







摘要
基于监督学习的目标检测框架需要大量繁琐的手工标注,这在实际应用中可能不实用。半监督目标检测(Semi-supervised object detection, SSOD)可以有效地利用未标记数据来提高模型的性能,这对于目标检测模型的应用具有重要意义。在本文中,我们重新审视了SSOD,并提出了一个完整的端到端有效的SSOD框架InstantTeaching,该框架在每次训练迭代中使用扩展的弱-强数据增强即时伪标记进行教学。为了缓解确认偏差问题,提高伪标注的质量,我们进一步提出了一种基于instantteach的协同校正方案,记作instantteach∗。在MS-COCO和PASCAL VOC数据集上的大量实验证实了该框架的优越性。具体来说,当使用2%的标记数据时,我们的方法在MS-COCO上超过了最先进的方法4.2 mAP。即使有MS-COCO的完整监督信息,所提出的方法仍然比最先进的方法高出约1.0 mAP。在PASCAL VOC上,我们使用VOC07作为标记数据,VOC12作为未标记数据,可以实现5个以上的mAP改进。
引入
深度神经网络显著提高了各种计算机视觉应用的性能,如图像分类和目标检测。为了避免过拟合,获得更好的性能,需要大量精确的人工标注数据来训练深度学习模型。但是,假设有足够数量的精确标记数据用于训练可能不成立,特别是对于需要使用精确的类标签和精确的边界框坐标进行标注的对象检测任务。因此,一个自然的想法是在原始任务上利用大量的未标记数据来促进学习。为了减轻对人工标记数据的依赖,一种很有前途的方法被称为半监督学习(SSL)。
SSL最近受到了社区越来越多的关注,因为它提供了使用未标记数据的有效方法,以促进具有有限注释数据的模型学习。现有的SSL方法大多针对图像分类任务,半监督学习有多种策略,如自训练和协同训练。最近,一种流行的研究将一致性损失用于半监督学习。他们要么采用集成学习算法来强制未标记数据的预测在多个模型中保持一致,要么限制模型预测对噪声不变。SSL的另一个热门研究方向是更有效的数据增强,以提高模型的泛化和鲁棒性,其中一些基于学习和更复杂的数据增强策略大大提高了SSL在图像分类任务中的性能。
虽然半监督学习在图像分类领域已经取得了很大的进展,但半监督目标检测的文献还很少。最近提出的STAC在现有的SSOD方法中性能最好,并且在很大程度上优于监督模型,这对SSOD的研究具有重要意义。然而,我们发现STAC仍然存在一些问题。首先,其训练程序复杂,效率低下。在模型训练之前,STAC需要训练一个教师模型,然后利用教师模型预生成未标注数据的伪标注。其次,在模型训练过程中,预生成的伪注释将不再更新,常量标签将限制其性能。为了解决上述两个问题,本文提出了一种新的端到端SSOD框架——即时教学,该框架在每次训练迭代中使用扩展的弱-强数据增强即时伪标记进行教学。具体如图1所示,在每次迭代训练中,Instant-Teaching首先通过小批量的弱数据增强生成未标注数据的伪标注,然后将预测到的标注立即作为强数据增强的同一幅图像的ground truth进行训练。Instant-Teaching的优势在于,随着模型在训练过程中的收敛,可以瞬间提高伪注释的质量。弱-强数据增强方案继承自STAC,并与伪注释结合被证明是有效的,我们进一步扩展了强数据增强方案,包括Mixup和Mosaic。另外,确认偏差是SSL中常见的问题。为了缓解这一问题,我们进一步提出了一种基于即时教学的共同矫正方案,称为Instant-Teaching*。Instant-Teaching*同时训练两个结构相同但权重不同的模型,这两个模型相互帮助以纠正错误的预测。在推理过程中,我们仍然只使用单个模型,因此它不会增加推理时间。
