







在第五讲中我们学习了GPU三个重要的基础并行算法: Reduce, Scan 和 Histogram,分析了 其作用与串并行实现方法。 在第六讲中,本文以冒泡排序 Bubble Sort、归并排序 Merge Sort 和排序网络中的双调排序 Bitonic Sort 为例, 讲解如何从数据结构课上学的串行并行排序方法转换到并行排序,并附GPU实现代码。
在并行方法中,我们将考虑到并行方法需要注意的特点进行设计,希望大家在读完本文后对GPU上并行算法的设计有一些粗浅的认识。需注意的特点如下:
1. 充分发挥硬件能力(尽量不要有空闲且一直处于等待状态的SM)
2. 限制branch divergence(见CUDA系列学习(二))
3. 尽量保证内存集中访问(即防止不命中)
( 而我们在数据结构课上学习的sort算法往往不注意这几点。)
CUDA系列学习目录:
CUDA系列学习(一)An Introduction to GPU and CUDA
CUDA系列学习(二)CUDA memory & variables - different memory and variable types
CUDA系列学习(三)GPU设计与结构QA & coding练习
CUDA系列学习(四)Parallel Task类型 与 Memory Allocation
CUDA系列学习(五)GPU基础算法: Reduce, Scan, Histogram
I. Bubble Sort
冒泡排序,相信大家再熟悉不过了。经典冒泡排序通过n轮有序冒泡(n为待排序的数组长度)得到有序序列, 其空间复杂度O(1), 时间复杂度O(n^2)。
那么如何将冒泡排序算法改成并行算法呢? 这里就需要解除一些依赖关系, 比如是否能解除n轮冒泡间的串行依赖 & 是否能解除每一轮冒泡内部的串行依赖, 使得同样的n^2次冒泡操作可以通过并行, 降低step complexity。
1996年, J Kornerup针对这些问题提出了odd-even sort算法,并在论文中证明了其排序正确性。
I.1 从Bubble Sort到Odd-even Sort
先来看一下odd-even sort的排序方法:

图1.1
上图为odd-even sort的基本方法。
奇数步中, array中奇数项array[i]与右边的item(array[i + 1])比较;
偶数步中, array中奇数项array[i]与左边的item(array[i - 1]) 比较;
这样,同一个step中的各个相邻比较就可以并行化了。
PS: 对于array中有偶数个元素的数组也是一样:
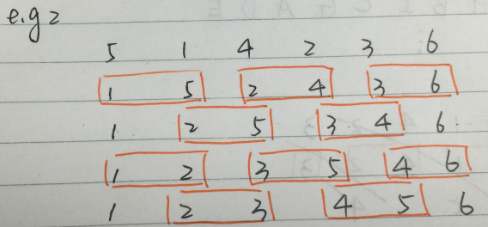
图1.2
I.2 Odd-even Sort复杂度
在odd-even sort的算法下, 原本O(n^2)的总比较次数不变,但是由于并行,时间复杂度降到O(n), 即
step complexity = O(n)
work complexity = O(n^2)
code详见 < Bubble sort and its variants >
II. Merge Sort
看过odd-even sort后,我们来看如何将归并排序并行化。数据结构课上我们都学过经典归并排序: 基于divide & conquer 思想, 每次将一个array分拆成两部分, 分别排序后合并两个有序序列。 可以通过 T(n)=2T(n/2)+n 得到, 其complexity = O(nlogn)。 和I.1节类似, 我们看看merge sort中的哪些步是可以并行的。
这里可以将基于merge sort的大规模数据排序分为三部分。 经过divide步之后, 数据分布如图所示:
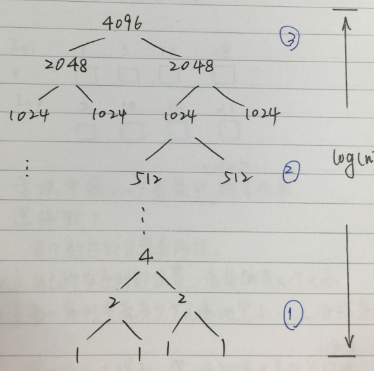
图2.1
最下端的为 大量-短序列 的合并;
中间一块为中等数量-中等长度序列 的合并;
最上端的为少量-长序列 的合并;
我们分这三部分进行并行化。 之后大家会明白为啥要这么分~<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









