







CVPR2024 轨迹预测系列(一)
文章目录

一、Adapting to Length Shift: FlexiLength Network for Trajectory Prediction.
- Adapting to Length Shift: FlexiLength Network for Trajectory Prediction. arXiv
- 适应长度变化:用于轨迹预测的 FlexiLength 网络
1、Abstract
Trajectory prediction plays an important role in various applications, including autonomous driving, robotics, and scene understanding. Existing approaches mainly focus on developing compact neural networks to increase prediction precision on public datasets, typically employing a standardized input duration. However, a notable issue arises when these models are evaluated with varying observation lengths, leading to a significant performance drop, a phenomenon we term the Observation Length Shift. To address this issue, we introduce a general and effective framework, the FlexiLength Network (FLN), to enhance the robustness of existing trajectory prediction techniques against varying observation periods. Specifically, FLN integrates trajectory data with diverse observation lengths, incorporates FlexiLength Calibration (FLC) to acquire temporal invariant representations, and employs FlexiLength Adaptation (FLA) to further refine these representations for more accurate future trajectory predictions. Comprehensive experiments on multiple datasets, i.e., ETH/UCY, nuScenes, and Argoverse 1, demonstrate the effectiveness and flexibility of our proposed FLN framework.
轨迹预测在自动驾驶、机器人和场景理解等各种应用中发挥着重要作用。现有方法主要集中于开发紧凑的神经网络以提高公共数据集的预测精度,通常采用标准化的输入持续时间。然而,当使用不同的观察长度评估这些模型时,会出现一个值得注意的问题,导致性能显着下降,我们将这种现象称为观察长度偏移。为了解决这个问题,我们引入了一个通用且有效的框架,即 FlexiLength Network (FLN),以增强现有轨迹预测技术针对不同观测周期的鲁棒性。具体来说,FLN 将轨迹数据与不同的观测长度相结合,结合 FlexiLength Calibration (FLC) 来获取时间不变表示,并采用 FlexiLength Adaptation (FLA) 进一步细化这些表示,以实现更准确的未来轨迹预测。对多个数据集(即 ETH/UCY、nuScenes 和 Argoverse 1)的综合实验证明了我们提出的 FLN 框架的有效性和灵活性。
