






单目SLAM一般处理流程包括track和map两部分。所谓的track是用来估计相机的位姿。而map部分就是计算pixel的深度,如果相机的位姿有了,就可以通过三角法(triangulation)确定pixel的深度,把这些计算好深度的pixel放到map里就重建出了三维环境。
http://blog.csdn.net/heyijia0327/article/details/50758944
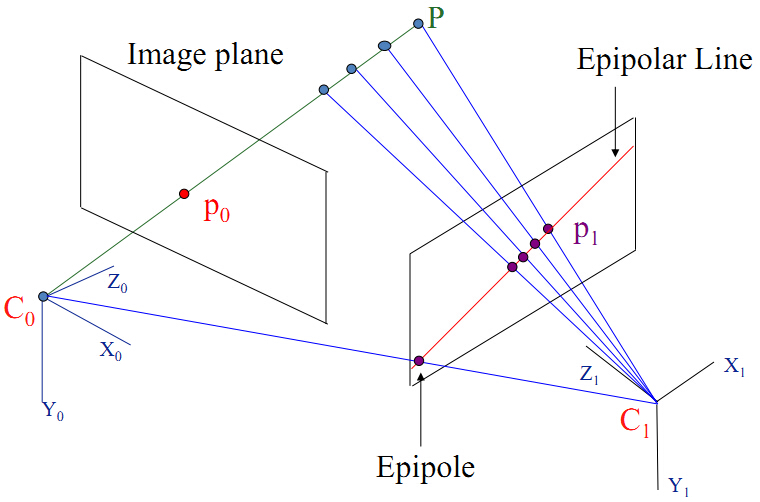
1 对极几何
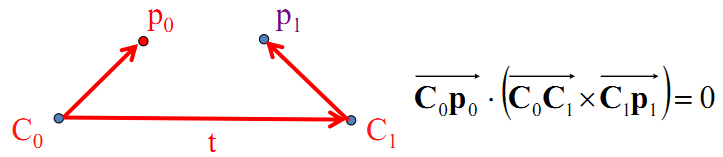
| (高翔7.3讲)在正确匹配的基础上求解相机运动---通过对极几何列式子的基础矩阵F或本征矩阵E或单应矩阵H,分解得R,t +(高翔7.5讲)单目三角测量得深度 极线几何约束是一种点对直线的约束,而不是点与点的约束,尽管如此,极线约束给出了对应点重要的约束条件,它将对应点匹配从整幅图像寻找压缩到在一条直线上寻找对应点。 在立体视觉测量中,立体匹配(对应点的匹配 )是一项关键技术,极线几何在其中起着重要作用。立体视觉系统中,有两个摄像机在不同角度拍摄物理空间中的一实体点,在两副图像上分别成有有两个成像点。立体匹配就是已知其中的一个成像点,在另一副图像上找出该成像点的对应点---极限搜索(高翔13.2讲)。极线几何约束是一种常用的匹配约束技术。 |
![]()
![]()


p1=⎛⎝⎜x1y11⎞⎠⎟c1
这时,由共面得到的向量方程可写成: (1)

补充:一个向量a叉乘一个向量b可以表示为一个反对称矩阵乘以向量b的形式这时由向量a表示的反对称矩阵(skew symmetric matrix)如下:
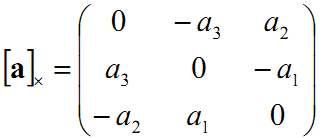
所以式(1)可以写成:
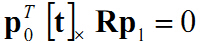

本征矩阵的性质:
一个3x3的矩阵是本征矩阵的充要条件是对它奇异值分解后,它有两个相等的奇异值,并且第三个奇异值为0。
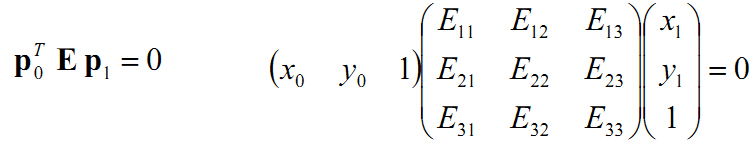
牢记这个性质,它在实际求解本征矩阵时有很重要的意义。
[这个性质的证明见Hartley的著作《Multiple view geometry》的第258页。]
2 计算本征矩阵E、尺度scale的来由
将矩阵相乘的形式拆开得到
上面这个方程左边进行任意缩放都不会影响方程的解:
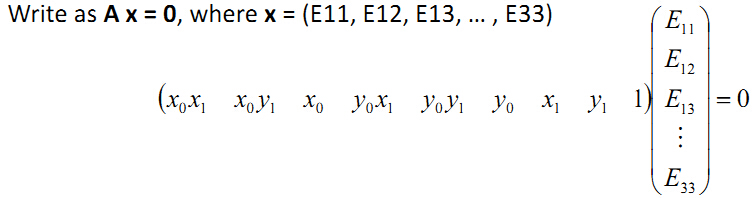

