相关”的类别。比如 K=3K = 3K=3,那么就选“猫、狗、兔子”三个类别。
-
计算差距:计算“正确类别(猫)”的概率和这些次级类别(狗、兔子)的概率之间的差距。这个差距作为一种约束,用于优化学生网络。比如:猫的概率是 0.8,狗是 0.1,兔子是 0.05,作者会让学生关注这些差距: 差距1: 0.8−0.1=0.7 ;差距2: 0.8−0.05=0.75。学生需要学习这些差距关系,既能明确“猫是正确答案”,也能理解“狗和兔子在某种程度上是相似的”。
损失函数推导:
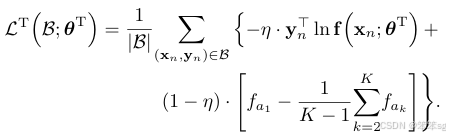
实验结果如下:

实验结果,K越大,效果越明显。
12 2019年——"Distillation-Based Training for Multi-Exit Architectures"——Mary Phuong、AmCampus1
12.1 论文链接
Distillation-Based Training for Multi-Exit Architectures
12.2 摘要
多出口架构(Multi-exit architectures)是一种将处理层堆叠与早期输出层(early output layers)交替插入的设计,允许在测试时可以提前停止处理,从而节省计算时间和/或能耗。在本文中,我们提出了一种基于知识蒸馏(Knowledge Distillation)原理的多出口架构新训练方法。该方法通过匹配早期出口与后期更准确出口的输出概率,鼓励早期出口模仿后期出口。
在 CIFAR100 和 ImageNet 数据集上的实验表明,基于蒸馏的训练方法显著提升了早期出口的准确性,同时保持了后期出口的先进性能。该方法在训练数据有限的情况下表现尤为出色,并且能够轻松扩展到半监督学习(semi-supervised learning),即在训练时利用未标注数据。此外,该方法实现非常简单,仅需几行代码,训练时几乎不增加计算开销,测试时完全没有额外开销。
12.3 核心思想
通俗理解:
- 模型有多个“出口”,相当于在爬楼梯时,不用爬到顶就可以停下来“拍照”得到一个结果。
- 通过一种“老师教学生”的方式(知识蒸馏),让早期出口(低楼层)也能接近后期出口(高楼层)的结果。
通常KD在student和teacher network网络模型容量相差较大时,表现较差。Ensemble distribution KD方法可以很好的保证分布diversity,同时多个模型融合的结构较好。大致思路:作者借鉴muti-exit architectures去做ensemble distribution KD,扩展提出新的损失函数。
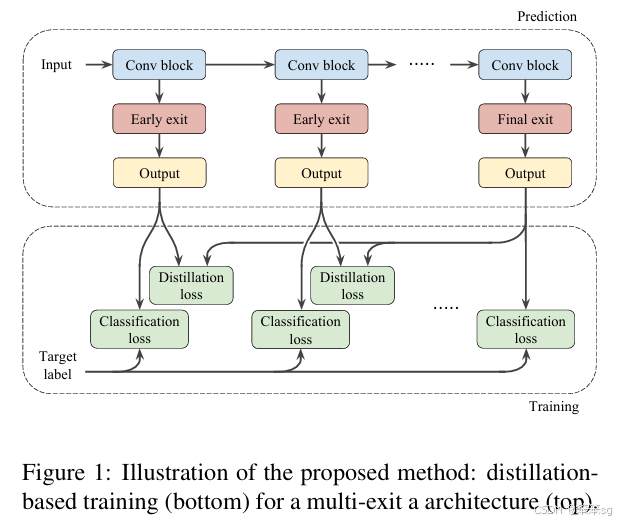
损失函数推导:
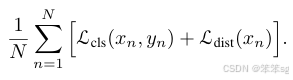
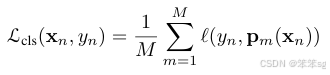
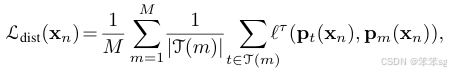
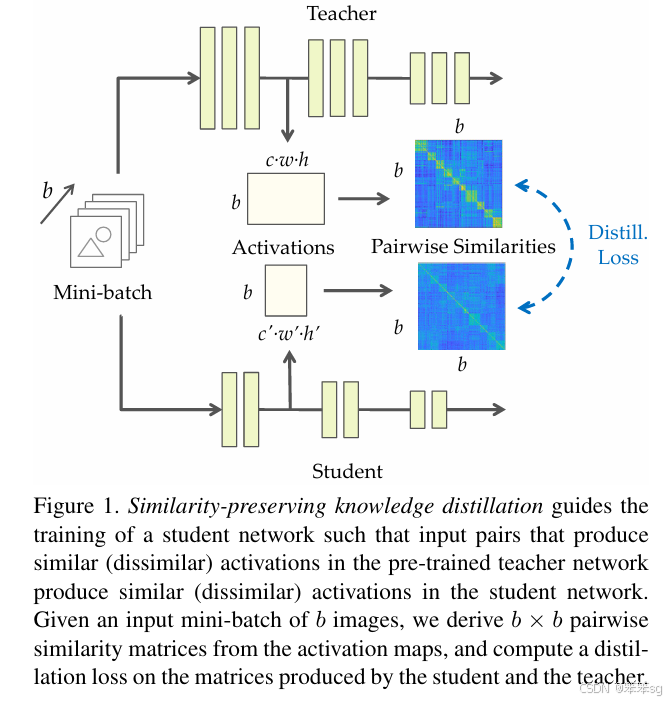
13 2019年——"Similarity-Preserving Knowledge Distillation"——Frederick Tung、Greg Mori
13.1 论文链接
Similarity-Preserving Knowledge Distillation
13.2 摘要
知识蒸馏是一种广泛适用的技术,用于在训练好的教师网络的指导下训练学生神经网络。例如,在神经网络压缩中,通过蒸馏高容量的教师模型来训练一个紧凑的学生模型;在特权学习中,通过蒸馏利用特权数据训练的教师模型来训练一个无法访问这些数据的学生模型。蒸馏损失决定了教师的知识如何被捕获并转移到学生模型中。
本文提出了一种新的知识蒸馏损失形式,其灵感来源于一个观察,即语义上相似的输入通常会在训练好的网络中引发相似的激活模式。相似性保持的知识蒸馏指导学生网络的训练,使得在教师网络中产生相似(或不相似)激活的输入对,在学生网络中也能产生相似(或不相似)的激活。
与以往的蒸馏方法不同,学生不需要模仿教师的表示空间,而是要在其自己的表示空间中保持成对输入的相似性。基于三个公共数据集的实验结果表明了该方法的潜力。
13.3 核心思想
如果两个输入在教师网络中有着高度相似的激活,那么引导学生网络趋向于对该输入同样产生高的相似激活(反之亦然)的参数组合,那将是有利的(对于学生更好的学习老师网络的能力与知识)。基于这个观察和假设,本文主要思路提出了一个保留相似性损失,来促使学生网络学习老师网络在对于数据内部的关系表达的知识。
假设证明试验:
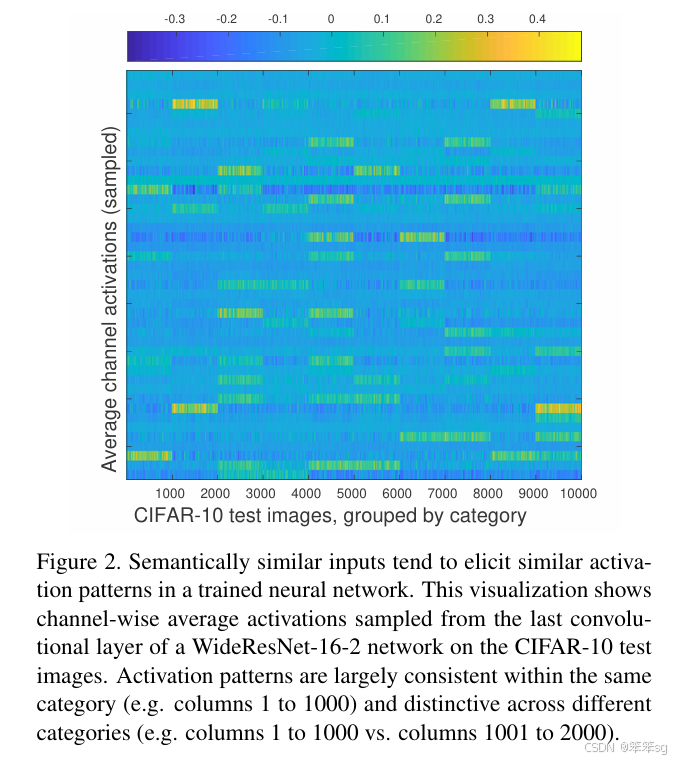
图2这个图指示了CIFAR-10中10000张图片分别对应于教师网络最后一个卷积层的激活值中所有通道内计算均值得到的矢量,整体绘制出来得到的结果。这里分成了十类,每一类对应相邻的1000张图片,可见,相邻的1000张图片的激活情况是类似的,而不同类别之间有明显差异。

图3中展示了对于CIFAR-10测试集上的数个batch的G矩阵可视化结果,这里的激活是从最后一个卷积层收集而来的。
• 每一列表示一个单独的batch,两个网络都是一致的。
• 每个batch的图像中,对于样本的顺序已经通过其真值类别分组。一个batch包含128张图片样本。在两行的G矩阵中,显示了独特的块状模式,这指示了者系网络的最后一层的激活,在相同类别的时候有着相似的结果,而不同类别也有着不同的结果,也就是前者有着更大的相似性,后者相似性较小。
• 图中每个块大小不同,这主要是因为不同类别在每个batch中包含的样本数不同。
• 上下对比也可以看出来,对于复杂模型(下面),块状模式更加明显突出,这也反映出来,其对于捕获数据集的语义信息有着更强的能力。
• 这样的现象也在一定程度上支撑了本文的假设,也反映出前面提出的相似性损失的意义与价值所在,就是促使学生网络可以更好的模仿学习老师模型对于数据特征中的关联信息的学习。
实验结果:
13 2019年——"Be Your Own Teacher"——Linfeng Zhang、Jiebo Song...