在这里面作者提出了Observation Length Shift的概念,当使用不同的观察长度评估这些模型时,会导致性能显着下降
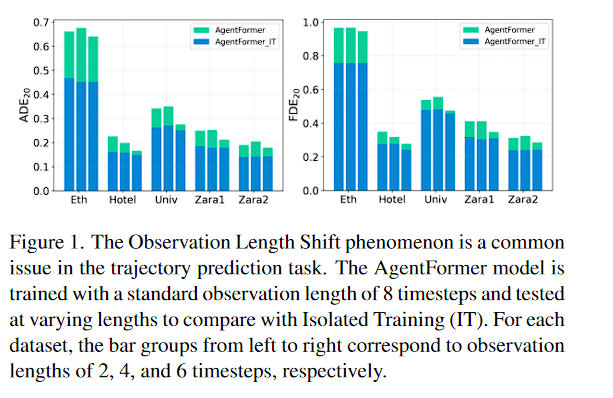
图 1. 观察长度偏移现象是轨迹预测任务中的常见问题。 AgentFormer 模型使用 8 个时间步长的标准观察长度进行训练,并以不同的长度进行测试,以与隔离训练 (IT) 进行比较。对于每个数据集,从左到右的条形组分别对应于 2、4 和 6 个时间步长的观察长度。
- AgentFormer 用于对照,设置Observation Length 为8个时间步长,在2,4,6时间步长下的测试
- AgentFormer_IT 用于探究不同的Observation Length对结果的影响, 原文提到的是specific observation length,推测是保持和测试的时间步长保持一致,即2,4,6

2、FlexiLength Network
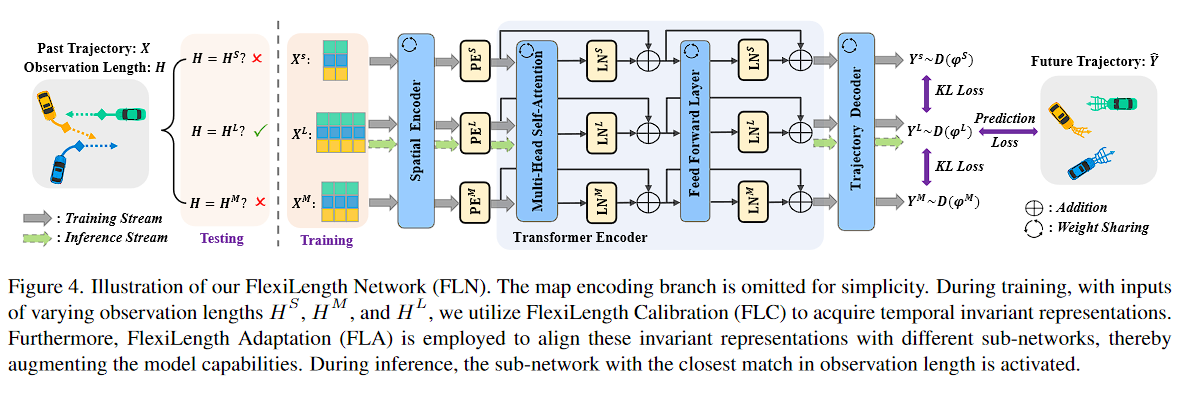
图 4.我们的 FlexiLength 网络 (FLN) 的图示。为了简单起见,省略了映射编码分支。在训练期间,通过输入不同的观察长度 H S H^S HS, H M H^M HM,和 H L H^L HL ,我们利用 FlexiLength Calibration (FLC) 来获取时间不变表示。此外,采用 FlexiLength Adaptation (FLA) 将这些不变表示与不同的子网络对齐,从而增强模型功能。在推理过程中,观察长度最匹配的子网络被激活。
这里的“观察者长度”(Observation Length,标记为 H H H ) 指的是模型在预测未来轨迹之前用来观察的过去轨迹的时间长度。这个长度可以是不同的取值,比如 H S H^S HS, H M H^M HM,和 H L H^L HL ,代表短、中、和长的观察序列。
需要注意的是,这里的 H S H^S HS, H M H^M HM,和 H L H^L HL 是通过we can generate sequences of varying lengths either through truncation or a sliding window approach.截断或滑动来获得不同的长度

这里的观察者长度用于训练和推理(测试)过程:
- 训练时 :根据不同的观察长度 H S H^S HS, H M H^M HM,和 H L H^L HL 输入相应的历史轨迹,模型学习如何根据不同长度的观察来预测未来的状态。这里引入了“FlexiLength Calibration (FLC)”来获取时间不变的表示,并通过“FlexiLength Adaptation (FLA)”来对齐这些表示,增强模型的泛化能力。
- 推理时 (即测试时):根据测试时提供的观察长度,激活与之最匹配的子网络来进行未来轨迹的预测。
因此,观察者长度在这里既适用于训练集也适用于测试集,它是连接过去轨迹输入和未来轨迹预测的桥梁。
3、Datasets
Datasets. We use three following datasets: (1) The ETH/UCY dataset [31, 46] is a primary benchmark for pedestrian trajectory prediction, including five datasets, Eth, Hotel, Univ, Zara1, and Zara2, with densely interactive trajectories sampled at 2.5Hz. (2) The nuScenes dataset [74] is a large autonomous driving dataset featuring 1000 scenes, each annotated at 2Hz, and includes HD maps with 11 semantic classes. (3) Argoverse 1 [7] contains 323,557 realworld driving sequences sampled at 10Hz, complemented with HD maps for trajectory prediction.
