







大语言模型(LLM)基本原理
大语言模型的也是属于机器学习-深度学习模型的一种,为了便于理解,建议看本文之前先看我的上一篇博文AI算法(机器学习)的基本原理
自回归语言模型
目前的大语言模型(Large Language Model,LLM)基本采用自回归语言模型,即给出上文,预测下一个词(Token),并将预测出的Token拼到原先的上文,作为下一次的预测上文,不断迭代式地自回归生成。**
如对于一个词条(koken) 长度为L文本序列
x
1
:
L
x_{1:L}
x1:L ,即用前面的
x
1
:
i
−
1
x_{1:i−1}
x1:i−1个词条预测第
x
i
x_{i}
xi词条
用数学概率表示为:
p
(
x
1
:
L
)
=
p
(
x
1
)
p
(
x
2
∣
x
1
)
p
(
x
3
∣
x
1
,
x
2
)
⋯
p
(
x
L
∣
x
1
:
L
−
1
)
=
∏
i
=
1
L
p
(
x
i
∣
x
1
:
i
−
1
)
.
p(x_{1:L}) = p(x_1) p(x_2 \mid x_1) p(x_3 \mid x_1, x_2) \cdots p(x_L \mid x_{1:L-1}) = \prod_{i=1}^L p(x_i \mid x_{1:i-1}).
p(x1:L)=p(x1)p(x2∣x1)p(x3∣x1,x2)⋯p(xL∣x1:L−1)=i=1∏Lp(xi∣x1:i−1).
如文本:
p
(
t
h
e
,
m
o
u
s
e
,
a
t
e
,
t
h
e
,
c
h
e
e
s
e
)
=
p
(
t
h
e
)
p
(
m
o
u
s
e
∣
t
h
e
)
p
(
a
t
e
∣
t
h
e
,
m
o
u
s
e
)
p
(
t
h
e
∣
t
h
e
,
m
o
u
s
e
,
a
t
e
)
p
(
c
h
e
e
s
e
∣
t
h
e
,
m
o
u
s
e
,
a
t
e
,
t
h
e
)
.
\begin{align*} p({the}, {mouse}, {ate}, {the}, {cheese}) = \, & p({the}) \\ & p({mouse} \mid {the}) \\ & p({ate} \mid {the}, {mouse}) \\ & p({the} \mid {the}, {mouse}, {ate}) \\ & p({cheese} \mid {the}, {mouse}, {ate}, {the}). \end{align*}
p(the,mouse,ate,the,cheese)=p(the)p(mouse∣the)p(ate∣the,mouse)p(the∣the,mouse,ate)p(cheese∣the,mouse,ate,the).
在计算每一个词条(token)概率
p
(
x
i
∣
x
1
:
i
−
1
)
p(x_{i}∣x_{1:i−1})
p(xi∣x1:i−1)时,会模拟退火算法,通过一个温度参数T来控制随机性
for
i
=
1
,
…
,
L
:
x
i
∼
p
(
x
i
∣
x
1
:
i
−
1
)
1
/
T
,
\begin{aligned}\text { for } i & =1, \ldots, L: \\x_i & \sim p\left(x_i \mid x_{1: i-1}\right)^{1 / T},\end{aligned}
for ixi=1,…,L:∼p(xi∣x1:i−1)1/T,
模拟退火算法是模拟金属冶炼过程中,退火温度的控制,温度高时,分子热运动加剧,位置越随机;温度逐步降低时,分子逐步趋向稳定状态
计算方式如下:
假设预测下一个词条为cheese,mouse 两个之一,预测原始概率分别为
p
(
cheese
)
=
0.4
p(\text { cheese })=0.4
p( cheese )=0.4,
p
(
mouse
)
=
0.6
p(\text { mouse })=0.6
p( mouse )=0.6,通过参数T来调整原始概率,调整后概率和可能不为1,因此需要归一化:
p
(
cheese
)
=
0.4
,
p
(
mouse
)
