






标题:图表上的深度学习Deep Learning on Graphs: A Survey
作者: Ziwei Zhang , Peng Cui , and Wenwu Zhu , Fellow, IEEE
文章目录
Abstract
深度学习已在许多领域都被证明取得了成功,比如声学、图像到自然语言处理。然而,由于图的独特特性,将深度学习应用到它身上中并非易事。因此,本文作者调查分析了大量致力于将深度学习方法应用于图,从而使得图分析技术的有益进展的研究工作。
本文根据现有方法的模型体系结构和训练策略将其分为五类:图递归神经网络、图卷积网络、图自编码器、图强化学习和图对抗方法。此外,文章还分析了不同方法的差异和组成。最后,文章简述了他们的实际应用并讨论了他们未来的发展方向。
Introduction
-
传统的深度学习架构应用到图中所存在一些挑战:
1.不规则的图形结构:这样的结构使得我们很难将一些基本的数学操作推广到图形中;
2.图的异质性和多样性:图本身可能很复杂,包含不同的类型和属性。此外,图的任务也有很大的不同,从以节点为中心的问题,到以图为中心的问题。而上述的这些不同的类型、属性和任务都需要不同的模型体系结构来处理特定的问题;
3.大规模的图:在如今的大数据时代,真实的图可以很容易地拥有数百万甚至数十亿个节点和边。因此,如何设计可伸缩模型,最好是对图大小具有线性时间复杂度的模型,是一个关键问题;
4.合并跨学科的知识:图表通常与其他学科相联系。这种性质提供了机遇和挑战:可以利用领域知识来解决特定的问题,但集成领域知识会使模型设计复杂化; -
图的深度学习的五大分类以及区别:
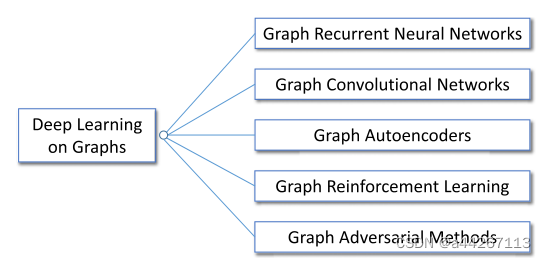
- RNN通过在节点级或图级建模状态来捕获图的递归和顺序模式;
- GCNs定义了不规则图结构上的卷积和读出操作,以捕获常见的局部和全局结构模式;
- GAEs采用低秩图(很多行(列)是线性相关的)结构,并且采用无监督方法进行节点表征学习;
- RL定义了基于图的操作和奖励,以在遵循约束条件的情况下获得图任务的反馈;
- 对抗方法采用对抗训练技术来增强基于图的模型的泛化能力,并通过对抗攻击来检验模型的坚固性。

本文的工作不同于以前的工作,本文的作者系统和全面地审查不同的在图上在图上的深度学习架构,而不是专注于一个特定的分支。前人的工作都没有考虑图强化学习或图对抗方法,这些正是在本文中涉及的。
要注意网络嵌入,本文关注的是不同的深度学习模型是如何应用于图的,而网络嵌入可以被认为是一个使用了其中一些模型的具体应用示例
网络嵌入是网络表征学习的一种方法,旨在用低维、稠密的向量空间表示高维、稀疏的向量空间,所学习到的特征可以用于分类、回归、聚类等机器学习任务
- 图上的深度模型的学习任务:
- 以节点为中心的任务:这些任务与图中的单个节点相关联,比如节点分类、链路预测和节点推荐;
- 以图为中心的任务:这些任务与整个图关联,比如图分类、估计各种图属性和生成图;
注意:有时候可以通过将以节点为中心的问题转化为以图为中心的网络,就可以将以节点为中心的问题研究为以图为中心的问题
综述
一、图递归神经网络 Graph RNN
- 含义:是序列数据建模的事实标准。它可以大致分为两类:节点级RNN和图级RNN;
- 主要的区别在于模式是位于节点级并由节点状态建模,还是位于图级并由公共图状态建模。下图总结了他俩的主要特点:

1.1 节点级RNNs Node-Level RNNs