数据集。我们使用以下三个数据集:(1)ETH/UCY数据集[31, 46]是行人轨迹预测的主要基准,包括Eth、Hotel、Univ、Zara1和Zara2五个数据集,具有以2.5采样的密集交互轨迹赫兹。 (2) nuScenes数据集[74]是一个大型自动驾驶数据集,具有1000个场景,每个场景以2Hz进行注释,并包括具有11个语义类别的高清地图。 (3) Argoverse 1 [7] 包含 323,557 个以 10Hz 采样的现实世界驾驶序列,并辅以用于轨迹预测的高清地图。
4、Experiments
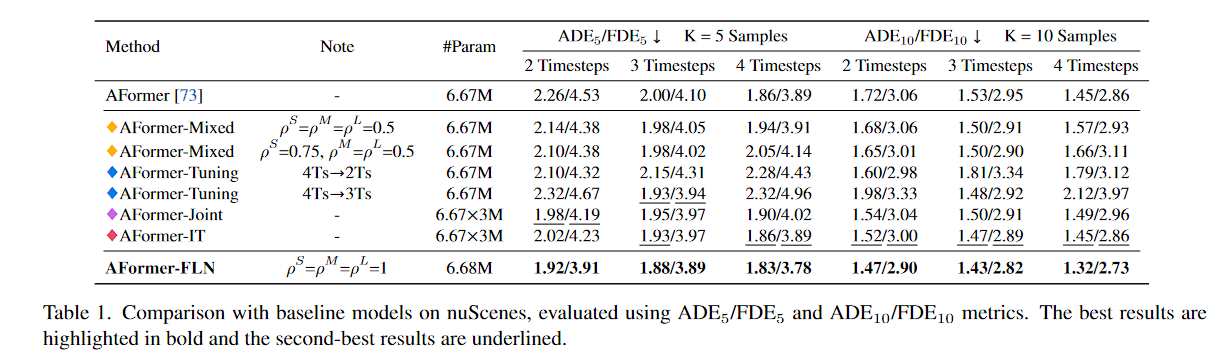
表 1. 与 nuScenes 上的基线模型的比较,使用 ADE5/FDE5 和 ADE10/FDE10 指标进行评估。最好的结果以粗体突出显示,次好的结果加下划线。
where K indicates the number of trajectories to be predicted.(其中K表示要预测的轨迹数量)
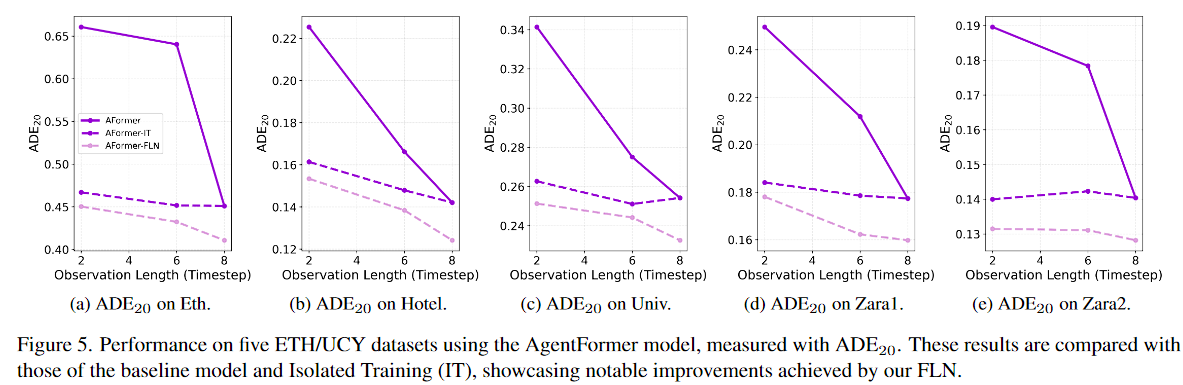
图 5. 使用 AgentFormer 模型在五个 ETH/UCY 数据集上的性能,通过 ADE20 进行测量。这些结果与基线模型和隔离训练 (IT) 的结果进行了比较,展示了我们的 FLN 取得的显着改进。
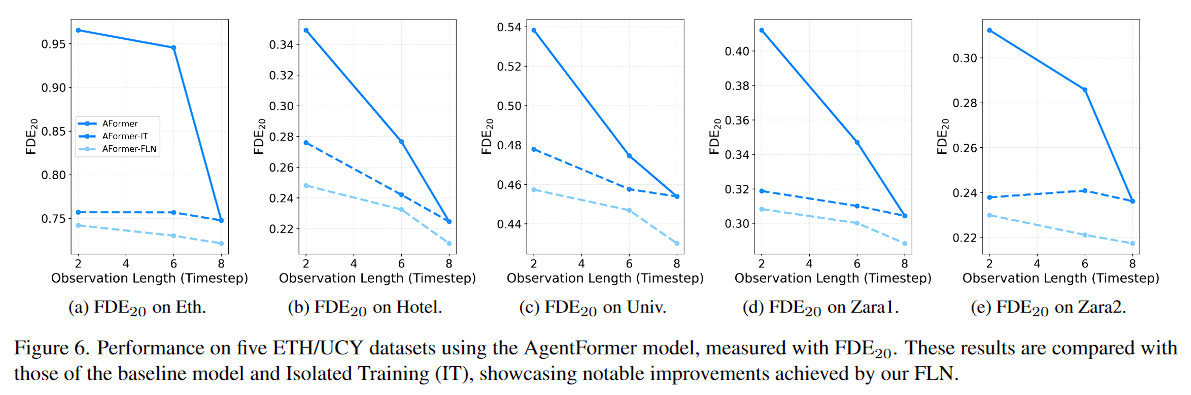
图 6. 使用 AgentFormer 模型在五个 ETH/UCY 数据集上的性能,通过 FDE20 进行测量。这些结果与基线模型和隔离训练 (IT) 的结果进行了比较,展示了我们的 FLN 取得的显着改进。
5、Implementation Details
We employ the official codes of the AgentFormer model [73], as found in 1, and the HiVT [75] model, as found in 2, to evaluate our proposed framework. We utilize the provided pre-trained models to assess the performance across different observation lengths. Specifically, for the HiVT model, we opt for its smaller variant, HiVT-64, and use the Argoverse 1 validation set.
我们采用 AgentFormer 模型 [73] 的官方代码(如 1 中所示)和 HiVT [75] 模型(如 2 中所示)来评估我们提出的框架。我们利用提供的预训练模型来评估不同观察长度的性能。具体来说,对于 HiVT 模型,我们选择其较小的变体 HiVT-64,并使用 Argoverse 1 验证集。