=
0.6
p
T
=
2
(
cheese
)
=
(
0.4
)
1
/
2
/
(
(
0.4
)
1
/
2
+
(
0.6
)
1
/
2
)
=
0.45
,
p
T
=
2
(mouse
)
=
(
0.6
)
1
/
2
/
(
(
0.4
)
1
/
2
+
(
0.6
)
1
/
2
)
=
0.55
p
T
=
0.5
(
cheese
)
=
0.31
,
p
T
=
0.5
(mouse
)
=
0.69
p
T
=
0.2
(cheese
)
=
0.12
,
p
T
=
0.2
(mouse)
=
0.88
p
T
=
0
(cheese
)
≈
0
,
p
T
=
0
(mouse
)
≈
1
\begin{array}{cl}p(\text { cheese })=0.4, & p(\text { mouse })=0.6 \\p_{T=2}(\text { cheese })=(0.4)^{1/2} / ((0.4)^{1/2} + (0.6)^{1/2}) = 0.45, & \left.p_{T=2} \text { (mouse }\right)=(0.6)^{1/2} / ((0.4)^{1/2} + (0.6)^{1/2}) = 0.55 \\p_{T=0.5}(\text { cheese })=0.31, & \left.p_{T=0.5} \text { (mouse }\right)=0.69 \\\left.p_{T=0.2} \text { (cheese }\right)=0.12, & p_{T=0.2} \text { (mouse) }=0.88 \\\left.p_{T=0} \text { (cheese }\right)\approx0, & \left.p_{T=0} \text { (mouse }\right)\approx1\end{array}
p( cheese )=0.4,pT=2( cheese )=(0.4)1/2/((0.4)1/2+(0.6)1/2)=0.45,pT=0.5( cheese )=0.31,pT=0.2 (cheese )=0.12,pT=0 (cheese )≈0,p( mouse )=0.6pT=2 (mouse )=(0.6)1/2/((0.4)1/2+(0.6)1/2)=0.55pT=0.5 (mouse )=0.69pT=0.2 (mouse) =0.88pT=0 (mouse )≈1
从上计算过程可知,当T越大时,原始概率之间的差距为逐渐缩小,即随机性变大
- T=0:确定性地在每个位置 i 选择最可能的令牌 x i x_{i} xi,即选择概率最大的那个
- T=1:从纯语言模型“正常(normally)”采样,即使用原始概率
- T=∞:每个词条的概率相近,从整个词汇表上的均匀分布中采样
大语言模型实现结构
大语言模型的实现通常基于transformer的decoder结构

Embedding
简单来说,embedding就是将输入文本转化为向量(数值数组)形式,便于神经网络的计算
Positional Encodeing(位置编码)
经过embedding转换之后,已经可以进行decoder处理了。但是此时的输入由于是整体输入,没有额外增加位置信息。同一个token在不同位置的embedding相同,经过attention计算后的数据也相同,只是位置不一样。但通常认为某个token在一句话的不同位置应该表示出不同的含义,因此需要一个额外的操作引入位置信息,使其结果有所区别。
位置信息可以直接编码为一个向量,并将文本向量与位置向量相加
Muti_Head Self Attention(多头自注意力机制)
在Decoder中,mask-attention是为了解决训练时answer内容中前面的token不能观察到后面token的信息而引入的,在推理时所有输入(提示词)均可以互相看到,并不需要mask-attention。又考虑到训练和推理时模型架构一致会使得效果更好,因此在后面的LLM中,Decoder-block一般只包含self-attention。