我们在PASCAL VOC和MS-COCO数据集上测试了即时教学的有效性,并遵循最新的SSOD文献STAC中的实验协议来评估性能。值得一提的是,我们的即时教学框架在所有实验协议中都优于最先进的方法,并在半监督对象检测学习方面取得了最先进的性能。
主要贡献:
-
提出了一个新的SSOD框架,称为Instant-Teaching,它在每次训练迭代期间使用扩展的弱-强数据增强即时伪标记进行教学。即时教学是一个端到端的框架,可以有效地利用未标记的数据。
-
为了缓解确认偏差问题,提高伪标注的质量,我们进一步提出了一种基于Instant-Teaching的协同校正方案,记作Instant-Teaching*。
-
在PASCAL VOC和MSCOCO数据集上的大量实验证明了我们的即时教学框架的显著有效性。
相关工作
Object detection
目标检测是一项重要的计算机视觉任务,近年来受到了相当多的关注。其中一个研究方向是强的两阶段目标检测器,它首先使用区域提议网络(Region Proposal Network, RPN)生成稀疏的感兴趣区域集(RoIs),然后进行分类和边界框回归。另一种研究方向是速度快的单阶段目标探测器。然而,这些方法在大量精确的人类注释数据上训练更强或更快的模型,这些数据在实际应用中获取是昂贵和耗时的。在这项工作中,我们遵循流行的两阶段对象检测器(FasterRCNN)来开发我们的框架。不同于以往的方法只在标记数据上训练模型,我们使用我们提出的半监督学习策略在标记数据和非标记数据上训练我们的目标检测器。
Semi-supervised learning(SSL)
半监督学习(SSL)利用了未标记数据的潜力,以促进具有有限注释数据的模型学习。现有的SSL方法大多集中在图像分类任务上,大部分工作都是基于一致性的方法,这限制了模型对噪声的不变性。基于伪标记的方法通过使用预定义的阈值生成未标记数据的高质量硬标签(即输出类概率的参数max)并对模型进行再训练来提高SSL的性能。最近,数据增强已被证明是增强SSL在图像分类中的强大范例。MixMatch通过猜测数据增强的未标记数据的低熵标签,并使用Mixup混合已标记和未标记数据,从而改进SSL。FixMatch, UDA和ReMixMatch表明,RandAugment和CTAugment可以显著促进SSL的学习。
Semi-supervised object detection (SSOD)
半监督目标检测(Semi-supervised object detection, SSOD)将半监督学习应用于目标检测。最近,一些现有的工作提出通过将SSL纳入到目标检测中,在标记数据和未标记数据上训练目标检测器。[33,47]中的方法依赖于额外的上下文(例如,来自视频的时间信息)。[36]中的方法提出了数据精馏,通过集成未标记数据的多重转换预测来自动生成新的训练注释。NOTE-RCNN[15]提出迭代进行包围盒挖掘和检测器再训练。S4OD[28]提出了一种选择性网作为选择边界框的启发式方法,以提高对未标记网页图像的目标检测。CSD[22]提出了一种基于一致性的对象检测SSL方法,该方法利用翻转增强和一致性约束来提高检测性能。ISD[23]在CSD的基础上,提出利用插值正则化进一步提高SSL的对象检测性能。最近,STAC[45]开发了一个用于对象检测的SSL框架,该框架结合了自我训练和基于强数据增强的一致性正则化,实现了最先进的结果。
