







预测分析
DCB产品的稳定性会受到多个因素的影响,如地磁或太阳活动、卫星零均值基准变化等,这些影响会导致DCB的部分缺失或偏差,若在这些情况下,能够对DCB值进行短期预报,那么便会有效解决用户对于DCB产品及时性的需求,也会保证DCB数值的完整性。(HAN Xueli, 2017)利用ARIMA模型,实现不同太阳活动水平下BDS卫星DCB的短期预报,结果表明,ARIMA预测效果好于多项式拟合的预测结果。(梅登奎, 2020)采用二次多项式拟合方法,对GPS、GLONASS和BDS的DCB进行长短期预报,结果显示,利用二次多项式方法可以较好地预报GPS卫星频间偏差的长期及短期数据,对于GLONASS卫星及BDS卫星的频间偏差求值及预报也具有重要的参考作用。上述研究已经得到较好的结果,但要么是针对传统信号进行预报,要么是缺少对其他卫星系统的预报分析。因此,可以利用GM(1,1)和ARIMA方法来对GNSS的四大卫星的新信号DCB进行预报。
预测效果
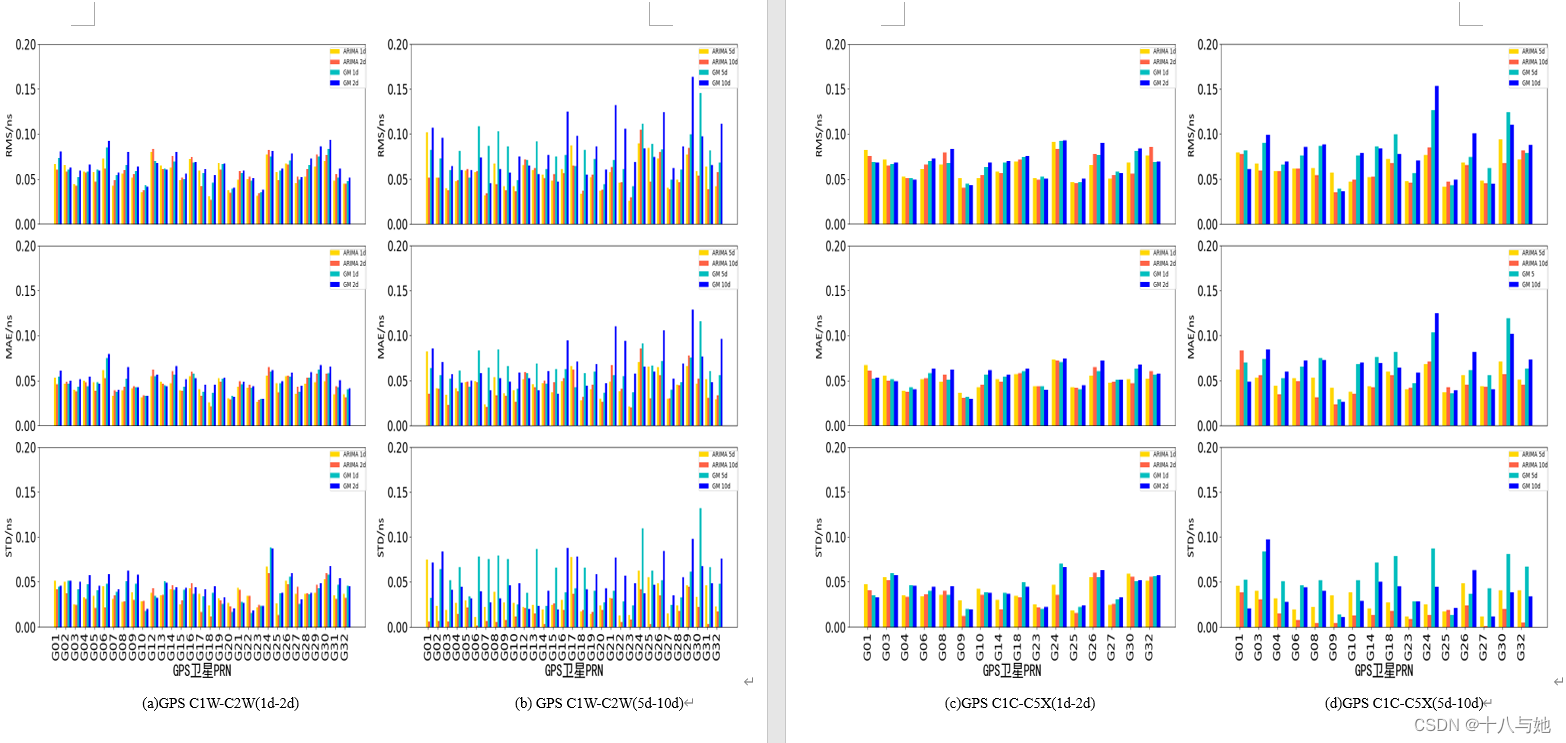
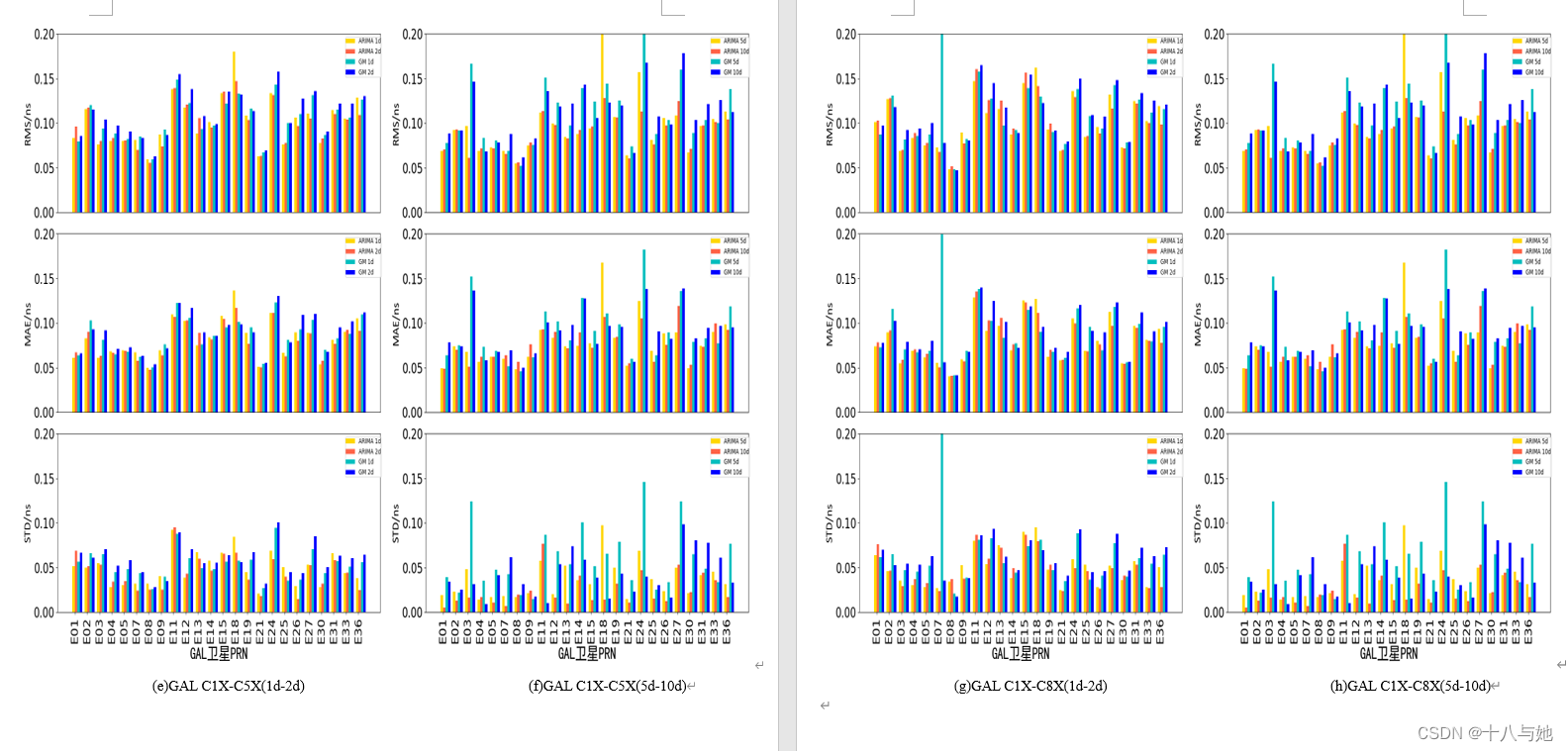
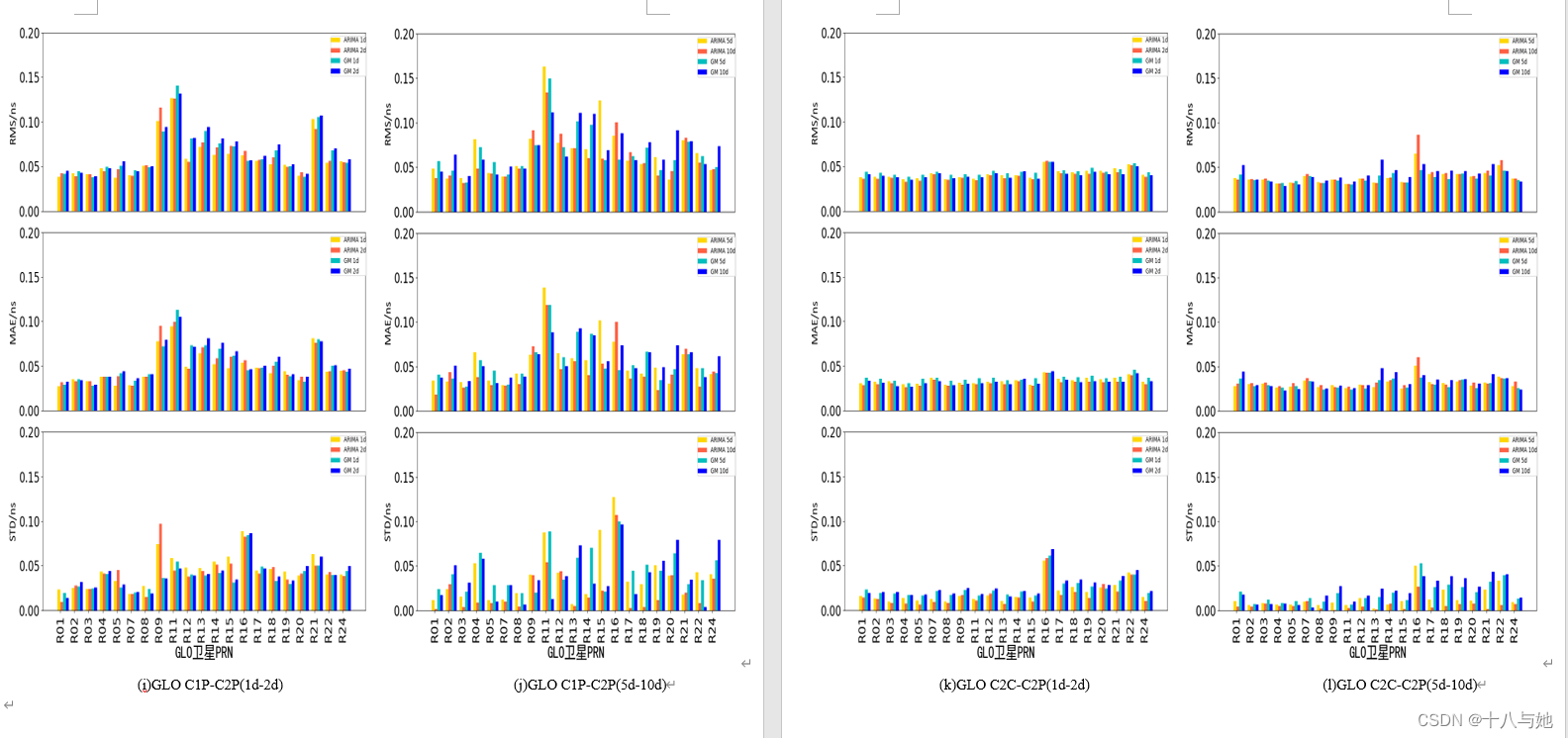
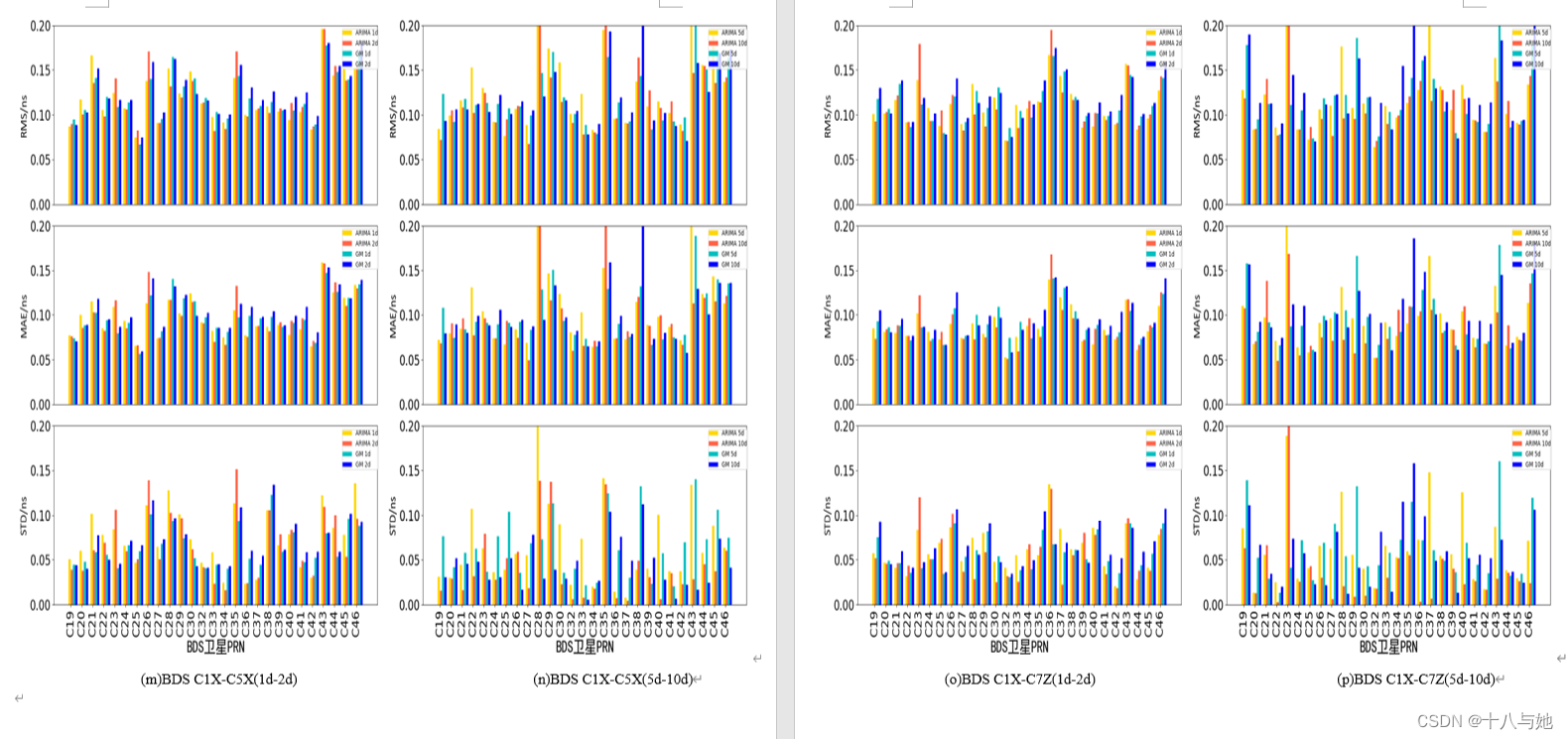
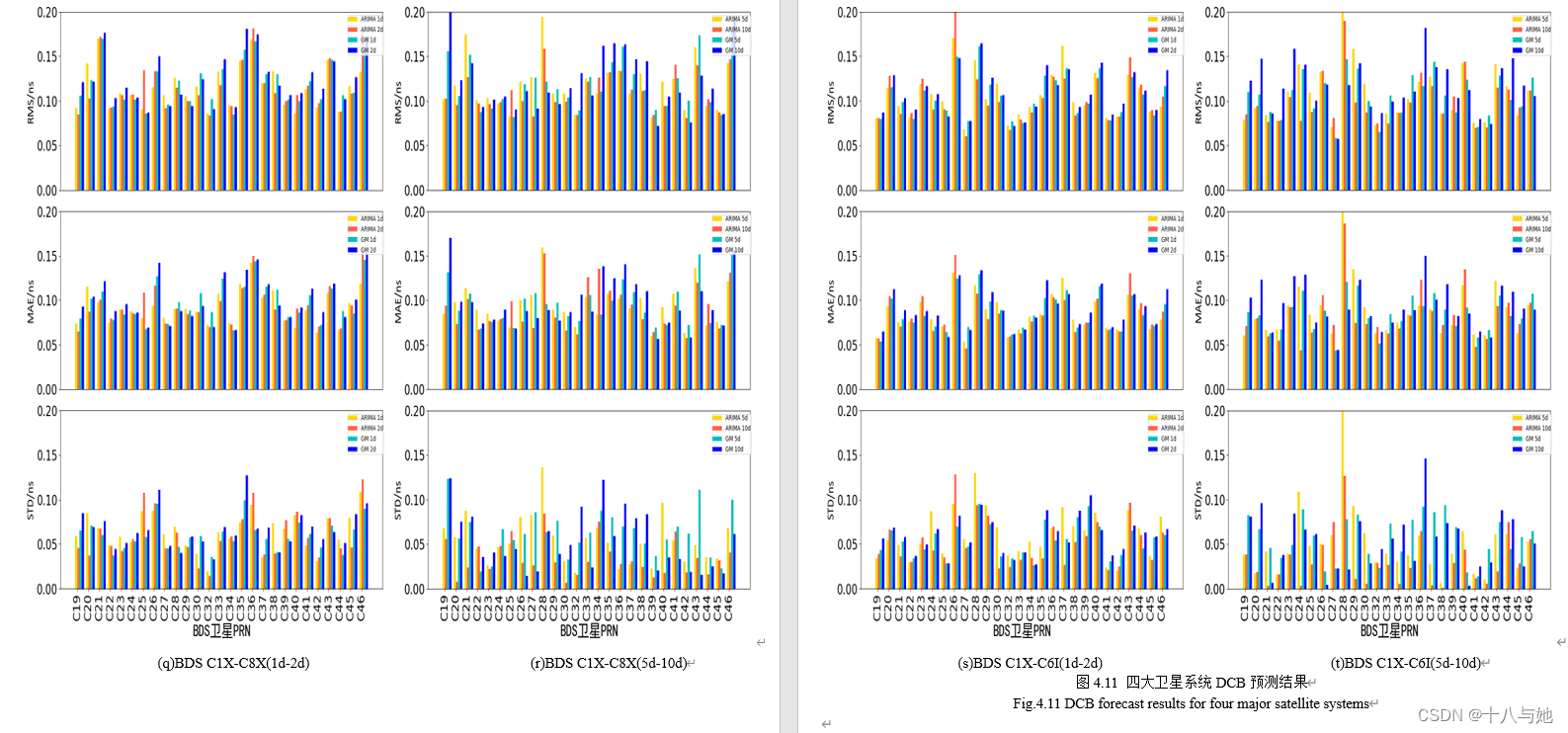
预测结论
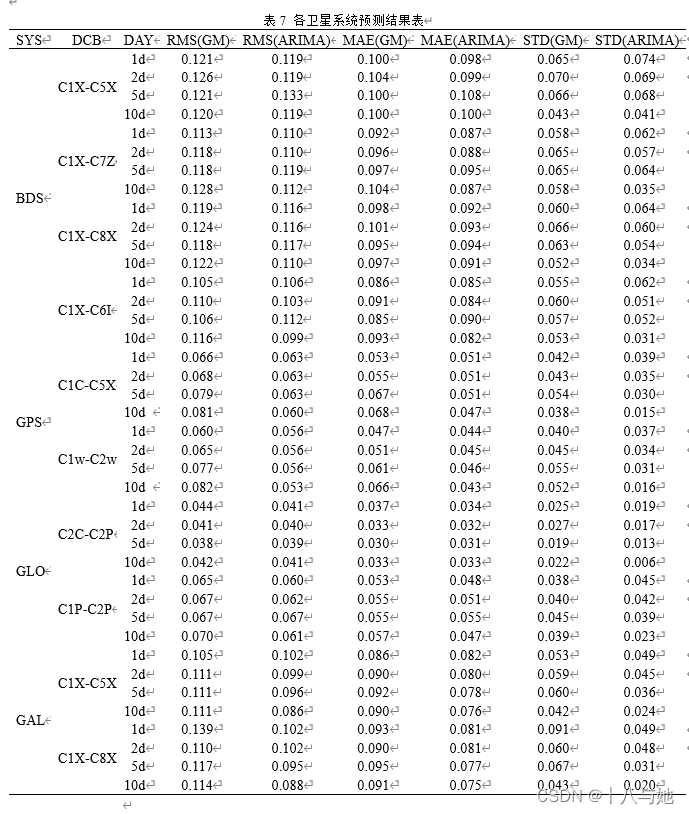
从图4.11可以看出,对于预测精度来说,GLONASS的DCB的效果最好,两种预测方法的RMS均在0.040.06ns之间,MAE在0.030.05ns之间,STD在0.020.04ns之间,说明利用两种预测方法对GLONASS的DCB产品进行短期预报具有很高的精度和很好的稳定性;GPS的预测精度和稳定性次之,RMS在0.06ns左右,MAE处于0.040.05ns左右,STD在0.04ns附近;BDS和GAL的预测精度相当,但GAL短期预报的稳定性优于BDS。
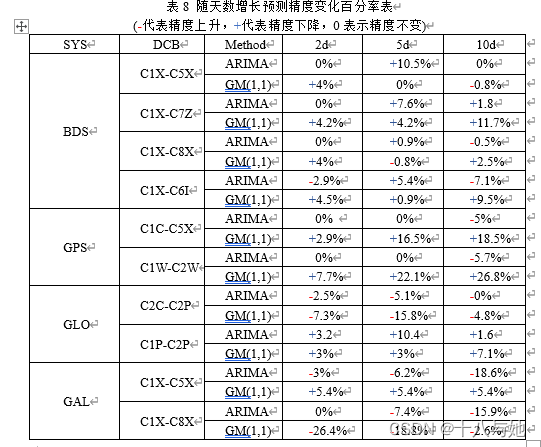
结合表7、8的平均精度统计情况,可以直观地看出:ARIMA的预测精度和稳定性优于GM(1,1)方法,精度和稳定性分别提升约11.2%和45.6%;对于ARIMA预测方法来说,随着一次预测天数的增加,GPS和Galileo的DCB平均预测精度呈现上升趋势,BDS和GLONASS的DCB平均预测精度和DCB类型有关,精度有升有降,且以上情况平均数值变化均不明显,但是预测的稳定性会显著提高,这与一次预测的数据越多,预测的结果就会越有关联性,从而数值之间更加稳定的原因有关;对于GM(1,1)预测方法来说,随着一次预测天数的增加,BDS和GPS的DCB平均预测精度总体呈现下降趋势,GLONASS和Galileo的DCB预测精度和DCB类型有关,精度有升有降,且以上情况数值变化较ARIMA方法明显,GPS的DCB产品随着预测天数的增加,预测稳定性降低;GLONASS的DCB产品随着预测天数的增加,预测稳定性提高;GPS和Galileo的DCB产品的预测稳定性没有较明显变化。
图4.12-图4.15展示了ARIMA与GM(1,1)两方法对各系统的各DCB类型的预测精度随一次预测天数变化的曲线图。对于BDS的DCB预测效果来说,DCB精度没有规律性的变化趋势,要具体的DCB类型具体分析,选择出针对该类型来说,最适合的一次预测天数;对于GPS的DCB预测效果来说,ARIMA方法要好于GM(1,1),两者对比在此处最为明显;对于Galileo和GLONASS的DCB预测来说,预测精度的数值变化较为平缓且具有规律,体现为在某一数值范围内的上下波动。
GM(1,1)源码
# -*- coding: utf-8 -*-
"""
Created on April 1 19:23:24 2021
@author: Xymeng
"""
from pandas import Series