这篇论文一作是NEU-CS-15级的亲学长,2019年他才大四就发了一篇这么nb的论文,我这种21级小菜鸡只能顶礼膜拜了(ORZ)。
13.1 论文链接
Be Your OwnTeacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
13.2 摘要
卷积神经网络已广泛应用于各种应用场景。为了将应用的边界扩展到一些对准确性要求极高的领域,研究人员一直在探索通过更深或更宽的网络结构来提高准确性的方法,这带来了计算和存储成本的指数级增长,从而延迟了响应时间。
本文提出了一种名为自蒸馏(Self-Distillation)的通用训练框架,通过缩小网络规模而非扩展它,显著提升卷积神经网络的性能(准确性)。与传统的知识蒸馏不同——传统知识蒸馏是一种网络之间的知识转换方法,强迫学生神经网络逼近预训练教师神经网络的softmax层输出——本文提出的自蒸馏框架在网络内部进行知识蒸馏。网络首先被分成多个部分,然后将网络较深部分的知识压缩到较浅部分。实验进一步证明了所提自蒸馏框架的泛化能力:准确性平均提升了2.65%,最小提升为0.61%(在ResNeXt中),最大提升为4.07%(在VGG19中)。此外,它还提供了在资源有限的边缘设备上进行深度可扩展推理的灵活性。我们的代码将在GitHub上发布。
13.3 核心思想
传统的方法要么关注于提升精度,要么关注于减少计算成本。例如,一般通过将模型结构复杂化去提升精度,通过知识蒸馏去压缩模型从而减少计算成本。但是传统的方法仍有它的不足之处,前者提升一点精度的代价可能就是计算成本会指数级地增加,例如:ResNet100和ResNet150;后者也面临着精度下降、Teacher模型选择较为困难和过多超参数需要调整的问题。
有了以上的motivations,这篇论文就提出了self distillation这种训练方式。总体而言,作者的contributions如下:
- 提出了一种one-step的自我知识蒸馏的框架,不仅能够显著增加精度,还不会增加任何推理时的计算成本
- 作者在五种卷积网络架构和两种数据集上跑了实验,验证了self distillation这种方法的泛化能力。
这篇论文引的一些Related work比较有意思,所以在这里记录一下。主要分为以下三类:
- Knowledge Distillation:知识蒸馏就不解释了,可以看看Hinton的Distilling the Knowledge in a Neural Network以及Romero的FitNets(第一次提出了hint learning,本文也借鉴到了这个思想)
- Adaptive Computation:一些researchers会选择性地去掉模型中的一些计算过程从而达到节省计算资源的目的。可去掉的过程主要是以下三类:layers, channels and images
- Deep Supervision:深度监督这个和本论文的self distillation最为相似,主要的不同就在于self distillation浅层的classifiers是通过distillation来学习的,而Deep Supervision则是通过label来学习
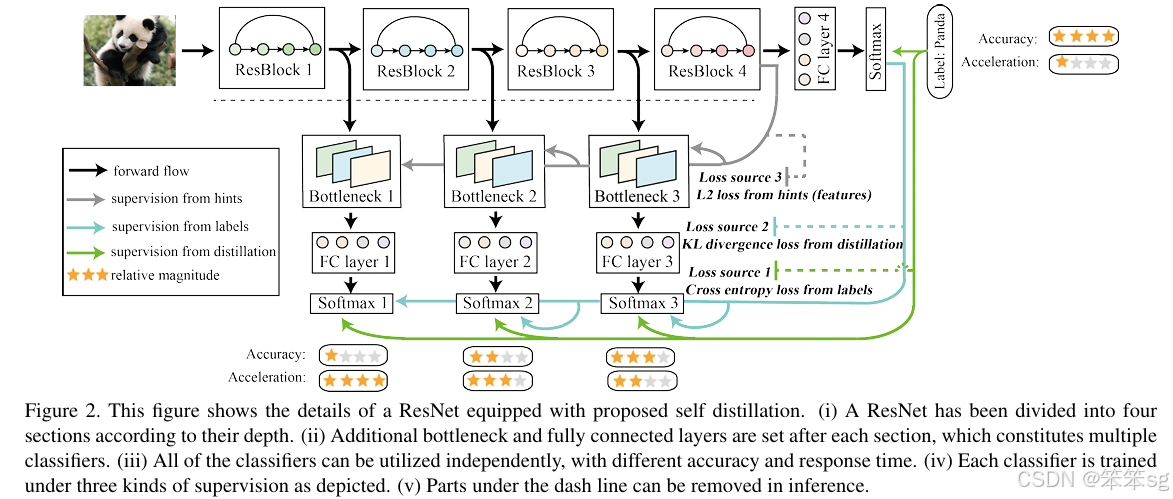
如上图所示,整体来看整个训练过程的思想就是最深层layer去蒸馏和监督浅层的各个Blocks。黑色虚线下方的Bottlenecks、FC Layers、Softmaxs这些都是训练时为了方便蒸馏和监督时加入的模块,在inference的时候是不需要这些的,因此不会增加任何推理计算成本。
整个模型的监督和蒸馏的loss分为三大部分:
Loss source 1: Cross entropy loss from labels(绿色线),公式如下:
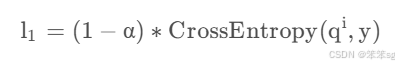
其中, 就是第i个softmax层分类器的输出(包括最深一层softxmax)。
Loss source 2: KL divergence loss from distillation(蓝色线),公式如下:
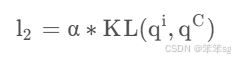
其中, 就是第i个softmax层分类器的输出,
是最深层softmax层分类器的输出。
Loss source 3: L2 loss from hints(from features)(灰色线),这一部分是用来监督bottlenecks的,公式如下:
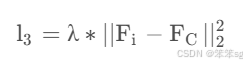
其中, 就是第i个bottleneck的feature输出,
就是最深bottleneck的feature输出。
综上,总体的loss公式如下:
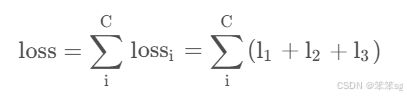
当i=C,即最后一层时,α , λ 为0。
14 2020年——"Online Knowledge Distillation via Collaborative Learning"——Qiushan Guo、Xinjiang Wang
14.1 论文链接
Online Knowledge Distillation via Collaborative Learning
14.2 摘要
这项工作提出了一种高效且有效的在线知识蒸馏方法,通过协同学习(KDCL),能够持续提升具有不同学习能力的深度神经网络(DNN)的泛化能力。与现有的两阶段知识蒸馏方法不同,传统方法先预训练一个大容量的DNN作为“教师”,然后将教师的知识单向传递给另一个“学生”DNN(即单向传递),KDCL将所有DNN视为“学生”,并在单阶段内进行协同训练(在协同训练过程中,知识在任意学生之间传递),从而实现并行计算、快速计算和良好的泛化能力。具体来说,我们精心设计了多种方法,通过有效地集成学生的预测并扭曲输入图像来生成软目标作为监督信号。大量实验表明,KDCL在不同数据集上持续提升了所有“学生”的表现,包括CIFAR-100和ImageNet。例如,当ResNet-50和MobileNetV2一起使用KDCL训练时,分别在ImageNet上达到了78.2%和74.0%的Top-1准确率,分别比原始结果提升了1.4%和2.0%。我们还验证了使用KDCL预训练的模型在MS COCO数据集上的目标检测和语义分割任务中表现良好。例如,FPN检测器的mAP提升了0.9%。
14.3 核心思想
和之前的“Deep mutual learning CVPR 2018”论文一样,该方法采用的也是在线蒸馏的方式。
下面是本文的方法和其他一些方法结构上的不同:
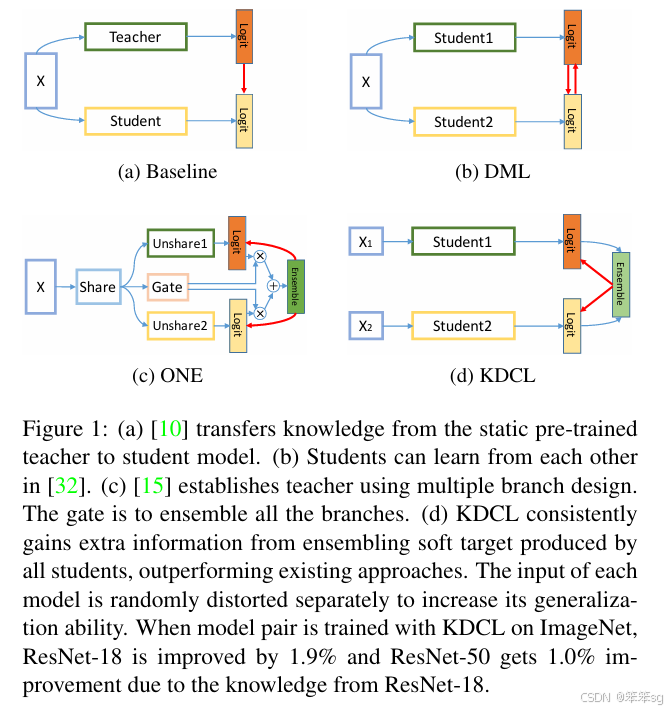
图1:(a)[10]将知识从静态的预先培训的教师转移到学生模型。(b) 学生可以在[32]中相互学习。(c) [15]使用多分支设计建立教师。gate是把所有的分支集合在一起。(d) KDCL始终从所有学生产生的组合软目标中获得额外信息,优于现有方法。每个模型的输入分别随机失真,以提高其泛化能力。当在ImageNet上用KDCL训练模型对时,由于ResNet-18的知识,ResNet-18提高了1.9%,ResNet-50提高了1.0%。