在这些方法的启发下,本文以一种更有效、更简单的方式利用伪注释的有效使用以及数据扩充和协同校正方案半监督来进行目标检测进一步提高性能。
方法
问题定义
在半监督目标检测(SSOD)中,我们给出了一组标记数据![]() 和一组未标记数据
和一组未标记数据![]() ,其中x和y分别表示图像和地面真实标注(类标签和边界框坐标)。SSOD的目标是训练目标检测器在标记数据和未标记数据上进行检测。
,其中x和y分别表示图像和地面真实标注(类标签和边界框坐标)。SSOD的目标是训练目标检测器在标记数据和未标记数据上进行检测。
框架概述
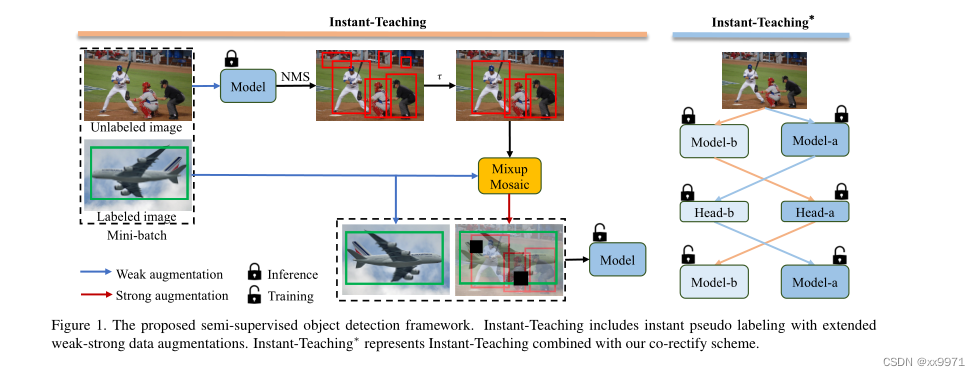
如图1所示,我们的 Instant-Teaching∗框架主要由两个模块组成,即基于弱-强数据增强的即时伪标注和校正。值得一提的是,第一个使用弱-强数据增强的即时伪标记模块已经形成了一个完整的SSOD框架,称为即时教学(instant - teaching),它也优于最先进的方法。
这两个模块各有侧重,其中利用弱-强数据增强的即时伪标注,使我们的方法能够训练到端到端,并且随着模型的收敛,伪标注的质量瞬间提高。此外,弱-强数据增强强制模型在预测弱增广和强增广未标记数据之间是保持一致的。通过这种方式,模型可以从自己生成的伪注释中学习有用的信息。协同校正方案同时训练两个具有相同结构的模型,两个模型相互帮助纠正错误预测,从而缓解了常见的确认偏差问题,进一步提高了模型性能。
请注意,虽然我们的Instant-Teaching∗同时训练两个模型,但我们在推断过程中只使用一个模型(模型-a),这不会增加推断时间。
Instant-Teaching∗
Instant pseudo labeling. 这有利于在训练过程中用更精确的模型更新伪标注,这促使我们提出即时伪标注。即时伪标记同时进行模型训练和伪标签生成,是端到端的,与最新的STAC[45]框架不同。STAC需要预先训练教师模型,以生成未标记数据的伪注释。此外,STAC在训练期间不更新生成的伪注释,这限制了它的性能。
更具体地说,我们将每个训练迭代分解为两个步骤。在第一步中,我们使用当前模型在一个小批处理中生成未标记数据的伪注释。注意,在这一步中,我们对未标记的数据应用弱增强α(·)(除非有特别说明,我们在所有实验中只使用随机翻转作为弱增强)。在第二步中,我们使用第一步生成的伪注释对相同的未标记数据应用强增强A(·),并使用一个完整的训练目标来更新模型参数,该目标包括有监督损失和无监督损失。注意在这一步中,为了得到与STAC的公平比较,我们只对未标记的数据应用强数据增强,而仍然对标记的数据应用弱增强。事实上,在最初的训练阶段,模型的性能会比较差。为了保证生成的伪标注的质量,我们始终在第一步采用非最大抑制(NMS)和基于置信度的框滤波,并在第一步使用高阈值τ(除非另有说明,我们在所有实验中使用τ = 0.9)。
总的来说,通过联合最小化监督损失和非监督损失来训练模型,如下:

Weak-strong data augmentations.