from pandas import DataFrame
import matplotlib.pyplot as plt
import xlrd
import xlsxwriter as xlwt
import openpyxl
import numpy as np
import pandas as pd
import scipy.interpolate as spi
from sklearn.metrics import mean_squared_error
np.set_printoptions(suppress=True) # 取消科学计数法输出
def Identification_Algorithm(x,n): #辨识算法,x表示本次取的数据,n表示滚动窗口大小
B = np.array([[1]*2]*(n-1)) #创建二维数组
tmp = np.nancumsum(x)
for i in range(len(x)-1):
B[i][0] = ( tmp[i] + tmp[i+1] ) * (-1.0) / 2
Y =np.array(x[1:]).T
BT =B.T
a = np.linalg.inv(np.dot(BT,B))
a = np.dot(a,BT)
a = np.dot(a,Y) #二行一列
a = np.array(a).T #一行二列 a[0] a[1]
return a
def step_ratio(data): #计算级比
n = len(data)
flag = 0
# print(n)
ratio = [data[i]/data[i + 1] for i in range(len(data)-1)]
min_la, max_la = min(ratio), max(ratio)
thred_la = [np.exp(-2/(n+2)),np.exp(2/(n+2))]
if min_la > thred_la[0] and max_la < thred_la[-1]:
# print("级比满足要求,可用GM(1,1)模型")
# print('级比为:{}\n'.format(ratio))
flag = 1
else:
# print("级比超过灰色模型的范围")
flag = 0
return flag
def GM_Model(X0,a,tmp): #GM(1,1)模型
A = np.ones(len(X0))
for i in range(len(A)):
A[i] = a[1]/a[0]+(X0[0]-a[1]/a[0])*np.exp(a[0]*(tmp[i]-1)*(-1))
# print ('GM(1,1)模型为:\nX(k) = ',X0[0]-a[1]/a[0],'exp(',-a[0],'(k-1))',a[1]/a[0])
XK = Series(A)
# print ('GM(1,1)模型计算值为:')
# print (XK)
return XK
def Return(XK): #预测值还原
tmp = np.ones(len(XK))
for i in range(len(XK)):
if i == 0:
tmp[i] = XK[i]
else:
tmp[i] = XK[i] - XK[i-1]
X_Return = Series(tmp)
return X_Return
def predi(X0,a,n): #X0表示窗口选取的数据,a表示方程系数,n表示滚动窗口大小
A = a[1] / a[0] + (X0[0] - a[1] / a[0]) * np.exp(a[0] * (n) * (-1))
B = a[1] / a[0] + (X0[0] - a[1] / a[0]) * np.exp(a[0] * (n-1) * (-1))
return A-B
DOY = [a for a in range(92,120)]
if __name__ == '__main__':#函数入口
RMSE1 = []
MRE = []
STD = []
