







在第5节中,我们创建了一个来自🤗 Datasets仓库的GitHub问题和评论数据集。本节我们将使用这些信息构建一个搜索引擎,帮助我们找到关于库的最紧迫问题的答案!
利用嵌入进行语义搜索
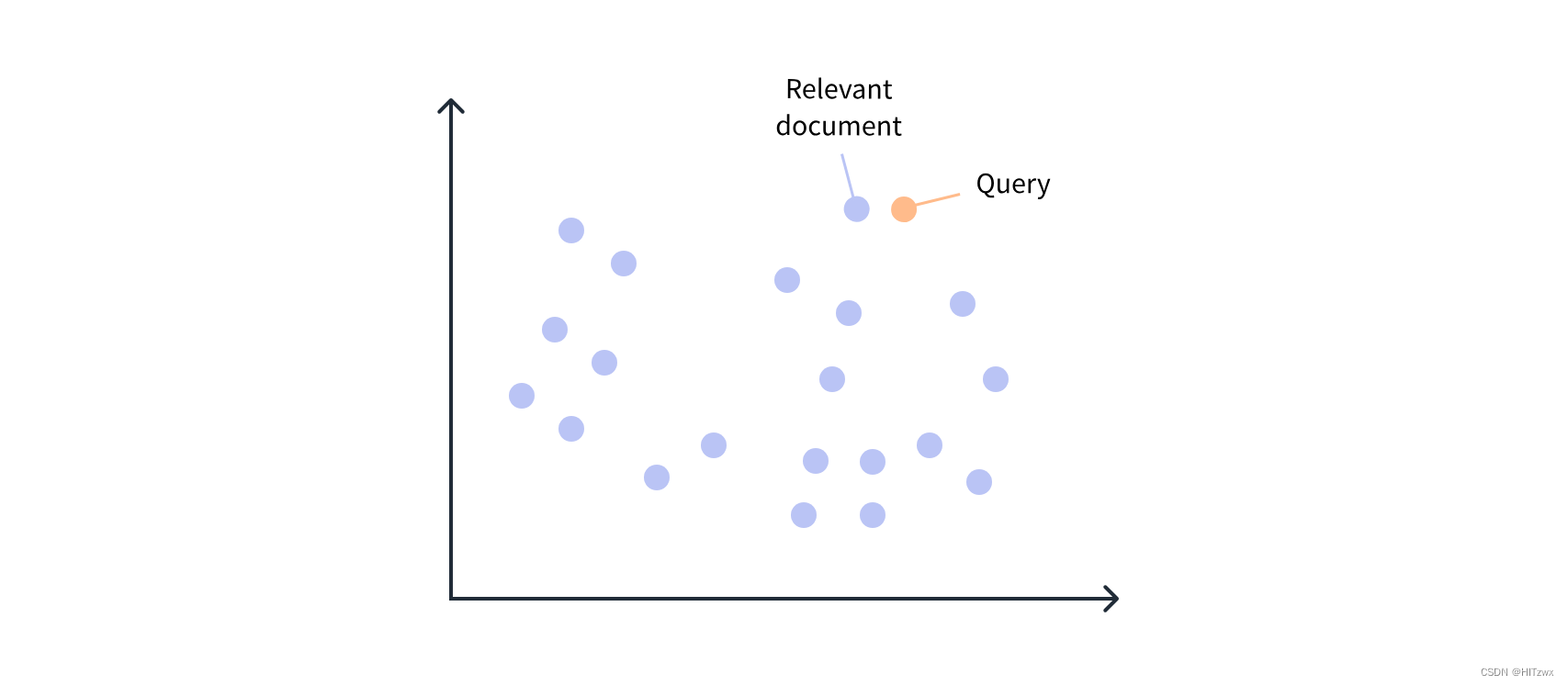
如第1章所述,基于Transformer的语言模型将文本中的每个令牌表示为一个嵌入向量。实际上,我们可以将单个嵌入向量“聚合”为整个句子、段落或(在某些情况下)文档的向量表示。然后,可以通过计算每个嵌入向量与语料库中其他向量的点积相似度(或其他相似度度量)来找到相似的文档。
在本节中,我们将使用嵌入来开发一个语义搜索引擎。这些搜索引擎相比基于查询关键词匹配的传统方法,具有多方面的优势。
加载和准备数据集
首先,我们需要下载GitHub问题数据集,我们可以像往常一样使用load_dataset()函数:
from datasets import load_dataset
issues_dataset = load_dataset("lewtun/github-issues", split="train")
issues_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})
在这里,我们指定了默认的train拆分,所以它返回一个Dataset而不是DatasetDict。首先,我们需要过滤掉拉取请求,因为它们通常很少用于回答用户查询,并且会引入搜索引擎中的噪声。我们可以使用Dataset.filter()函数来排除这些行:
issues_dataset = issues_dataset.filter(
lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
)
issues_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











