







卡尔曼滤波原理
假设有一个离散系统
x
(
k
)
=
A
x
(
k
−
1
)
+
B
(
u
(
k
)
+
w
(
k
)
)
w
(
k
)
∼
N
(
0
,
Q
)
y
(
k
)
=
C
x
(
k
)
+
v
(
k
)
v
(
k
)
∼
N
(
0
,
R
)
\begin{aligned} x(k) & =A x(k-1)+B(u(k)+w(k)) & & w(k) \sim N(0, Q) \\ y(k) & =C x(k)+v(k) & & v(k) \sim N(0, R) \end{aligned}
x(k)y(k)=Ax(k−1)+B(u(k)+w(k))=Cx(k)+v(k)w(k)∼N(0,Q)v(k)∼N(0,R)
其中
w
w
w是系统噪声,
v
v
v是观测噪声,假设所有的状态和噪声都服从高斯分布。
现在假设知道了 k-1 时刻的后验状态估计 x ^ ( k − 1 ) \hat{x}(k-1) x^(k−1)和协方差 P ^ ( k − 1 ) \hat{P}(k-1) P^(k−1),要根据 k 时刻的输入和输出,确定 x ( k ) x(k) x(k)的后验分布。假设 x ^ ( k ) \hat{x}(k) x^(k)表示后验, x ˇ ( k ) \v{x}(k) xˇ(k)表示先验。
卡尔曼滤波的第一步(预测),通过状态方程确定
x
(
k
)
x(k)
x(k)的先验分布,状态方程是线性的,高斯分布经过线性变换后仍是高斯分布。因此有:
P
(
x
(
k
)
∣
x
(
0
)
,
u
(
1
:
k
)
,
y
(
1
:
k
−
1
)
)
∼
N
(
A
x
^
(
k
−
1
)
+
B
u
(
k
)
,
A
P
^
(
k
−
1
)
A
T
+
B
Q
B
T
)
P(x(k)|x(0),u(1:k),y(1:k-1)) \sim N(A\hat{x}(k-1)+Bu(k),A\hat{P}(k-1)A^T+ BQB^T)
P(x(k)∣x(0),u(1:k),y(1:k−1))∼N(Ax^(k−1)+Bu(k),AP^(k−1)AT+BQBT)
这一步显示了如何从上一时刻状态和有噪声输入信息推断出当前时刻的状态分布,这个分布就是先验。记
x
ˇ
(
k
)
=
A
x
^
(
k
−
1
)
+
B
u
(
k
)
P
ˇ
(
k
)
=
A
P
^
(
k
−
1
)
A
T
+
B
Q
B
T
\v{x}(k) = A\hat{x}(k-1)+Bu(k) \quad \v{P}(k) = A\hat{P}(k-1)A^T+ BQB^T
xˇ(k)=Ax^(k−1)+Bu(k)Pˇ(k)=AP^(k−1)AT+BQBT
即:
P
(
x
(
k
)
∣
x
(
0
)
,
u
(
1
:
k
)
,
y
(
1
:
k
−
1
)
)
∼
N
(
x
ˇ
(
k
)
,
P
ˇ
(
k
)
)