b = 8
l = 0
path = r'E:\MGEX产品\C1X-C8X(E).txt'
with open(path,'r+') as a1:
alldata = a1.readlines()
while l<len(alldata):
alldata0 = alldata[l]
data0 = alldata0[7:(len(alldata0)-2)]
data00 = data0.split(', ')
n = 0
while n<len(data00):
data00[n] = float(data00[n])
n = n + 1
data = pd.array(data00) #生成等间隔点对应的沉降数据,36天
data = data + b
print(data)
err_list = [] #定义残差列表
relative_err = [] #定义相对误差列表
rmse = [] #定义
meanrelativeerr = []
realdata = [] #实际数据
predata = [] #预测数据
data1 = []#存储窗口大小数据
sum = 0 #初始化残差平方和
N = [] #存放n数值
K =np.array( np.arange(1,len(data)+1,1))
n = 10 #最优滚动窗口
for i in range(0, 28 - n): # 向下不停滚动
tmp = np.arange(1, n + 1) # 生成沉降数据序号,长度和滚动窗口大小相同
data1 = data[i:i + n]
flag = step_ratio(data1) # 计算级比
print(flag)
if flag:
a = Identification_Algorithm(data1, n) # 辨识算法
# GM(1,1)模型
XK = GM_Model(data1, a, tmp)
# 预测值还原
X_Return = Return(XK)
X_Compare1 = np.ones(len(data1))
X_Compare2 = np.ones(len(data1))
for p in range(len(data1)):
X_Compare1[p] = data1[p] - X_Return[p] # 残差
X_Compare2[p] = X_Compare1[p] / data1[p] * 100 # 相对误差
# print('原始数据护为:{},预测数据为:{}'.format(data[i + n], predi(data1, a, n)))
predata.append(predi(data1, a, n))
realdata.append(data[i+n])
print(predata)
'''以下为模型检验做准备'''
err = data[i+n] - predi(data1, a, n) # 计算残差
relativeerr = abs(data[i+n] - predi(data1, a, n)) # 计算相对误差
err_list.append(err)
relative_err.append(relativeerr)
meanrelativeerr.append(np.array(relative_err).mean())
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False # 此行代码即为可以显示负号
u = len(realdata)
realdata = pd.array(realdata)-b
predata = pd.array(predata)-b
realdata = list(realdata)
predata = list(predata)
plt.plot(DOY[n:n + u], realdata, 'o-b', label='realDCB')
plt.plot(DOY[n:n + u], predata, 'o-r', label='predicDCB')
