







End-to-End Object Detection with Fully Convolutional Network阅读笔记
(一)Title

首个端到端的全卷积训练网络,这篇文章在POTO以及3DMF上的数学功底让我望尘莫及,作者对深度学习框架模型的理解也很深入。文章思路和实验设计上都非常清晰。在大佬面前,深感自己的弱小呢。
(二)Summary
基于全卷积网络的主流目标检测器大多数仍然需要非最大抑制(NMS)后处理,在这篇文章中,我们不再使用NMS,为此,对于完全卷积检测器,我们引入了Prediction-aware One-To-One:POTO label assignment for classification,以实现端到端检测,获得与NMS相当的性能。此外,提出了一种简单的3D Max Filtering(3DMF),利用多尺度特征,提高局部区域卷积的可分辨性。通过这些技术,我们的端到端框架在COCO和CrowdHuman数据集上实现了与NMS的许多最先进的检测器相媲美的性能。
此外,作者介绍了目前目标检测中一些state of art的方法:
- eliminate the pre-defined set of anchor boxes(取消预先设定anchor boxes) by using distance-aware and distribution-based label assignments.
- many approaches based on recurrent neural networks have been introduced to predict the bounding box(使用RNN来预测bounding boxes) for each instance by using an autoregressive decoder.
- DETR] introduces a bipartite matching based training strategy and transformers with the parallel decoder to enable end-to-end detection.
作者在这里提出的问题是:如何在全卷积的网络中来实现端到端的目标检测任务?。
想要实现端到端,必须取消掉NMS,NMS是由于a one-to-many label assignment rule(也就是一个真实的box在网络输出会预测多个预测框,然后使用NMS来对真实标签做简化。)首先需要解决掉这个问题,解决这个问题的方法也很简单,我们让一个Groud Truth网络只生成一个Prediction,也就是 one-to-one label assignment
性能表现:在COCO数据集上,我们基于FCOS backbone和ResNeXt-101 backbone的端到端检测器显著优于NMS baseline 1.1%的mAP。并且在拥挤场景下检测更加具有健壮性和灵活性。ResNet-50主干网下,我们的端到端检测器实现了3.1%的AP50和5.6%的mMR绝对增益,超过了基于NMS的FCOS baseline。
(三)Research Object
利用POTO解决one-to-many label assignment存在的NMS后处理过程,作者同时提出3DMF来抑制重复的预测。但是使用上面两个技巧,依旧达不到NMS FCOS baseline。为了提升网络的特征表示能力,作者引入auxiliary loss。最终达到了FCOS的性能,同时,在拥挤人群检测中具有较好的性能以及较高的recall。
(四)Problem Statement
如何实现全卷积网络中取消掉NMS的端到端训练?采用one-to-one label assignment.
在使用hand-designed one-to-one label assignment时,存在的问题是我们固定选取的这个区域(这里我的理解是feature map上某一个特定的location)可能不是我们训练的最佳选择,也就是说,使用这个location预测的bounding boxes很可能不是可以通过NMS保留下来的那个(使用one-to-many带NMS的方法),作者这里给的解释是The fixed assignment could cause ambiguity issues and reduce the discriminability of features,