P(x(k)|x(0),u(1:k),y(1:k-1)) \sim N(\v{x}(k),\v{P}(k))
P(x(k)∣x(0),u(1:k),y(1:k−1))∼N(xˇ(k),Pˇ(k))
显然这个状态有很大的不确定性,因为系统有噪声,另外,可以计算该状态下的输出:
P
(
y
(
k
)
∣
x
(
k
)
)
∼
N
(
C
x
(
k
)
,
R
)
P(y(k)|x(k)) \sim N(Cx(k),R)
P(y(k)∣x(k))∼N(Cx(k),R)
根据贝叶斯公式,可以计算当前时刻的状态分布的后验概率,即
P
(
x
(
k
)
∣
x
(
0
)
,
u
(
1
:
k
)
,
y
(
1
:
k
)
)
⏟
后验
=
P
(
x
(
k
)
,
x
(
0
)
,
u
(
1
:
k
)
,
y
(
1
:
k
)
)
P
(
x
(
0
)
,
u
(
1
:
k
)
,
y
(
1
:
k
)
)
=
P
(
y
(
k
)
∣
x
(
k
)
)
P
(
x
(
k
)
∣
x
(
0
)
,
u
(
1
:
k
)
,
y
(
1
:
k
−
1
)
)
P
(
x
(
0
)
,
u
(
1
:
k
)
,
y
(
1
:
k
)
)
∝
P
(
y
(
k
)
∣
x
(
k
)
)
⏟
似然
P
(
x
(
k
)
∣
x
(
0
)
,
u
(
1
:
k
)
,
y
(
1
:
k
−
1
)
)
⏟
先验
\begin{aligned} \underbrace{P\left(x(k) \mid x(0), u(1: k), y(1: k)\right)}_{\text {后验 }} & =\frac{P\left(x(k), x(0), u(1: k), y(1: k)\right)}{P\left(x(0), u(1: k), y(1: k)\right)}=\frac{P\left(y(k) \mid x(k)\right) P\left(x(k) \mid x(0), u(1: k), y(1: k-1)\right)}{P\left(x(0), u(1: k), y(1: k)\right)} \\ & \propto \underbrace{P\left(y(k) \mid x(k)\right)}_{\text {似然 }} \underbrace{P\left(x(k) \mid x(0), u(1: k), y(1: k-1)\right)}_{\text {先验}} \end{aligned}
后验
P(x(k)∣x(0),u(1:k),y(1:k))=P(x(0),u(1:k),y(1:k))P(x(k),x(0),u(1:k),y(1:k))=P(x(0),u(1:k),y(1:k))P(y(k)∣x(k))P(x(k)∣x(0),u(1:k),y(1:k−1))∝似然
P(y(k)∣x(k))先验
P(x(k)∣x(0),u(1:k),y(1:k−1))