plt.grid(linestyle="-.", linewidth=0.25, color='k')
plt.xlabel('DOY')
plt.ylabel('DCB/ns')
plt.xticks(DOY[n:],rotation=45)
RMSE = np.sqrt(mean_squared_error(realdata, predata))
rmse.append(RMSE)
plt.title(label='滚动窗口大小为:{},RMSE为:{}'.format(n, RMSE))
'''
以下是预测值精度表
'''
Compare = {'Realdata': realdata, 'Predata': predata,
'Error': err_list, 'RE': relative_err}
Compare = DataFrame(Compare)
print('预测值精度表')
print(Compare)
plt.legend()
plt.show()
N.append(n)
RMSE1.append(rmse[0])
MRE.append(np.mean(relative_err))
STD.append(np.std(predata))
relative_err = []
predata = []
realdata = []
err_list = []
meanrelativeerr = []
N = []
rmse = []
l = l+1
print('ERMSgm1={}'.format(RMSE1))
print('EMREgm1={}'.format(MRE))
print('Estdgm1={}'.format(STD))
print(len(RMSE1))
print(len(MRE))
print(len(STD))
ARIMA源码
import pandas as pd
import numpy as np
import xlrd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.stats.diagnostic import acorr_ljungbox
from sklearn.metrics import mean_squared_error
from pandas import DataFrame
import warnings
warnings.filterwarnings("ignore")
def ad_test(data): #检查序列平稳性函数
datatest = list(adfuller(data, autolag='AIC'))
print("1. ADF : ",datatest[0])
print("2. P-Value : ", datatest[1])
print("3. Num Of Lags : ", datatest[2])
print("4. Num Of Observations Used For ADF Regression:", datatest[3])
print("5. Critical Values :")
for key, val in datatest[4].items():
print("\t", key, ": ", val)
DOY = [a for a in range(92,120)]
N = []
rmse = []
meanrelativeerr = []
relative_err = []
if __name__ == '__main__': #主函数入口
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False # 此行代码即为可以显示负号
RMSE1 = []
MRE = []
STD = []
b = 8
l = 0
path = r'E:\MGEX产品\C1X-C8X(E).txt'
with open(path, 'r+') as a1:
alldata = a1.readlines()