(x0x1x0y1x0y0x1y0y1y0x1y11)E33⎛⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜E11/E33E12/E33E13/E33...1⎞⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟=0
所以E虽然有9个未知数,但是有一个变量E33可以看做是缩放因子,因此实际只有8个未知量,这里就是尺度scale的来由,后面会进一步分析这个尺度。
AX=0,x有8个未知量,需要A的秩等于8,所以至少需要8对匹配点。有了匹配点后,就只需要求解最小二乘问题了,上面这个方程的解就是矩阵A进行SVD分解: 后,
后,
V矩阵最右边那一列的值。另外如果这些匹配点都在一个平面上那就会出现A的秩小于8的情况,这时会出现多解,会让你计算的E可能是错误的。
上面是计算本征矩阵E的八点法,大家也可以去看看wiki的详细说明wiki链接。
1x0y1x0y0x1y0y1y0x1y11)E33⎛⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜E11/E33E12/E33E13/E33...1⎞⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟=0
在应用的时候,考虑到E矩阵反正已经是缩放了的,所以更多的是直接令奇异值为(1,1,0),程序如下:

有了本征矩阵E,就可以从E中恢复平移t和旋转R。
3本征矩阵恢复R、T,尺度scale的进一步分析

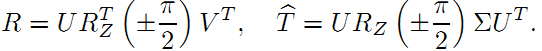

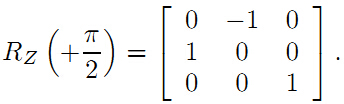
从R,T的计算公式中可以看到R,T都有两种情况,组合起来R,T有4种组合方式。由于一组R,T就决定了摄像机光心坐标系C的位姿,所以选择正确R、T的方式就是,
把所有特征点的深度计算出来,看深度值是不是都大于0,深度都大于0的那组R,T就是正确的。
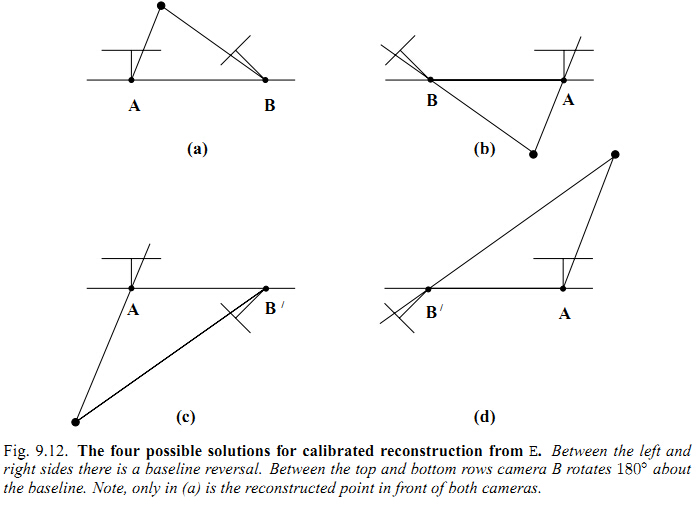
但是特征点深度怎么计算出来呢?这部分的推导见下一篇博客。 http://blog.csdn.net/heyijia0327/article/details/50774104

