







车辆轨迹预测系列 (二):常见数据集介绍
文章目录
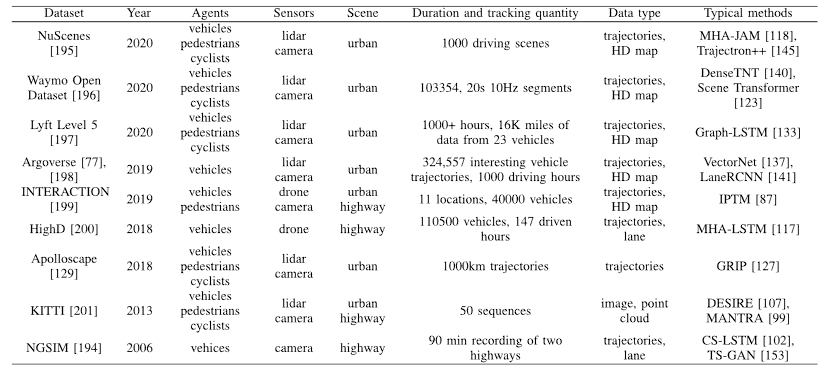
- Dataset:数据集名称及参考文献编号。
- Year:数据集发布的年份。
- Agents:数据集中涉及的代理对象,包括行人(pedestrians)、骑行者(cyclists)和车辆(vehicles)。
- Sensors:数据集中使用的传感器类型,包括激光雷达(lidar)、摄像头(camera)和无人机(drone)。
- Scene:数据采集的场景类型,包括城市(urban)和高速公路(highway)。
- Duration and tracking quantity:数据集的持续时间和跟踪数据的数量。包括驾驶场景的数量、数据时长、车辆数量等。
- Data type:数据的类型,包括轨迹(trajectories)、高清地图(HD map)、图像(image)、点云(point cloud)等。
- Typical methods:针对该数据集常用的典型方法或模型。
详细分析
1、NuScenes (2020):
- Agents:行人、骑行者、车辆
- Sensors:激光雷达、摄像头
- Scene:城市
- Duration and tracking quantity:1000个驾驶场景
- Data type:轨迹、高清地图
- Typical methods:MHA-JAM, Trajectron++
- Download Link: nuScenes Dataset
- Paper Link:https://arxiv.org/abs/1903.11027 nuScenes: A multimodal dataset for autonomous driving