知识提炼通常被定义为“师生”学习环境。它能够提高紧凑的“学生”深度神经网络的性能,因为“教师”网络的表示可以用作结构化知识来指导学生的训练。教师产生的预测(如软目标)可以很容易地被学生学习,并鼓励学生比从头开始训练的预测更好地概括。然而,在传统的离线知识提取框架中,教师首先经过预训练,然后固定,这意味着知识只能从教师转移到学生(即单向),如图1a所示。
在线蒸馏方法更具吸引力,因为训练过程被简化为单个阶段,并且所有网络都被视为学生。这些方法融合了所有学生网络的培训过程,使他们能够从彼此那里获得额外的知识。在深度相互学习(DML)中,学生直接从其他学生的预测中学习,如图1b所示。然而,学生的产出可能是多样的,相互冲突,甚至是基本事实。当模型之间的性能显著不同时,这种方法会损害高性能模型。
(ONE)提出的另一种方法是在建立动态教师的同时训练多分支网络,如图1c所示。尽管如此,这种方法是不灵活的,因为网络被迫共享较低的层,并且知识转移仅发生在单个模型中的上层,而不是其他模型中的高层,从而限制了额外的知识和性能。门模块并不能保证高质量的软目标。
自蒸馏表明,与教师相比,将收敛的教师模型蒸馏为相同网络架构的学生模型可以进一步提高泛化能力。自蒸馏和在线蒸馏的功效使我们产生了以下问题:我们能否在一级蒸馏框架中使用一个小网络来改进具有更大容量的模型?
在这项工作中,我们提出了一种新的通过协作学习的在线知识提取方法。在KDCL中,具有不同能力的学生网络协作学习,以产生高质量的软目标监督,如图1d所示,它为每个学生提取了额外的知识。高质量的软目标监督旨在指导具有显著性能差距的学生以更高的泛化能力和更小的数据域输入扰动方差一致收敛。
主要挑战是产生软目标监督,以提高所有具有不同学习能力或显著成绩差距的学生的高信心表现。当模型输出之间存在差异时,嵌入往往会产生更好的结果。因此,我们建议通过在线方式将学生的输出与地面实况信息仔细组合,生成高质量的软目标监督。此外,我们建议通过在验证集上测量模型来估计泛化误差。生成软目标是为了在验证集上具有更强的泛化能力。
为了提高对输入数据域中扰动的不变性,软目标应该鼓励学生以类似的失真输入图像进行类似的输出。因此,向学生提供图像,这些图像是从相同的输入中单独扰动的,并且通过组合输出并融合数据增强的信息来生成软目标。在这种情况下,模型集成的好处得到了进一步的利用。
为了评估KDCL的效果,我们对图像分类的基准CIFAR-100和ImageNet-2012进行了广泛的实验。我们证明,使用KDCL,成对训练的ResNet-50[8]和ResNet-18分别达到77.8%和73.1%的val准确率。得益于ResNet-18的额外知识,ResNet18的性能比基线提高了1.9%,ResNet-50的性能提高了1.0%。我们还验证了用KDCL预训练的模型在COCO数据集上很好地转移到对象检测和语义分割。
我们的贡献如下。
- 设计了一个基于协作学习的新的知识提炼管道。各种学习能力的模型可以从合作培训中受益。
- 设计了一系列模型集成方法,以在一阶段在线知识提取框架中动态生成高质量的软目标。
- 通过转移知识和融合具有不同失真的图像输出,增强了输入域中对扰动的不变性。
下面是本文提出的方法的概图:
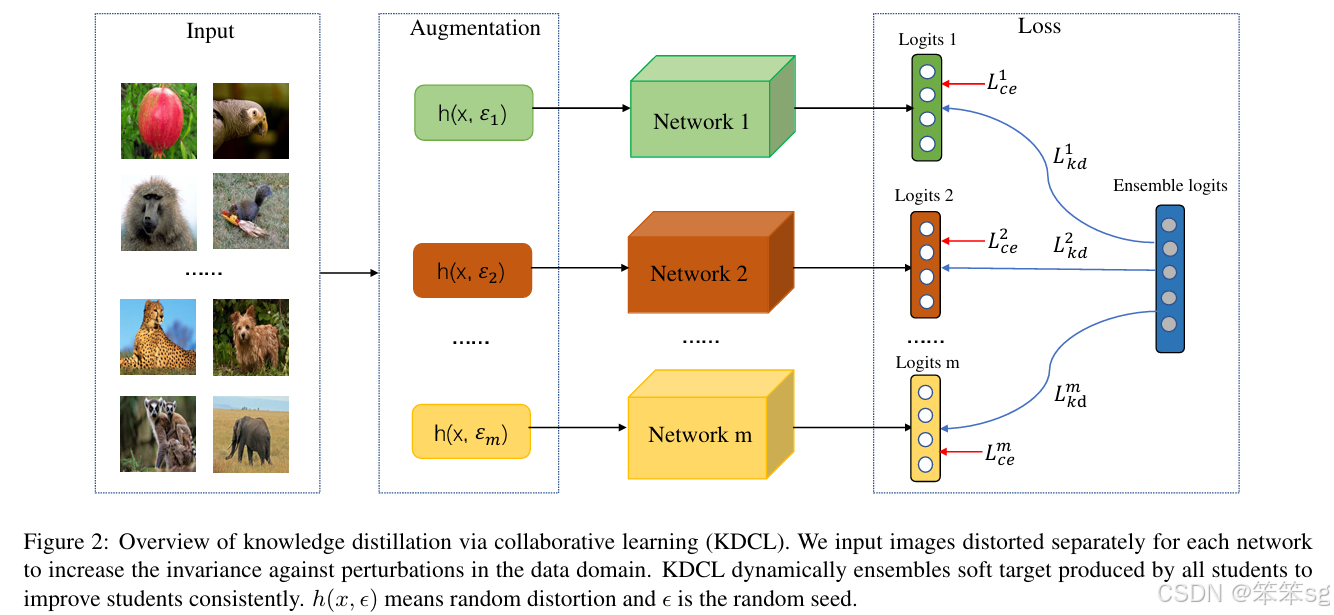
KDCL 的亮点在于以在线的方式自动产生软目标,然后提出了多种方法来产生软目标,比如 KDCL-Naive.、KDCL-Linear.、KDCL-MinLogit.、KDCL-General。另外为了提高对数据扰动的不变性对每一个子网络进行了数据增强并且融合这些知识。
15 2~14总结
上面我们详细介绍了KD领域从2015年的开山之作到2020年大量KD相关工作的涌现,现在我们来简单做个分类总结。
15.1 从知识的角度出发
我们知道在神经网络中,知识通常是指学习到的权重和偏置。同时,大型深度神经网络中还存在丰富多样的知识来源。典型的知识蒸馏方法使用模型输出(logits)作为教师知识的来源,而其他方法则关注中间层的权重或激活值。此外,还有其他类型的相关知识,例如不同类型激活值和神经元之间的关系,或教师模型本身的参数。
这些不同形式的知识可分为以下三类:
- 基于响应的知识(Response-based knowledge)
- 基于特征的知识(Feature-based knowledge)
- 基于关系的知识(Relation-based knowledge)
因此从这个角度出发,我们可以将上述工作归为以下三类:
Logits(Response)-based:
- Distilling the Knowledge in a Neural Network Hilton NIPS 2014
- Deep mutual learning CVPR 2018
- On the efficacy of knowledge distillation, ICCV 2019
- Self-training with noisy student improves imagenet classification 2019
- Training deep neural networks in generations: A more tolerant teacher educates better students AAAI 2019
- Distillation-based training for multi-exit architectures ICCV 2019
- Be Your OwnTeacher: Improve the Performance of Convolutional Neural Networks via Self Distillation ICCV 2019
- Online Knowledge Distillation via Collaborative Learning CVPR 2020
Feature-based:
- Fitnets: Hints for thin deep nets. ICLR 2015
- Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. ICLR 2017
- Paraphrasing Complex Network: Network Compression via Factor Transfer. NeurIPS 2018
- A Comprehensive Overhaul of Feature Distillation. ICCV 2019
Relation-based:
- A gift from knowledge distillation: Fast optimization, network minimization and transfer learning CVPR 2017
- Similarity-preserving knowledge distillation ICCV 2019
15.2 3种基于知识的方式优缺点总结
15.2.1 Logits(Response)-based Knowledge优缺点总结
优点:
1.简单易于理解,student模型学teacher模型输出的概率分布,相当于给出了类别之间的相似性信息,提供了额外的监督信号,学起来更容易。
2.对于输出层,实现简单方便。
缺点:
1.蒸馏效率依赖于softmax loss计算和number of class