如何鼓励模型从模型本身生成的伪注释中学习有用的信息对所有基于半监督方法自训练是至关重要的。在半监督图像分类和半监督目标检测中,弱-强数据增强方案是一种很有前景的方法。弱-强数据增强迫使模型在弱增强和强增强的未标记数据之间保持一致的预测,从而鼓励模型从伪注释中学习有用的信息。
直观地看,弱-强数据增强方案的关键在于弱增强和强增强的区别。在弱增强不变的情况下,强增强越复杂、越合适,模型从伪注释中学到的信息就越多。基于这一假设,我们扩展了STAC的强数据增广,并对未标记数据引入了更复杂的增广,包括Mixup和Mosaic。实验结果也表明,我们扩展的弱-强数据增强可以进一步提高半监督目标检测的性能。
具体地,如图2 (Mixup)所示,给定一个未标记的图像xu及其伪标注(bu,cu),其中bu是四维盒坐标,cu是这些伪盒的单热点类标签(注意,当置信评分大于置信阈值τ时,我们使用硬标签)。我们首先从小批中随机选择一个带ground-truth注解(bl,cl)的标签图像xl。接下来,我们用Beta(am,am)分布得出的混合系数![]() 混合这两张图片及其单热点标签和边界框坐标,其中am=1。最后,我们使用图像和软类的混合标签和边界框坐标来替换未标记的图像xu的内容和伪注释。可计算为:
混合这两张图片及其单热点标签和边界框坐标,其中am=1。最后,我们使用图像和软类的混合标签和边界框坐标来替换未标记的图像xu的内容和伪注释。可计算为:

对于Mosaic,如图2 (Mosaic)所示,给定一个小批量的无标签图像xu和有标签的图像xl,我们随机进行两种混合样式(水平混合和垂直混合),并对其对应的注释进行相应的混合。通过对未标记数据进行Mixup和Mosaic数据增强,可以提高模型对伪标注噪声的鲁棒性,缓解模型训练中的过拟合问题。
注意,为了公平比较,我们在所有实验中只对未标记的数据进行Mixup和Mosaic数据增强,对标记的弱数据增强的数据保持不变,这与STAC相同。

Co-rectify.
确认偏差是半监督学习中常见的问题。当模型以高置信度生成不正确的预测时,这些不正确的预测将通过不正确的伪注释进一步加强。换句话说,模型本身很难纠正这些错误的预测。
为了缓解这一问题,我们提出了一种协同校正方案,该方案同时训练两个模型fa(·)(模型-a)和fb(·)(模型-b)。这两个模型相互帮助,纠正错误的预测,如图1所示。共同校正成功的关键在于两种模式不会收敛到同一个模式。我们采取两种措施来确保两个模型独立收敛。首先,虽然两个模型具有相同的结构,但它们使用不同的初始化参数。其次,虽然两个模型在每个小批处理中共享相同的数据,但它们的数据扩充和伪注释也不同。
我们以fa(·)模型为例,用类似的方法构造了fb(·)模型的修正伪注释。在每次训练迭代中生成伪标注时,模型fa(·)首先预测弱增强无标记图像xu的类概率ci和边界框坐标。然后,我们利用模型fb(·)中的检测头,以预测框ti为建议,细化类概率ci和包围框坐标ti。最后,纠正后的类概率由ci和xir取平均值,纠正后的包围框坐标是ti和tir的加权平均值。协同校正过程可计算为:
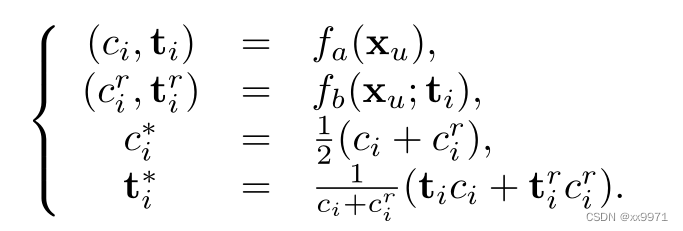
实验