优点:
- 多模态数据:包括雷达、激光雷达(LiDAR)、摄像头和GPS数据。
- 高质量标注:详细的目标检测和跟踪,包含场景理解、行为预测和3D物体检测。
- 场景丰富:包括城市和高速公路场景,覆盖多种天气和时间条件。
缺点:
- 数据量较大:需要较大的存储和计算资源。
- 标注成本高:数据标注的工作量大,成本较高。
适用场景:
- 适合需要多传感器融合、场景理解和行为预测的研究和开发工作。
- 高质量的数据需求,尤其是在复杂城市环境中的自动驾驶开发。
详细介绍
数据集是一个带有3d对象注释的大规模自动驾驶数据集。
●全传感器套件(1倍激光雷达,5倍雷达,6倍摄像头,IMU, GPS)
●1000个20秒的场景
●140万张相机图像
●39万次激光雷达扫描
●两个不同的城市:波士顿和新加坡
●左侧与右侧交通
●详细地图信息
●1.4M 3D边框手动标注23个对象类
●新增:为32个类别手动标注了1.1亿个激光雷达点
1、下载
完整的nuScenes数据集包含1000个场景,Mini中包含10个场景
-
深入nuScenes数据集(1/6)-https://www.linpx.com/p/deep-into-the-nuscenes-dataset-16.html
-
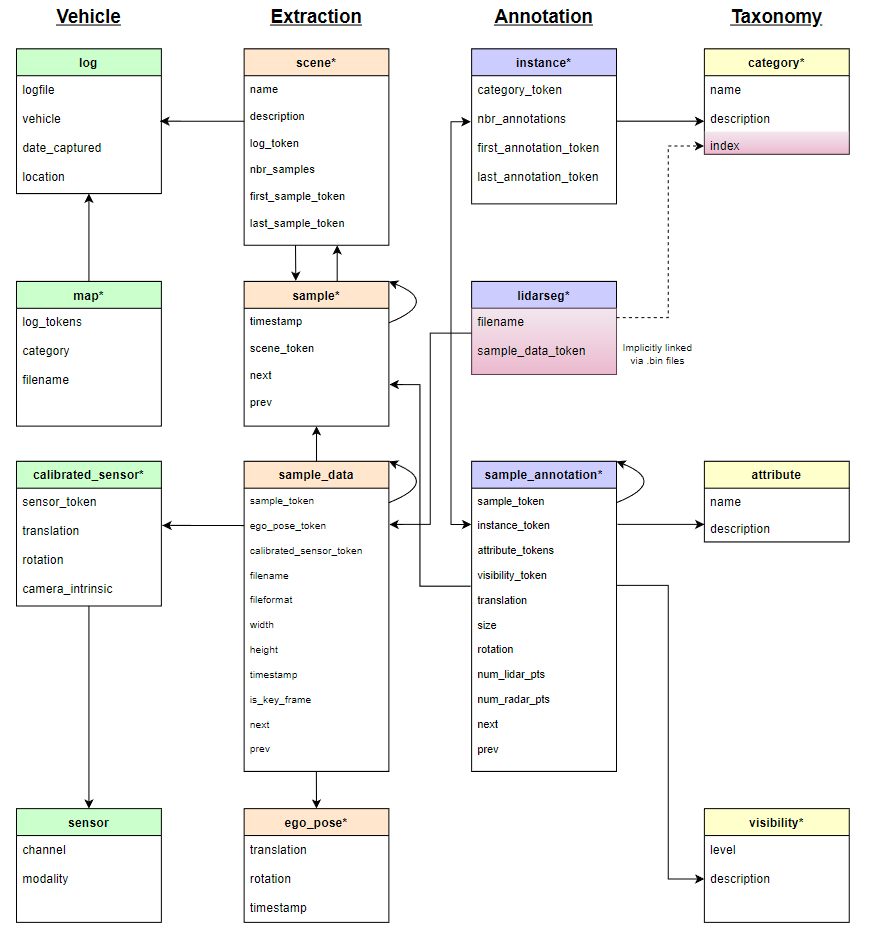
https://github.com/nutonomy/nuscenes-devkit/blob/master/docs/schema_nuscenes.md
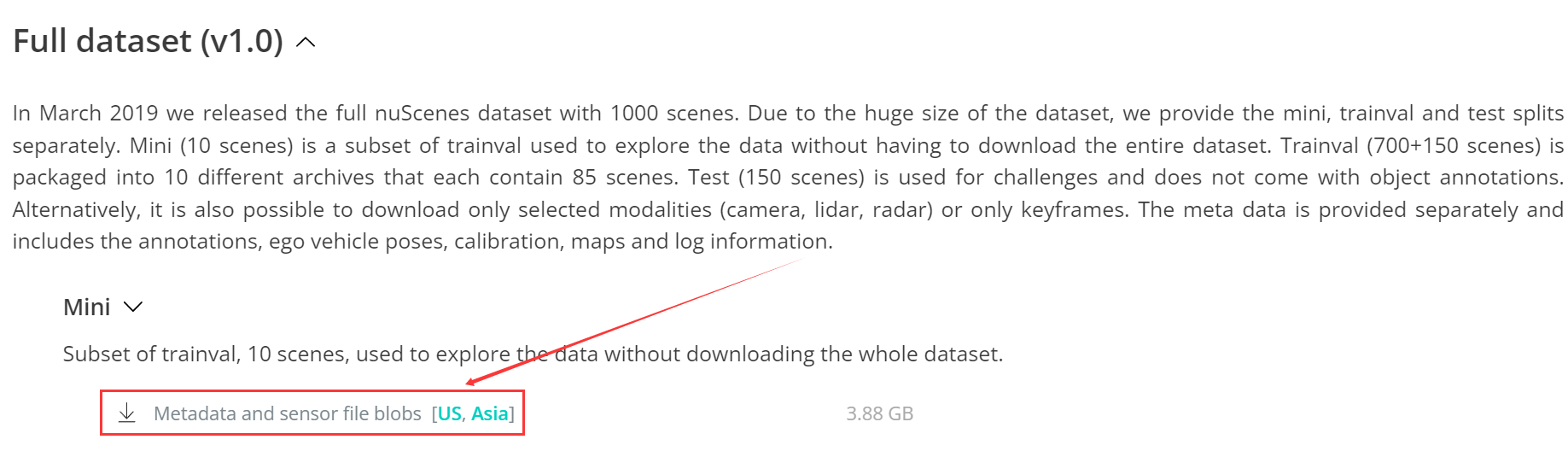
顺带一提,这里面还有一个nuScenes预测任务的比赛