- 原理:为了编码图结构信息,每个节点vi都用一个低维状态向量si表示;
- 方法:使用Jacobi方法将状态向量迭代求解到稳定点后,使用Almeida-Pineda算法执行一个梯度下降步骤,以最小化任务特定的目标函数,例如,回归任务的预测值与地面真值之间的平方损失;然后,重复这个过程,直到收敛;
- 展望:回顾过去,GNN(神经网络图)结合了一些早期用于处理图数据的方法,如递归神经网络和马尔可夫链。展望未来,GNN的基本思想有着深刻的启发:正如后面将展示的,许多最先进的GCN实际上都有一个基础公式,遵循相同的框架在直接节点邻里之间交换信息;
- 缺点:为了确保状态向量有唯一解,F(·)[一个待学习的参数函数]必须是一个 收缩图;
- “收缩图”要求任何两点之间的距离只能在F操作操作之后,而这严重限制了建模能力
- 由于在梯度下降步骤之间需要多次迭代才能达到稳定状态,导致GNN的计算成本很高
因此,GNN并没有成为一般研究的重点。
- 提升:
- **门控图序列神经网络(GGS-NNs)**是对gnn的一个显著改进。作者用GRU代替了状态向量中的递归定义,从而消除了“收缩图”的要求,并支持现代优化技术;
- SSE采用了和上面差不多的优化方法,但是它在计算时没有使用GRU,而是采用了随机不动点梯度下降法来加速训练过程。
1.2 图级RNN Graph-Level RNNs
- 不同:在图级RNN中,不是对每个节点应用一个RNN来学习节点状态,而是对整个图应用一个RNN来对图状态进行编码,常常应用于图生成问题,这里采用了两个RNN,一个用于 生成新节点 ,另一个用于 自回归生成新添加节点的边 ;
- 动态图神经网络(DGNN):使用 时间感知的LSTM 来学习节点表示。当建立一条新边时,DGNN利用LSTM更新两个相互作用的节点及其相邻节点的表示,即考虑到一步传播效应;
- 此外,图RNN还可以与其他结构相结合,从而提升其使用体验;
二、图卷积网络(GCNs) GRAPH CONVOLUTIONAL NETWORKS
现代GCNs通过 设计的卷积 和 读出函数 来学习常见的图的局部和全局结构模式。因为大多数GCNs可以通过反向传播来训练特定任务的损失。
2.1 卷积操作 Convolution Operations
- 图卷积可以分为两组:
- 光谱卷积spectral convolutions:通过图傅里叶变换或其扩展将 节点表示转换到光谱域 进行卷积;
- 空间卷积spatial convolutions:通过 考虑节点邻域 来进行卷积;
2.1.1 光谱方法 Spectral Methods
由于图缺少网格结构,所以CNNs中最常用的卷积运算无法用在图上。而Bruna等人首先利用图拉普拉斯矩阵L从 谱域引入了对图数据的卷积 ,它在信号处理中起着类似于傅里叶基的作用。图的卷积运算如下:
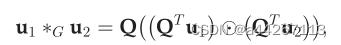
其中u1,u2∈RN是定义在节点上的两个信号,Q是L的特征向量。
而信号u可以通过下面的方程得到:
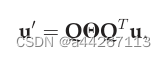
其中u`是输出信号,而θ = θ(∧)∈RN×N为可学习滤波器的对角矩阵,∧为L的特征值
卷积层是通过对不同的输入输出信号对使用不同的滤波器来定义的,定义如下:
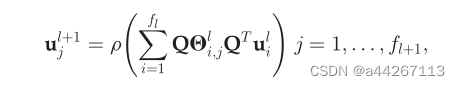
其中l表示层,ulj∈RN为第l层节点的第j个隐藏表示(即信号)