Attention机制就是注意力机制,这就和我们人类看图片、看自然语言是一样的,我们人读一句话是有自己的关注点,重点词汇的。而Attention机制就是给这些输入tokens一个权重, 提取句子的核心token。
attention计算过程如下:
-
首先假设输入的embedding是 I = [ a 1 , a 2 , a 3 , a 4 ] I = [a1,a2,a3,a4] I=[a1,a2,a3,a4], 分别乘以三个权重矩阵 W q W^q Wq, W k W^k Wk, W v W^v Wv得到三个矩阵 Q Q Q, K K K, V V V

-
把 K K K 转置之后 K T K^T KT与 Q Q Q相乘得到Attention矩阵 A ∈ R ( N , N ) A ∈ R ( N , N ) A∈R(N,N),代表每一个位置两两之间的attention,这里省略了 d \sqrt d d(通常要除以 d \sqrt d d来缩放)。再将它取 softmax(对数归一化) 操作得到 A ^ ∈ R ( N , N ) \widehat{A} \in R(N,N) A ∈R(N,N)
最后将它乘以 V V V 矩阵得到输出 O ∈ R ( d , N ) O \in R(d,N) O∈R(d,N) 。

这是单头自注意力的计算,多头注意力则基于不同的 Q Q Q, K K K, V V V计算多次并把结果合并 -
Add & Norm(残差和归一化)
残差连接:即在计算结果后加上原始输入序列,以便如果上面注意力计算结果 f f f的梯度消失,梯度仍然可以通过 x 1 : L x_{1:L} x1:L 进行计算:
x 1 : L + f ( x 1 : L ) x_{1:L}+f(x_{1:L}) x1:L+f(x1:L) -
FeedForward(FFN前馈层)
主要包含两个线性层和一个激活函数。
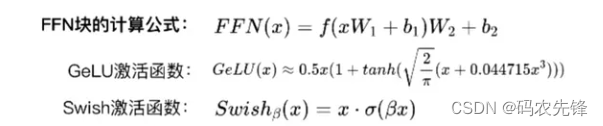
LLM大语言模型网络结构通常就是把 F e e d F o r w a r d ∘ S e l f A t t e n t i o n FeedForward∘SelfAttention FeedForward∘SelfAttention 结构重复迭代上百次来实现
- 输出层
通过Linear线程层连接后,再通过softmax函数得到词表中每个token的概率
大语言模型训练
目标函数
如上面提到的对于一个**词条(koken)**长度为L文本序列
x
1
:
L
x_{1:L}
x1:L ,
用数学概率表示为:
p
(
x
1
:
L
)
=
p
(
x
1
)
p
(
x
2
∣
x
1
)
p
(
x
3
∣
x
1
,
x
2
)
⋯
p
(
x
L
∣
x
1
:
L
−
1
)
=
∏
i
=
1
L
p
(
x
i
∣
x
1
:
i
−
1
)
.
p(x_{1:L}) = p(x_1) p(x_2 \mid x_1) p(x_3 \mid x_1, x_2) \cdots p(x_L \mid x_{1:L-1}) = \prod_{i=1}^L p(x_i \mid x_{1:i-1}).
p(x1:L)=p(x1)p(x2∣x1)p(x3∣x1,x2)⋯p(xL∣x1:L−1)=i=1∏Lp(xi∣x1:i−1).
我们要使这个概率最大化,可以转化为使它的负数最小化(使用梯度下降求解,通常转化为最小化问题),并且使用对数形式(防止数据溢出,并将乘法转为加法,且函数极值点不变)。
设
θ
\theta
θ 是大语言模型的所有参数。设
D
D
D 是由一组序列组成的训练数据。
然后,我们可以遵循最大似然原理,定义以下负对数似然目标函数:
O
(
θ
)
=
∑
x
∈
D
−
log
p
θ
(
x
)
=
∑
x
∈
D
∑
i
=
1
L
−
log
p
θ
(
x
i
∣
x
1
:
i
−
1
)
.
O(\theta) = \sum_{x \in D} - \log p_\theta(x) = \sum_{x \in D} \sum_{i=1}^L -\log p_\theta(x_i \mid x_{1:i-1}).
O(θ)=x∈D∑−logpθ(x)=x∈D∑i=1∑L−logpθ(xi∣x1:i−1).