2.对于没有label(low-level vision)的问题,无法去做
3.当student network模型太小时,很难从teacher network distilled成功
15.2.2 Feature/Relation-based Knowledge优缺点总结
优点:
- 泛化性更好,目前SOTA的方法都是基于feature/Relation
- 可以处理cross domain transfer and low-level vision问题
缺点:
- 对于信息损失很难度量,因此很难选择最好的方法。
- 大多数方法随机选择intermediate layers,可解释性不够
- 特征的蒸馏位置手动选择或基于任务选择
15.3 从训练方式的角度出发
训练学生模型和教师模型的方法主要分为三类:离线蒸馏、在线蒸馏和自蒸馏。蒸馏训练方法的分类取决于教师模型是否与学生模型同时更新。
因此从这个角度出发,我们可以将上述工作归为以下两类:
离线蒸馏:
- Distilling the Knowledge in a Neural Network Hilton NIPS 2014
- Fitnets: Hints for thin deep nets. ICLR 2015
- Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. ICLR 2017
- A gift from knowledge distillation: Fast optimization, network minimization and transfer learning CVPR 2017
- Paraphrasing Complex Network: Network Compression via Factor Transfer. NeurIPS 2018
- A Comprehensive Overhaul of Feature Distillation. ICCV 2019
- On the efficacy of knowledge distillation, ICCV 2019
- Self-training with noisy student improves imagenet classification 2019
- Training deep neural networks in generations: A more tolerant teacher educates better students AAAI 2019
- Similarity-preserving knowledge distillation ICCV 2019
在线蒸馏:
- Deep mutual learning CVPR 2018
- Online Knowledge Distillation via Collaborative Learning CVPR 2020
自蒸馏:
- Distillation-based training for multi-exit architectures ICCV 2019
- Be Your OwnTeacher: Improve the Performance of Convolutional Neural Networks via Self Distillation ICCV 2019
16 Applications-NLP-BERT
因为Bert本身参数量大,当前对Bert瘦身有三个思路,分别是Distillation(蒸馏)、Quantization(量化)和Pruning(剪枝)。其中蒸馏效果最好。因此接下来,将通过三篇paper回顾下BERT蒸馏如何去做。
16.1 DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter 2019
论文链接:1910.01108
源码:DistilBERT
基于Transformer的预训练模型的趋势就是越来越大,训练数据和参数量也是越来越多。
本文将介绍蒸馏方法中的DistilBert。把KD思想简单应用到BERT上,DistilBERT的参数大约只有BERT的40%,而速度快了60%,保证97%精度。大致思路:对BERT做forward pass,再计算Triple Loss,进行Backward Propagation训练DistilBERT。
损失函数:
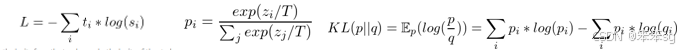
模型最后的输出的由distillation loss 以及训练误差,分别是 Mask language modeling loss 和cosine embedding loss 的线性加和组成。上面的公式主要是拟合两个的模型输出概率分布,理想当然都是用cross entropy来解决,但是在看源码的时候,我们发现这实现中用的是Kullback-Leibler loss。经过查阅资料,发现其实KL距离和cross entropy其实是等价的,都是拟合两个概率分布,使得最大似然。KL diversion 代表的是两个分布的距离,越大 代表分布越不像,越小=0 代表两个分布一样。Mask language modeling loss(跟Bert 一致),首层的embedding的cosine embedding loss 。
模型结构:
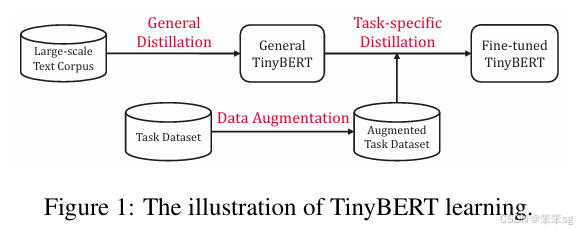
- DistilBert将token-type embeddings以及pooler层去掉
- 学生模型layer数是老师模型的一半,6层transformer encode,但是hidden dim是一致的,文章中指出学生参数初始化是直接复制老师模型的layers,具体的操作是skip的方式,例如12层的教师模型,学生模型6层,初始化用的是for teacher_idx in [0,2,4,7,9,11]。
实验结果:
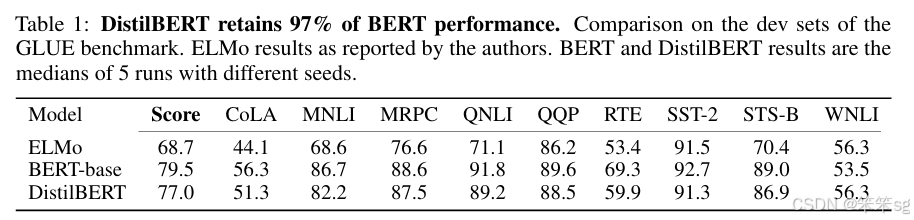


蒸馏模型的效果取决于三个方面,一个是模型大小,一个是模型效果,以及预测速度。文章中对比了distlbert以及教师模型Bert-Base,得出了结论,可以得到97%的Bert的效果,大小减少了近40%,预测时间提高了60%。可以说还是非常好的。它也提出了,它的学生模型可以在iphone7上直接运行。同时,训练时长和机器配置相比训练BERT而言,明显很有优势。

16.2 TinyBERT: Distilling BERT for natural language understanding 2019
论文链接:1909.10351
源码:Pretrained-Language-Model/TinyBERT at master · huawei-noah/Pretrained-Language-Model
通过对Bert编码器中的Transformer进行压缩,提出新的 transformer 蒸馏法,同时还提出了一种专门用于 TinyBERT的两段式学习框架,从而分别在预训练和针对特定任务的具体学习阶段执行 transformer 蒸馏。这一框架确保 TinyBERT 可以获取 teacherBERT 的通用和针对特定任务的知识。最终可以达到96% BERT base performance, 7.5x samller, 9.4x faster.