预测nuScenes数据集中物体的未来轨迹。 轨迹是x-y位置的序列。对于这个挑战,预测时间为6秒,采样时间为 2赫兹。
2、说明
2、Waymo Open Dataset (2020):
-
Agents:行人、骑行者、车辆
-
Sensors:激光雷达、摄像头
-
Scene:城市
-
Duration and tracking quantity:103354个10Hz段,20秒每段
-
Data type:轨迹、高清地图
-
Typical methods:DenseTNT, Scene Transformer
-
Download Link: Waymo Open Dataset
-
Paper Link:https://openaccess.thecvf.com/content/ICCV2021/html/Ettinger_Large_Scale_Interactive_Motion_Forecasting_for_Autonomous_Driving_The_Waymo_ICCV_2021_paper.html Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset
优点:
- 高质量的LiDAR数据:提供了丰富的3D点云数据,标注精确。
- 开放数据集:数据集开放,易于获取和使用。
- 多样化场景:涵盖城市道路和高速公路,支持多种驾驶场景。
缺点:
- 数据规模大:需要较高的计算和存储能力。
- 标注复杂:高精度的标注要求较高的处理和计算资源。
适用场景:
- 适用于需要高质量LiDAR数据和复杂场景理解的研究。
- 特别适合3D物体检测、跟踪和行为预测算法的开发。
1、介绍
官方数据集中包含两类Motion和Preception,由于本文重点在于轨迹预测,因此仅介绍Motion数据
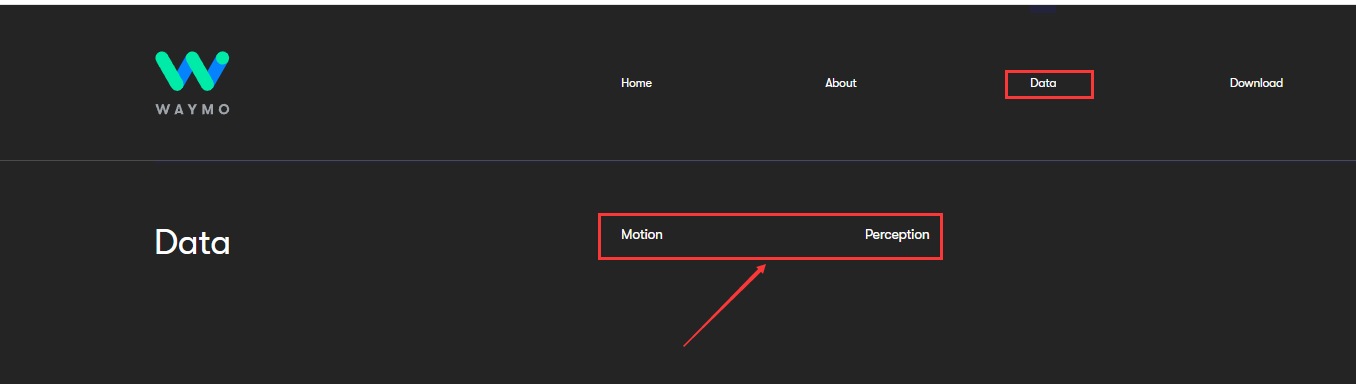
**Motionhttps://waymo.com/open/data/motion/**用于Sim Agents (2024 version), Motion Prediction (2024 version), Occupancy and Flow Prediction (2024 version), and Interaction Prediction.等内容

**Perceptionhttps://waymo.com/open/data/perception/**用于 3D Semantic Segmentation, 3D Camera-Only Detection, Real-time 3D Detection, Real-time 3D Tracking, 2D Detection, 2D Tracking, and Domain Adaptation.等内容