因此,作者这里利用分类和回归的质量动态地assigns the foreground samples ,也就是作者提出的prediction-aware one-to-one (POTO) label assignment,
大量实验表明,这些重复的框,主要来自于不同scales(不同大小上)上的具有较高置信度的预测值,作者使用一个简单的可微分3D max filtering operator嵌入到FPN头中。
此外作者修改one-to-many assignment 作为辅助损失,用于给特征表示学习提供足够多的监督信息、
(五)Method

取消掉one-to-many的label prediction,作者提出的方法的两个关键是:
- a mixture label assignment (Prediction-aware one-to-one label assignment以及a modified one-to-many label assignment(auxiliary loss))
- a 3D Max Filtering(3DMF)
实现了取消掉NMS后处理,同时保证较强的特征表示能力。
得到的整体网络框架为:
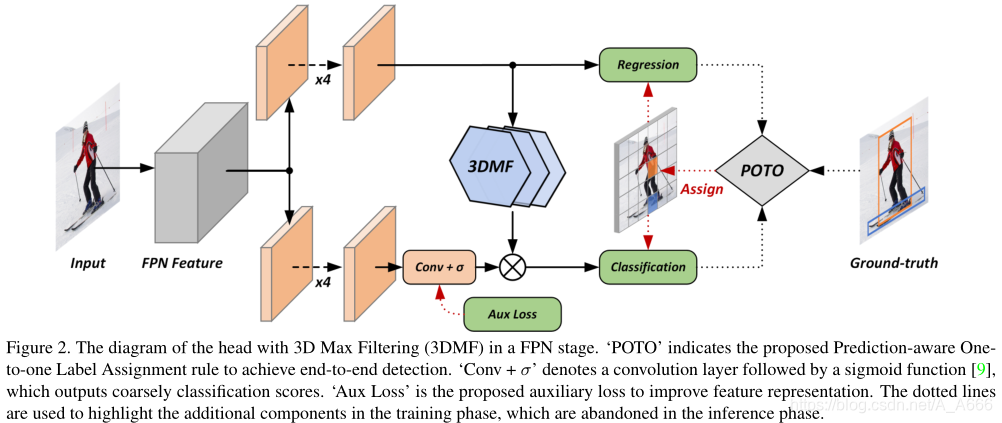
5.1 Prediction-aware One-to-one Label Assignment
使用固定的hand-designed one-to-one label assignment得到的location往往不是最优的,因此,这种强迫式地分配会使得网络收敛难度增加,同时造成更多的False-positive预测。作者这里根据Prediction的质量来进行label assignment。
目标检测的损失函数为
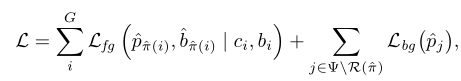
其中,
Ψ
\Psi
Ψ表示所有预测的索引集(the index set of all the predictions),
N
和
G
N和G
N和G分别表示Prediction bounding boxes的数量,Ground Truth bounding boxes 的数量,
L
f
g
L_{fg}
Lfg表示前景损失,
L
b
g
L_{bg}
Lbg表示背景损失。
c
i
,
b
i
c_i,b_i
ci,bi分别是Ground Truth的类别标签以及回归坐标,与之对应着的
p
^
π
^
(
i
)
\hat{p}_{\hat{\pi}(i)}
p^π^(i)和
b
^
π
^
(
i
)
\hat{b}_{\hat{\pi}(i)}
b^π^(i)是预测类别分数以及预测的bounding boxes坐标。
作者这里选取label assignment的指标为:
π
^
=
arg
min
π
∈
Π
G
N
∑
i
G
L
f
g
(
p
^
π
^
(
i
)
,
b
^
π
^
(
i
)
∣
c
i
,
b
i
)
\hat{\pi}=\underset{\pi \in \Pi_{G}^{N}}{\arg \min } \sum_{i}^{G} \mathcal{L}_{f g}\left(\hat{p}_{\hat{\pi}(i)}, \hat{b}_{\hat{\pi}(i)} \mid c_{i}, b_{i}\right)
π^=π∈ΠGNargmini∑GLfg(p^π^(i),b^π^(i)∣ci,bi)
前人的工作中通过使用foreground loss将其看成是一个biparticle matching problem(二分匹配问题),使用Hungarian algorithm求解,但是foreground loss通常需要额外的权重来减轻优化问题,例如,不平衡的训练样本和多个任务的联合训练。在实验6.1部分中的表现在mAP上没能达到baseline。
这里,作者采用的方式是(POTO)来获得一个更好的assignment
π
^
=
arg
max
π
∈
Π
G
N
∑
i
G
Q
i
,
π
(
i
)
where
Q
i
,
π
(
i
)
=
1
[
π
(
i
)
∈
Ω
i
]
⏟
spatial prior
⋅
(
p
^
π
(
i
)
(
c
i
)
)
1
−
α
⏟
classification
.