while l < len(alldata):
alldata0 = alldata[l]
data000 = alldata0[7:(len(alldata0) - 2)]
data00 = data000.split(', ')
n = 0
while n < len(data00):
data00[n] = float(data00[n])
n = n + 1
data = pd.array(data00) # 生成等间隔点对应的沉降数据,36天
data = data + b
data = list(data)
data = pd.Series(data)
print(data)
print(type(data))
rowset = []
predictset = []
n = 10
c = 0
for i in np.arange(start=0,stop =28 - n,step=5):
if c<=2:
data0 = data.iloc[i:n + i] # 滚动取值
train = np.array(data0) # 将数据集转换成数组形式
model = ARIMA(train, order=(1, 1, 1)) # 生成ARIMA模型
mod_fit = model.fit() # 训练模型
pre = mod_fit.forecast(steps=5) # 向后预测一个值
pre = list(pre)
print(pre)
predictset.append(pre[0]) #将预测的值放入列表中
predictset.append(pre[1]) #将预测的值放入列表中
predictset.append(pre[2]) #将预测的值放入列表中
predictset.append(pre[3]) #将预测的值放入列表中
predictset.append(pre[4]) #将预测的值放入列表中
print(predictset)
rowda = data.iloc[n + i:n + i + 5]
row = list(rowda)
rowset.append(row[0]) #将对应的真值放入列表中
rowset.append(row[1]) #将对应的真值放入列表中
rowset.append(row[2]) #将对应的真值放入列表中
rowset.append(row[3]) #将对应的真值放入列表中
rowset.append(row[4]) #将对应的真值放入列表中
relativeerr = abs(row[0] - pre[0])
relativeerr0 = abs(row[1] -pre[1])
relativeerr1 = abs(row[2] -pre[2])
relativeerr2 = abs(row[3] -pre[3])
relativeerr3 = abs(row[4] -pre[4])
relative_err.append(relativeerr)
relative_err.append(relativeerr0)
relative_err.append(relativeerr1)
relative_err.append(relativeerr2)
relative_err.append(relativeerr3)
c = c+1
elif c==3:
data0 = data.iloc[i:n + i] # 滚动取值
train = np.array(data0) # 将数据集转换成数组形式
model = ARIMA(train, order=(1, 1, 1)) # 生成ARIMA模型
mod_fit = model.fit() # 训练模型
pre = mod_fit.forecast(steps=3) # 向后预测一个值
pre = list(pre)
print(pre)
predictset.append(pre[0]) #将预测的值放入列表中
predictset.append(pre[1]) #将预测的值放入列表中
predictset.append(pre[2]) #将预测的值放入列表中
