






一、知识蒸馏入门
1.1概念介绍
知识蒸馏(knowledge distillation)是模型压缩的一种常用的方法,不同于模型压缩中的剪枝和量化,知识蒸馏是通过构建一个轻量化的小模型,利用性能更好的大模型的监督信息,来训练这个小模型,以期达到更好的性能和精度。最早是由Hinton在2015年首次提出并应用在分类任务上面,这个大模型我们称之为teacher(教师模型),小模型我们称之为Student(学生模型)。来自Teacher模型输出的监督信息称之为knowledge(知识),而student学习迁移来自teacher的监督信息的过程称之为Distillation(蒸馏)。
1.2知识蒸馏的种类
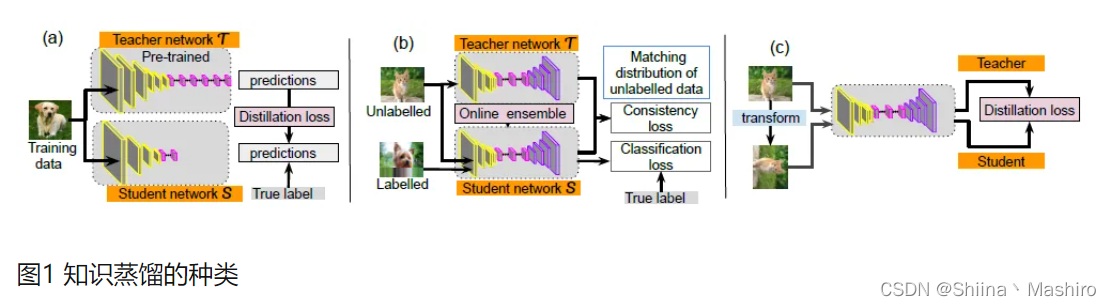
1.离线蒸馏
离线蒸馏方式即为传统的知识蒸馏,如上图(a)。用户需要在已知数据集上面提前训练好一个teacher模型,然后在对student模型进行训练的时候,利用所获取的teacher模型进行监督训练来达到蒸馏的目的,而且这个teacher的训练精度要比student模型精度要高,差值越大,蒸馏效果也就越明显。一般来讲,teacher的模型参数在蒸馏训练的过程中保持不变,达到训练student模型的目的。蒸馏的损失函数distillation loss计算teacher和student之前输出预测值的差别,和student的loss加在一起作为整个训练loss,来进行梯度更新,最终得到一个更高性能和精度的student模型。
2.半监督蒸馏
半监督方式的蒸馏利用了teacher模型的预测信息作为标签,来对student网络进行监督学习,如上图(b)。那么不同于传统离线蒸馏的方式,在对student模型训练之前,先输入部分的未标记的数据,利用teacher网络输出标签作为监督信息再输入到student网络中,来完成蒸馏过程,这样就可以使用更少标注量的数据集,达到提升模型精度的目的。
3.自监督蒸馏
自监督蒸馏相比于传统的离线蒸馏的方式是不需要提前训练一个teacher网络模型,而是student网络本身的训练完成一个蒸馏过程,如上图(c)。具体实现方式 有多种,例如先开始训练student模型,在整个训练过程的最后几个epoch的时候,利用前面训练的student作为监督模型,在剩下的epoch中,对模型进行蒸馏。这样做的好处是不需要提前训练好teacher模型,就可以变训练边蒸馏,节省整个蒸馏过程的训练时间。
1.3知识蒸馏的功能
1.提升模型精度
用户如果对目前的网络模型A的精度不是很满意,那么可以先训练一个更高精度的teacher模型B(通常参数量更多,时延更大),然后用这个训练好的teacher模型B对student模型A进行知识蒸馏,得到一个更高精度的模型。
2.降低模型时延,压缩网络参数
