







💥《DeepSeek》:
正需要AI帮忙整理会议纪要,却遇到服务器排队提示;或是赶着生成代码时突然卡顿,眼睁睁看着灵感溜走。其实这类问题完全可以通过本地部署解决——就像把常用的办公软件装进电脑一样,让AI真正成为随时待命的智能助手。
经过三天的实际测试,经历了各种踩坑后,给大家推荐几种比较实用的部署方案。
本文将手把手拆解成功率98%的极简路线——让你在23分钟内完成从‘安装焦虑’到‘丝滑推理’的阶级跃迁!

目录
方法一:DS安装助手极速部署(懒人专用)
首推的是「DS安装助手」这类工具,确实能大幅降低部署门槛,不用折腾环境配置,自动搞定所有依赖项。
整个过程只需三步:下载安装包、选择模型版本(建议新手选7B基础版)、点击安装按钮,20分钟内就能完成部署。日常问答响应速度稳定在3秒以内,且完全不用担心对话记录外传。
(👉 使用流程:)
1️⃣ 安装包下载
下载后直接点击快速安装即可,下载链接如下:
https://file-cdn-deepseek.fanqiesoft.cn/deepseek/deepseek_28348_st.exe
2️⃣ 选择模型与下载路径
建议下载路径不要放在c盘,之后点击立即安装。
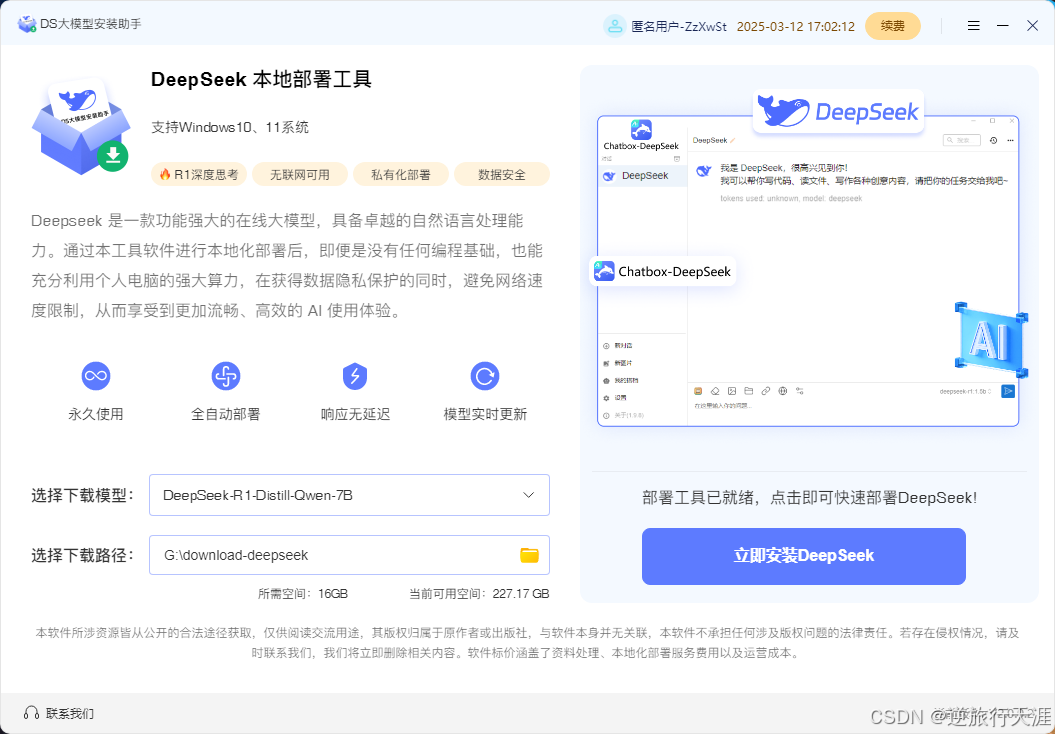
系统会自动进行安装所需的模型和可视化软件,等待安装完成即可。
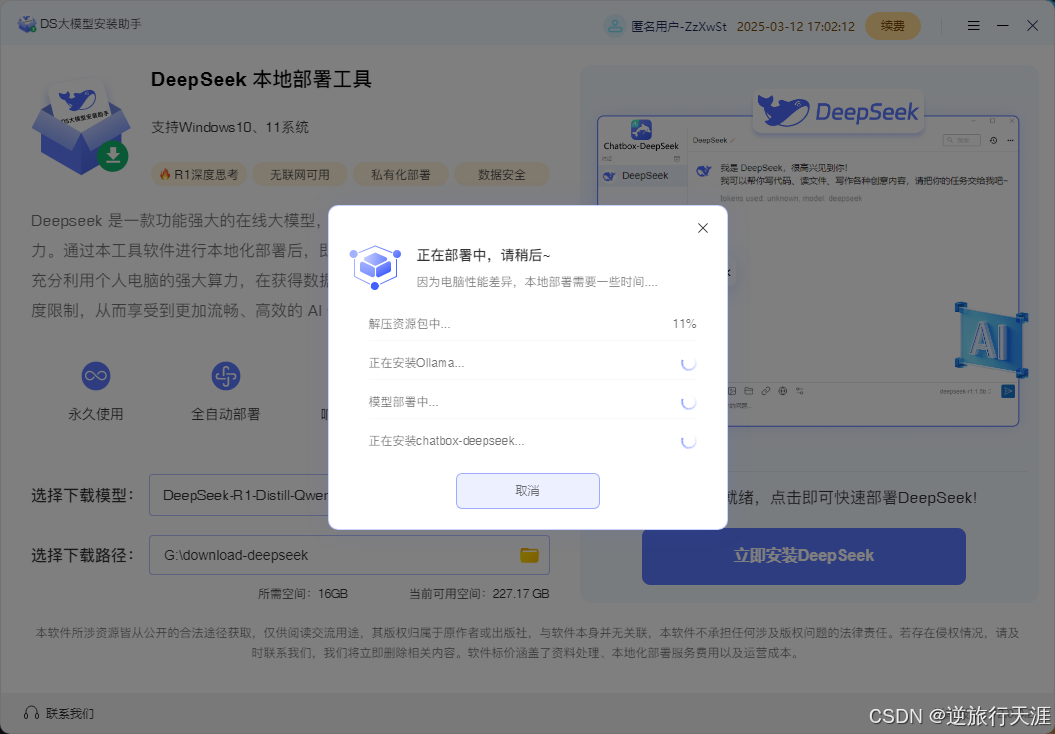
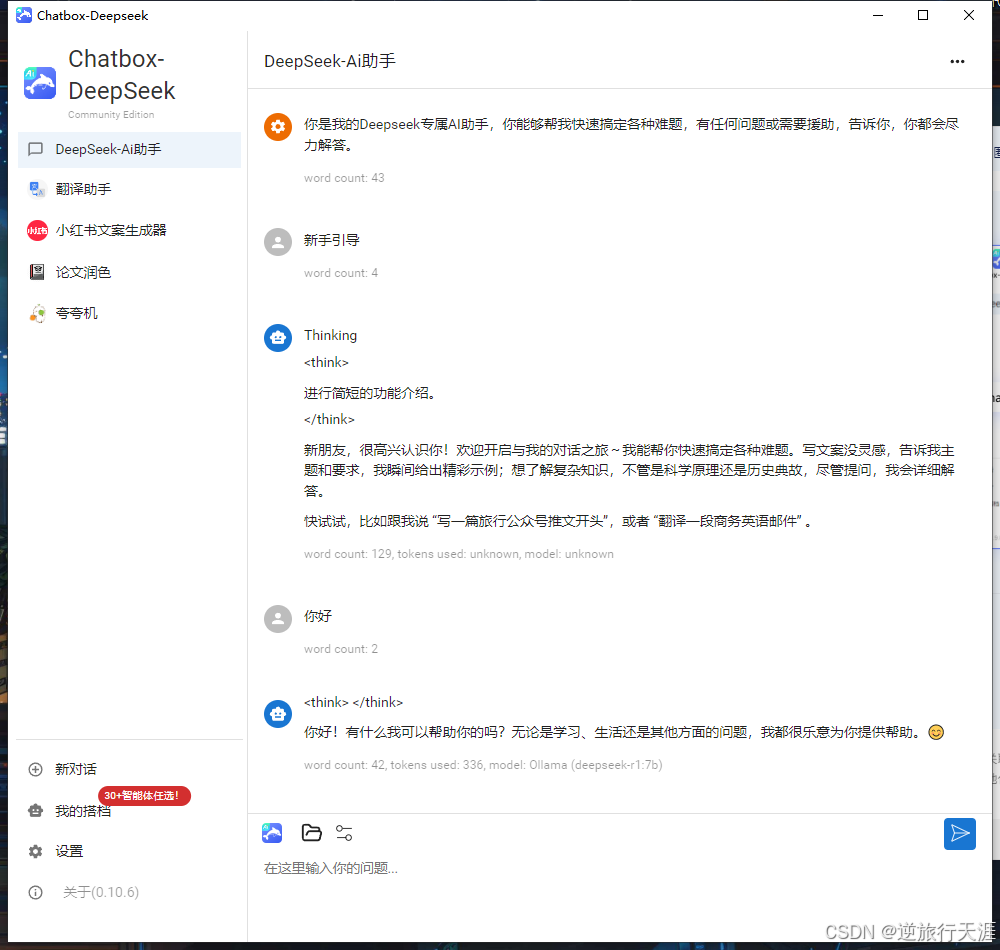
3️⃣ 安装完成
方法二:LM Studio部署DeepSeek实测
1️⃣安装LM Studio软件
1.根据你的电脑系统下载相应安装包
👉 LM Studio - Discover, download, and run local LLMs