print(predictset)
rowda = data.iloc[n + i:n + i + 5]
row = list(rowda)
rowset.append(row[0]) #将对应的真值放入列表中
rowset.append(row[1]) #将对应的真值放入列表中
rowset.append(row[2]) #将对应的真值放入列表中
relativeerr = abs(row[0] - pre[0])
relativeerr0 = abs(row[1] -pre[1])
relativeerr1 = abs(row[2] -pre[2])
relative_err.append(relativeerr)
relative_err.append(relativeerr0)
relative_err.append(relativeerr1)
meanrelativeerr.append(np.array(relative_err).mean())
rowset = pd.array(rowset) - b
predictset = pd.array(predictset) - b
rowset = list(rowset)
predictset = list(predictset)
RMSE = np.sqrt(mean_squared_error(rowset, predictset))
plt.plot(DOY[n:], predictset, 'o-b', label='预测数据')
plt.plot(DOY[n:], rowset, 'o-r', label='实际数据')
plt.grid(linestyle="-.", linewidth=0.25, color='k')
plt.xticks(DOY[n:], rotation=45)
plt.xlabel('DOY')
plt.ylabel('DCB/ns')
plt.xticks(rotation=80)
plt.title(label='滚动窗口大小为:{},RMSE为:{}'.format(n, RMSE), fontdict=dict(fontsize=16,
color='k',
family='KaiTi',
weight='light',
style='italic'))
plt.legend()
plt.show()
print(n, '+', predictset)
Compare = {'Predata': predictset}
Compare = DataFrame(Compare)
print('预测值精度表')
print(Compare)
RMSE1.append(RMSE)
MRE.append(np.mean(relative_err))
STD.append(np.std(predictset))
predictset = []
rowset = []
relative_err = []
err_list = []
meanrelativeerr = []
N = []
rmse = []
l = l + 1
print('ERMSarima5={}'.format(RMSE1))
print('EMREarima5={}'.format(MRE))
print('Estdarima5={}'.format(STD))
print(len(RMSE1))
print(len(MRE))
print(len(STD))
# # data = data0.diff(1).dropna()
# # data1 = data0.diff(2).dropna()
# # plt.plot(data,label='一次差分')
# # plt.plot(data1,label='二次差分')
# # plt.legend()
# # plt.show()
#
# #
# # ad_test(data) #平稳性检验,p<0.05数据是稳定的
# # ad_test(data1) #平稳性检验,p<0.05数据是稳定的
# '''
# 以下代码是为了检验,若通过P<0.05,拒绝原假设(序列为白噪声序列),故差分后的序列是平稳的非白噪声序列
# '''
##result = acorr_ljungbox(data,lags = [i for i in range(1,12)],boxpierce=True,return_df=True)