最后会得到一个关于
x
(
k
)
x(k)
x(k)的高斯分布,将结果设为
x
(
k
)
∼
N
(
x
^
(
k
)
,
P
^
(
k
)
)
x(k) \sim N(\hat{x}(k),\hat{P}(k))
x(k)∼N(x^(k),P^(k)),那么:
N
(
x
^
(
k
)
,
P
^
(
k
)
)
=
η
⋅
N
(
C
x
(
k
)
,
R
)
⋅
N
(
x
ˇ
(
k
)
,
P
ˇ
(
k
)
)
N(\hat{x}(k),\hat{P}(k)) = \eta \cdot N(Cx(k),R) \cdot N(\v{x}(k),\v{P}(k))
N(x^(k),P^(k))=η⋅N(Cx(k),R)⋅N(xˇ(k),Pˇ(k))
用取巧的方法,我们已经知道两边都是高斯分布,只需比较
x
(
k
)
x(k)
x(k)的系数,忽略高斯分布前面的
η
\eta
η因子,将等式部分展开:有
(
x
(
k
)
−
x
^
(
k
)
)
T
P
^
k
−
1
(
x
(
k
)
−
x
^
(
k
)
)
=
(
y
(
k
)
−
C
x
(
k
)
)
T
R
−
1
(
y
(
k
)
−
C
x
(
k
)
)
+
(
x
(
k
)
−
x
ˇ
(
k
)
)
T
P
ˇ
k
−
1
(
x
(
k
)
−
x
ˇ
(
k
)
)
\left(x(k)-\hat{x}(k)\right)^T \hat{P}_k^{-1}\left(x(k)-\hat{x}(k)\right)=\left(y(k)-Cx(k)\right)^T R^{-1}\left(y(k)-C x(k)\right)+\left(x(k)-\v{x}(k)\right)^T \v {P} _k^{-1}\left(x(k)-\v{x}(k)\right)
(x(k)−x^(k))TP^k−1(x(k)−x^(k))=(y(k)−Cx(k))TR−1(y(k)−Cx(k))+(x(k)−xˇ(k))TPˇk−1(x(k)−xˇ(k))
这里的等号并不严格,允许与
x
(
k
)
x(k)
x(k)无关的常数,我们需要求出左侧的
x
^
(
k
)
,
P
^
k
\hat{x}(k),\hat{P}_k
x^(k),P^k,将两边展开,分别比较
x
(
k
)
x(k)
x(k)的二次和一次项系数。
对于二次项系数
有:
P
^
k
−
1
=
C
T
R
−
1
C
+
P
ˇ
k
−
1
\hat{P}_k^{-1}=C^T R^{-1} C+ \v{P} _k^{-1}
P^k−1=CTR−1C+Pˇk−1
定义中间变量:
K
=
P
^
k
C
T
R
−
1
K=\hat{P}_k C^T R^{-1}
K=P^kCTR−1
将
P
^
k
−
1
=
C
T
R
−
1
C
+
P
ˇ
k
−
1
\hat{P}_k^{-1}=C^T R^{-1} C+ \v{P} _k^{-1}