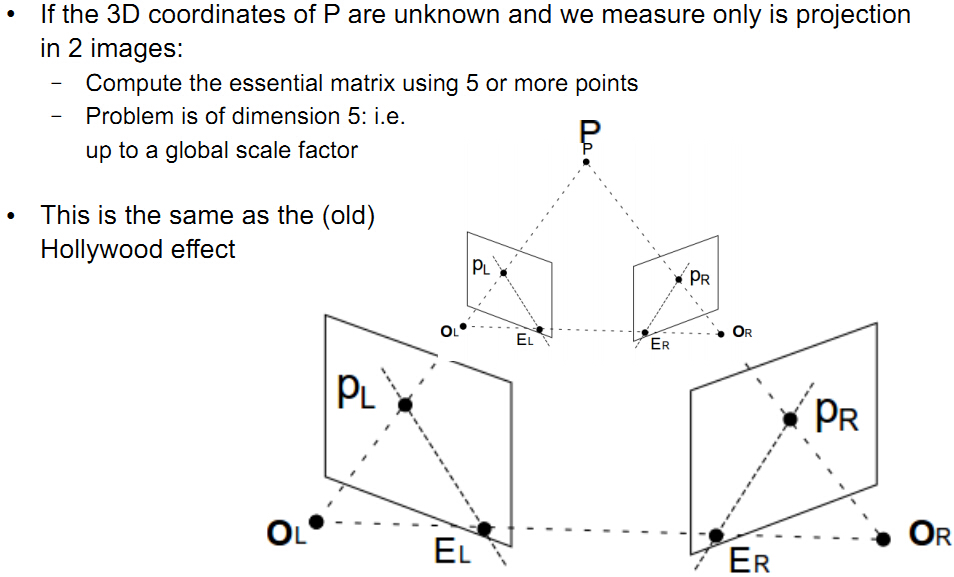
这个图简单明了的演示了这种平移缩放作用。从图中也可以看出,由于尺度scale的关系,不同的t,决定了以后计算点P的深度也是不同的,所以恢复的物体深度也是跟尺度scale有关的,这就是论文中常说的结构恢复structure reconstruction,只是恢复了物体的结构框架,而不是实际意义的物体尺寸。
并且要十分注意,每两对图像计算E并恢复R,T时,他们的尺度都不是一样的,本来是同一点,在不同尺寸下,深度不一样了,这时候地图map它最头痛了,所以这个尺度需要统一。
那么如何统一呢?如果你一直采用这种2d-2d匹配计算位姿的方式,那每次计算的t都是在不同尺度下的。我们已经知道出现尺度不一致是由于每次都是用这种计算本征矩阵的方式,而尺度就是在计算E时产生的。所以尺度统一的另一种思路就是后续的位姿估计我不用这种2d-2d计算本征E的方式了,也就说你通过最开始的两帧图像计算E恢复了R,T,并通过三角法计算出了深度,那我就有了场景点的3D坐标,后续的视频序列就可以通过3Dto2d(opencv里的solvePnp)来进行位姿估计,这样后续的视频序列就不用计算本征矩阵从而绕过了尺度,所以后续的视频序列的位姿和最开始的两帧的尺度是一样的了。但是,这样计算又会产生新的问题–scale drift。因为,两帧间的位姿总会出现误差,这些误差积累以后,使得尺度不再统一了,如下图所示(借用@清华大学王京同学的图,很容易帮助理解):
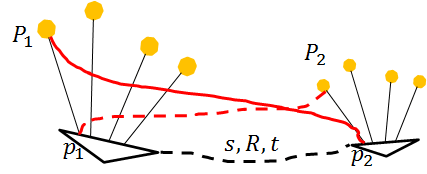
随着相机位姿误差的积累,地图中的四个点在第二帧的位置相对于第一帧中来说像是缩小了一样。位姿误差累计导致尺度漂移这一点,对照上面讲尺度不确定问题时的那个图就很容易理解。关于如何纠正这个scale drift的问题很多单目slam里都提到了,所以这里不再深入。
相机的轨迹有了,接下来就是structure reconstruction 了。
补充: 特征点匹配(常见的有如下两种方式)
1. 计算特征点,然后计算特征描述子,通过描述子来进行匹配,优点准确度高,缺点是描述子计算量大。
2. 光流法:在第一幅图中检测特征点,使用光流法(Lucas Kanade method)对这些特征点进行跟踪,得到这些特征点在第二幅图像中的位置,得到的位置可能和真实特征点所对应的位置有偏差。所以通常的做法是对第二幅图也检测特征点,如果检测到的特征点位置和光流法预测的位置靠近,那就认为这个特征点和第一幅图中的对应。在相邻时刻光照条件几乎不变的条件下(特别是单目slam的情形),光流法匹配是个不错的选择,它不需要计算特征描述子,计算量更小。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