大语言模型的训练目标是使整个词条的联合概率最大化,即使负对数似然最小化。
模型训练
预训练
大语言模型预训练是通过上文的词来预测下一个词,属于自监督的预训练。
在这个阶段,训练数据主要来自互联网上的原始文本,这些文本质量一般但数量巨大。该阶段主要任务目标是根据上文预测下一个词(token)。
- 序列分割:
将长文本分割为固定长度的上下文窗口(计算复杂度限制,如GPT-3的2048个Token),每个窗口作为一个训练样本。- 动态滑动窗口:每次随机选取文本中的一个位置作为起点,避免模型仅学习固定位置模式。
- 跨文档处理:不同文档间用特殊标记(如<|endoftext|>)分隔,防止模型混淆不同来源的内容。
- 输入格式:
每个样本的输入为[Token_1, Token_2, …, Token_{n-1}],目标输出为[Token_2, Token_3, …, Token_n],即预测当前Token的下一个Token。
在大语言模型的预训练中,还采用了 in-context learning 技术。为了让模型能够理解人类的意图,与人类的思想对齐,会构造类似这样数据:在句子前加上一个任务(task),同时会给出完成该任务的几个示例。例如,向模型输入 “请将中文翻译成英文。你好,Hello,再见,goodbye,销售,”,然后让模型学习下一个输出 “sell”。通过示例的个数又可以分为:
few-show learning: 允许输入数条示例和一则任务说明;
one-shot learning: 只允许输入一条示例和一则任务说明;
zero-shot learning: 不允许输入任何范例,只允许输入一则任务说明。
zero-shot learning 可以表示为:
p ( o u t p u t ∣ i n p u t , t a s k ) p(output∣input,task) p(output∣input,task)
通过引入 in-context learning 技术,使得预训练的大语言模型直接拥有完成特定任务的能力。
监督微调(SFT)
(Supervised Fine-Tuning,监督微调)是指在预训练模型的基础上,通过监督学习(人工标注数据)的方法对模型进行进一步微调,以适应特定任务或数据集。SFT在大语言模型的训练过程中起着重要作用,特别是在提升模型在特定任务上的性能方面。
基于人类反馈的强化学习(RLHF)
RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)是一种结合了强化学习和人类反馈的方法,用于训练和优化大语言模型,使其生成的内容更符合人类期望和偏好。RLHF在训练过程中如下:
- 通过人工评审或用户互动,收集模型输出的反馈;
- 使用收集到的人类反馈训练一个奖励模型(Reward Model),该模型能够根据输入文本和生成输出的质量给予评分,反映人类的偏好和评价;
- 使用强化学习算法(如Proximal Policy Optimization, PPO),在奖励模型的指导下进一步优化语言模型。强化学习通过调整模型参数,使得生成的内容在奖励模型评分中表现更优。
AI反馈强化学习(RLAIF)
RLAIF(Reinforcement Learning with AI Feedback,AI反馈强化学习)是一种结合强化学习和AI生成的反馈方法,用于优化大语言模型。RLAIF利用其他AI系统(如GPT4,而不是人类)提供的反馈来指导模型的行为调整,从而提高生成结果的质量和一致性。
大语言模型扩展
通过上文我们知道,大语言模型的本质是一个通过上文概率预测下一个token的一个模型。通过大量语料的训练,大语言模型拥有很强的自然语言理解和生成的能力。
但是在实际运用中还存在许多缺陷:
知识不足
如将大语言模型用于知识问答、智能客服等场景,大模型对于在训练语料中从未出现的未来知识(晚于训练时间)、或专业领域的深度知识是无法解答的。