(
IoU
(
b
i
,
b
^
π
(
i
)
)
)
α
⏟
regression
\begin{aligned} \hat{\pi} &=\underset{\pi \in \Pi_{G}^{N}}{\arg \max } \sum_{i}^{G} Q_{i, \pi(i)} \\ \text { where } Q_{i, \pi(i)}=& \underbrace{1\left[\pi(i) \in \Omega_{i}\right]}_{\text {spatial prior }} \cdot \underbrace{\left(\hat{p}_{\pi(i)}\left(c_{i}\right)\right)^{1-\alpha}}_{\text {classification }} . \\ & \underbrace{\left(\operatorname{IoU}\left(b_{i}, \hat{b}_{\pi(i)}\right)\right)^{\alpha}}_{\text {regression }} \end{aligned}
π^ where Qi,π(i)==π∈ΠGNargmaxi∑GQi,π(i)spatial prior
1[π(i)∈Ωi]⋅classification
(p^π(i)(ci))1−α.regression
(IoU(bi,b^π(i)))α
其中,
Q
i
,
π
(
i
)
∈
[
0
,
1
]
Q_{i, \pi(i)} \in [0,1]
Qi,π(i)∈[0,1]表示第i个Ground-Truth 和我们选择的作为第i个label assignment
π
(
i
)
\pi(i)
π(i)之间的匹配质量。其中考虑了空间先验,分类的置信度以及回归的质量。
Ω
i
\Omega_{i}
Ωi表示第i个地面真值的候选预测集,即空间先验,同时对classification和regression利用
α
\alpha
α进行了加权几何平均数,从6.1的实验中POTO不仅减小with/without NMS之间的差异,同时提升了性能。
5.2 3D Max Filtering
首先,作者弄清楚重复预测究竟是来自何处?进行了实验

从这个表中,作者给出的分析是:when applying the NMS to each scale separately.性能有明显的退化,重复的预测主要来自于nearby spatial regions of the most confident prediction。对于上图没有看明白。
接着作者提出使用3DMF来抑制重复的Predictions
作者这里的3DMF思路来自于CornerNet和CenterNet中max filter,将其从single-scale扩展到多尺度版本。它能够变换FPN多个尺度的特征,特征图中的每一个通道分别采用3D最大值滤波。
x
~
s
=
{
x
~
s
,
k
:
=
Bilinear
x
s
(
x
k
)
∣
∀
k
∈
[
s
−
τ
2
,
s
+
τ
2
]
}
\tilde{x}^{s}=\left\{\tilde{x}^{s, k}:=\underset{x^{s}}{\operatorname{Bilinear}}\left(x^{k}\right) \mid \forall k \in\left[s-\frac{\tau}{2}, s+\frac{\tau}{2}\right]\right\}
x~s={x~s,k:=xsBilinear(xk)∣∀k∈[s−2τ,s+2τ]}
给定一个输入feature
x
s
x^s
xs,在FPN中尺度为s,首先采用bilinear运算符 to interpolate the features from τ adjacent scales as the same size of input feature
x
s
x^s
xs,3DMF图示如下
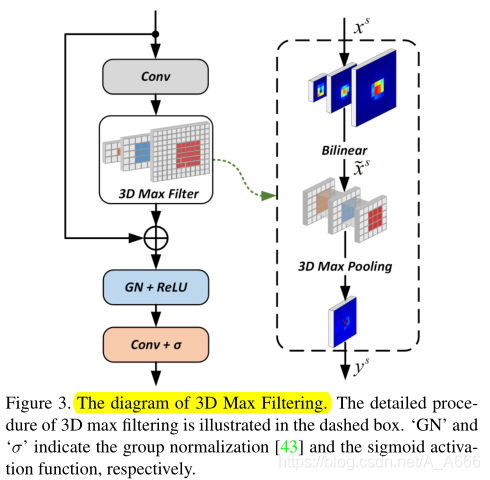
等式:
y
i
s
=
max
k
∈
[
s
−
τ
2
,
s
+
τ
2
]
max
j
∈
N
i
ϕ
×
ϕ
x
~
j
s
,
k
y_{i}^{s}=\max _{k \in\left[s-\frac{\tau}{2}, s+\frac{\tau}{2}\right]} \max _{j \in \mathcal{N}_{i}^{\phi \times \phi}} \tilde{x}_{j}^{s, k}
yis=k∈[s−2τ,s+2τ]maxj∈Niϕ×ϕmaxx~js,k
对于比例尺度s的空间位置i,最大值
y
i
s
y_i^s
yis是通过临近tube尺度以及
ϕ
×
ϕ
{\phi \times \phi}
ϕ×ϕ的空间距离上。这个操作可以通过3D max-pooling 运算符高效实现。
并且在这个过程中,所有模块都是由简单的可微算子构造的,并且只有很小的计算开销。
5.3 Auxiliary Loss(辅助损失)
使用了POTO以及3DMF得到的表现性能依旧不如FCOS baseline,这种现象可能是由于一对一的标签分配提供较少的监督,使得网络难以学习强有力的特征表示造成的.作者这里引入auxiliary loss来增强学习特征表示的能力。
auxiliary loss采用Focal loss和改进的一对多标签分配,具体来说,根据之前公式(4)
Q
i
,
π
(
i
)
∈
[
0
,
1
]
Q_{i, \pi(i)} \in [0,1]
Qi,π(i)∈[0,1]建议的匹配质量, one-to-many label assignment 首先选出前9个预测作为每个FPN阶段的候选,然后,它将候选对象指定为匹配质量超过统计阈值的前景样本,这个统计阈值是通过the summation of the mean and the standard deviation of all the candidate matching qualities来计算出来的.