2.下载后按照流程步骤安装,建议不要安装在c盘,安装后页面如下

3.刚开始为英文,点击右下角设置,语言可以调整为中文

2️⃣ 模型下载
1.点击我的模型,点击搜索按钮,可以在线安装开源模型(需要魔法,下载速度慢)

2.如果无法从这里安装也不要慌,可以从其他地方先下载好模型,之后导入进行使用。
👉 模型下载地址:魔搭社区
依据你的电脑性能下载模型14B、32B,性能差点选7B

点击模型文件,依据你的电脑性能任选一个下载

3️⃣ 模型导入
新建一个文件夹,比如我在G盘新建个DeepSeek文件夹,文件夹下再新建models文件夹,将我们下载的模型文件放到models文件夹下
将模型目录这里的地址调整为G:DeepSeek(创建的文件夹地址)


点击聊天,选择刚下载的模型

依据你的电脑性能自行调节,拉的高效果好,但会卡顿

加载模型后便可以本地使用了。
方法三:Ollama + Chatbox 部署
1️⃣ 安装Ollama
Olama是一个开源工具,用于在本地轻松运行和部署大型语言模型。安装流程如下:
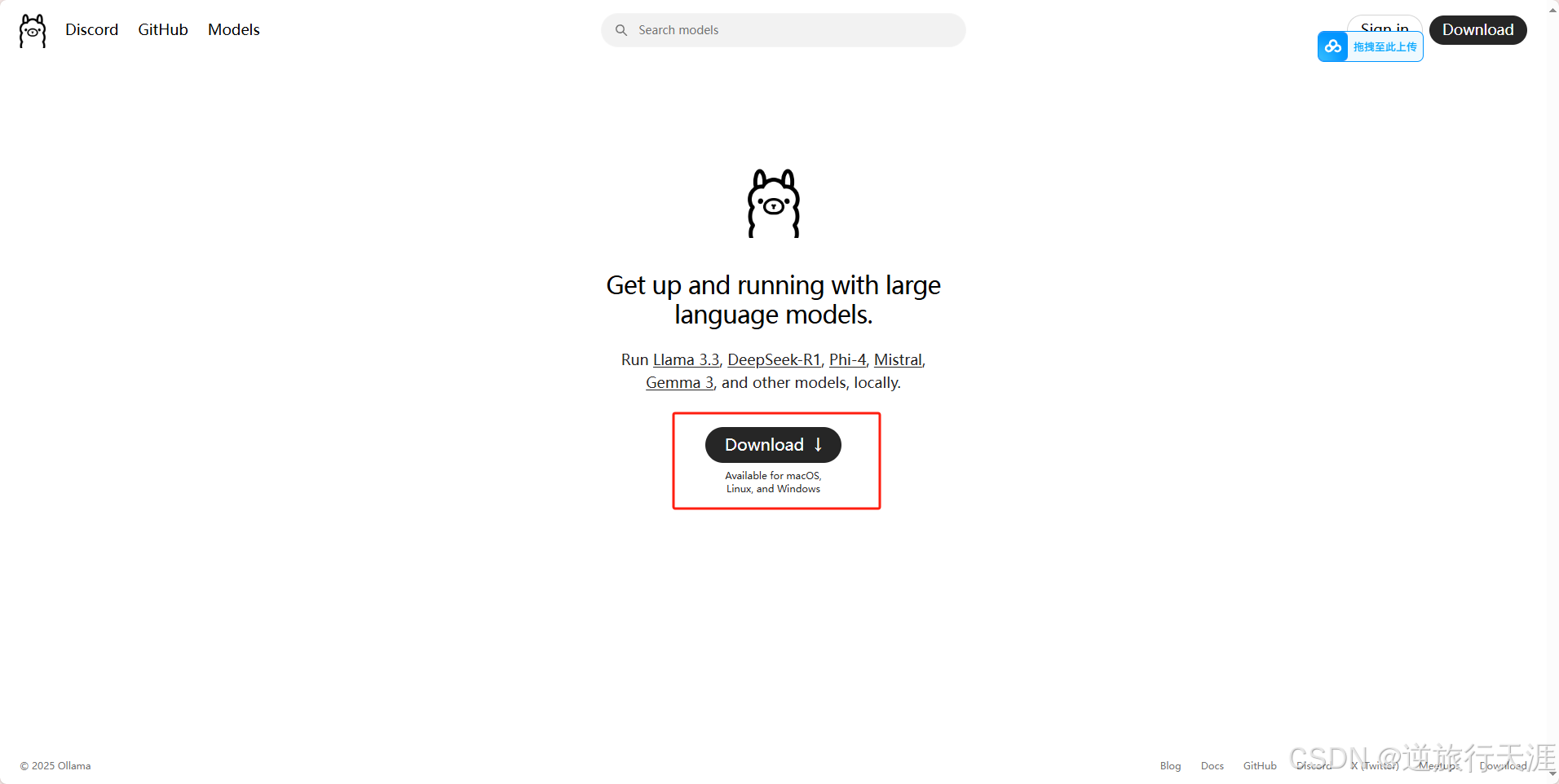
👉下载链接:
1.进入官网选择Download。
2、Ollama配置环境变量
Win10或Win11可以直接搜索“环境变量”,下图搜索,打开“编辑系统环境变量”设置:
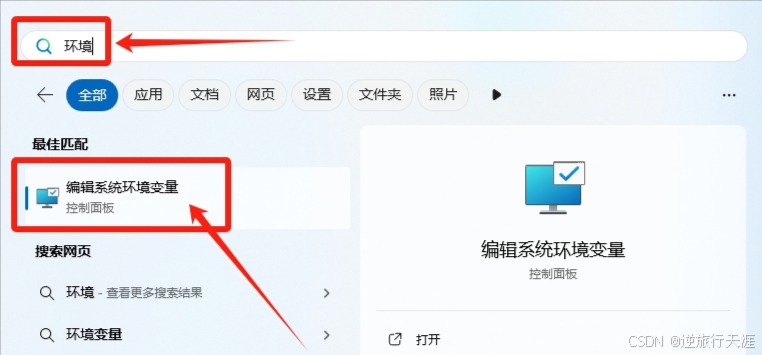
具体配置环境变量解释如下图:

2️⃣ 下载并部署DeepSeek模型
1. 去Ollama官网点击Models进入模型选择:
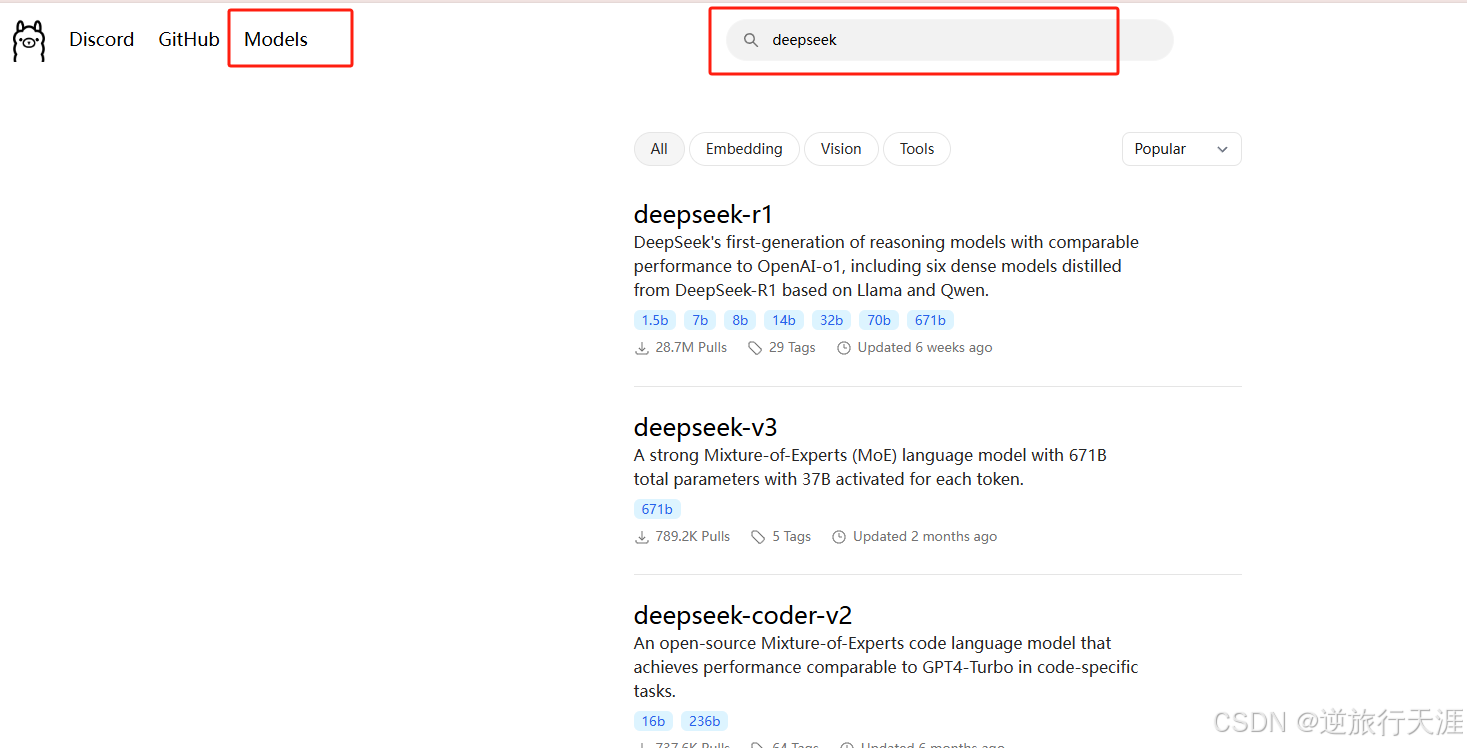
Ollama支持多种DeepSeek模型版本,用户可以根据硬件配置选择合适的模型。
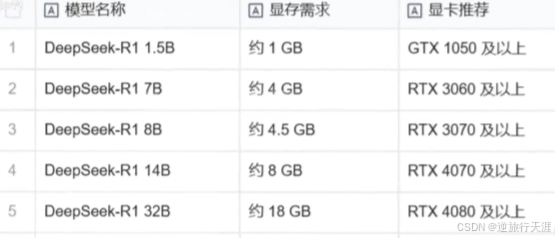
入门级:1.5B版本,适合初步测试。
中端:7B或8B版本,适合大多数消费级GPU
高性能:14B、32B或70B版本,适合高端GPU。
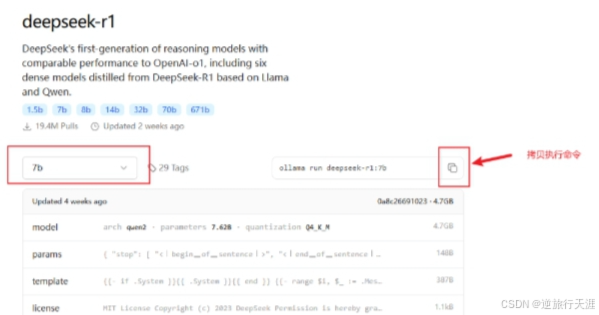
2.在终端运行以下命令启动Ollama服务:
3️⃣ 下载可视化交互界面 Chatbox
虽然我们可以在本地正常使用 Deepseek 这个模型了,但是这个 AI 工具的面板是非常简陋的,很多人使用不习惯,这时我们就可以通过 Chatbox 这个可视化图文交互界面来使用它。
👉
进入 Chatbox 官网,Chatbox 虽然有本地客户端,但我们也可以直接使用网页版。
