






目标追踪方法都有哪些
附赠自动驾驶最全的学习资料和量产经验:链接
1. DeepSORT算法
卡尔曼滤波器又叫最佳线性滤波器 经典滤波器:高通,低通,带通 滤波其实是过滤一些特定频段的噪声的.
通过过滤白噪声或者是高斯噪声, 白噪声在统计学上是有特性的,那这个特性,通常用均值和方差来表示,
卡尔曼滤波: 举个用统计学方法对温度策略估计的例子,用两个精度不同的温度计测量体 温,并且假设两个测量误差都是服从零均值的正态分布.
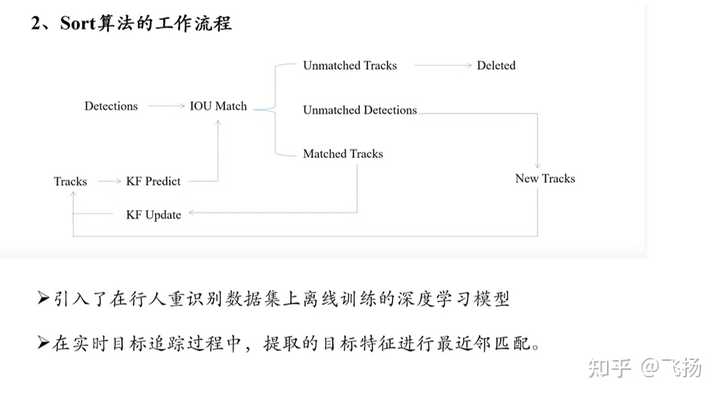
Sort算法 1,sort算法的核心: 卡尔曼滤波算法和匈牙利算法
卡尔曼滤波算法作用: 用当前的一系列运动变量去预测下一时刻的运动变量, 但是第一次的检测效果用来初始化卡尔曼滤波的运动变量
匈牙利算法的作用:解决分配问题, 就是把一群检测框和卡尔曼预测的框做分 配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果. IOU作为前后帧间目标关系度量指标

外观特征增加的提取CNN网络,是根据VGG网络启发的
案例:


知识点分几大块:
1, 卡尔曼滤波 卡尔曼滤波是一种递归的状态估计方法,它通过系统模型和测量值来更新 状态的最优估计。 通俗解释: 想一个场景:梦回大学,打游戏, 特别团战, 一个说打,一个说不打, 这种现象,你到底要听谁的, 犹豫过来,到底该去听谁的 团战:A说张量没大, B说谁去骗张量的,我该信谁的? 那么这个时候,那就看我能更信这俩人当中的哪一个的(那就看谁的权重大,谁 大我就听谁的, ) 这就是卡尔曼滤波在最直观的解释, A和B 我该更加倾向于谁的, 举例:
现在我只有观测值(A说张量没大, )和一个估计值(数学模型预测张量) 观测值是在原始的卡尔曼滤波中表示传感器检测到的值, 或者是传感器观察 到的值, 手里还有一个数学模型,在帮我估计张量CD等于多少,刚刚把大招放出来, 那么这个时候我该如何选, 如何选才能得到最优的结果? 我是通过观测值选开团,还是案估计值开团呢, 一般传感器返回回来的结果, 拿GPS做定位的时候,误差很正常,观测值也是有误差的, 那个算法那个模型100% 估计预测结果,估计值也必有误差, 那么我该怎么综合得到最终的估计. 卡尔曼滤波针对观测值,得到传感器结果和实际观察得到的结果, 我的目标 框,我的bbox,检测出来的结果,是观测值, 检测器检测出来完整的检测到人, 观测 值可能会得到这个人靠左一点,靠右一点, 观测值和估计值,做一个折中,怎么综合利用来输出一个更精确的结果这是卡 尔曼滤波做的事情,就是折中考虑,并不是认为折中,让算法帮忙折中,到底相信估 计值和观测值. 什么是观测值,什么是估计值
观测值可以是系统变量的取值, 也可以是由传感器产生的测量数据。 这些 观测值对于估计系统的状态至关重要, 因为它们提供了关于系统当前状态的信 息。 卡尔曼滤波中的观测值的似然估计通常是指在给定当前状态估计的情况 下, 计算观测值与预测观测值之间的差异的概率密度函数。 这个概率密度函数 可以用于衡量观测值与状态估计的拟合程度, 从而帮助滤波器更好地更新状态 估计。 在卡尔曼滤波中, 通常使用高斯分布( 正态分布) 来表示观测噪声 卡尔曼滤波算法的目的是融合不同的观测类型的数据,把不同种类的数据 进行融合,然后得到一个更好的,更符合测量实际的数据。卡尔曼滤波算法的 核心就是预测、融合与迭代。
2 匈牙利算法 匈牙利算法是基于Hall定理中充分性证明的思想,它是部图匹配最常见的算 法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配 的算法。 匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法
一、 匈牙利算法基本概念 匈牙利算法(Hungarian algorithm),即图论中寻找最大匹配的算 法,暂不考虑加权的最大匹配(用KM算法实现)。 匈牙利算法(Hungarian algorithm),主要用于解决一些与二分图 匹配有关的问题。
KM算法, 也称为Kuhn-Munkres算法, 是一种用于求解分配问题的经典算 法。 它特别适用于解决在二分图中寻找最大权匹配的问题
KM算法是一种 计算机算法,功能是求完备匹配下的最大权匹配。在一个二 分图内,左顶点为X,右顶点为Y,现对于每组左右连接XiYj有权wij,求一种匹 配使得所有wij的和最大。
最近在研究一个比较有意思的应用—车辆追踪算法。传统的车辆追踪算法 是基于检测器检出车辆,之后使用卡尔曼滤波和匈牙利算法来进行位置预测与 数据级联的。关于卡尔曼滤波,我之前已经写过一篇文章进行了详细的介绍; 最近则是在研究匈牙利算法是如何工作的。这里简单的记录一下相关原理。 匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,广 泛应用在运筹学领域。 美国数学家哈罗德·库恩于1955年提出该算法。之所以被 称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes Kőnig(1884-1944)和Jenő Egerváry(1891-1958)的工作上创建起来的。 在车辆追踪中,匈牙利算法(Hungarian Algorithm)与KM算法(Kuhn Munkres Algorithm)都是用来解决多目标跟踪中的数据关联问题,而数据关 联问题,亦可转化为求解二分图的最大匹配问题。二分图的最大匹配问题听起 来很绕口,这里如何理解呢?换句话说,就是求解任务分配问题,也叫指派问 题,即n项任务,对应分配给n个人去做,应该由哪个人来完成哪项任务,能够 使完成效率最高.
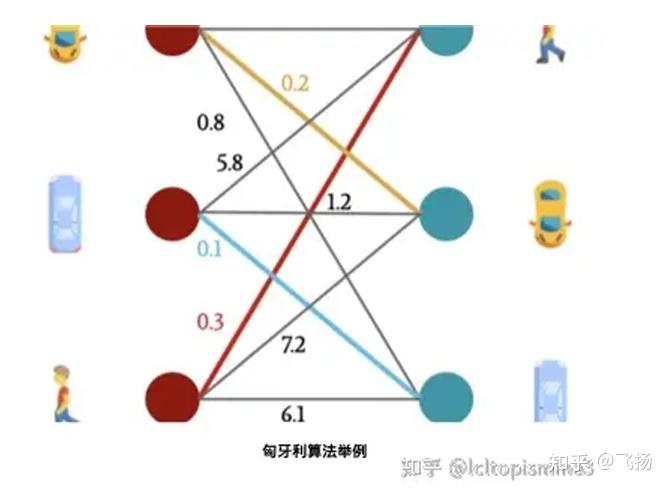

从图上可以看到,不同的车和人,之间的距离是不一样的。那么如果正确 的把对应的车和对应的人匹配起来呢?这时候就需要用到匈牙利算法。 一个关于匈牙利算法的例子 这里我们使用一个例子来说明如何使用匈牙利算法 假设你有4个检测框(简写为det),对应于四个相应的追踪轨迹(简写为 tracking), 给定相应之间的距离(稍后会讲到怎么算这个距离),那么如何匹 配检测框与对应的追踪轨迹呢?
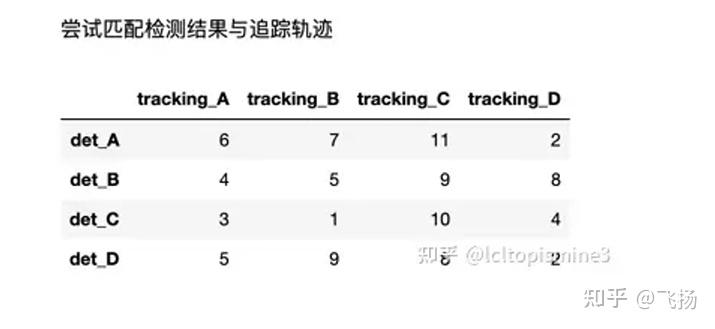