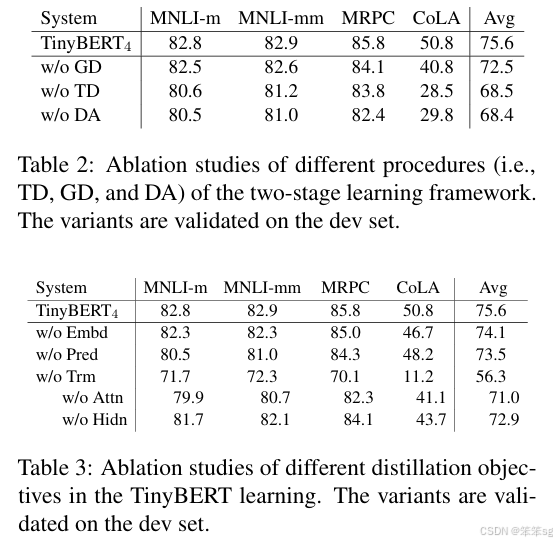
损失函数推导:
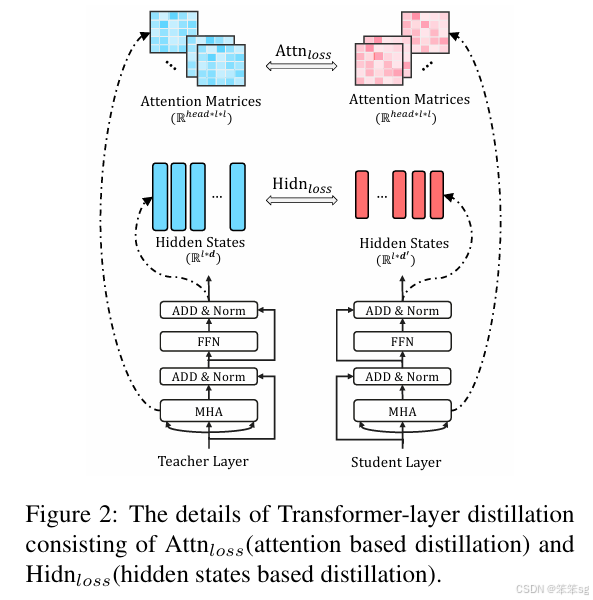
Transformer-layer Distillation
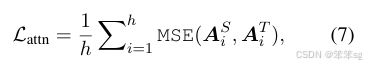
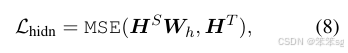
attention based distillation attention 的权重可以获取很多的语言学的知识,所以不能够忽视这些信息。文章中定义每一层的attention loss, 这边的h表示的是attention heads的个数。
hidden states based distillation 除了mimic attention 的权重之外,我们还需要mimic每个encoder的hidden states的输出,Hs表示的是学生的某一个block的hidden states的output, Ht表示的是老师的对应block的hidden states的output,为什么需要乘以Wh呢,这是因为做一个线性映射, Wh 是一个可学习的矩阵,目的是把学生模型的特定向量映射到对应的老师模型的向量空间去,因为我们不要求两个的维度一致。
Embedding-layer Distillation
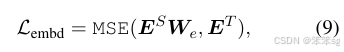
其实embedding layer的学习在distilBERT已经提到了,它学习的是embedding的cosine距离,但是这边提出的的方式用的是MSE,其中Es 表示的是学生的embedding,Et 表示的是老师的embedding,为什么需要乘以We呢,这是因为做一个线性映射, We 是一个可学习的矩阵,目的是把学生模型的特定向量映射到对应的老师模型的向量空间去吗,因为我们不要求两个的维度一致。
Prediction-Layer Distillation,最后的这个就是典型的softmax-soft loss了。
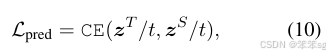
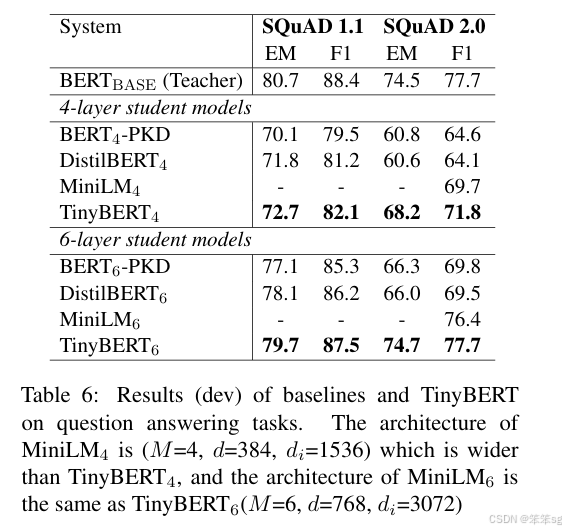
实验结果:
16.3 Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers 2020
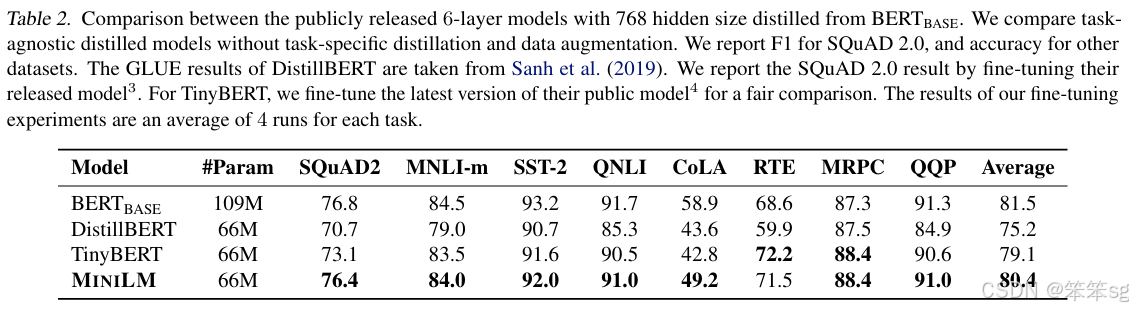
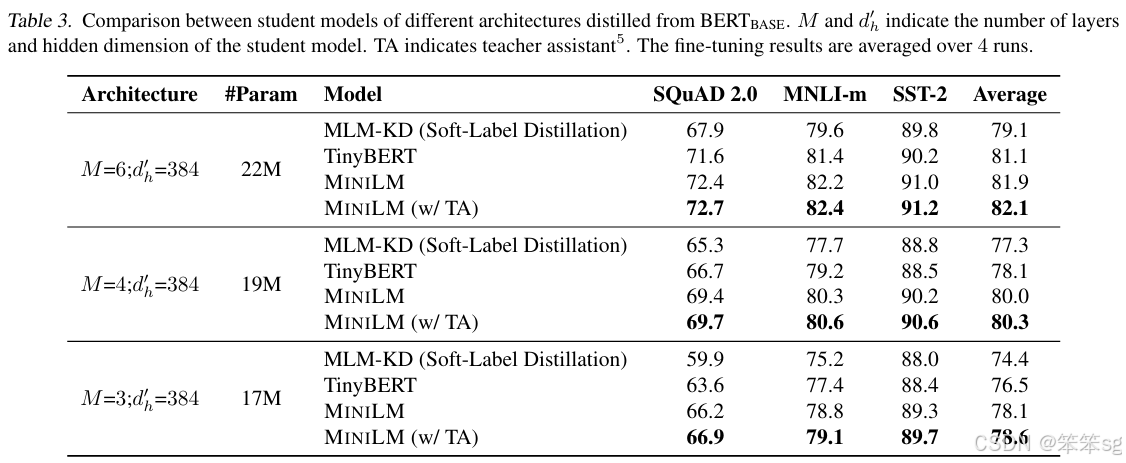
论文链接:MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers
源码:unilm/minilm at master · microsoft/unilm
DistilBERT采用了soft-label distillation loss and a cosine embedding loss,并通过从两层中选取一层来初始化老师的学生。 但是,学生的每个Transformer层都必须具有与其老师相同的体系结构。 TinyBERT利用更细粒度的知识,包括Transformer网络的hidden states和self-attention distributions,并将这些知识逐层转移到学生模型中。 为了进行逐层蒸馏,TinyBERT采用统一函数来确定教师和学生层之间的映射,并使用参数矩阵对学生的隐藏状态进行线性变换。 本文具体提出只蒸馏teacher网络的最后一个Transformer层的self-attention模块,就可以达到不错的效果。与以前的方法相比,使用最后一个Transformer层的知识而不是执行层到层的知识提纯可以减轻教师模型和学生模型之间的层映射困难,并且我们的学生模型的层数可以更灵活。
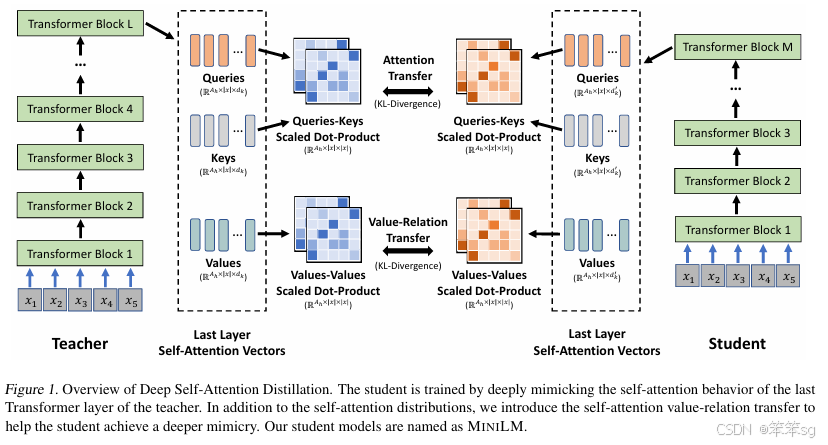
图1整体介绍了深度自注意力知识蒸馏的方法,主要由两种知识迁移构成:
第一种就是自注意力得分/分布迁移(Self-Attention Distribution Transfer),主要迁移自注意力得分/分布知识(Attention Scores/Distributions)。自注意力得分矩阵由Queries 和 Keys 通过点积操作得到,矩阵中每个值表示两个词的依赖关系。自注意力得分矩阵是自注意力模块中至关重要的知识,我们通过相对熵(KL-Divergence)来计算大模型和小模型自注意力得分矩阵的差异。
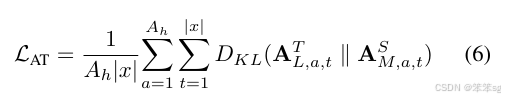
第二种,为了迁移更深层次的自注意力知识,使小模型可以更深层次地模仿大模型,我们引入了 Values 知识并将其转换为关系矩阵进行迁移。Values 关系矩阵(Value Relation)由 Values 向量间点积得到,可以表示 Values 词与词间的依赖。使用点积操作可以将大小模型不同维度的 Values 向量转换为相同维度大小的关系矩阵,避免引入额外的随机初始化参数对小模型的 Values 向量进行线性变换,以使其和大模型向量具有相同的维度来进行知识迁移。我们也通过相对熵来衡量大小模型间关系矩阵的差异。
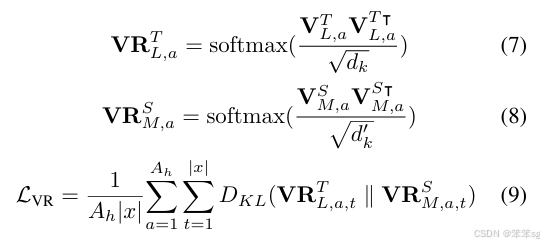
整体损失函数:
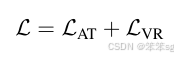
实验结果:
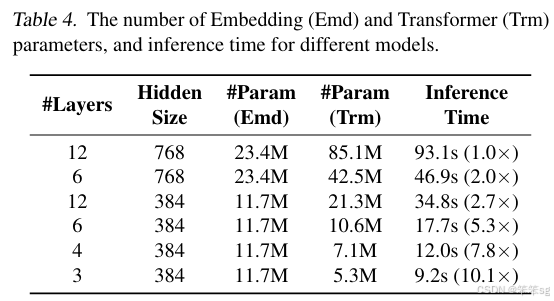
17 QA
17.1 Why KD works?
17.1.1 证明1
论文链接:Explaining Knowledge Distillation by Quantifying the Knowledge
作者提出三个假设,并依次证明。
1.KD促使DNN更容易从数据中学习更多的视觉概念。
2.KD可确保DNN更容易同时学习到各种视觉概念,在没有KD的情况下,DNN在多个阶段分阶段学习不同的视觉概念。
3. KD使得学习产生了更稳定的优化方向。
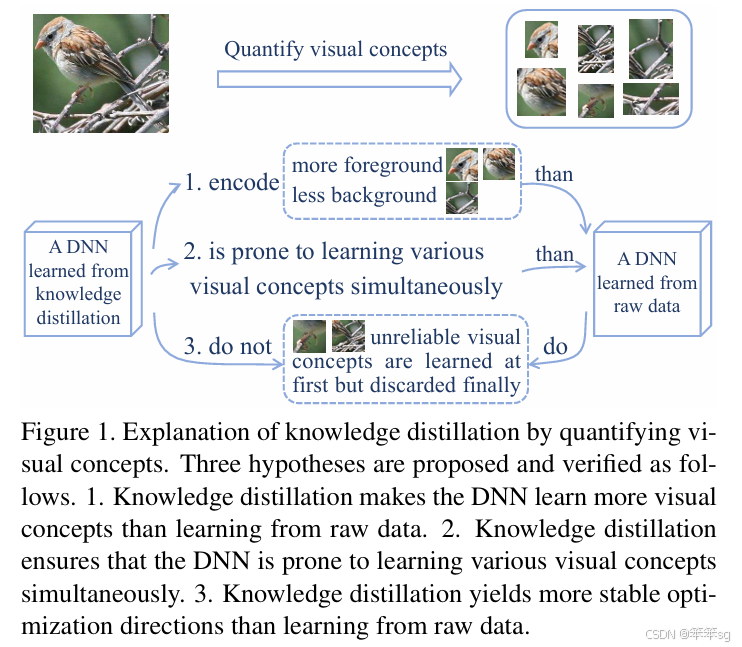
如何证明?
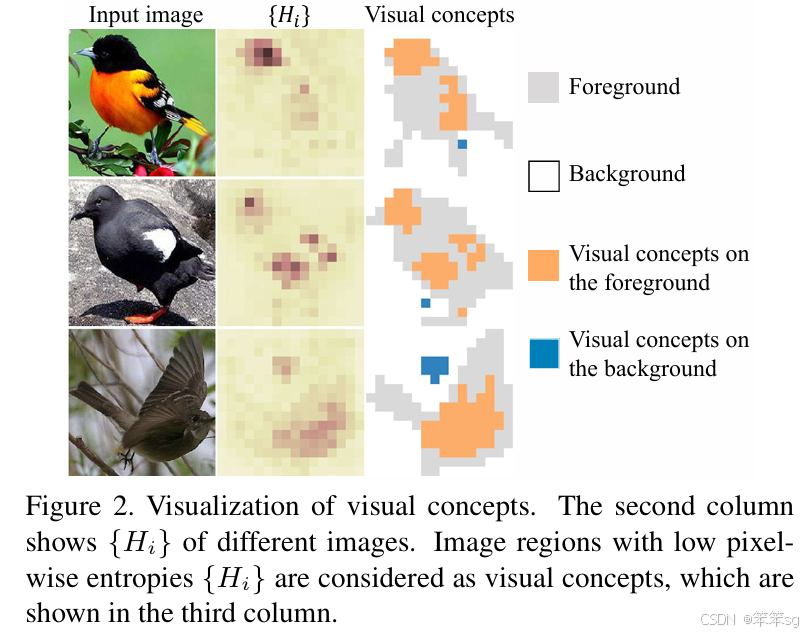
对于第一个假设,就是如何度量测试number of visual concepts;
第二个假设就是度量学习不同visual concepts的速度;
第三个假设就是度量学习的稳定性。
假设一证明:

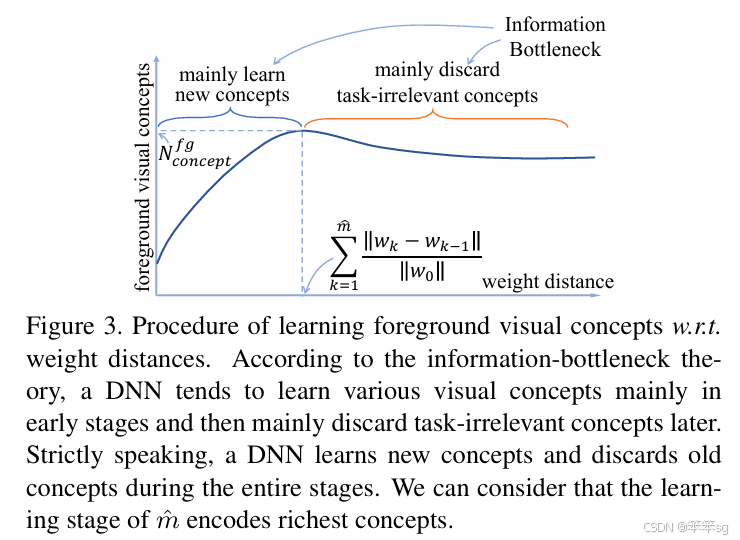
假设二证明:
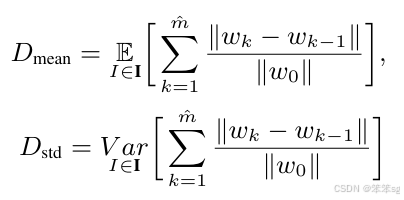

假设三证明:
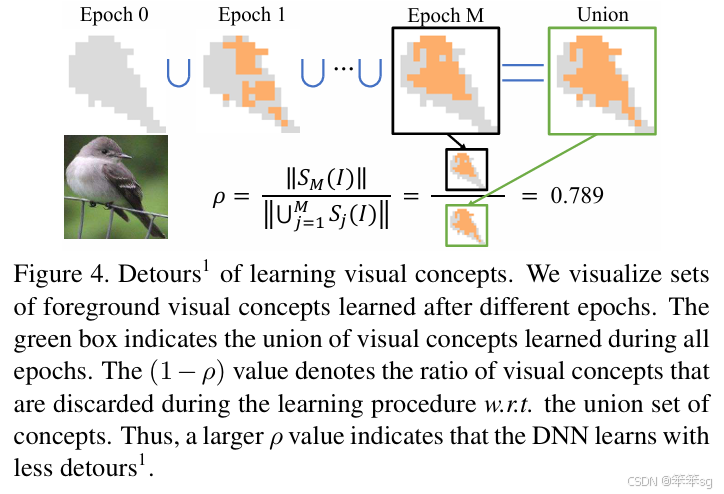
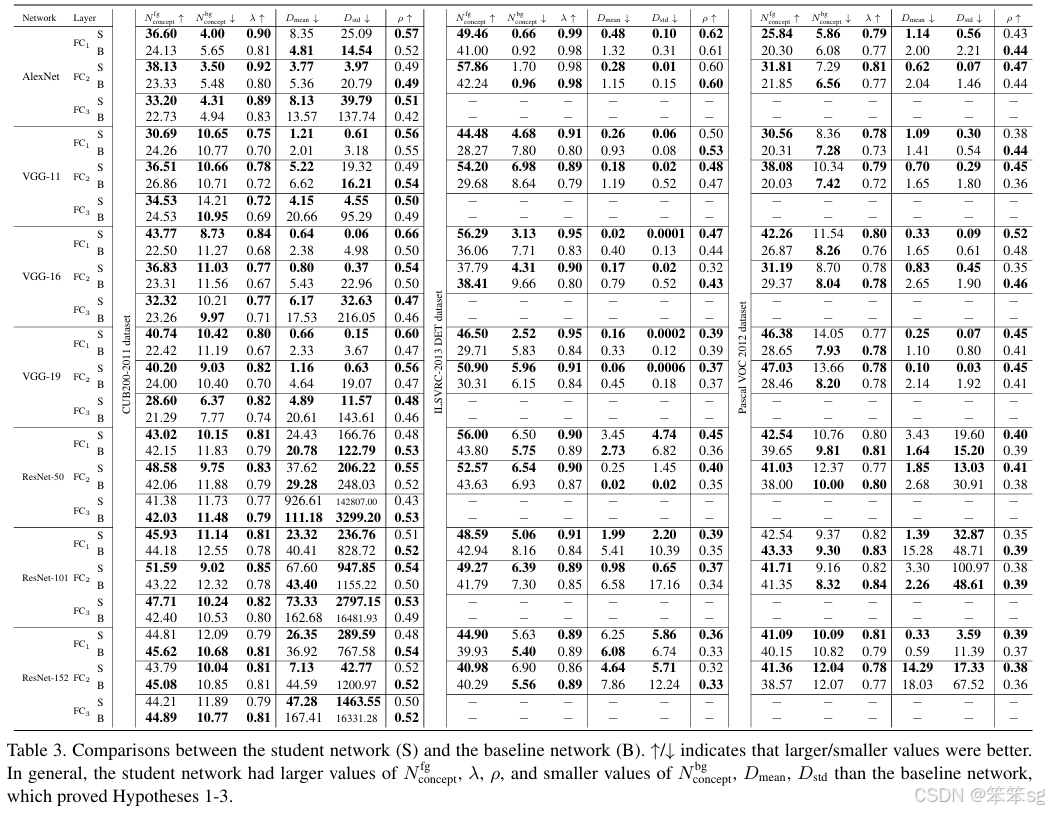
分子反应了视觉概念的数量,最终被选作对象分类,就是图4里面的黑框里面的东西; 分母表示在学习过程中临时学习到的视觉概念,就是图4里面绿色框里面的东西。最终分子/分母,代表已尝试过但最终被DNN丢弃的视觉概念集。 一个高的 ρ 表示DNN少走弯路,更稳定地优化;反之亦然。具体请看最后试验结果汇总表3。
实验结果:
17.1.2 证明2
论文链接:Variational Information Distillation for Knowledge Transfer
作者总结到,KD其实是最大化teacher network 和student network之间的mutual information(互信息)。通过大量的数学推导,得出下面的公式。具体推导过程,读者可以看原paper。