(六)Experiment
在实验实现上的一些细节内容:
- 采用a pair of -convolution heads分别用于分类和回归
- 在3DMF中第一个卷积和第二个卷积的输出通道分别为256和1
- 所有backbone参数是在ImageNet数据集上进行预训练
- 训练阶段,Image reshape到短边长度为800,所有的训练策略和Detectron2中的2x schedule相同。
- 冻结主干网first two stage的参数,并微调网络的其余部分
- 8个GPU上,每个GPU上两个图片,180K迭代,进行多尺度训练。
- 初始学习率0.01,120K,160K迭代衰减10.
- 使用Synchronized SGD去优化所有模型。
6.1 label assignment Ablation实验
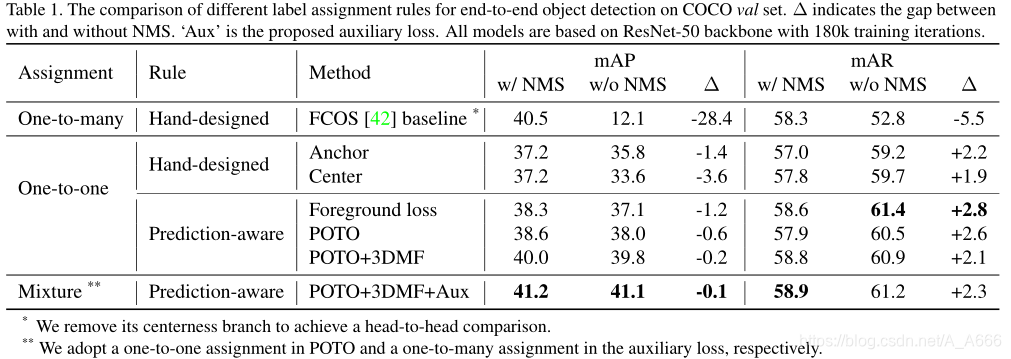
在一对多标签分配中,丢弃掉NMS,造成mAP大幅度下降,因此,仅仅依靠一对多分配,很难实现有竞争力的端到端检测同时从前两行的实验中,我们发现:
- 首先,当应用one to one label assignment时,有和没有NMS的检测器之间的性能差距仍然不可忽略。
- 由于对每个实例的less supervision,一对一标签分配的性能仍然低于FCOS基线
POTO+3DMF+Aux取得了最佳的mAP性能。
6.2 Visualization
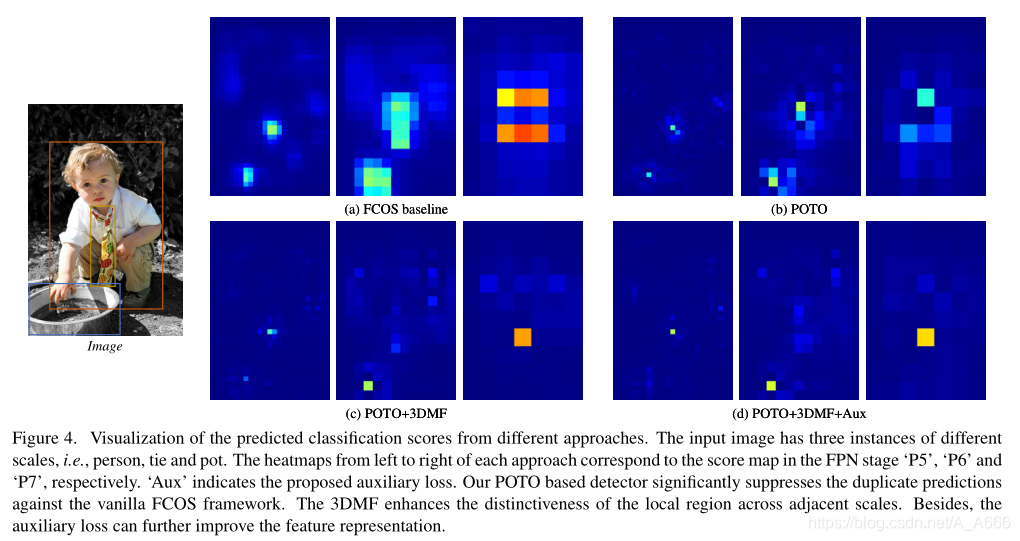
我们展示了来自FCOS基线的分类分数的可视化和我们提出的框架。从上图中可以看出,FCOS baseline有一对多的分配中心输出大量的重复预测,很多位置的置信度分数较高,这些重复的预测被评估为假阳性样本,并极大地影响性能。相反,通过使用所提出的POTO规则,重复样本的分数被显著抑制。在引入3DMF后,达到更好的效果,这是由于3DMF模块引入了多尺度竞争机制,检测器可以在不同的FPN阶段很好地执行独特的预测
6.3 POTO
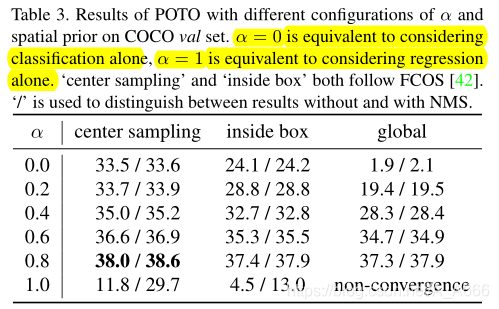
在Spatial prior上,center sampling策略是要由于inside box和global策略的,它反映了图像的先验知识在现实世界场景中是必不可少的。