但是这个方法中参数的学习量在实际应用中较难实现,以及每个节点可能受到所有其他节点的影响。所以采用了平滑滤波器:
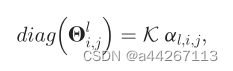
其中K为固定的插值核,al,i,j是学习的插值系数。
- 未解决的问题:
- 首先,因为每次计算都需要拉普拉斯矩阵的完整特征向量,每次向前和向后传递的时间复杂度至少是O(N2),更不用说计算特征分解所需的OðN3Þ复杂度了,这意味着这种方法对大规模图是不可伸缩的(效率低下);
- 其次,由于滤波器依赖于图的特征基Q,但是Q不能在不同大小和结构的多个图之间共享。
- 解决方法:
- 多项式滤波器:由于只需要计算一个稀疏矩阵L和一些向量的矩阵乘法,这让我们 只用计算一个稀疏矩阵L和一些向量的矩阵乘法 ,从而使得问题得到了简化。同时,它还将光谱图卷积与空间结构连接起来。具体地说,当谱卷积函数是多项式或一阶时,谱图卷积等价于空间卷积;
- 一阶邻居的空间方法(NFPs方法):因为参数可以在不同的图中共享,并且与图的大小无关,所以Neural FPs可以处理任意大小的多个图;
- 图标记过程:分配一个唯一的节点顺序,然后使用这种预定义的顺序将节点邻居排成一行。这种方法使得 不同图中的节点都有一个固定大小和顺序 的接受域。缺点是卷积严重依赖于图标注过程,这是一个没有学习的预处理步骤;
- 框架:从概念上讲,mpnn是一个框架,每个节点根据自己的状态发送消息,并根据从相邻节点接收到的消息更新自己的状态 。此外,这个框架的作者还提出增加一个连接到所有节点的“主”节点来加速长距离的消息传递,他们将隐藏表示分成不同的“塔”来提高泛化能力;
2.2 读取操作 Readout Operations
- 定义:利用图卷积运算,可以学习到有用的节点特征来解决许多以节点为中心的任务。但是,为了处理以图为中心的任务,需要聚合节点信息以形成图级表示;
但是由于图形缺乏网格结构,一些现有的读取方法不能直接使用。
-
命令不变性 Order Invariance:操作应该与节点的顺序无关,也就是说,如果我们在两个节点集之间使用双目标函数改变节点和边的索引,整个图的表示应该不会改变;
-
模糊直方图:基本思想是构造几个 “直方图容器” ,然后计算最后一层L中节点vi在这些容器中的隶属度,即以节点表示为样本,与一些预定义的模板匹配,最后返回最终直方图的拼接——>这样可以区分在和/平均值/最大值相同的情况下分布不同的节点;
-
与图卷积联合训练的可微层次聚类算法:由于大多数的分层聚类方法都不是端到端方式训练,所以就有了这个算法。它在每一层使用隐藏表示学习软聚类分配矩阵,并将学习得到的矩阵进行粗化来实现单个节点代表整个图。
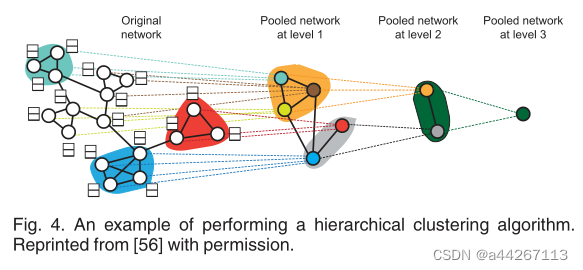
-
总之,平均或求和等统计 是最简单的读取操作,而 与图卷积联合训练的层次聚类算法 更高级,但也更复杂。
2.3 提升方法
已经引入了许多技术来进一步改进GCNs。注意,其中一些方法是通用的,也可以应用于图上的其他深度学习模型:
- 注意机制 Attention Mechanism: 在前面提到的GCN中,节点邻域以相等或预定义的权值聚合。然而,邻居的影响可能会有很大的差异;因此,它们应该在训练中学习,而不是预先确定。因此,受注意机制的启发,**图注意网络(GAT)**通过修改中的卷积运算,将注意机制引入GCNs中,如下所示:
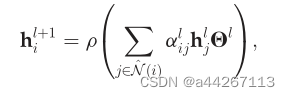 ?