6、Conclusion
In this paper, we tackle the critical challenge of Observation Length Shift in trajectory prediction by introducing the FlexiLength Network (FLN). This novel framework, incorporating FlexiLength Calibration (FLC) and FlexiLength Adaptation (FLA), offers a general solution for handling varying observation lengths and requires only one-time training. Our thorough experiments on datasets such as ETH/UCY, nuScenes, and Argoverse 1 demonstrate that FLN not only improves prediction accuracy and robustness over a range of observation lengths but also consistently outperforms Isolated Training (IT). Limitation and Future Work. One limitation is that FLN will increase training time due to handling several input sequences per training iteration. Going forward, we will focus on enhancing the training efficiency of FLN.
在本文中,我们通过引入 FlexiLength Network (FLN) 来解决轨迹预测中观察长度偏移的关键挑战。这一新颖的框架结合了 FlexiLength 校准 (FLC) 和 FlexiLength 适应 (FLA),为处理不同的观察长度提供了一种通用解决方案,并且仅需要一次性培训。我们对 ETH/UCY、nuScenes 和 Argoverse 1 等数据集进行的彻底实验表明,FLN 不仅提高了一系列观察长度上的预测准确性和鲁棒性,而且始终优于隔离训练 (IT)。限制和未来的工作。一个限制是 FLN 由于每次训练迭代处理多个输入序列而会增加训练时间。下一步,我们将重点关注提升FLN的训练效率。
二、CaDeT: a Causal Disentanglement Approach for Robust Trajectory Prediction in Autonomous Driving.