t代表教师网络的中间层,s代表相对应的student网络的中间层,c,h,w分别对应channel,height,width;q(t|s)是variational distribution变异分布,公式如图所示,是一个高斯均方差分布和标准差之和。有了这个公式,可以画出它学习过程中的variational distribution的heat map热度图(红色像素代表概率越高),我们直接看图。
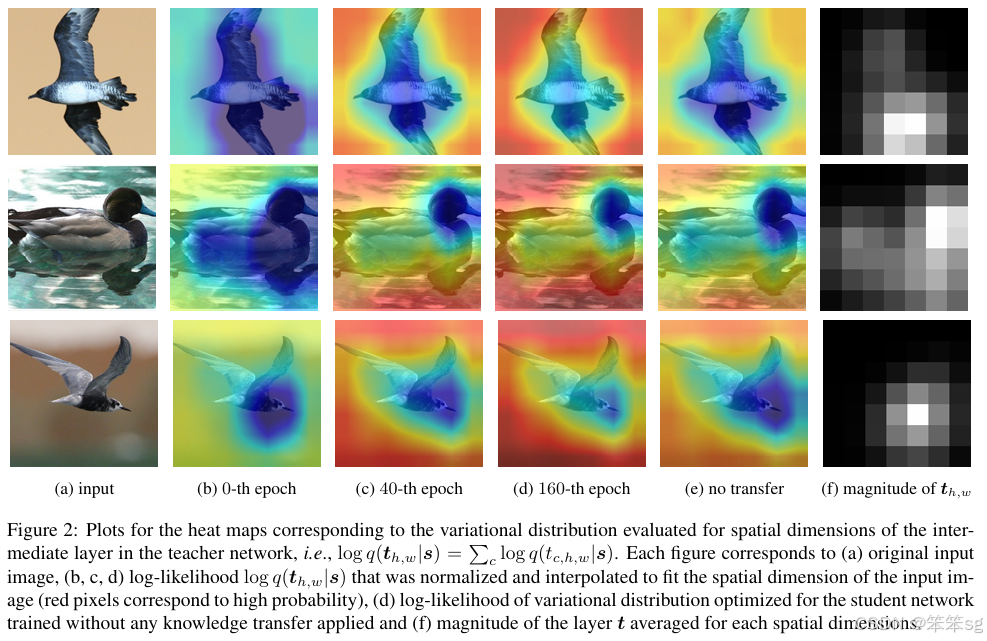
图a是输入图像,图(b,c和d)是不同训练epoch下的student网络和teacher网络variational distribution的密度heat map变化,观察到学生网络通过训练,根据教师网络去估计中间层的密度分布;同时作为比较,作者也画出了未经KD训练的学生网络和老师网络的variational distribution的密度heat map变化(图e所示)。通过e和b/c/d的相互比较,我们观察到e无法获得较高的variational distribution对数似然概率,这表明教师与学生网络之间的相互信息较少。 即作者的推断和理论推导work,KD其实是最大化teacher network 和student network之间的mutual information(互信息)。
17.2 Are bigger models better teachers?
论文链接:On the Efficacy of Knowledge Distillation
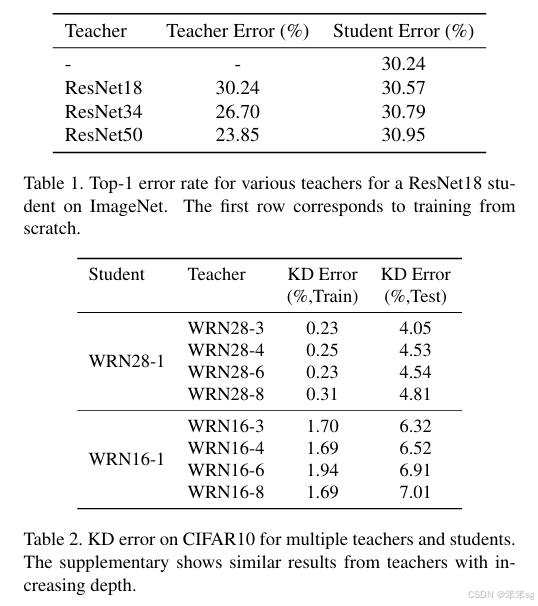
上面表中的结果告诉我们:教师模型并非越大越好,要考虑到学生模型的承载能力。这就好比一个专教尖子班的金牌讲师,你现在让他去带一个差生(学生模型),金牌讲师如果按照教尖子班的模式去教这个学生,由于他平时习惯了高端教学方法,这个差生肯定跟不上他的节奏,效果可能还不如一个普通老师教的好。
模型容量不匹配,导致student模型不能够mimic teacher,反而带偏了主要的loss;