Classification vs. regression
超参数
α
\alpha
α调节分类和回归的比例,当α = 0时,赋值规则只依赖于分类的预测分数。在这种情况下,与NMS的差距被大大消除,但绝对性能仍然不令人满意,通过分类和回归质量的适当融合,绝对性能显著提高。
Quality function上分类和回归混合表现
采用加法时,对应的表达式为:
(
1
−
α
)
⋅
p
^
π
(
i
)
(
c
i
)
+
α
⋅
IoU
(
b
i
,
b
^
π
(
i
)
)
(1-\alpha) \cdot \hat{p}_{\pi(i)}\left(c_{i}\right)+\alpha \cdot \operatorname{IoU}\left(b_{i}, \hat{b}_{\pi(i)}\right)
(1−α)⋅p^π(i)(ci)+α⋅IoU(bi,b^π(i))
采用乘法时,对应的表达式为:
p
^
π
(
i
)
(
c
i
)
(
1
−
α
)
⋅
IoU
(
b
i
,
b
^
π
(
i
)
)
α
{\hat{p}_{\pi(i)}\left(c_{i}\right)}^{(1-\alpha)} \cdot {\operatorname{IoU}\left(b_{i}, \hat{b}_{\pi(i)}\right)}^{\alpha}
p^π(i)(ci)(1−α)⋅IoU(bi,b^π(i))α
进行的交融实验表现为:
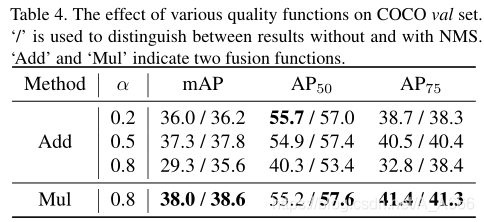
从图中可以看出使用乘法的效果相比于使用加法的效果要好
6.4 3D Max Filtering
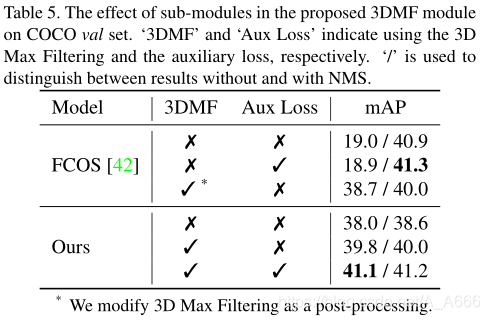
Components
没有3DMF和Aux loss情况下,在mAP上without NMS方法上有了19% mAP的提升,通过使用所提出的3DMF,性能进一步提高了1.8% mAP,与使用NMS的差距缩小到0.2% mAP,结果显示了多尺度和局部范围抑制对于端到端目标检测的关键作用。加上auxiliary loss使得我们获得了和使用NMS的FCOS相当的性能。
End-to-end.