# # result1 = acorr_ljungbox(data1,lags = [i for i in range(1,12)],boxpierce=True,return_df=True)
# # print(result)
# # print(result1)
#
# step_fit = auto_arima(data,trace=True,suppress_warnings=True) # Best model: ARIMA(1,1,0)(0,0,0)[0]
#
# '''
# 以下代码块为分割数据集
# '''
# # print(data.shape)
# train=np.array(data.iloc[:24])#测试集为0-23共24个数据
# test=data.iloc[24:] #检测集为24-47共24个数据
# # print(train.shape,test.shape)
# # print(train)
# # print(test)
# # print(type(test))
# # print(type(train))
# # #设置字体为楷体
# plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
# plt.rcParams['axes.unicode_minus']=False
#
# model=ARIMA(train,order=(1,1,0))
# res=model.fit()
# diagnostics = res.plot_diagnostics() # font.set_text(s, 0, flags=flags)
# # # print(res.summary())
# plt.show()
#
# plt.rcParams['font.sans-serif'] = ['KaiTi']
# plt.rcParams['axes.unicode_minus']=False
# pre = res.predict(start=1,end=24,dynamic=False,typ='levels')
# rmse = np.sqrt(mean_squared_error(train,pre))
# plt.plot(pre,'ko',label='预测数据')
# plt.plot(train,'b*',label='实际数据')
# plt.title(label='RMSE为:{}'.format(rmse),fontdict=dict(fontsize=16,
# color='k',
# family='KaiTi',
# weight='light',
# style='italic'))
# plt.legend()
# plt.show()
# model1 = ARIMA(data,order=(1,1,0))
# res1 = model1.fit()
# pre1 = res1.predict(start=1,end=48,tpe='levels')
# pre2 = res1.forecast(steps=30)
# rmse1 = np.sqrt(mean_squared_error(data,pre1))
# plt.plot(pre1,'ko',label='拟合数据')
# plt.plot(pre2,'ro',label='预测数据')
# plt.plot(data,'b*',label='实际数据')
# plt.title(label='RMSE为:{}'.format(rmse1),fontdict=dict(fontsize=16,