我们可以采用这样几个步骤来进行匹配 1. 按照行,减去本行最小值 2. 按照列,减去本列最小值 3. 尝试以最少数量的线条划掉所有零;如果这个数量大于等于矩阵的行列 数,那么跳到第五步 4. 在剩下的矩阵中,减去最小值;如果有零被交叉,那么把这个最小值加 上去,然后重复第三步 5. 从只有一个零的行开始一一对应,对应完则整个行列删除
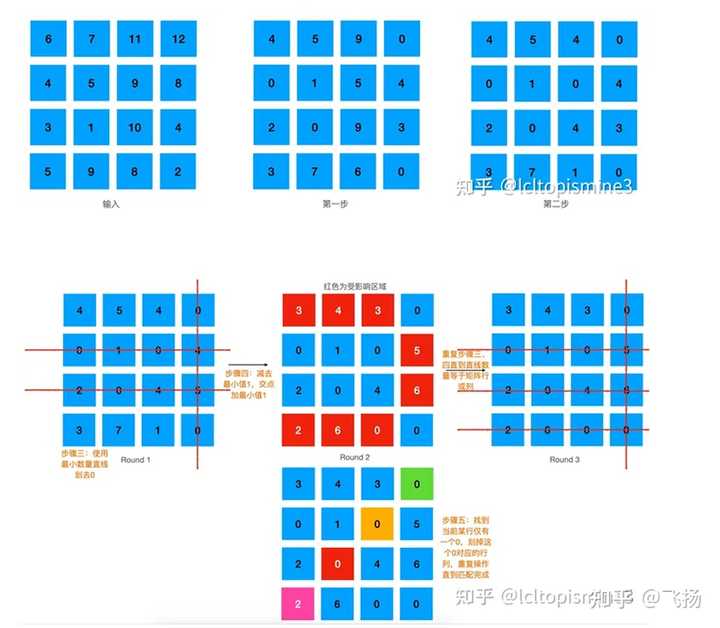

详细的执行步骤可以看一下这里的两张图,有比较清晰的描述。 最终结果: det_A->D det_B->A det_C->B det_D->C, 这里 -> 代表 “匹配” 的意思。 额外要注意的是,这里我们求解的矩阵是N * N的,如果对应矩阵是 M * N 的话,需要给少的维度补齐,补的值是当前矩阵中的最大值即可。 匈牙利算法原理与实现 接下来,我们简单聊一下匈牙利算法的原理和实现。 匈牙利算法一般是在二分图(Bipartite graph)这样的数据结构上实现的。这 种图的名字可以看到,会把图中元素一分为二,其中顶点分为两两不相交的集 合,并且同属于一个集合内的点两两不相连。
那么如何基于二分图(也叫二部图)判断匹配呢?这里我们说两条边匹 配,即为存在两条边e1,e2,有e1,e2的顶点不相交,即为成功匹配。反之,如 果相交了,代表的情况就是同一个人完成两个任务,这不符合匹配的要求,具 体例子可以看下图
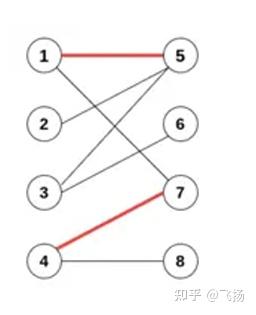