我们在大规模数据集MS-COCO上测试了我们提出的半监督目标检测框架Instant-Teaching∗,并报告了80多个对象类别的mAP。为了进行公平的比较,我们使用与STAC相同的SSL实验设置。在MS-COCO数据集上进行SSL实验时,使用了两个实验设置。在第一种设置中,118k带标签的图像中只选取少量数据作为带标签集。其余部分用作未标记集。在此设置下,当只有少量标记数据时,我们能够验证SSL算法的性能。在第二种设置中,整个118k的图像作为标记集,另外的123k的未标记图像作为未标记集,这使得我们可以验证SSL算法是否可以在已经存在大规模标记图像的情况下进一步提高检测器的性能。在第一个实验设置中,我们从118k标记的图像中随机选取1%、2%、5%和10%作为标记集。
此外,我们还测试了和[Consistency-based semi-supervised learning for object de- tection.]一样在PASCAL VOC上的性能,并报告了超过20个对象类别的mAP。我们使用VOC07的训练集作为标注数据,该训练集包含约5k张图像,而未标注数据包含VOC12的训练集(约11k张图像)和MS-COCO的子集,该子集与PASCAL VOC的类相同(约95k张图像)。我们评估了VOC07测试集上的性能,并报告了IoU=0.5、IoU=0.75和IoU=0.5:0.95的map值。
实现细节
我们基于MMDetection工具箱实现了我们的Instant-Teaching*框架。为了获得公平的比较,我们遵循STAC使用Faster-RCNN和FPN作为我们的目标检测器,并使用ResNet-50作为特征提取器。利用imagenet预训练模型对特征权重进行初始化。Instant-Teaching∗主要包含三个超参数:λ、λu和τ,我们设置λ = 1.0、λu = 1.0和τ = 0.9,除非另有说明。
我们所有的实验都保持与STAC相同的训练参数。具体来说,我们使用SGD优化器在8个gpu上训练模型,初始学习率为0.01,动量为0.9,权值衰减为1e−4,总训练步长为180k。学习率在120k和165k时分别衰减10×。此外,我们将小批量大小固定为16,其中标记图像与未标记图像的比例为1:1。和STAC一样,对于1%,2%,5%和10% MS-COCO协议,我们使用快速学习时间。对于100%的协议,我们使用标准的学习时间。快速训练采用多尺度训练,标准训练时间采用单尺度训练,详见STAC[45]附录A和我们的补充资料。
结果
我们将与监督基线和最先进的SSOD方法进行详细的比较,包括CSD和STAC。详细结果汇总于表1和表2。

如表1所示,在MS-COCO数据集的所有实验设置下,我们的即时教学∗比最先进的方法性能要好得多。具体来说,对于1%的方案,即时教学的∗使mAP从STAC的13.97提高到18.05,从而实现了4.08的mAP改进;对于2%的方案,即时教学的∗使之从STAC的18.25提高到22.45,从而实现了4.2的mAP改进。当有更多的标记数据时,即时教学也带来了显著的mAP改进:5%方案的24.38到26.75,10%方案的28.64到30.40。对于100%协议,在39.21 mAP的高基准下,我们的Instant-Teaching仍然实现了大约1.0 mAP的改进。
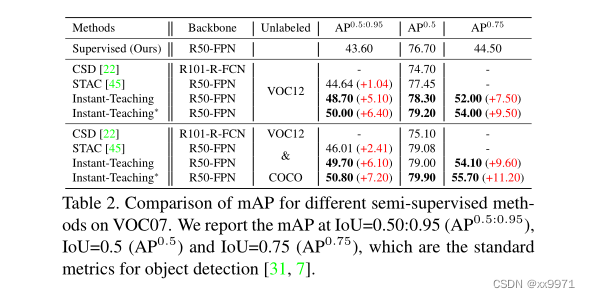