P^k−1=CTR−1C+Pˇk−1两边左乘
P
^
k
\hat{P}_k
P^k,有
I
=
P
^
k
C
T
R
−
1
C
+
P
^
k
P
ˇ
k
−
1
=
K
C
+
P
^
k
P
ˇ
k
−
1
I = \hat{P}_kC^T R^{-1} C + \hat{P}_k \v{P} _k^{-1} = K C + \hat{P}_k \v{P} _k^{-1}
I=P^kCTR−1C+P^kPˇk−1=KC+P^kPˇk−1
于是有:
P
^
k
=
(
I
−
K
C
)
P
ˇ
k
\hat{P}_k = (I - K C )\v{P} _k
P^k=(I−KC)Pˇk
这里有点循环定义的意思,由
P
^
k
\hat{P}_k
P^k定义了
K
K
K,又把
P
^
k
\hat{P}_k
P^k写成了
K
K
K的表达式。实际中
K
K
K可以不依靠
P
^
k
\hat{P}_k
P^k算得(需要用到SMW公式):
K
=
P
ˇ
k
C
T
(
C
P
ˇ
k
C
T
+
R
)
−
1
K=\v {P} _k C^T(C\v{P} _kC^T + R)^{-1}
K=PˇkCT(CPˇkCT+R)−1
对于一次项系数
有:
−
2
x
^
(
k
)
T
P
^
k
−
1
=
−
2
y
(
k
)
T
R
−
1
C
−
2
x
ˇ
(
k
)
T
P
ˇ
k
−
1
-2\hat{x}(k)^T \hat{P}_k^{-1}=-2 y(k)^T R^{-1}C -2 \v{x}(k)^T \v{P} _k^{-1}
−2x^(k)TP^k−1=−2y(k)TR−1C−2xˇ(k)TPˇk−1
取系数转置得:
P
^
k
−
1
x
^
(
k
)
=
C
T
R
−
1
y
(
k
)
+
P
ˇ
k
−
1
x
ˇ
(
k
)
\hat{P}_k^{-1}\hat{x}(k)= C^T R^{-1} y(k)+ \v{P} _k^{-1} \v{x}(k)
P^k−1x^(k)=CTR−1y(k)+Pˇk−1xˇ(k)
两侧左乘
P
^
k
\hat{P}_k
P^k,得:
x
^
(
k
)
=
P
^
k
C
T
R
−
1
y
(
k
)
+
P
^
k
P
ˇ
k
−
1
x
ˇ
(
k
)
\hat{x}(k) = \hat{P}_kC^T R^{-1} y(k)+ \hat{P}_k\v{P} _k^{-1} \v{x}(k)
x^(k)=P^kCTR−1y(k)+P^kPˇk−1xˇ(k)
x
^
(
k
)
=
P
^
k
C
T
R
−
1
y
(
k
)
+
P
^
k
P
ˇ
k
−
1
x
ˇ
(
k
)
=
K
y
(
k
)
+
(
I
−
K
C
)
x
ˇ
(
k
)
=
x
ˇ
(
k
)
+
K
(
y
(
k
)
−
C
x
ˇ
(
k
)
)