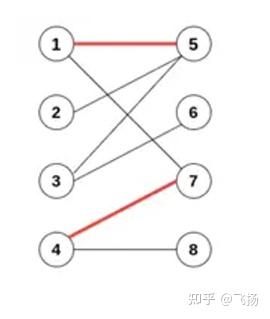
这里,我们有边 e1 连接 点1和点5, e6连接 点4和点7,且各点之间不相 交;红色边表示成功的匹配,被称为匹配边,匹配边所连接的点被称为匹配 点。同样可以定义非匹配边和非匹配点(也就是顶点相交) 接下来,我们再给出最大匹配的定义:如果给定的二分图里面,有若干边 不相交(形成若干匹配),且匹配数量达到这个二分图里所有可能匹配的最大 值,那么我们认为这个二分图对应的匹配达到最大匹配(Maximum Matching)。图中 {e2,e3,e5,e7} 即为其中一组最大匹配。
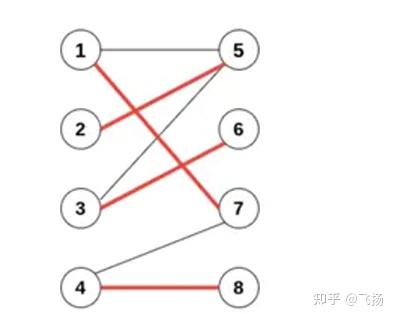

此外有关于二分图(也属于图的定义),还有两个常常提到的定义,这里 简单做一下介绍。 交错路径:图匹配结果中,如果相邻两条边性质不同,也就是出现匹配边 >非匹配边->匹配边 相互交错的情况,那么我们说存在交错路径。假设 {e2, e7} 相互匹配,我们有 {e1,e2,e6,e7}为交错路径。 增广路径:如果一条路径的首尾是非匹配点,路径中除此之外(如果有) 其他的点均是匹配点,那么这条路径就是一条增广路径(Agumenting path)。也就是说,从一个非匹配点出发,走交错路径到另一个非匹配点(保 证了两边的边为非匹配边)。这里假设{e1, e6}相互匹配,我们有 {e7,e6,e2,e1,e3}为增广路径。 从增广路径的定义可以看到,增广路径的首尾是非匹配点。因此,增广路 径的第一条和最后一条边,必然是非匹配边;由交错路径的定义可知,增广路 径从非匹配边开始,匹配边和非匹配边依次交替,最后由非匹配边结束。这样 一来,增广路径中非匹配边的数目总比匹配边大 1。考虑置换增广路径中的匹配 边和非匹配边,由于增广路径的首尾是非匹配点,其余则是匹配点,这样的置 换不会影响原匹配中其他的匹配边和匹配点,因而不会破坏匹配;而增广路径 的置换,可使匹配的边数加1,得到比原有匹配更大的匹配。 由于二分图的最大匹配必然存在(比如,上限是包含所有顶点的完全匹 配),所以,在任意匹配的基础上,如果有办法不断地搜寻出增广路径,直到 最终我们找不到新的增广路径为止。具体来说,每次找到增广路径,就尝试进 行替换,使得匹配边数+1。最后就有可能得到二分图的一个最大匹配。这也是 匈牙利算法的设计思路这里我们再举一个例子来进一步理解这个问题.

匈牙利算法详解 匈牙利算法(Hungarian Algorithm)是一种组合优化算法(combinatorial optimization algorithm),用于求解指派问题(assignment problem),算法时 间复杂度为O(N^3)。Harold Kuhn发表于1955年,由于该算法基于两位匈牙利 数学家的早期研究成果,所以被称作“匈牙利算法”。 假设有三位工人A,B和C,需要分配他们每人完成一件工作;对于不同的工 作他们所需要花费的时间不同,如下表所示。问题就是要找到一套耗时最小的 指派方案。用矩阵表示如下: 匈牙利算法包含四步。前两步一次执行完,第三步和第三步会重复执行直 到最优分配出现。算法的输入是n*n的矩阵,只有非负数。 Step 1: Subtract row minima (减去行最小值) 对于每一行,找到该行的最小值,然后该行的数都减去这个最小值 Step 2: Subtract column minima(减去列最小值) 同样的,对于每一列,找到该列的最小值,然后该列的数都减去这个最小值 Step 3: Cover all zeros with a minimum number of lines(用最少的线覆 盖所有的0) 用最少的水平线和垂直线覆盖掉矩阵的所有0元素。如果需要n条线,那么在这 些0中就存在最优解。算法结束 如果需要的线.















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