?
其中αlij是为节点vi对第l层节点vj的关注:
- 剩余和跳跃连接Residual and Jumping Connections: 许多研究发现,现有的GCNs最适合的深度往往非常有限,如2或3层。为了解决这个问题,可以在GCNs中加入类似ResNet的剩余连接:
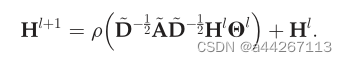
实验结果表明,增加这种残余连接可以增加网络的深度,这与ResNet的结果类似; - 边缘特征Edge Features: 对于边缘类型等具有离散值的简单边缘特征,一个简单的方法是针对不同的边缘类型训练不同的参数并聚合结果,许多传统方法(如,CLN,ECC以及R-GCNs等)只适用于有限数量的离散边缘特征:
- DCNN提出了另一种方法,将每条边转换成与该边的头尾节点相连的节点。经过这种转换后,边缘特征可以被视为节点特征;
- Kearnes等人提出了一种使用“编织模块”的架构:他们学习了节点和边的表示,并在每个编织模块中使用4种不同的函数交换信息:节点到节点(NN)、节点到边缘(NE)、边缘到边缘(EE)和边缘到节点(EN):
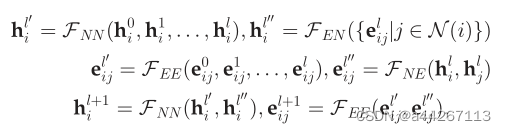
其中elij是边(vi,vj)在第l层的表征;
F(·)则是可学习的函数,其下标表示消息传递方向;
- 抽样方法: 由于许多实图遵循幂律分布(即少数节点具有非常大的度),邻居的数量可以非常快地扩展。因此,我们提出了两种抽样方法:邻域抽样和分层抽样:
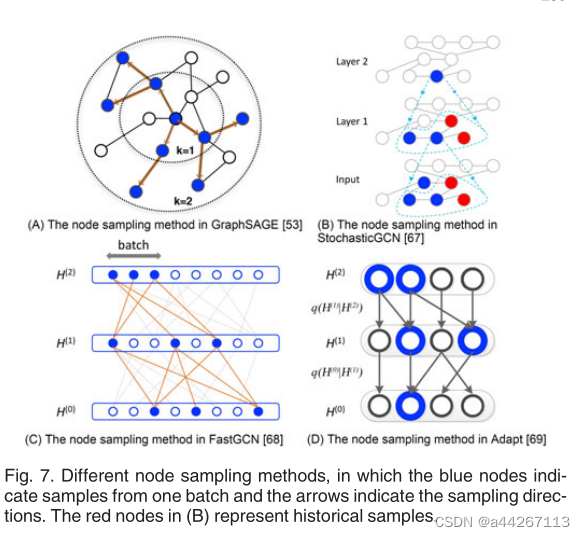
邻域抽样是在计算过程中对每个节点进行抽样;
而分层抽样则是将每个卷积层(即逐层采样)的节点解释为i.i.d.样本,将图卷积解释为概率测度下的积分变换。而这可以减少差异,从而获取更好的性能。
三、图自动编码机(GAEs) GRAPH AUTOENCODERS
自动编码机(AE)及其变体在无监督学习任务中得到了广泛的应用,它适用于图的学习节点表示。
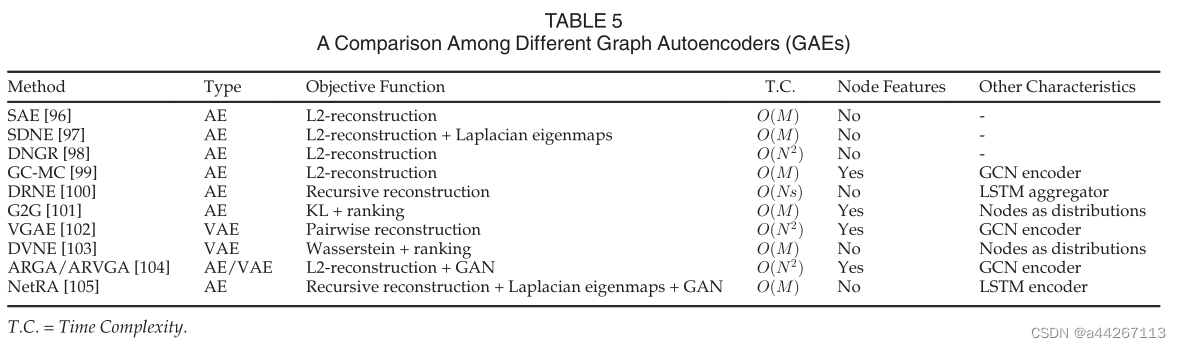
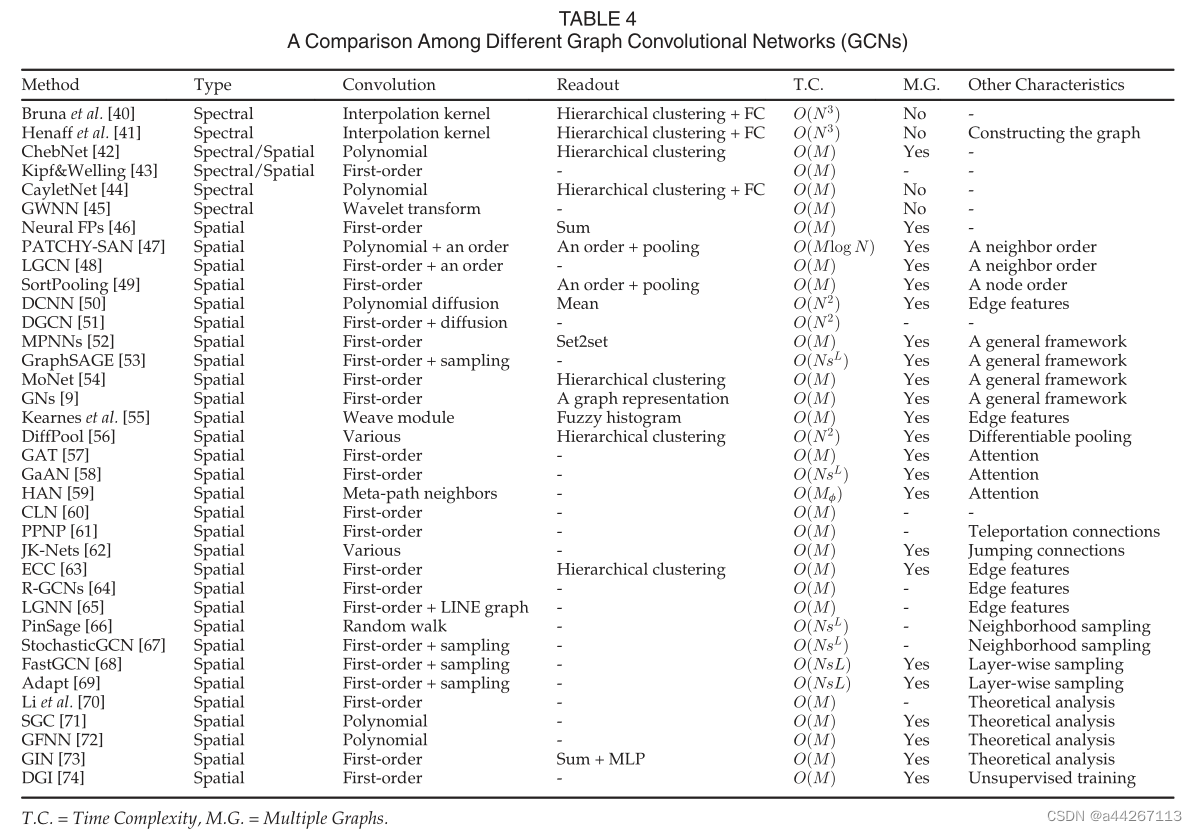