\begin{aligned} \hat{x}(k) &= \hat{P}_kC^T R^{-1} y(k)+ \hat{P}_k\v{P} _k^{-1} \v{x}(k) \\ &= K y(k)+ (I - K C ) \v{x}(k) \\ &= \v{x}(k) + K (y(k) - C \v{x}(k) ) \end{aligned}
x^(k)=P^kCTR−1y(k)+P^kPˇk−1xˇ(k)=Ky(k)+(I−KC)xˇ(k)=xˇ(k)+K(y(k)−Cxˇ(k))
由此得到了后验均值的表示,上面两个步骤可以归纳为“预测”和“更新”。流程如下所示:
预测:
x ˇ ( k ) = A x ^ ( k − 1 ) + B u k P ˇ k = A P ^ k − 1 A T + B Q B T {\v{x }(k)} = A{\hat{x}(k - 1)} + Bu_k \quad {\v{P} _k} = A{\hat{P} _{k - 1}}A^T + BQB^T xˇ(k)=Ax^(k−1)+BukPˇk=AP^k−1AT+BQBT
更新:先计算K,它又称卡尔曼增益:
K = P ˇ k C T ( C P ˇ k C T + R ) − 1 K=\v{P} _k C^T ( C \v{P} _k C^T + R)^{-1} K=PˇkCT(CPˇkCT+R)−1
然后计算后验概率分布:
P ^ k = ( I − K C ) P ˇ k x ^ ( k ) = x ˇ ( k ) + K ( y ( k ) − C x ˇ ( k ) ) y ^ ( k ) = C x ^ ( k ) \begin{aligned} \hat{P}_k &= (I - K C)\v{P} _k \\ \hat{x}(k) &= \v{x}(k) + K (y(k) - C\v{x}(k)) \\ \hat{y}(k) &= C\hat{x}(k) \\ \end{aligned} P^kx^(k)y^(k)=(I−KC)Pˇk=xˇ(k)+K(y(k)−Cxˇ(k))=Cx^(k)
仿真
假设控制对象为:
P
(
s
)
=
133
s
2
+
25
s
P(s) = \frac{133}{s^2+25s}
P(s)=s2+25s133
仿真代码如下
% created by hyacinth on 2024/1/5
clc
clear
close all
%%
fs = 1e3;
dt = 1/fs;
a = 25; b = 133;
sys = tf(b,[1 a 0]);
dsys = c2d(sys,dt,'zoh');
[num, den] = tfdata(dsys,'v');
A1 = [0 1; 0 -a];
B1 = [0; b];
C1 = [1, 0];
D1 = 0;
% [A1, B1 ,C1 ,D1] = tf2ss(133,[1 25 0]);
[A, B, C, D] = c2dm(A1, B1, C1, D1, dt, "zoh");