用户如果对目前的网络模型A的时延不满意,可以先找到一个时延更低,参数量更小的模型B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的teacher模型C来对这个参数量小的模型B进行知识蒸馏,使得该模型B的精度接近最原始的模型A,从而达到降低时延的目的。
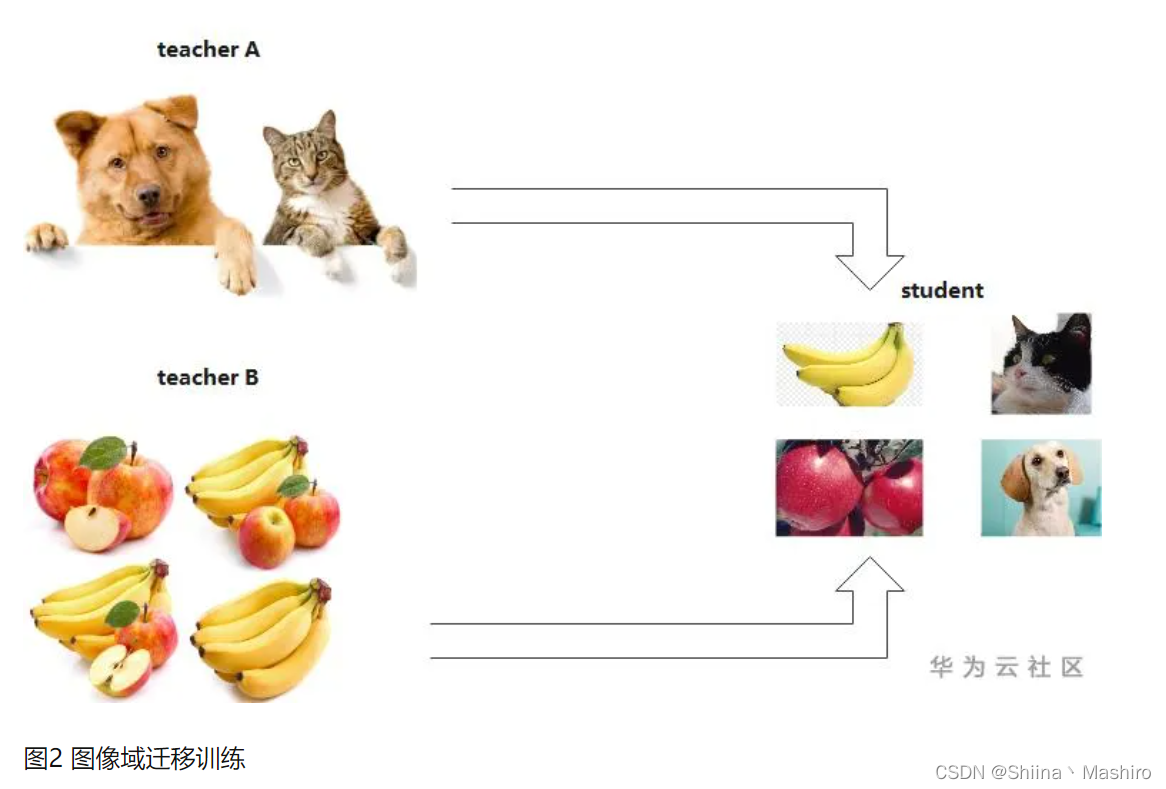
3.图片标签之间的域迁移
用户使用狗和猫的数据集训练了一个teacher模型A,使用香蕉和苹果训练了一个teacher模型B,那么就可以用这两个模型同时蒸馏出一个可以识别狗,猫,香蕉以及苹果的模型,将两个不同与的数据集进行集成和迁移。
二、知识蒸馏模型架构
2.1 hard target 和 soft target
传统training过程(hard targets): 对ground truth求极大似然
KD的training过程(soft targets): 用large model的class probabilities作为soft targets
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,KD的训练方式使得每个样本给Net-S带来的信息量大于传统的训练方式。
【举个例子】
在手写体数字识别任务MNIST中,输出类别有10个。
假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率为0.1,而其他负标签对应的值都很小,而另一个"2"更加形似"7","7"对应的概率为0.1。这两个"2"对应的hard target的值是相同的,但是它们的soft target却是不同的,由此我们可见soft target蕴含着比hard target多的信息。并且soft target分布的熵相对高时,其soft target蕴含的知识就更丰富。
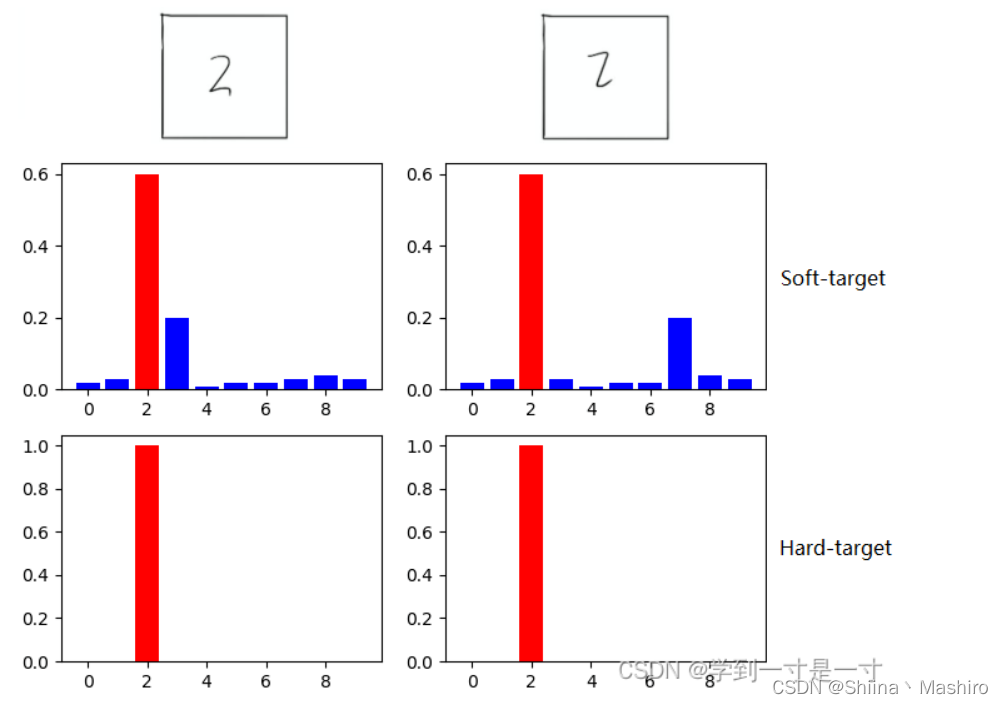
这就解释了为什么通过蒸馏的方法训练出的Net-S相比使用完全相同的模型结构和训练数据只使用hard target的训练方法得到的模型,拥有更好的泛化能力。
2.2 softmax函数
先回顾一下原始的softmax函数:
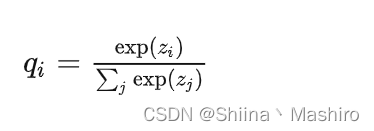
但要是直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。
下面的公式时加了温度这个变量之后的softmax函数:
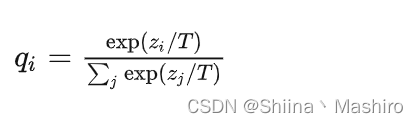
这里的T就是温度。
原来的softmax函数是T = 1的特例。 T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
2.3 知识蒸馏过程
蒸馏过程的基本模型架构
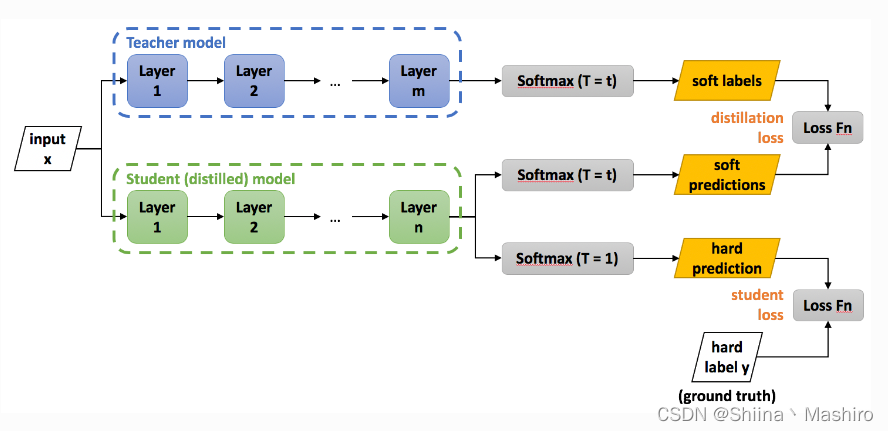
模块特点及其作用
这里会有两种角色模型