不同图形自动编码器(GAEs)的比较
3.1 自动编码器 Autoencoders
- 基本观点:将邻接矩阵或其变体作为节点的原始特性,AEs可以作为一种降维技术来学习低维节点表示
- 基本方法:SAE(稀疏自动编码机)压缩了转移矩阵的信息并将其转换为低维向量,然后根据该向量重构原始特征,另外还加入了稀疏性正则化项,然后再应用k均值聚类算法来进行节点聚类任务。但是其有效性仍未得到解释;
- 结构深度网络嵌入(SDNE):这个东西解释了上面的有效性:重构损失实际上对应于节点之间的二阶接近度,即两个节点如果有相似的邻域,则共享相似的网格表示——即协同过滤或三角闭包;
3.2 变分编码器(VAEs) Variational Autoencoders
- 变分自动编码器是另一种将降维与生成模型相结合的深度学习方法;
- 好处:容忍噪音和学习平滑表示;
- 缺点:由于这种方法需要重构整个图,所以其时间复杂度为O(N2);
- 首先将VAE引入到图形数据中,其中的解码器是一个简单的线性乘积;然后通过 最小化变分下界 来学习模型参数;
四、图强化学习GRL GRAPH REINFORCEMENT LEARNING
- RL擅长从反馈中学习,尤其是在处理不可微目标和约束时;

图强化学习的主要特点
- GCNP利用 RL 生成目标定向分子图,同时考虑非微分目标和约束。它将图的生成建模为 添加节点和边的马尔可夫决策过程 ,将生成模型视为 运行在图生成环境中的RL代理 ;
- MolGAN采用了类似的思路,使用 RL 生成分子图。不过它建议直接生成完整的图,而不是通过一系列操作生成图;这种方法对小分子特别有效;
- GTPN则是采用 RL 来预测化学反应产物。智能体在分子图中 选择节点对,并 预测它们新的结合类型 ,并根据预测是否正确立即和最后给予奖励;
- GAM利用 随机漫步 将 RL 应用于图分类,相关人员将随机游走的生成建模为部分可观察的马尔可夫决策过程 (POMDP)。代理执行了两个动作:首先,它预测 图的标签 ;然后,它在随机游走中选择下一个节点。奖励仅由代理是否正确分类图来确定;
- DeepPath采用 RL 进行知识图(KG)推理,它的任务是寻径,即在两个目标节点之间找到信息最丰富的路径;