u_1 = 0; u_2 = 0;
y_1 = 0; y_2 = 0;
ei = 0; e_1 = 0;
N = 1000;
t = (1:N)*dt;
yd = ones(1,N);
w = 0.002*randn(1,N); % system noise
v = 0.002*randn(1,N); % observational noise
Q = 1; R = 1;
P = B*Q*B';
x = zeros(2, 1);
S = 2; % flag
kp = 8; ki = 0.8; kd = 0.2;
threshold = 30;
for n=1:1:N
y(n) = -den(2)*y_1 - den(3)*y_2 + num(2)*u_1 + num(3)*u_2;
yv(n) = y(n) + v(n); % add observational noise
if S==1 % no kalman filter
y(n) = yv(n);
elseif S==2 % using kalman filter
P = A*P*A' + B*Q*B';
K = P*C'/(C*P*C'+R);
P = (eye(2) - K*C)*P;
x = x + K*(yv(n) - C*x);
y(n) = C*x;
end
e(n) = yd(n) - y(n);
ei = ei + e(n)*dt;
u(n) = kp*e(n) + ki*ei + kd*(e(n)-e_1)/dt;
if abs(u(n)) > threshold
u(n) = sign(u(n))*threshold;
end
u(n) = u(n) + w(n); % add system noise
x = A*x + B*u(n);
u_2 = u_1; u_1 = u(n);
y_2 = y_1; y_1 = y(n);
e_1 = e(n);
end
figure
subplot(3,1,1);hold on;grid on
plot(t,yd,LineWidth=2)
plot(t,y, ".-")
legend("yd","y")
subplot(3,1,2);hold on;grid on
plot(t,u,LineWidth=2)
legend("u")
subplot(3,1,3);hold on;grid on
plot(t,e,LineWidth=2)
legend("e",Location="best")
未使用卡尔曼滤波的结果为:
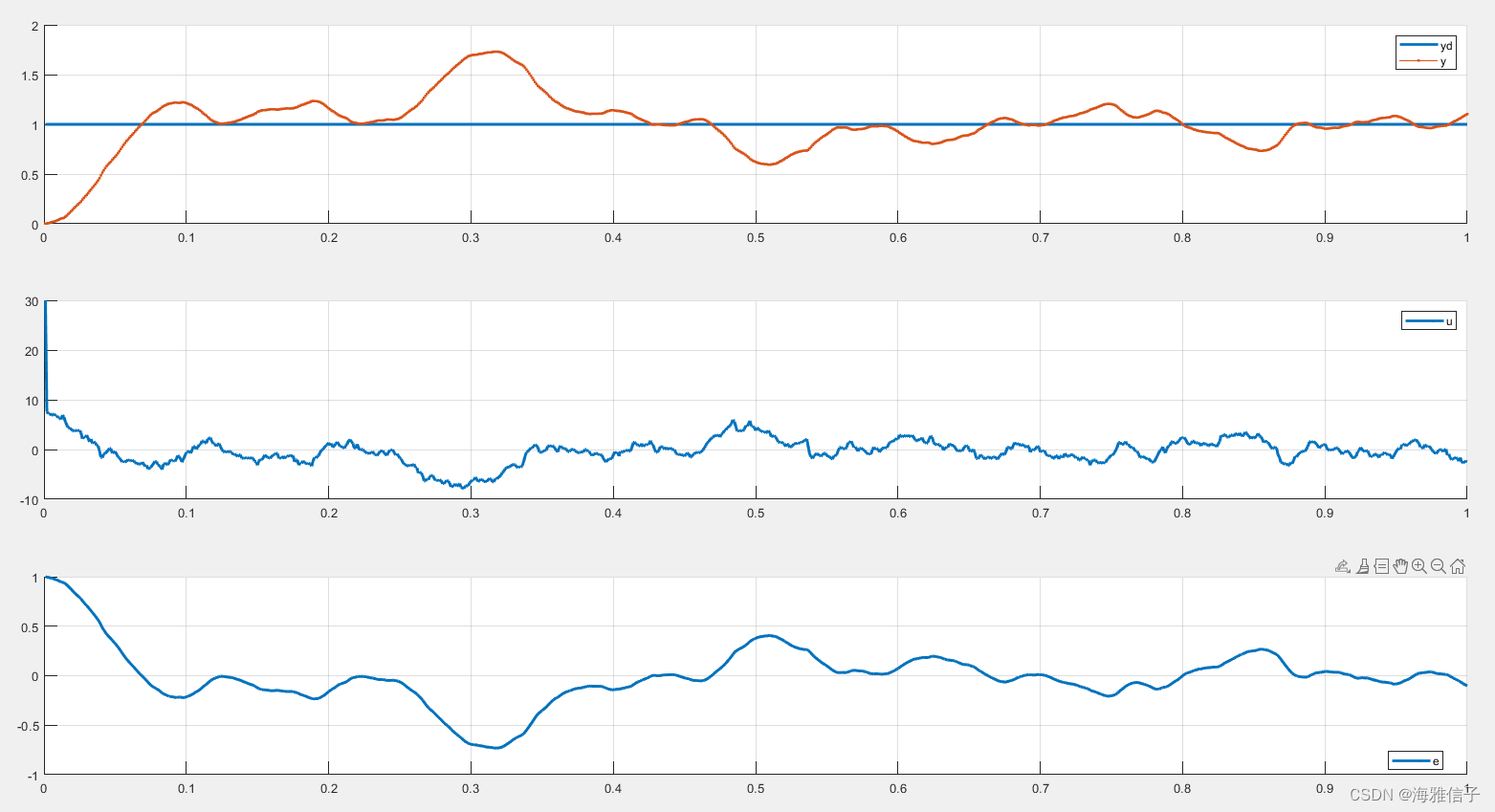
使用了卡尔曼滤波的结果为:
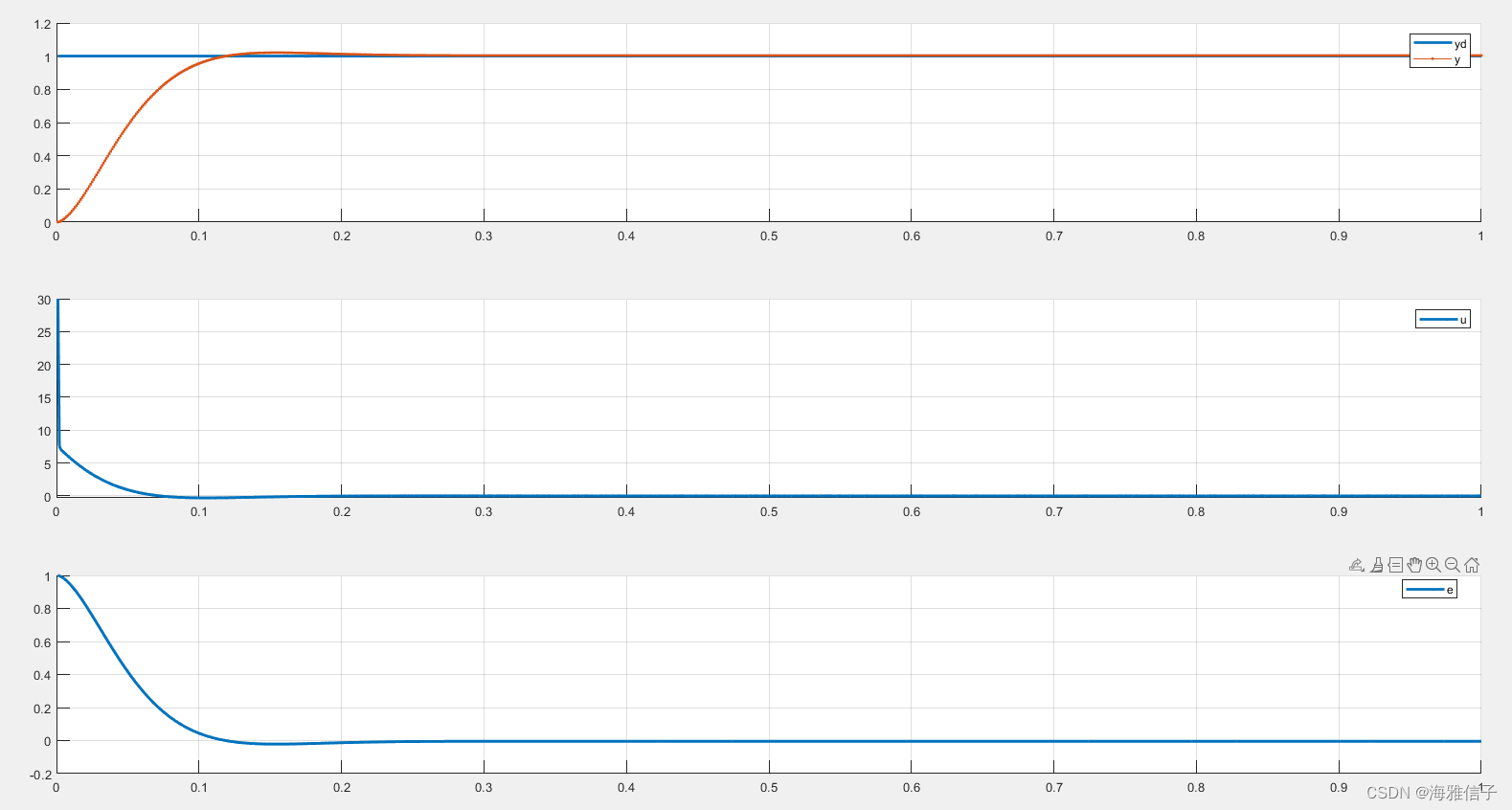
可以看到,卡尔曼滤波的效果非常明显。















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