解决方案:
- 重新训练/微调模型,加入新的知识(参数庞大,训练成本太高)
- RAG(Retrieval-Augmented Generation)检索增强生成,将知识先存储到知识数据库中,用户问答时基于问题先从知识库中检索相关内容(LLM上下文长度限制,太大的知识无法全部放入提示词中),拼接到提示词中,再让LLM回答。
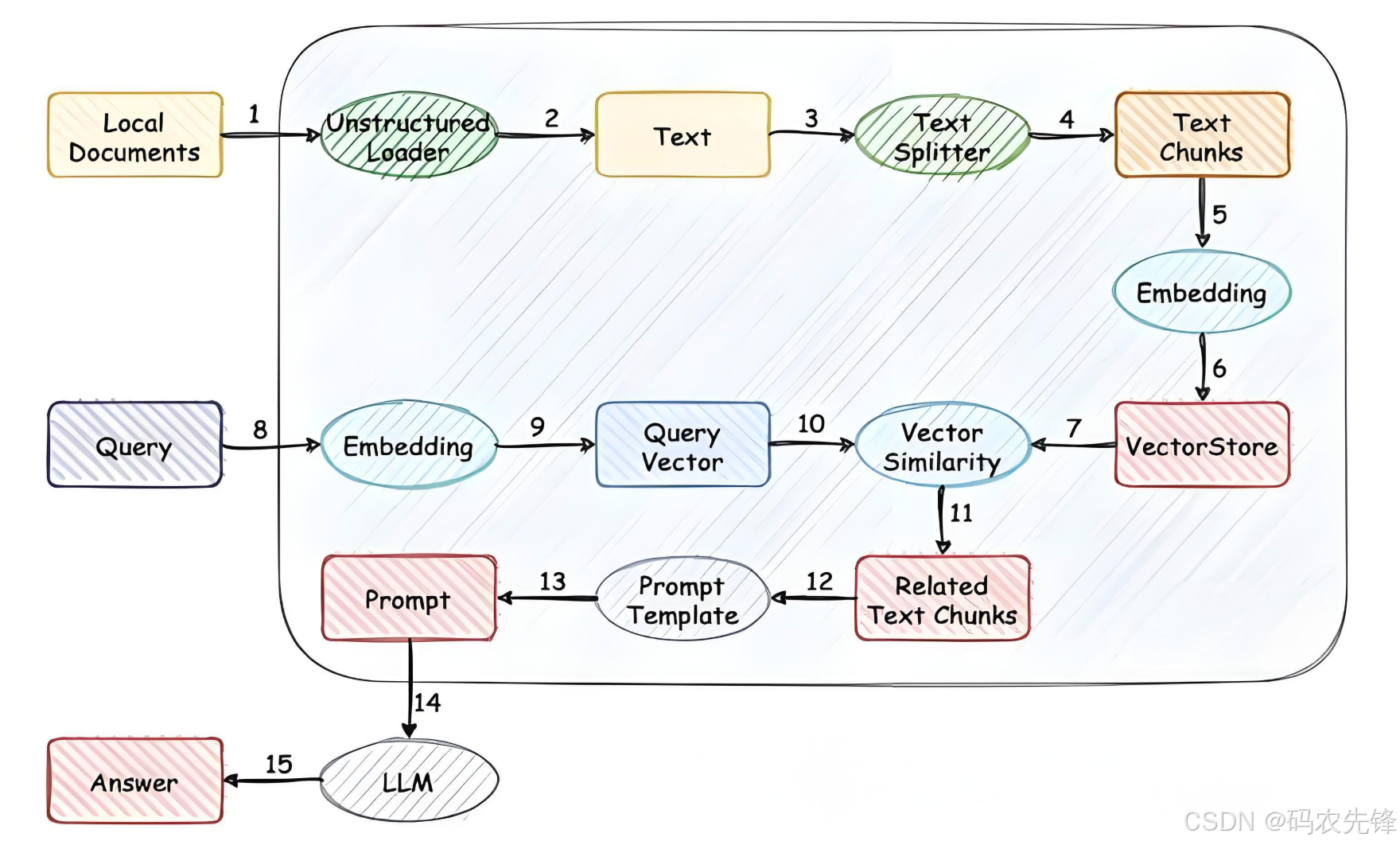
RAG提示词示例:
你的目标是根据用户的问题以及给出的背景信息给出答案。
你需要遵守的规则是:
1. 必须使用中文回答用户提出的问题。
2. 答案的字数控制在300字以内。
3. 不采用背景信息中的错误信息。
4. 要考虑答案和问题的相关性,不做对问题没有帮助的回答。
5. 简明扼要,重点突出,从不过多花哨词藻。
6. 不说模糊的推测。
7. 尽量多的使用数值类信息。
背景信息是:
{background}
开始!
需要回答的问题是: {input}
优化方向:
- 如何在庞大的知识库中高效、准确地召回真正相关的知识,各种检索、召回、排序技术优化。如分词检索、向量检索、知识图谱检索等
- 多模态(如表格、图片、音视频等)知识检索
思维能力
2022 年 Google 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中研究发现:当大模型突破某个规模时,性能显著提升,表现出让人惊艳、意想不到的能力。比如语言理解能力、生成能力、逻辑推理能力等。一般来说,模型在100亿到1000亿参数区间,可能产生能力涌现,其中就包括思维涌现。通过(Chain-of-Thought, CoT)技术就能激活大模型的这种思维能力,其核心是通过提示词(Prompt)引导模型将复杂问题分解为多个逻辑步骤,并使模型在回答时会展示"思考过程",例如:“首先…然后…因此…”,最终得出答案。

思维链提示词示例:
- Zero-Shot-CoT
不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。 - Few-Shot-CoT
在示例中详细描述了“解题步骤”,让模型照猫画虎模仿得到推理能力。
优化方向:
除了在提示词中激活大模型推理能力,也可以在训练阶段通过强化学习锻炼大模型的思维能力。如GPT-o1, DeepSeek-R1
使用工具
大语言模型只具备自然语言生成能力,如果能够实现调用其他业务系统API(Function Call)的能力,才能实现扩展LLM的能力,真正和业务系统相结合,扩展LLM的能力。
ReAct模式(结合知识库、思维链、工具执行结果)提示词示例:
你是一位精通信息分析的ai助手。
你的目标是根据用户的问题以及给出的背景信息给出答案。
你必须优先选择使用提供的工具回答用户提出的问题,若用户没有提供工具可以根据你的通识能力解决问题。
你在回答时问题必须使用中文回答。
你必须从多个角度、维度分析用户的问题,帮助用户获取最全面的信息,需要根据背景和问题,决定搜索哪些信息可以回答问题。
请注意: 你在给出最终答案时需要从多角度给出更详细的原因,而不是一个简单的结论。
您可以使用以下工具:
{tools}
你的回答必须严格使用以下格式:
Question: 您必须回答的问题
Thought: 你应该经常想想该怎么做
Action: 要采取的行动应该是 one of [{tool_names}]
Action Input: 行动的输入
Observation: 行动的结果
... (Thought/Action/Action Input/Observation 的过程可以重复 N 次)
Thought: 我现在知道最终答案了
Final Answer: 原输入问题的最终答案
背景信息是:
{background}
开始!