CaDeT: a Causal Disentanglement Approach for Robust Trajectory Prediction in Autonomous Driving. CVPR2024
CaDeT:自动驾驶中稳健轨迹预测的因果解开方法
1、Abstract
For safe motion planning in real-world, autonomous vehicles require behavior prediction models that are reliable and robust to distribution shifts. The recent studies suggest that the existing learning-based trajectory prediction models do not posses such characteristics and are susceptible to small perturbations that are not present in the training data, largely due to overfitting to spurious correlations while learning.
为了实现现实世界中的安全运动规划,自动驾驶车辆需要对分布变化可靠且稳健的行为预测模型。最近的研究表明,现有的基于学习的轨迹预测模型不具备这样的特征,并且容易受到训练数据中不存在的小扰动的影响,这主要是由于学习时对虚假相关性的过度拟合。
In this paper, we propose a causal disentanglement representation learning approach aiming to separate invariant (causal) and variant (spurious) features for more robust learning. Our method benefits from a novel intervention mechanism in the latent space that estimates potential distribution shifts resulted from spurious correlations using uncertain feature statistics, hence, maintaining the realism of interventions. To facilitate learning, we propose a novel invariance objective based on the variances of the distributions over uncertain statistics to induce the model to focus on invariant representations during training. We conduct extensive experiments on two large-scale autonomous driving datasets and show that besides achieving state-of-the-art performance, our method can significantly improve prediction robustness to various distribution shifts in driving scenes. We further conduct ablative studies to evaluate the design choices in our proposed framework.
在本文中,我们提出了一种因果解缠表示学习方法,旨在分离不变(因果)和变异(虚假)特征以实现更稳健的学习。我们的方法受益于潜在空间中的一种新颖的干预机制,该机制使用不确定的特征统计来估计由虚假相关性引起的潜在分布变化,从而保持干预的真实性。为了促进学习,我们提出了一种基于不确定统计分布方差的新颖的不变性目标,以促使模型在训练期间专注于不变表示。我们对两个大规模自动驾驶数据集进行了广泛的实验,结果表明,除了实现最先进的性能外,我们的方法还可以显着提高对驾驶场景中各种分布变化的预测鲁棒性。我们进一步进行烧蚀研究来评估我们提出的框架中的设计选择。
2、Introduction
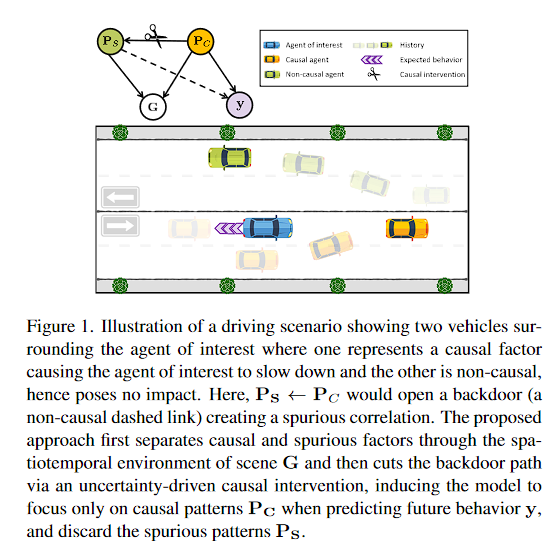
图 1. 驾驶场景图示,显示感兴趣主体周围有两辆车,其中一辆代表导致感兴趣主体减速的因果因素,另一辆是非因果因素,因此不会造成影响。在这里, P S ← P C P_S ← P_C PS←PC 将打开一个后门(非因果虚线链接),从而创建虚假相关性。所提出的方法首先通过场景 $G $的时空环境分离因果因素和虚假因素,然后通过不确定性驱动的因果干预来切断后门路径,诱导模型在预测未来行为 y 时仅关注因果模式 P C P_C PC,并丢弃虚假模式 P S P_S PS.