2、概述
动作数据集以包含协议缓冲区数据的分片TFRecord格式文件的形式提供。数据被分成训练集、测试集和验证集,其中70%的训练集、15%的测试集和15%的验证集。该数据集由103354个片段组成,每个片段包含20秒的10Hz目标轨迹和片段所覆盖区域的地图数据。这些片段被进一步分解为9秒的窗口(1秒的历史数据和8秒的未来数据),这些窗口有不同的重叠。数据以两种形式提供。第一种形式存储为场景协议缓冲区。第二种形式将场景原型转换为tf。示例protos包含用于构建模型的张量。这两种格式的详细信息在本页的末尾。
训练集或验证集中的每9秒序列都包含1秒的历史数据、1个当前时间的样本和8秒的未来数据,采样频率为10 Hz。这对应于10个历史样本、1个当前时间样本和80个未来样本,总共91个样本。测试集隐藏了总共11个样本(10个历史样本和1个当前时间样本)的真实未来数据。
Scenario Proto format 场景原型格式

3、下载
需要注册账号选择需要的数据集下载即可

4、教程
如果您想要直接进入,请查看这里的教程。Github repo还包括一个快速入门,其中包含Waymo开放数据集支持代码的安装说明。
https://github.com/waymo-research/waymo-open-dataset/blob/master/tutorial/tutorial_motion.ipynb
5、参考
3、Lyft Level 5 (2020):
- Agents:行人、骑行者、车辆
- Sensors:激光雷达、摄像头
- Scene:城市
- Duration and tracking quantity:1000+小时,从23辆车中收集16K英里的数据
- Data type:轨迹、高清地图
- Typical methods:Graph-LSTM
- Download Link: Lyft Level 5 Dataset
- Paper Link: https://proceedings.mlr.press/v155/houston21a.html One Thousand and One Hours: Self-driving Motion Prediction Dataset
优点:
- 多传感器数据:包括摄像头、雷达和LiDAR数据。
- 城市环境:重点覆盖城市环境,适合城市自动驾驶研究。
- 高精度标注:标注数据详细,支持多种任务。
缺点:
- 需要高性能计算:处理数据的计算资源需求较高。
适用场景:
- 适用于城市环境下的自动驾驶研究和开发,特别是多传感器数据融合和场景理解。
1、官方
2、数据集

3、备注
这个项目视乎已终止且未得到积极维护
4、Argoverse (2019):
- Agents:车辆
- Sensors:激光雷达、摄像头
- Scene:城市
- Duration and tracking quantity:324,557个有趣的车辆轨迹,1000个驾驶小时
- Data type:轨迹、高清地图
- Typical methods:VectorNet, LaneRCNN
- Download Link: Argoverse Dataset
- Paper Link: https://arxiv.org/abs/2301.00493Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
优点:
- 多样化的场景:包括城市和高速公路环境。
- 丰富的标注:提供了高质量的标注,涵盖对象检测、轨迹预测等任务。
- 数据格式标准化:数据格式标准化,便于使用和开发。
缺点:
- 数据规模大:需要较多的存储和计算资源。
- 标注成本高:数据标注工作量大。
适用场景:
- 适合复杂场景下的自动驾驶算法开发,特别是在城市环境中的应用研究。
- 强调场景理解和轨迹预测的任务。
1、数据下载
Argoverse包含两个版本Argoverse 1和Argoverse 2

点击下载

https://www.argoverse.org/av2.html#download-link


2、参考
5、INTERACTION (2019):
- Agents:车辆、行人
- Sensors:无人机、摄像头
- Scene:城市、高速公路
- Duration and tracking quantity:11个地点,40,000辆车
- Data type:轨迹、高清地图
- Typical methods:IPTM
- Download Link: INTERACTION Dataset
- Paper Link: https://arxiv.org/abs/1910.03088 INTERACTION Dataset: An INTERnational, Adversarial and Cooperative moTION Dataset in Interactive Driving Scenarios with Semantic Maps
优点:
- 专注于行为预测:特别适合研究交通参与者之间的互动和行为预测。
- 多场景数据:涵盖多种场景和交通情况,数据丰富。
缺点:
- 数据标注需求高:高质量的标注需要较多的人力和时间。
适用场景:
- 适合行为预测和交通参与者互动研究,尤其是在复杂交通场景中的应用。
1、数据请求
- 特点: INTERACTION 数据集包含各种交通场景下的车辆轨迹数据,涵盖城市交叉口、环形交叉口等多样场景,适合研究车辆间交互影响的预测问题。
- 链接: INTERACTION Dataset
- 备注:需要单独请求,随后会发到邮箱