Question: {input}
tools为所有可调用工具的描述信息信息,tool_names为工具名称集合。ReAct模式通过多轮对话的方法,让LLM优先判断调用哪个工具,并根据上下文提取调用参数。工程侧根据大模型Action输出的工具名称和Action Input(工具调用的参数),调用工具执行获取结果,输入到Observation中,继续让大模型回答,最终获得结果。
优化方向:
- 优化工具描述提示词,是LLM更准确判断该调用的工具
- 当工具集较庞大时,通过工具检索或Agent拆分,使LLM更准确地使用工具
- 工程侧通过提示词和编码兜底等方式来规范、完善大模型输出格式,满足工具调用需求
- 模型推理过程中改造优化,规范大模型输出。
- 通过更多任务分解、流程编排模式,优化LLM执行复杂任务效果
会话记忆
大语言模型本身并不具备记忆能力,只能一问一答的形式输出。为了使LLM的回答更准确、连贯,能够记住多轮对话历史,也是通过工程侧记录会话历史,并在会话时通过提示词传入,使得LLM获得会话记忆能力。
会话记忆提示词示例:
你是一位精通信息分析的ai助手。
你的目标是根据用户的问题以及给出的背景信息给出答案。
你需要遵守的规则是:
1. 必须使用中文回答用户提出的问题。
2. 答案的字数控制在300字以内。
3. 不采用背景信息中的错误信息。
4. 要考虑答案和问题的相关性,不做对问题没有帮助的回答。
5. 简明扼要,重点突出,从不过多花哨词藻。
6. 不说模糊的推测。
7. 尽量多的使用数值类信息。
之前的对话:
{chat_history}
开始!
需要回答的问题是: {input}
优化方向:
- 记忆如何清除、多智能体之间如何记忆共享、传递
- 因LLM上下文长度限制,大量会话记忆如何压缩,摘要
AI Agent
LLM有了上面提到的能力,就形成了基于大语言模型的AI Agent (LLM-based Agent), 即采用 LLM 作为这些Agent的大脑或控制器的主要组成部分,并通过多模态感知和工具利用等策略来扩展其感知和行动空间, 并通过思维链(CoT)和问题分解等技术,使这些基于 LLM 的Agent具备推理和规划,解决复杂业务问题的能力。

通用人工智能(AGI)
AGI(Artificial General Intelligence,通用人工智能)指的是一种拥有与人类相当智能水平的人工智能系统,能够在各种不同的任务和环境中进行智能决策和问题解决。与目前大多数人工智能系统只能在特定领域下执行特定任务不同,AGI具备广泛的认知能力和理解力,能够理解和学习不同领域的知识,并自主地应用于不同情景中。
人工智能层次关系通常如下:

OpenAI全球事务副总裁Anna Makanju在接受采访时表示,OpenAI的使命是构建可以做到“当前人类认知水平”任务的通用智能。
总之,目前对AGI的研究还任重而道远。
学习资料
大模型理论基础
为什么现在的LLM都是Decoder-only的架构
C/CUDA实现和训练大语言模型GPT2
Java实现和训练大语言模型GPT2
详解AI Agent系列
阿里开源AI Agent框架


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