在PASCAL VOC实验中,我们也观察到类似的趋势。如表2所示,与STAC相比,以VOC07为标记数据,以VOC12为未标记数据,我们的Instant-Teaching∗使mAP从44.64提高到50.00,这表明了5.36的绝对mAP提高。当引入更多的未标记数据时(MS-COCO的子集),Instant-Teaching∗可以进一步提高mAP值,从STAC的46.01提高到50.80。我们还观察到Instant-Teaching∗的AP0.75的改善比AP0.5更显著。也就是说,mAP (AP0.5:0.95)的改进主要来自于预测的优质包围盒的改进。我们也在我们的Instant-Teaching∗在附录(A.4)中以不同的骨干,展示我们方法的可扩展性。
消融实验
即时伪标签
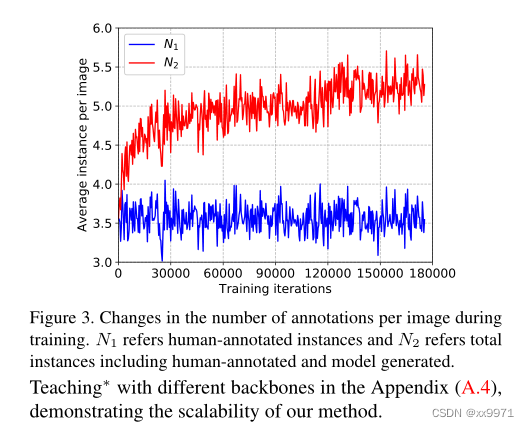
如图3所示,我们报告了每幅图像在每次训练迭代期间的平均注释实例数,其中N1表示只有人类注释的实例数,N2表示包括人类注释和生成的模型(伪注释)的总实例数。可以观察到,在训练过程中,高质量的伪标注数量(N2 ~ N1)逐渐增加。也就是说,随着模型的收敛,高质量的伪注释的数量可以立即提高。
从表3中,我们还可以观察到,在5% MS-COCO协议下,8×未标记数据,Instant-Teaching仅使用颜色抖动和Cutout[12]作为强数据增强,将mAP从STAC的23.14提高到24.70。无需使用更强大的数据增强,我们的即时教学已经超越了最先进的STAC方法。这些结果证明,通过不断改进伪标注,我们的即时伪标注最终可以获得更高的性能。
强数据增强
在弱-强数据增强方案中,强增强方案的选择直接影响最终的SSOD模型算法的性能。我们将STAC的强大增强功能从颜色抖动、几何变换和剪切扩展到包括Mixup和Mosaic。注意,我们没有应用几何变换,主要是因为在线的伪标注几何变换比较复杂,我们把它留给以后的工作。
如表3所示,在伪标记阶段的第一步中,我们首先还对未标记的数据应用强增强(Color+ cutout)。与STAC相比,该方法使我们的mAP下降了1.54。通过观察验证了我们的假设,即弱-强数据增强方案的关键在于弱增强和强增强的区别。此外,我们发现使用Mixup或Mosaic都能改善Instant-Teaching的表现。Instant-Teaching通过混合使用Mixup和Mosaic数据增强可以获得最好的表现,将mAP从STAC的23.14提高到25.60。这些结果表明,我们扩展的弱强数据增强可以进一步提高SSOD的性能。
注意,为了与STAC进行公平的比较,我们只对未标记的数据使用Mixup和Mosaic数据增强。
未标记数据的大小
在半监督目标检测领域,未标记数据大小的重要性不可忽视。因此,在本节中,我们使用MS-COCO的5%和10%标记数据来评估我们的方法,同时将未标记数据的大小从1、2、4和8倍改变为标记数据的大小。结果如表4所示。我们可以观察到,我们的方法在所有尺度的未标记数据上都优于最先进的方法STAC。值得一提的是,对于5%和10%的有标记数据,我们的instant - teach方法在1×无标记数据上训练得到的mAP分别为23.60和28.80,甚至高于在8×无标记数据上训练的STAC(23.14和27.95)。这表明即时教学可以有效地利用未标记的数据。
从图4我们可以观察到,我们的即时教学(没有协同校正)在很大程度上优于监督模型和最先进的方法STAC。我们还发现,随着未标记数据的大小的增加,STAC和instant - teach都遭受了“天花板效应”:当性能接近天花板时,改善变得更小。