我们用3DMF取代了CenterNet的2D max filter,作为消除重复预测的新后处理。在性能上有了1.1%的提升。
Kernel size

ϕ
\phi
ϕ和$ τ$对于性能的影响
性能和训练迭代的变化关系图示
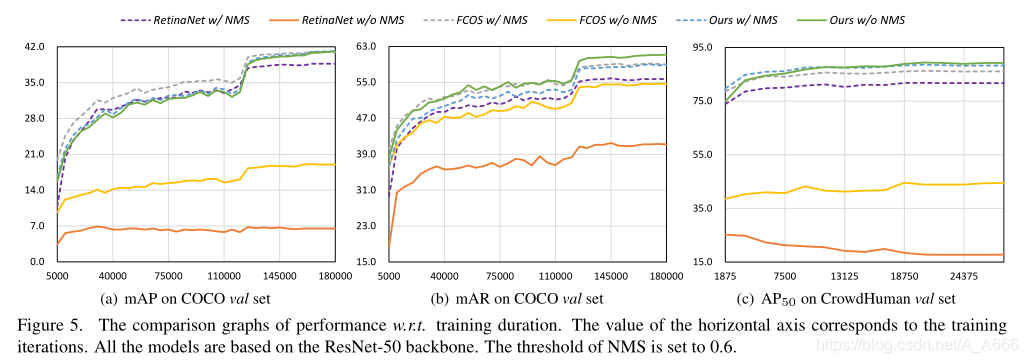
一开始,我们的端到端检测器不如带有NMS的检测器,经过180k次训练迭代,我们的方法最终优于其他NMS检测器。这种现象也发生在CrowdHuman val集合上,如图5©所示。此外,由于去除了手工设计的后处理,图5(b)展示了我们的方法在召回率方面相对于基于NMS的方法的优势。
6.5 更大的backbone
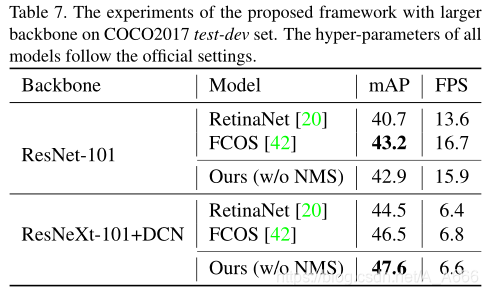
我们提供了具有较大主干的实验。当使用ResNet-101作为主干时,我们的方法比FCOS的方法稍差0.3% mAP。但是,当引入更强的主干时,即带有可变形卷积的ResNeXt-101,我们的端到端检测器实现了1.1%的mAP绝对增益,超过了FCOS和NMS。这可能归因于可变形卷积的灵活空间建模。此外,所提出的3DMF是高效且易于实现的,3DMF模块与带有NMS的基线检测器相比,只有轻微的计算开销。
6.6 在CrowdHuman上评估
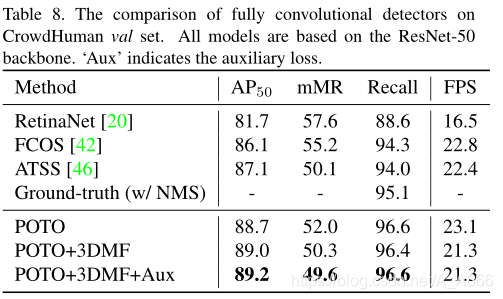
在拥挤人群下有更好的表现,同时具有较高的召回率、相比于NMS方法。
(七)Notes
1. 消除掉预先设定的anchor boxes的方法
by using distance-aware and distribution-based label assignments。真不错,想看看
2. 使用RNN来预测bounding boxes
这些方法存在的问题是:它们仅在小数据集上进行评估,并且迭代方式使得inference过程效率低下。
3. 两种手动设计的one-to-one label prediction方法(确定在特征图上的location)
- Anchor Rule
基于RetinaNet的,这里应该是和YOLO相似,在feature map上每一个location处,都存在着多个尺度的anchor,基于多个尺度的anchor和Ground Truth IoU最大的那个anchor对应的location就是我们这次的Prediction。其他的都设置为背景 - Center Rule
在特征层上location距离Ground Truth bounding boxes最近的那个位置。其他的都设置为背景。
(八)Conclusion
本文提出了一种POTO标签分配和3DMF,以弥补使用NMS的完全卷积网络和端到端目标检测之间的差距。在有辅助损失的情况下,我们的端到端框架在COCO和CrowdHuman数据集上与NMS的许多最先进的检测器相比实现了卓越的性能。我们的方法在复杂和拥挤的场景中也表现出了巨大的潜力,这可能有利于许多其他实例级任务。














 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