-
P S P_S PS表示spurious patterns(虚假模式,未对Agent造成影响)
-
P C P_C PC表示causal patterns(因果模式,对Agent造成影响)
-
G G G表示the spatiotemporal environment of scene(时空环境)
-
y y y表示predicting future behavior(预测未来的行为)
3、Methodology
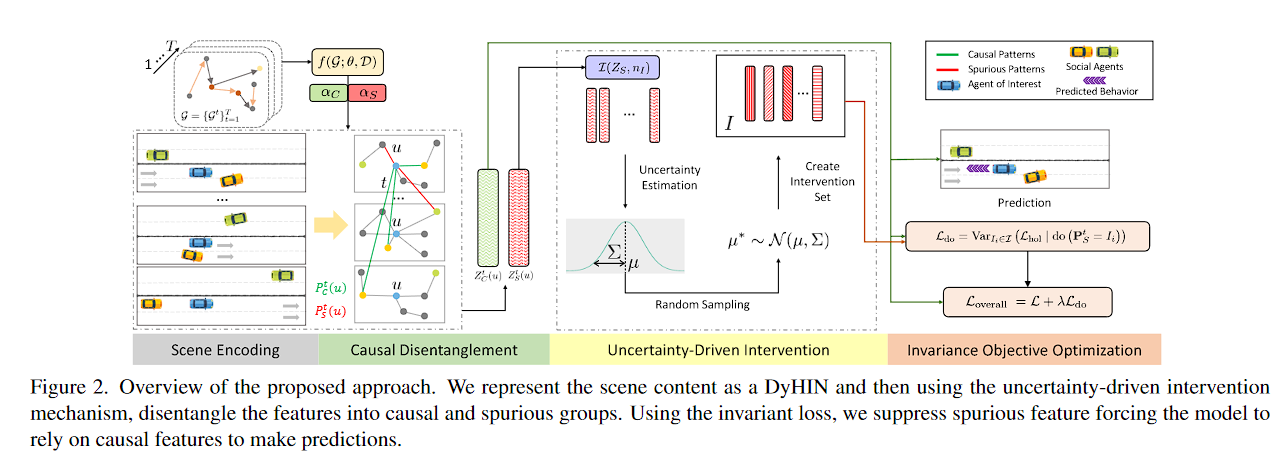
图 2. 所提议方法的概述。我们将场景内容表示为 DyHIN,然后使用不确定性驱动的干预机制,将这些特征分解为因果组和虚假组。使用不变损失,我们抑制虚假特征,迫使模型依赖因果特征进行预测。
DyHIN主要包含四个部分,具体如下
场景编码(Scene Encoding):
- DyHIN 被定义为一个动态图 G = { G t } t = 1 T G=\{G_t\}^T_{t=1} G={Gt}t=1T,其中 T T T 是时间戳的数量,每个时间戳 t t t的异构图切片 G t = ( V t , E t ) G_t=(V_t,E_t) Gt=(Vt,Et)由节点集合 V V V 和边集合 E E E 组成。图 G G G 包括节点和变的映射
因果解耦(Causal Disentanglement):
- P C ( u ) P_C(u) PC(u)表示因果模式和 P S ( u ) P_S(u) PS(u)表示伪因果模式, P C t ( u ) P_C^t(u) PCt(u)表示在第 t t t时间戳的内容
- u u u 表示场景中的交通参与者 A g e n t Agent Agent, α C \alpha C αC和 α S \alpha S αS表示的是注意力机制
- 解耦后的特征被分成两组,绿色表示因果特征 Z C t ( u ) Z_C^t(u) ZCt(u),红色表示伪因果特征 Z S t ( u ) Z_S^t(u) ZSt(u)。

不过这个最后一步的 Z ( u ) t ← Z C t ( u ) + Z S t ( u ) Z(u)^t \leftarrow Z^t_C(u)+Z^t_S(u) Z(u)t←ZCt(u)+ZSt(u)按照论文里的描述是聚合成 Z ( u ) Z(u) Z(u)再输入后续层,但是后续好像并没使用到 Z ( u ) Z(u) Z(u)
不确定性驱动的干预(Uncertainty-Driven Intervention):
- 使用不确定性估计模块 I ( Z S , n I ) I(Z_S,n_I) I(ZS,nI) 来估计伪因果特征中的不确定性。
- 根据估计的不确定性,通过采样获得干预集 μ ∗ ∼ N ( μ , Σ ) μ^∗∼N(μ,Σ) μ∗∼N(μ,Σ),
预测(Prediction):
- 干预后的特征被输入预测模型,生成对目标车辆(蓝色)的未来行为预测。
- 预测输出被用来计算损失函数 L d o L_{do} Ldo。
不变性目标优化(Invariance Objective Optimization):
- 通过计算不变性损失 L d o L_{do} Ldo 和总体损失 L o v e r a l l L_{overall} Loverall,压制伪因果特征的影响,增强模型对因果特征的依赖。