τ和λu的分析
在本节中,我们分析了置信阈值τ和无监督损失权值λu的影响。我们的Instant Teaching方法以10% MS-COCO为标记数据,其余为未标记数据进行测试。我们首先分析τ的影响。如表5所示,我们用λu = 1.0和τ∈{0.3,0.5,0.7,0.9}对InstantTeaching进行测试。结果表明,将阈值τ从0.3变化到0.9,模型可以获得更好的性能,这表明τ = 0.9是对未标记数据选择高质量伪标注的较好选择。

在分析无监督损失重量λu的影响时,我们固定τ = 0.9,并将λu的值从1/4变化到4。从图5中可以看出,instant - teaching在λu = 1.0时性能最好,而随着λu的增大或减小,mAP值略有下降,说明instant - teaching对λu的鲁棒性较强。
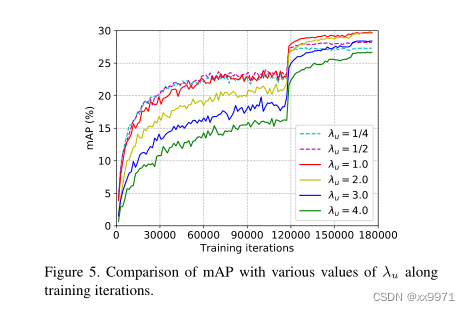
我们还可以观察到,在早期的训练迭代中,instant - teaching用较小的λu值(如1/4,1/2)获得了较高的mAP。换句话说,在早期训练阶段,伪标注的质量(数量)较低,模型更应该关注标注的数据。本文采用恒定的λu,并将λu的动态调整作为今后的工作。
协同校正分析
我们进一步提出了一种基于instantteach的协同校正方案,以缓解SSL中的确认偏差问题,如图1所(Instant-Teaching∗)。我们使用1%的标记数据和剩余99%的未标记数据(1% MS-COCO协议)来分析协同校正的效果。该模型分别采用有和无共同纠错方案的即时教学方法进行训练。为了进行评价,我们从MS-COCO 99%的未标记数据中随机选取5k标记数据进行测试。
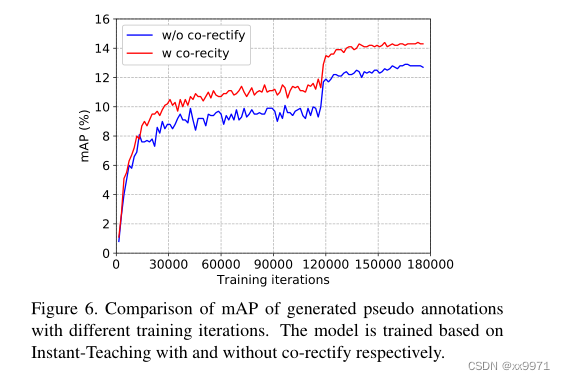
需要注意的是,为了验证协同校正方案是否能够生成更多高质量的伪标注,我们比较了评分大于0.9的预测伪标注的mAP(与训练期间的τ相同)。如图6所示,我们可以直接观察到,采用协同校正方案训练的模型能够更快地获得更好的性能,并且能够沿着训练迭代不断地提高我们Instant-Teaching的性能。
此外,我们在图7中可视化了一些未标记数据的伪注释。结果在同一个训练迭代(120k)中分别产生有和没有协同校正方案。我们可以观察到,即时教学与协同校正方案合作可以过滤掉一些错误的预测,同时产生更多高质量的伪注释。综上所述,协同矫正方案能够缓解确认偏差问题,进一步提高Instant-Teaching的性能。

总结
在本文中,我们重塑了半监督目标检测(SSOD),并提出了一个简单有效的端到端SSOD框架-即时教学,该框架在每次训练迭代期间使用扩展的弱-强数据增强即时伪标记进行教学。在即时教学的基础上,我们进一步提出了一种协同矫正方案,以缓解确认偏差问题,进一步提高成绩。对MS-COCO和PASCAL VOC进行了大量实验,证明了该方法的显著优越性。虽然我们使用了两阶段检测器Faster-RCNN进行评估,但我们提出的即时教学*是一个通用的SSOD框架,并不局限于对象检测模型。这意味着即时教学*可以直接应用于其他检测器,例如单阶段检测器SSD和FCOS,我们将其留到以后的工作中。















 2955
2955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