KD losses 和accuracy不匹配,导致student虽然可以follow teacher, 但是并不能吸收teacher知识。
17.3 Is a pretrained teacher important?
论文链接:Deep Mutual Learning
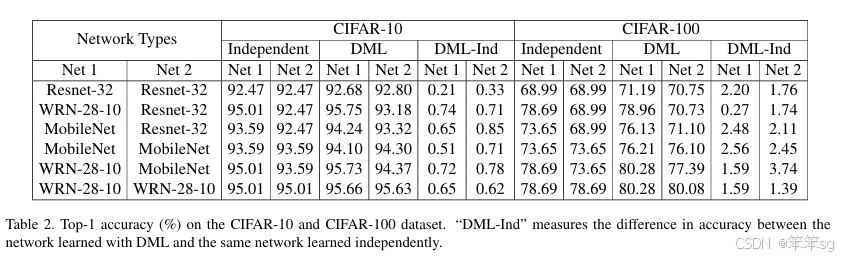
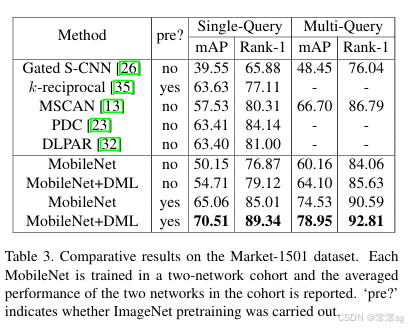
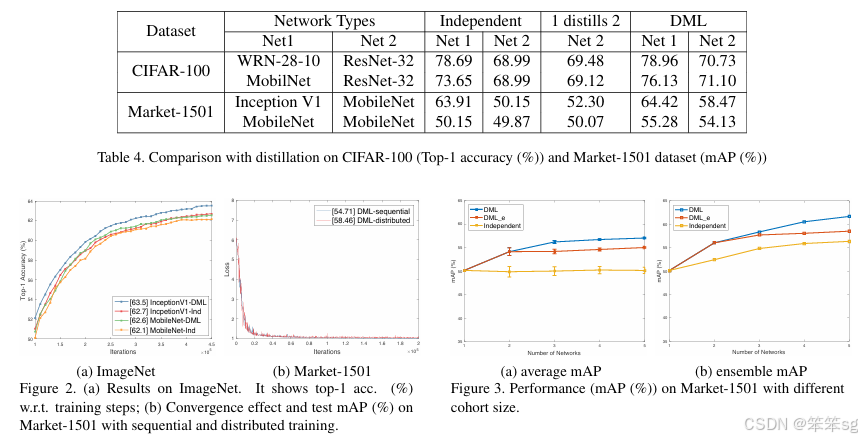
这篇paper其实两方面辩证来看:
1.假设没有一个pretrained的teacher模型,那KD在不同的peer students中间学习,也是可以获得不错的提高,所以pretrained的teacher其实没有那么重要,就拿bert这种大模型来说,如果pretrain一次大模型,需要很多数据,机器,时间成本去训练,那我们完全可以换几个小模型去训练,去做蒸馏;
2.如果在有pretrain的teacher前提下,那我们肯定让teacher更好的含有知识,就拿图像分类来说,它在imagnet上pre-train,再去fine tune其他模型,效果很明显。
17.4 Single teacher vs multiple teachers
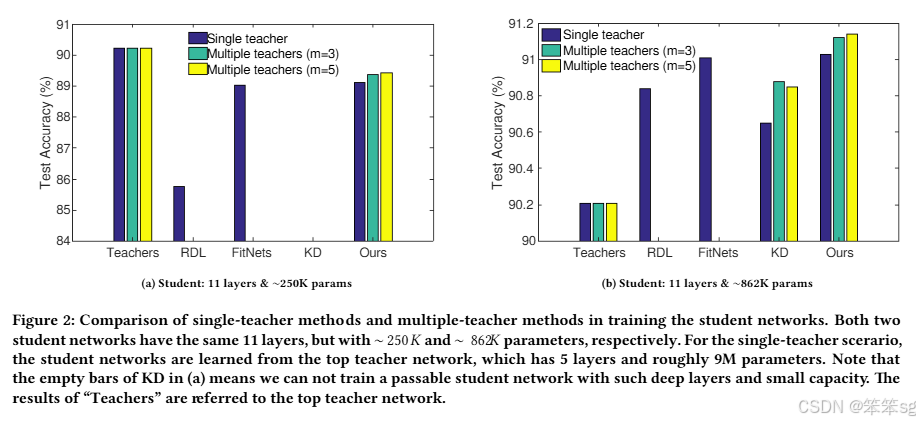
图2:单教师方法和多教师方法在训练学生网络中的比较。两个学生网络均为11层,但参数量分别约为250K和862K。在单教师场景中,学生网络从顶部教师网络学习,教师网络具有5层且约9M的参数。需要注意的是,图(a)中KD方法的空白条表示我们无法用这样深的层数和小容量训练出一个合格的学生网络。“Teachers”的结果是指顶部教师网络的性能。
18 更多资讯
好了,以上介绍了知识蒸馏(KD)较为完整的发展历程。当然,由于涉及KD的论文多达数千篇,我们无法一一列举,且对于近几年的KD文章涉及较少。因此,如果你希望更深入地了解KD的详细发展综述,可以参考以下两篇写得非常详尽的综述文章:
Knowledge Distillation: A Survey
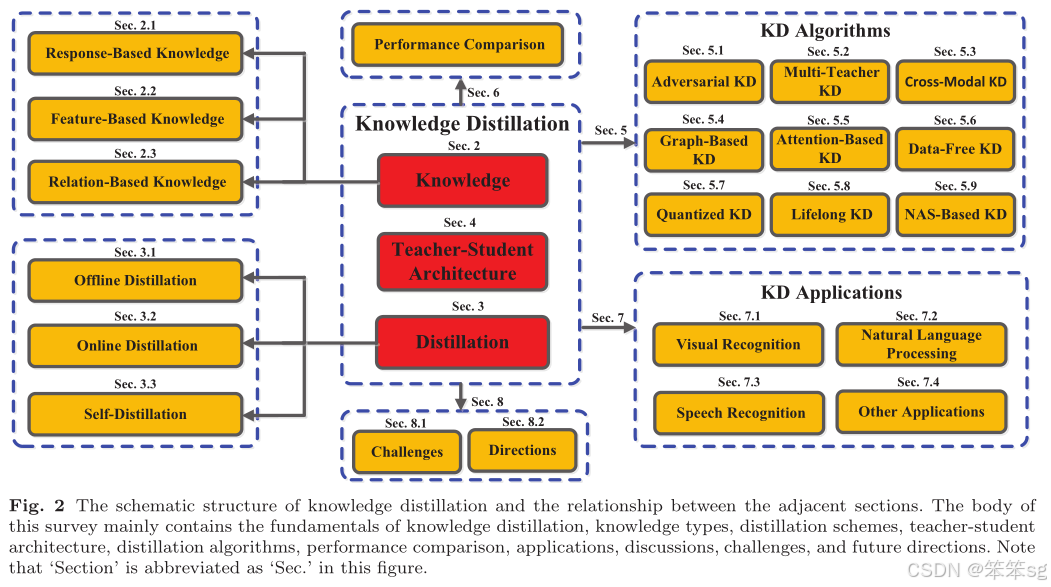
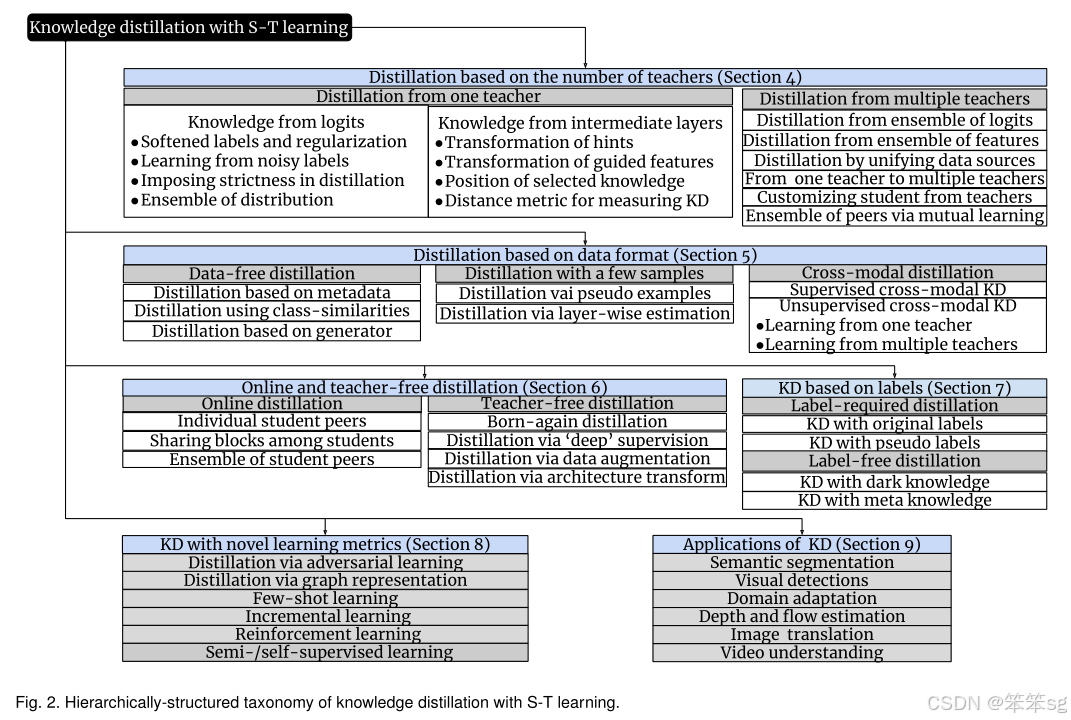
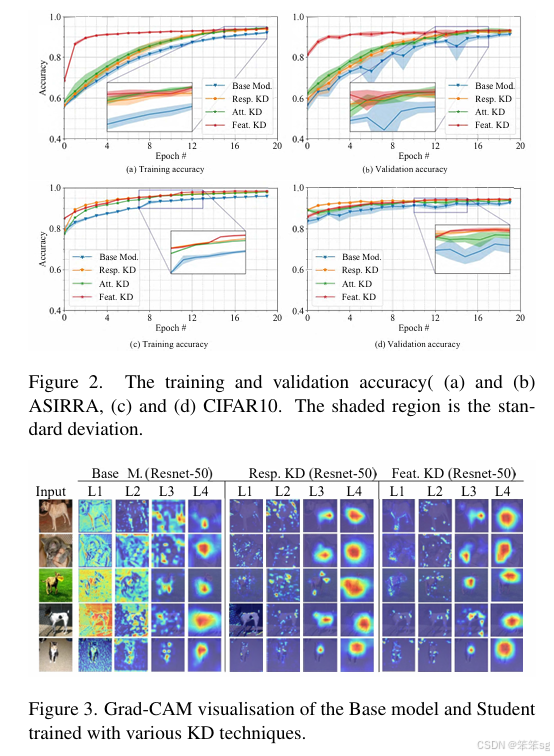
此外,如果你对知识蒸馏的知识迁移过程感兴趣,可以参见下面这篇24年最新的论文:
On Explaining Knowledge Distillation: Measuring and Visualising the Knowledge Transfer Process


















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