- L d o L_{do} Ldo 表示在干预下的因果损失,公式为: L d o = V a r I i ∈ X ( L h o l ∣ d o ( P S t = I i ) ) L_{do}=Var_{I_i}∈X(L_{hol}∣do(P^t_S=I_i)) Ldo=VarIi∈X(Lhol∣do(PSt=Ii))这里 LchlL_{chl}Lchl 是变化后的损失, X \mathcal{X} X 是输入特征集。
- 总体损失 L o v e r a l l L_{overall} Loverall为: L o v e r a l l = L + λ L d o L_{overall}=L+λL_{do} Loverall=L+λLdo 其中 LLL 是原始预测损失, λ\lambdaλ 是调节参数,用于平衡两部分损失的权重。

4、Datasets
We evaluate our method on two large-scale motion forecasting datasets including Argoverse-2 (AGV2) [9] and Waymo Open Motion Dataset (WOMD) [53]. AGV2 contains 250K scenarios split into 200K, 25K, and 25K samples for training, validation, and testing, respectively. The task is to make 6s predictions based on 5s observations. WOMD consists of 487K training scenes and validation and testing set each with 44K scenes. Here, the objective is to predict 8s into the future based on 1s observation.
我们在两个大型运动预测数据集上评估我们的方法,包括 Argoverse-2 (AGV2) [9] 和 Waymo 开放运动数据集 (WOMD) [53]。 AGV2 包含 250K 个场景,分为 200K、25K 和 25K 样本,分别用于训练、验证和测试。任务是根据 5s 的观察结果进行 6s 的预测。 WOMD 由 487K 训练场景以及验证和测试集组成,每个场景都有 44K 场景。这里,目标是根据 1 秒的观察来预测未来 8 秒的情况。
4、Experiments
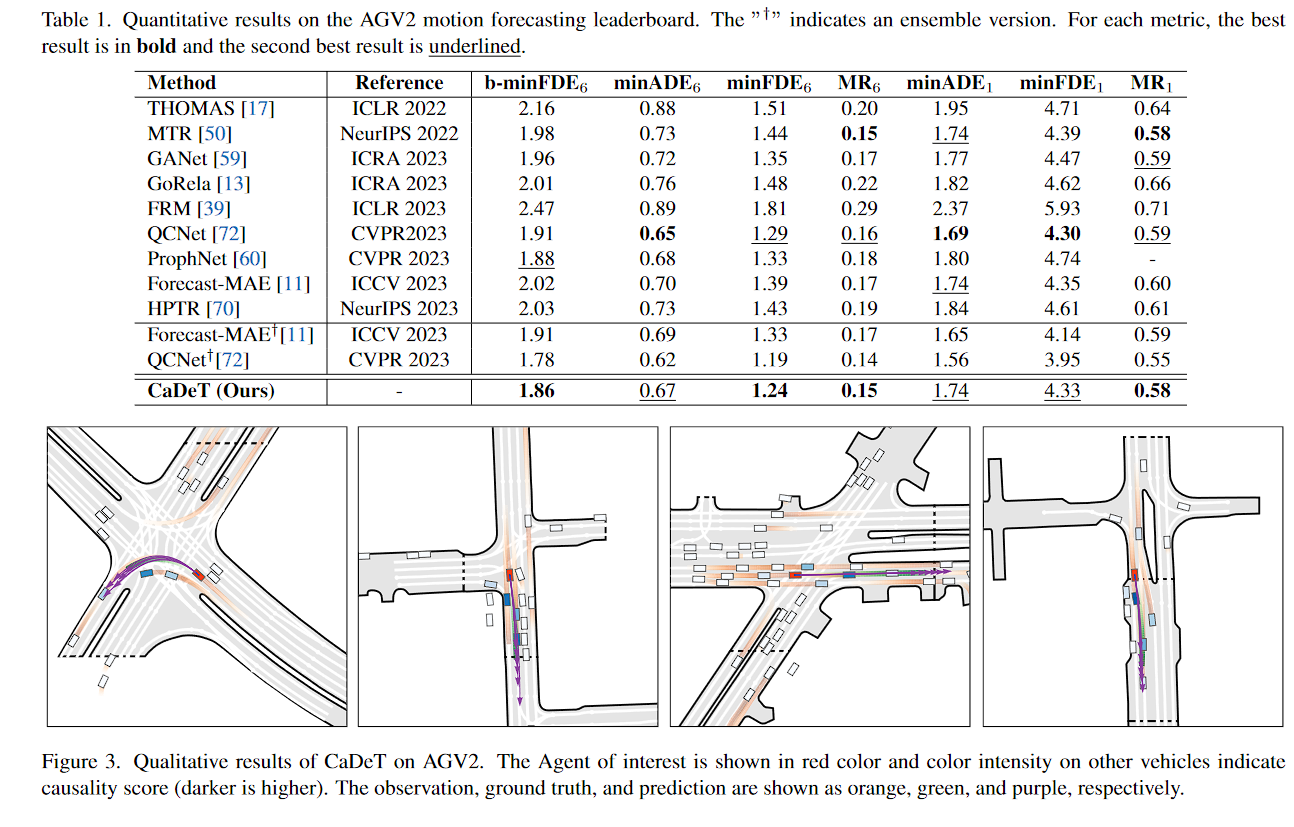
图 3. AGV2 上 CaDeT 的定性结果。感兴趣的代理以红色显示,其他车辆上的颜色强度表示因果分数(颜色越深越高)。观察、真实情况和预测分别显示为橙色、绿色和紫色。
5、Conclusion