进入 Chatbox 网页版本后点击使用自己的 API Key 或本地模型。
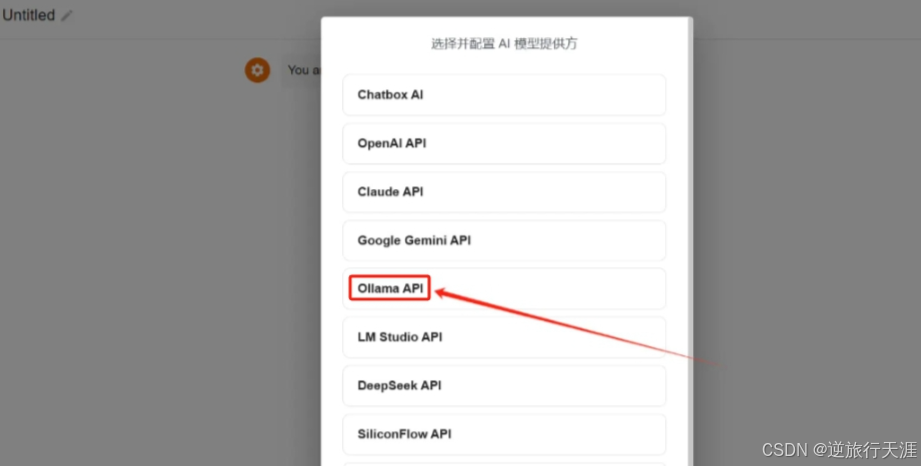
点击后会进入模型提供方选择界面,这里选择 Ollama API 。
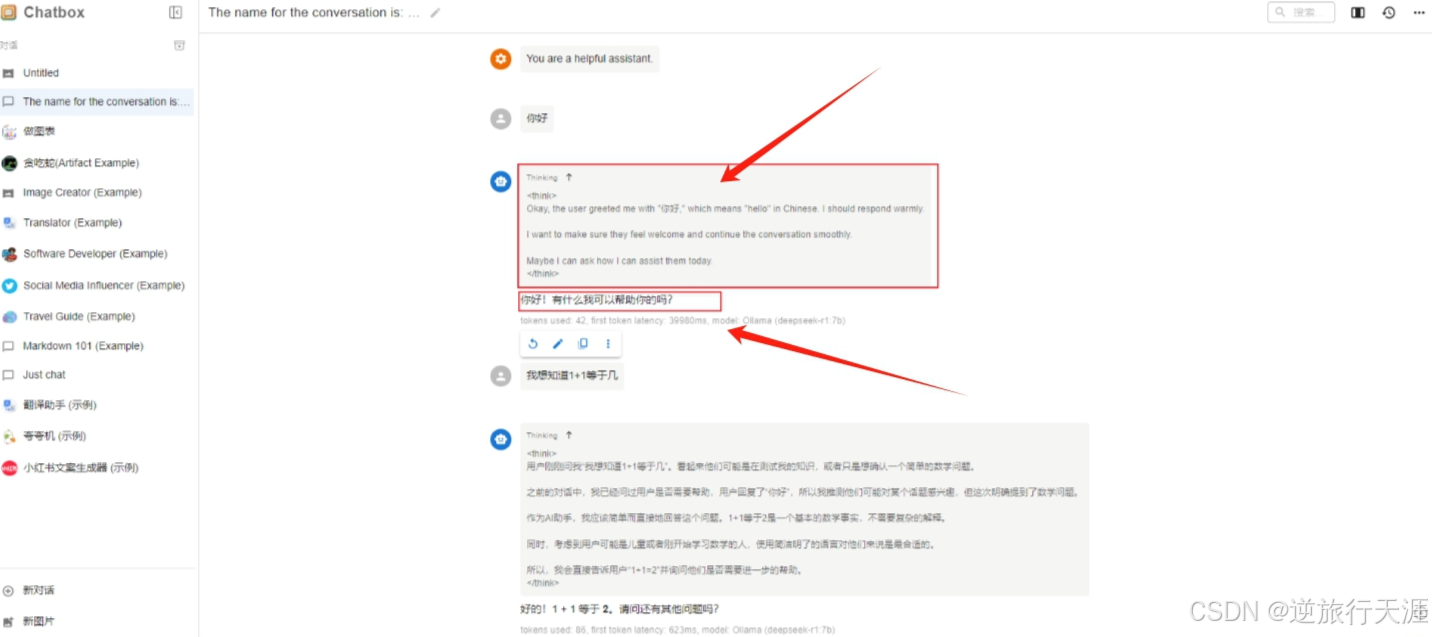
接下来只需要在 Chatbox 中新建对话即可使用 Deepseek 模型了,以下图为例,上方是它的思考过程,下方是它给出的答案。
方法四:硅基流动调用API使用
上述本地化部署方案虽然能有效规避服务器拥堵问题,但对硬件性能要求较高,普通用户若使用5年前的主流配置(如i5-8代+8GB内存),运行7B参数模型时仍可能面临10秒以上的响应延迟。
为此我们更推荐以下轻量化API调用方案,兼顾使用效率与设备兼容性:
1️⃣ API申请
我们首先需要在硅基流动申请一个账号,注册后可以直接获取2000万免费tokens,新增我们的秘钥用于后续使用,申请方法如下。
账号登录地址:

点击秘钥,选择新建秘钥,便可以获得自己的秘钥。记住自己的秘钥,在之后需要使用。

2️⃣ 下载Cherry Studio (API调用)
1.进入网址Cherry Studio - 全能的AI助手选择立即下载

2.安装时位置建议放在其他盘,不要放c盘

3.进入软件后,如果你的语言是英文的,可以选择设置,在常规设置这里调整语言。

4.选择设置,选择模型服务,输入你的API秘钥,点击检查即可。

5.向下拉选择管理按钮,在嵌入勾选最后一个(知识库要用到),全部里也可以选择你要用的模型。

6.之后就可以在聊天中进行使用

3️⃣ 知识库使用方法
1.添加一个新的知识库

2.在知识库可以上传你的文件

3.在聊天对话页面勾选知识库,便可以根据知识库内容回答问题



















 140
140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