1、老师模型(Teacher-Net):作为“知识”的输出者,会将自己从数据中学习到的知识,“传授”给学生模型。其特点就是,参数量大,结构复杂,还可以由一个或者多个大模型共同组成。当然,我们不需要对老师模型做任何限制,但会有训练数据作为输入输出,假设,输入为X, 输出是P
2、学生模型(Student-Net):作为“知识”的接收者,会吸收老师传过来的“知识”。其特点一般是参数量级小,结构简单。但对其也不会有特定的限制。 假设输入也为X, 输出为Q
蒸馏的训练学习过程
步骤:(soft target就是上图中的soft labels。)
S1: 得到训练好的Teacher Model(训练数据为hard labels)
S2:
Teacher Model(T=t)得到soft targets
S3:
Student Model(T=t)、Student Model(T=1)分别得到soft predictions、hard predictions。
Distillation Loss: 将上一步得到的soft targets与soft predictions作交叉熵
Student Loss: hard predictions与hard labels作交叉熵
总的损失函数是这两部分的加权,分别赋予权重β 、 α
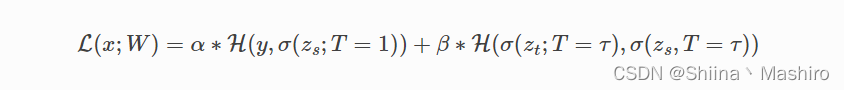
S3: 最后作测试令Student Model(T=1)
参数更新
where x is the input, W are the student model parameters, y is the ground truth label, H is the cross-entropy loss function, σ is the softmax function parameterized by the temperature T, and α and β are coefficients.
Z
s
Z_s
Zs and
Z
t
Z_t
Zt are the logits of the student and teacher respectively.

伪标记赋值
含义:首先,在标记数据上训练模型,然后使用训练后的模型预测未标记数据上的标签,从而创建伪标签。此外,将标记数据和新伪标记数据合并到用于培训数据的新数据集中。
在知识蒸馏中的应用:利用带标签数据训练好的教师模型在温度t下预测得到soft labels,在温度t下学生模型预测得到soft predictions,两者做交叉熵。
参考文章:
知识蒸馏中的温度参数
知识蒸馏综述
伪标记是一种简单的半监督学习方法
关于teacher-student(知识蒸馏)的一些思考与总结
浅谈计算机视觉中的知识蒸馏















 2652
2652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