6、HighD (2018):
- Agents:车辆
- Sensors:无人机
- Scene:高速公路
- Duration and tracking quantity:110500辆车,147驾驶小时
- Data type:轨迹、车道
- Typical methods:MHA-LSTM
- Download Link: HighD Dataset
- Paper Link: https://arxiv.org/abs/1910.03088 The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems
优点:
- 高速公路数据:专注于高速公路场景,数据集质量高。
- 数据标注细致:包括多种车辆和道路标志的标注,适合路径规划研究。
缺点:
- 数据场景有限:主要集中在高速公路场景,适用范围有限。
适用场景:
- 适合高速公路场景下的自动驾驶研究和路径规划算法开发。
1、介绍

2、数据请求
按照官方的要求,需要填写申请表,笔者正在申请
7、Apolloscape (2018):
- Agents:行人、骑行者、车辆
- Sensors:激光雷达、摄像头
- Scene:城市
- Duration and tracking quantity:1000公里轨迹
- Data type:轨迹
- Typical methods:GRIP
- Download Link: Apolloscape Dataset
- Paper Link: https://ieeexplore.ieee.org/abstract/document/8753527 The ApolloScape Open Dataset for Autonomous Driving and Its Application
优点:
- 多传感器数据:包括摄像头、LiDAR和雷达数据。
- 数据覆盖广:涵盖城市、农村和高速公路场景,数据丰富。
缺点:
- 数据标注复杂:标注过程复杂,需要较高的技术支持。
- 数据处理要求高:处理和存储数据需要较高的计算资源。
适用场景:
- 适合多场景下的自动驾驶研究,特别是需要多传感器数据融合的应用。
1、数据下载


我们的轨迹数据集包括基于相机的图像, 激光雷达扫描点云,并手动注释轨迹。它被收集在各种 照明条件和交通密度。更具体地说,它包含高度复杂的流量 车流中混杂着车辆、乘客和行人。
2、数据请求
官方提供了一些样本数据,完整版数据仍需邮件联系apolloscape.auto@gmail.com,全部数据笔者正在申请
8、KITTI (2013):
- Agents:行人、骑行者、车辆
- Sensors:激光雷达、摄像头
- Scene:城市、高速公路
- Duration and tracking quantity:50个序列
- Data type:图像、点云
- Typical methods:DESIRE, MANTRA
- Download Link: KITTI Dataset
- Paper Link: https://journals.sagepub.com/doi/full/10.1177/0278364913491297 Vision meets robotics: The kitti dataset
优点:
- 经典数据集:在自动驾驶领域广泛使用,数据格式标准化。
- 易于获取和使用:数据集公开,易于下载和使用。
缺点:
- 数据更新不频繁:数据集较老,部分数据不再符合当前技术水平。
- 场景较为简单:主要集中在城市和高速公路,复杂场景较少。
适用场景:
- 适用于入门级的自动驾驶研究和基准测试,特别是计算机视觉和深度学习算法的开发。
1、轨迹检测


2、数据集下载
https://www.cvlibs.net/datasets/kitti/eval_tracking.php

9、NGSIM (2006):
- Agents:车辆
- Sensors:摄像头
- Scene:高速公路
- Duration and tracking quantity:两段高速公路的90分钟记录
- Data type:轨迹、车道
- Typical methods:CS-LSTM, TS-GAN
- Download Link: NGSIM Dataset Next Generation Simulation (NGSIM) Vehicle Trajectories and Supporting Data
- Paper Link: Traffic analysis tools, Accessed: Jan. 6, 2021. [Online]. Available: https://ops.fhwa.dot.gov/trafficanalysistools/index.htm
优点:
- 交通流数据:专注于交通流和车流数据,适合交通流分析和交通管理研究。
- 数据覆盖广:涵盖多种交通情况和时间段,数据丰富。
缺点:
- 数据标注有限:标注信息相对简单,缺少复杂的物体检测和行为标注。
- 场景局限性:数据集主要集中在高速公路和城市道路,场景较为单一。
适用场景:
- 适合交通流分析、交通预测和交通管理研究,尤其是交通行为建模和流量预测。
1、数据下载
Next Generation Simulation (NGSIM) Vehicle Trajectories and Supporting Data


















 6238
6238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