# color='k',
# family='KaiTi',
# weight='light',
# style='italic'))
# plt.legend()
# plt.show()
# print(data)
# print(type(data))
# # plt.rcParams['font.sans-serif'] = ['KaiTi']
# # plt.plot(exceldata['X'],exceldata['Y'],label='原始序列')
# # plt.rc('figure',figsize=(15,6))
# # plt.xlabel('间隔')
# # plt.ylabel('沉降量/mm')
# # plt.show()
# #
# p = d = q = range(0, 2) #固定pdq的取值范围
#
# pdq = list(itertools.product(p, d, q)) #迭代生成pdq可能的所有组合
#
# seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))] #生成季节性参数组合
#
# listaic = []
# listparm = []
# minAIC = 0
# minpar = []
# warnings.filterwarnings("ignore") # specify to ignore warning messages
# #以下为搜索最佳参数
#
# # for param in pdq:
# # for param_seasonal in seasonal_pdq:
# # try:
# # mod = sm.tsa.statespace.SARIMAX(data,
# # order=param,
# # seasonal_order=param_seasonal,
# # enforce_stationarity=False,
# # enforce_invertibility=False)#强制实现平稳性并可逆性
# #
# # results = mod.fit()
# # a = results.aic
# # print('ARIMA{}x{} - AIC:{}'.format(param, param_seasonal, results.aic))
# # listaic.append(a)
# # listparm.append([param,param_seasonal])
# # if min(listaic)>= results.aic:
# # minAIC= results.aic
# # minpar=[param,param_seasonal]
# #
# # else:
# # minAIC = min(listaic)
# #
# # except:
# # continue
# # print('最小的AIC值是:',minAIC)
# # print('对应的参数组合为:',minpar)
#
# mod = sm.tsa.statespace.SARIMAX(data,
# order=(1, 1, 1),
# seasonal_order=(0, 1, 1, 12),
# enforce_stationarity=False,
# enforce_invertibility=False)
#
# results = mod.fit()
#
# # print(results.summary()) # 详细输出,results.summary()可以输出全部的模型计算参数表
#
# # results.plot_diagnostics(figsize=(15,12))
# # # results.plot_diagnostics(figsize=(15, 12))
# # plt.show()
















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