- MINERVA也采用 RL 进行知识图(KG)推理,它的任务是问答任务,即给定一个问题节点和一个关系,找到正确的答案节点;
五、图对抗的方式GAMs GRAPH ADVERSARIAL METHODS

5.1 对抗训练 Adversarial Training
- GAN(一种生成模型,试图通过学习让模型尽可能生成逼真的输入分布):
基本思想:建立两个连接的模型:
(1)鉴别器discriminator:通过生成假数据来“欺骗”鉴别器;
(2)生成器generator:区分样本是来自真实数据还是由生成器生成的;
对抗性训练在生成模型中被证明是 有效的 ,并能增强判别模型的泛化能力
- GraphGAN提出使用 GAN 对图嵌入方法进行增强——鉴别器实际上有两个目标: 原始图中的节点 对具有较大的相似性,而 生成器生成的节点对 具有较小的相似性;
- 对抗性网络嵌入(ANE) 也采用了一种 对抗性训练方案 来改进网络嵌入方法。它将GAN作为现有网络嵌入方法的附加正则化项,将 先验分布作为真实数据 ,并将嵌入向量作为生成的样本 ;
- GraphSGAN使用 GAN增强图 上的半监督学习,作者详细描述了损耗项,以确保发生器在平衡的密度间隙中产生样品以减弱现有模型在不同簇间的传播效应;
- NetGAN采用 GAN 进行图形生成任务。作者将图生成视为学习有偏随机游动分布的任务,并采用 GAN框架 使用LSTM生成和区分随机游动;
5.2 对抗攻击 Adversarial Attacks
- 基本思想:通过在数据中添加小的扰动来 故意“愚弄”目标方法 。研究对抗性攻击可以加深我们对现有模型的理解,并激发出更健壮的架构;
- Nettack首先提出了通过修改图结构和节点属性的攻击节点分类模型,如GCNs。简单地说,优化的目的是在图结构和节点属性中找到导致目标节点被错误分类的最佳合法更改。
约束条件:攻击应该是“不可察觉的”,也就是说,它应该只做很小的改变。具体地说,作者提出了保留节点度分布和特征共现等数据特征; - Dai等人研究了目标函数类似于上面那个的图的对抗攻击。然而,他们关注的是只改变图结构的情况。他们没有假设攻击者拥有所有信息,而是考虑了几种不同数量的可用信息的设置。不过实验结果表明,该攻击方法对节点分类任务和图分类任务均有效;
