







在文章《大语言模型落地的关键技术:RAG》中,我们初步了解了RAG的基本概念、发展历史、系统组成以及评估方法,本文将着重讲解LLM落地面临的困难以及RAG技术的优化策略。
一、基座模型缺陷
基座模型的知识局限性:
- 时效知识:模型知识的获取是通过使用训练数据集训练获取的,模型训练后产生的一些新知识,模型是无法学习的,而大模型训练成本极高,不可能经常为了弥补知识而进行模型训练。比如:2024年杭州购房政策解读。
- 专业知识:模型知识的广度获取严重依赖于训练数据集的广度,目前市面上大多数的大模型的训练集来源于网络公开数据集,对于一些特定领域或高度专业化的知识,无从学习。比如:青霉素和头孢类药物一起使用会有什么后果。
- 私有数据:对于企业来说,数据安全至关重要,企业内部数据没有被包含在训练数据中的。
- 非常识知识:基座模型本身是根据上下文来预测next token,当问题所涉及的知识不是常识时(比如长尾、冷门的知识),模型输出可能会出现幻觉。比如见手青的烹饪方法。
二、RAG特点
RAG通过检索LLM预训练语料之外的知识,来补齐基模在上述场景中的不足,从而达到减少幻觉和信息补充的目的,从而更加精准地回答用户的问题。(LLM和RAG的关系可以类比闭卷考试和开卷考试)
检索来源:搜索引擎(含SC)、专业知识库
RAG流程:检索(Retrieval)-增强(Augmentation)-生成(Generation)
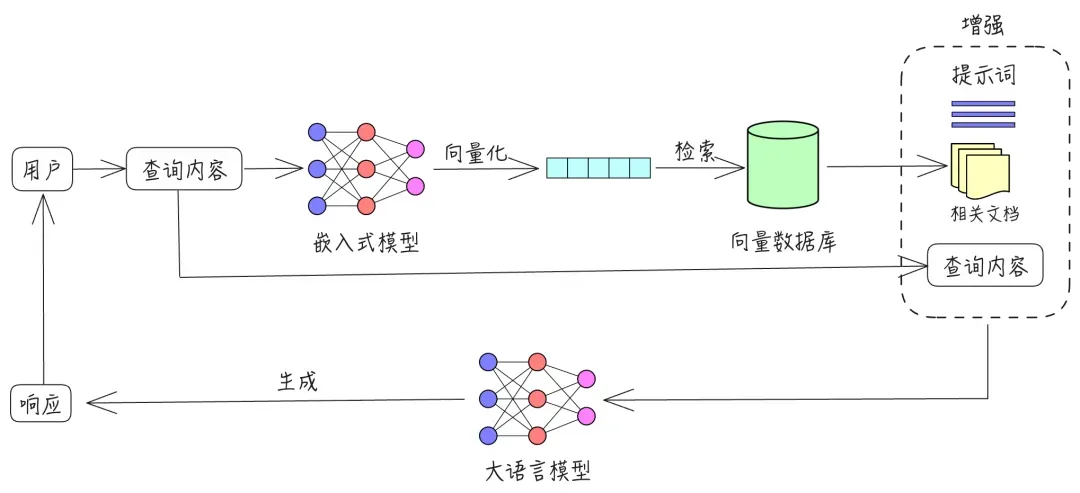
初级RAG,主要包括以下几个步骤:
- 建立索引:这一过程通常在离线状态下进行,数据清洗并分块,将分块后的知识通过embedding模型产出语义向量,并创建索引。
- 检索:用户的query问题,使用相同的embedding模型,计算问题嵌入和文档块嵌入之间的相似度,选择相似度最高的前K个文档块作为当前问题的增强上下文信息。
- 生成:将给定的问题和相关文档合并为新的提示,然后由大型语言模型基于提供的信息回答问题。如果有历史对话信息,也可以合并到提示中,用于多轮对话。
初级RAG主要在三个方面面临挑战:检索质量低、生成质量差和增强过程难。
- 检索质量低:首先使用长文本做索引,不能很好的突出主题,建立索引时,核心知识湮没在大量无用的信息中,其次,使用用户原始query做检索,不能很好的突出其核心诉求,这就导致用户query和知识索引不能很好的匹配,检索质量比较差。
- 生成质量差:未检索到知识或检索知识质量差时,大模型自主回答私域问题时,容易产生幻觉,或回答内容比较空洞,无法直接使用,知识库失去了本身的意义。
- 增强过程难:将检索到的信息与不同任务整合可能具有挑战性,有时会导致输出不连贯或不一致。此外,还有一个担忧是生成模型可能过度依赖增强信息,导致输出仅仅是复述检索内容而没有添加有洞察力或综合信息。
三、RAG策略
高级RAG相比于初级RAG,围绕着知识检索做优化,新增了检索前、检索中以及检索后的优化策略,用于解决索引、检索和生成的问题。
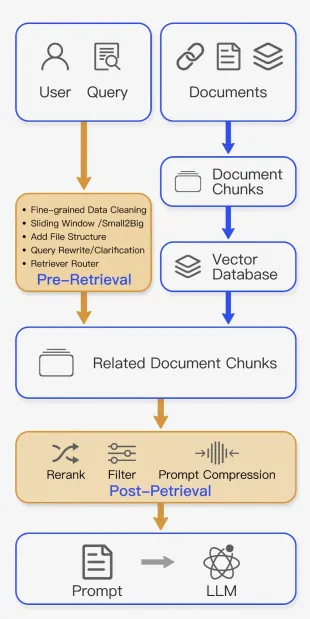
- 检索前优化:检索前优化集中在知识切分、索引方式和query改写的优化上。
- 知识切分:主要把较长的文本按照语义内聚性的分析切成小块,解决核心知识湮没以及语义截断的问题。
- 索引方式优化:通过优化数据索引组织方式提升检索效果。比如去除无效数据或插入某些数据来提高索引覆盖程度,从而达到与用户问题的高匹配度问题。
- query改写:主要需要理解用户想表达的意图,把用户原始的问题转换成适合知识库检索的问题,从而提高检索的精准程度。
- 检索优化:检索阶段的目标是召回知识库中最相关知识。
通常,检索基于向量搜索,它计算查询与索引数据之间的语义相似性。因此,大多数检索优化技术都围绕嵌入模型展开:
- 微调嵌入模型,将嵌入模型定制为特定领域的上下文,特别是对于术语不断演化或罕见的领域。
- 动态嵌入根据单词的上下文进行调整,而静态嵌入则为每个单词使用单一向量。
- 除了向量搜索之外,还有其他检索技术,例如混合搜索,通常是指将向量搜索与基于关键字的搜索相结合的概念。如果您的检索需要精确的关键字匹配,则此检索技术非常有益。
- 检索后优化:对检索到的上下文进行额外处理可以帮助解决一些问题,例如超出上下文窗口限制或引入噪声,从而阻碍对关键信息的关注。在RAG调查中总结的检索后优化技术包括:
- 提示压缩:通过删除无关内容并突出重要上下文,减少整体提示长度。
- 重新排序:使用机器学习模型重新计算检索到的上下文的相关性得分。
1、Query意图理解
RAG系统可能会遇到从知识库中检索到与用户query不相关的内容。这是由于如下问题:(1)用户问题的措辞可能不利于检索,(2)可能需要从用户问题生成结构化查询。为了解决上述问题,需要引入query理解模块。
1、意图识别
将用户query分到不同的意图信号(细分意图标签,一级标签如 问答、文创、角色扮演、安全、闲聊等,二级标签是对一级标签进行细化)。
2、Query改写
该模块主要利用LLM重新措辞用户query,而不是直接使用原始的用户query进行检索。这是因为对于RAG系统来说,在现实世界中原始query不可能总是最佳的检索条件。
3、Query扩写
该模块主要是为了将复杂问题拆解为子问题。该技术使用分而治之的方法来处理复杂的问题。它首先分析问题,并将其分解为更简单的子问题,每个子问题会从提供部分答案的相关文件检索答案。然后,收集这些中间结果,并将所有部分结果合成为最终响应。
4、Query重构
该模块强调了通过一次请求,实现对原始用户输入的复杂问题进行改写、拆解和拓展,挖掘用户更深层次的子问题,从而借助子问题检索效果更高的特点来解决复杂问题检索质量偏差的问题,旨在提高查询的准确性和效率。
2、检索策略
1、文本转换
将大型文档分割(或分块)成较小的块,即文本转换器。最简单的例子是,当需要处理长篇文本时,有必要将文本分割成若干块,以便能放入模型的上下文窗口中。理想情况下,希望将语义相关的文本片段放在一起。这听起来很简单,但潜在的复杂性却很大。
2、文本嵌入
文档嵌入模型会创建一段文本的向量表示。它可以捕捉文本的语义,让你快速有效地找到文本中相似的其他片段。这非常有用,因为它意味着我们可以在向量空间中思考文本,并进行语义搜索等操作。
3、向量数据库
随着嵌入式的兴起,人们开始需要向量数据库来支持这些嵌入式的高效存储和搜索。存储和搜索非结构化数据的最常见方法之一是嵌入数据并存储由此产生的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询 "最相似 "的嵌入向量。向量数据库负责存储嵌入数据并执行向量搜索。
4、索引
经过前面的数据读取和文本分块操作后,接着就需要对处理好的数据进行索引。索引是一种数据结构,用于快速检索出与用户查询相关的文本内容。它是检索增强 LLM 的核心基础组件之一。
5、排序和后处理
经过前面的检索过程可能会得到很多相关文档,就需要进行筛选和排序。常用的筛选和排序策略包括:
- 基于相似度分数进行过滤和排序
- 基于关键词进行过滤,比如限定包含或者不包含某些关键词
- 让 LLM 基于返回的相关文档及其相关性得分来重新排序
- 基于时间进行过滤和排序,比如只筛选最新的相关文档
- 基于时间对相似度进行加权,然后进行排序和筛选
3、生成策略
1、回复生成策略
检索模块基于用户查询检索出相关的文本块,回复生成模块让 LLM 利用检索出的相关信息来生成对原始查询的回复。这里给出一些不同的回复生成策略。
- 一种策略是依次结合每个检索出的相关文本块,每次不断修正生成的回复。这样的话,有多少个独立的相关文本块,就会产生多少次的 LLM 调用。
- 一种策略是在每次 LLM 调用时,尽可能多地在 Prompt 中填充文本块。如果一个 Prompt 中填充不下,则采用类似的操作构建多个 Prompt,多个 Prompt 的调用可以采用和前一种相同的回复修正策略。
2、prompt拼接策略
用于将提示的不同部分组合在一起。您可以使用字符串提示或聊天提示来执行此操作。以这种方式构建提示可以轻松地重用组件。
【推广时间】
AI的三大基石是算法、数据和算力,其中数据和算法都可以直接从国内外最优秀的开源模型如Llama 3、Qwen 2获得,但是算力(或者叫做GPU)由于某些众所周知的原因,限制了大部分独立开发者或者中小型企业自建基座模型,因此可以说AI发展最大的阻碍在于算力。
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台



















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