We proposed a novel causal disentanglement approach in which we formulated both the spatial and temporal relations in the scenes through spatiotemporal patterns and used a causal disentanglement approach to separate causal and spurious factors. We proposed an intervention mechanism to simulate the potential distribution shifts at inference time by generating multiple intervened distributions based on spurious factors in the latent space using feature statistics, hence, maintaining the realism of interventions. Lastly, we proposed an invariance training objective to leverage causal factors and intervened distributions to induce the model to focus on causal relations. As a result, the influence of spurious correlations are mitigated making the model more robust against distribution shifts during inference time. We conducted extensive empirical studies on two large-scale autonomous driving datasets and demonstrated that our approach not only achieves state-of-the-art performance but also significantly improves upon prediction robustness against various distribution shifts.
我们提出了一种新颖的因果解开方法,通过时空模式制定场景中的空间和时间关系,并使用因果解开方法来分离因果因素和虚假因素。我们提出了一种干预机制,通过使用特征统计基于潜在空间中的虚假因素生成多个干预分布来模拟推理时的潜在分布变化,从而保持干预的真实性。最后,我们提出了一个不变性训练目标,以利用因果因素和干预分布来诱导模型关注因果关系。因此,虚假相关性的影响得到减轻,使模型在推理时间内对分布变化更加稳健。我们对两个大规模自动驾驶数据集进行了广泛的实证研究,并证明我们的方法不仅实现了最先进的性能,而且还显着提高了针对各种分布变化的预测鲁棒性。
参考
-
https://github.com/amusi/CVPR2024-Papers-with-Code?tab=readme-ov-file#Autonomous-Driving
-
https://public.tableau.com/views/CVPR2024/CVPRtrends?:showVizHome=no
-
https://github.com/colorfulfuture/Awesome-Trajectory-Motion-Prediction-Papers


















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









