







增量学习综述
0. 摘要
作者从数据变化的角度,将增量学习算法分成三种,即,样本增量学习(Sample Incremental Learning)、类别增量学习(Class Incremental Learning)和特征增量学习(Feature Incremental Learning)。最后,作者对增量学习的研究重点和难点进行了展望。
1. 引言
数据分布变化包含样本变化和类别变化。
1. 样本变化是指样例在特征同构空间下的特征值的变化,以及样本在每一类中所占比例可能发生的变化。
2. 类别变化是指新类别的出现。
3. 特征变化是指训练数据和测试数据的特征空间不一致。
2. 背景
传统实际应用场景下,机器学习过程是渐进的:
1)标注数据,训练一个模型,用模型预测或分类新数据
2)数据变化,新数据和旧数据合并,重新训练
计算机技术和应用的快速发展,各行业积累了大量数据,呈几何倍数增长。
数据分析和数据处理的新问题:
a.标注数据代价高
b.数据集过大,训练时间过长,导致时间消耗和用户体验差
c.传统方式重新训练数据集,程序处在封闭状态,不适应在线应用
d.一般的机器学习分类方法,不能识别和更新新类,不能满足实际需求。
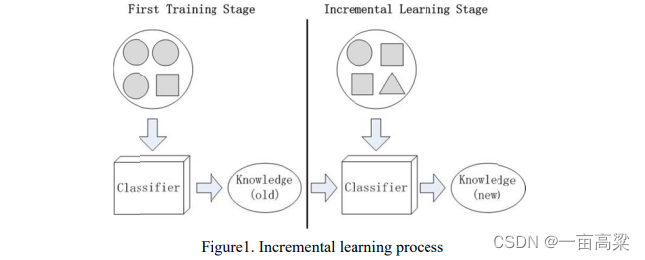
如图1所示:增量学习有以下四个特点:
- 分类器能够从新数据中学习新知识。如图1所示,分类器能够学到圆圈很方块的比例的变化。
- 学习和训练的数据只是新数据。不需要重复训练之前的训练数据。
- 获取新知识的同时,分类器能够整合旧知识。
- 分类器能够适应,识别和更新新的类别。如图1所示,增量学习阶段,分类器学习到了三角形。增量学习能够识别三角形,并且将三角形扩展到之前的类别中。
在1,2,3上面的工作比较多,但是4上面的工作还处于早期阶段。
增量学习可以分为3类:
6. 样本增量学习,Sample Incremental Learning, SIL
问题:由于新数据的各种原因,样本的特征值可能会改变,每个类别的比例也会改变。这些都会影响分类的准确率。
任务:因此,需要确保在现有知识的情况下,通过新样本的增量学习来提取新知识,融合新旧知识以提高分类的准确性。
7. 类别增量学习,Class Incremental Learning, CIL
任务:识别新类,并将其加入现有类别的集合中,提升分类的准确性和智能。
8. 特征增量学习,Feature Incremental Learning, FIL
一些新的属性特征能够将分类提升到一个很大的程度,并提升分类准确率。
任务:在现有特征空间的基础上,加入新的属性特征,构建新的特征空间,提升分类准确率。
3. 支持增量学习的分类算法
一些分类算法的分类原则自然支持增量学习,如朴素贝叶斯,支持向量机,决策树,随机森林,人工神经网络,K-最近邻,模糊粗糙集理论,学习++ NC等。
3.1 朴素贝叶斯
- 基本思想:通过计算先验概率和现有的统计数据获得后验概率。
- 增量学习:后验概率是下一次学习的先验概率。增量学习利用这个准则和[5]中的公式,预测新的知识,然后将新旧知识进行融合。最后,调整先验概率,提升分类能力和准确性。
3.2 支持向量机
- 基本思想:支持向量的概念是从几个支持向量中选择一个超平面来做分类。
- 增量学习:基于旧的支持向量学习新的支持向量。合并新数据的重要支持向量和保留的支持向量,选择一些有决定性的向量来做分类。
3.3 决策树
- 基本思想:将复杂的多分类问题转化成一棵树,从根节点开始,从上至下使用分层形式,通过信息熵来选择最有力的属性将样本分配给孩子节点,直到标注叶子节点。
- 增量学习:决策树是一个树结构,并且具有继承特性。在学习新知识之后,ID4算法[8]通过划分属性来计算信息增益,以确定是继承还是重构子树。但是,有可能会丢弃历史知识。ID5R算法[9]可以通过子树推广的方式有效地继承大部分历史计算。
3.4 随机森林
- 基本思想:它的主要思想是集成思想,它基于决策树的开发,包括多个决策树。 随机森林集成了所有决策树分类投票的结果,指定具有最高投票数的类作为最终输出。
- 增量学习:它不仅具有集成思想,还具有决策树的一些特征。 在增量学习过程中,集成思想可以通过学习新知识和训练决策树然后将其添加到原始随机森林中来实现增量学习。 决策树还赋予它继承和其他特征。
3.5 人工神经网络
- 基本思想:1957年,罗森布拉特提出了一种感知模型,这是第一个基于MP的真正神经网络模型[12]。 该模型利用网络拓扑知识作为理论来模拟人脑的神经系统,并处理从外界输入的复杂信息。 它具有智能化程度高,容错性高,并行性高的特点。
- 增量学习:人工神经网络具有自己学习增量知识的能力,这是一种非线性和自适应的信息处理系统,由大量相互连接的神经元组成。 它不仅可以处理发生各种变化的数据,还可以通过增量学习的方式处理每个数据,从而在一定程度上影响权重的更新,并使自己的电力系统不断变化。 整个动力系统的演化是一个连续迭代的过程。。
4. 增量学习回顾
4.1 样本增量学习
4.2 类别增量学习
4.3 特征增量学习
5. 总结
- 样本增量学习有相当程度的进步。 一方面,可以通过具有一定增量学习特性的机器学习算法来实现样本增量学习。 另一方面,结合聚类和分类技术,可以改进样本的选择和处理。
- 但是,类别和特征增量学习仍然面临很多困难。如何提高他们的性能是下一步的研究重点。
- 此外,如何将简单的样本增量学习,类增量学习和特征增量学习有机地结合起来,以应对复杂的数据变化,这也是值得进一步研究的研究方向。
6. 参考文献
[1] 论文下载















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