但是上述两种攻击都是有针对性的,即造成某些目标节点的误分类
- Zugner和Gunnemann首先研究了非目标攻击,其 目的 是降低模型的整体性能。他们将 图结构 视为需要优化的超参数,在优化过程中采用元梯度,并使用几种技术来逼近元梯度。图上的深度学习构成了关系数据建模的关键组成部分,它是走向拥有更好的机器学习和人工智能技术的未来的重要一步
总结
从上述内容里我们不难看出,虽然图的深度学习比起其他的学习来说比较复杂,但是其实际应用价值和应用领域也更加宽广。这是一个好机遇,同时也是一个巨大的挑战。
图上的深度学习构成了关系数据建模的关键组成部分,它是走向拥有更好的机器学习和人工智能技术的未来的重要一步
未来展望
应用
- 除了标准的图推理任务,如节点或图分类,基于图的深度学习方法也被应用于广泛的学科,包括建模社会影响,化学和生物学,物理,疾病和药物预测,基因表达,自然语言处理(NLP),计算机视觉,交通预测,程序归纳,解决基于图的NP问题,以及多智能体AI系统;
- 首先,在构建图或选择架构时,将领域知识纳入模型是很重要的;其次,基于图的模型通常可以构建在其他架构之上,而不是作为独立的模型;因此,关键的挑战是如何集成不同的模型;
未来方向
- 未经研究的图结构的新模型:由于图数据的结构极其多样,现有的方法并不能适用于所有的图数据;
- 现有模型的组合性:除了设计新的构建模块,如何系统地组合这些架构是一个有趣的未来方向。在这个过程中,如何有原则地吸收跨学科的知识,而不是个别地吸收,也是一个有待解决的问题;
- 动态图:许多真实的图在本质上是动态的:它们的节点、边和特征可以随着时间的推移而变化。但是如何对动态图的演化特征建模,并支持对模型参数的增量更新,在很大程度上仍未解决;
- 可解释性和健壮性:因为图通常与其他风险敏感的场景相关,在决策问题中,解释深度学习模型结果的能力是至关重要的。然而,基于图的深度学习的可解释性比其他黑箱模型更具挑战性,因为图节点和边通常是高度互联的;















 7305
7305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









