







大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。

如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
这篇文章主要介绍了Chatbot Arena,一个基于人类偏好的大型语言模型(LLM)评估的开源平台。文章提到,尽管大型语言模型解锁了新的功能和应用,但是它们与人类偏好的对齐仍然面临着重大挑战。为了解决这个问题,研究者们推出了Chatbot Arena。Chatbot Arena的方法论采用成对比较方式,并通过众包获取来自多样化用户群体的输入。平台已经运行了几个月,累计获得了超过24万个投票。文章描述了这个平台,分析了迄今为止收集的数据,并解释了他们正在使用的经过验证的统计方法,以有效地对模型进行评估和排名。研究者确认众包的问题足够多样化和具有辨识度,并且众包的人类投票与专家评审者的投票是一致的。这些分析共同为Chatbot Arena的信誉奠定了坚实的基础。由于其独特的价值和开源性质,Chatbot Arena已经成为最常被引用的LLM排行榜之一,被领先的语言模型开发者和公司广泛引用。文章末尾提到,他们的演示版公开可供查看。
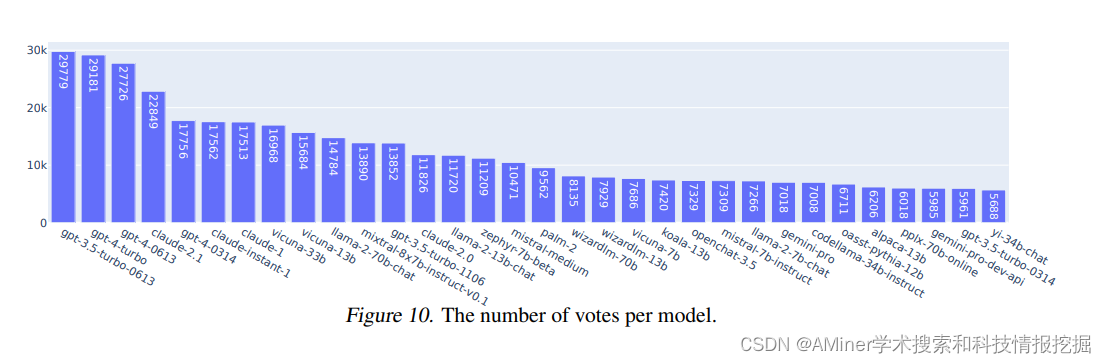
链接:https://www.aminer.cn/pub/65ea773a13fb2c6cf61fa015/?f=cs
2.On the Origins of Linear Representations in Large Language Models
这篇论文探讨了大型语言模型中表示概念的线性特征的起源。近期研究提出高级语义概念在高阶语言模型表示空间中以线性方式编码。为了研究这一现象,作者引入了一个简单的潜在变量模型来抽象和形式化下一个标记(next token)的预测概念动态。通过这一形式化框架,作者表明下一个标记预测目标函数(带有交叉熵的softmax)和梯度下降的隐性偏置共同促进了概念的线性表示。实验表明,当数据与潜在变量模型相匹配时,会涌现出线性表示,证实了这一简单结构已经足够产生线性表示。此外,作者还使用LLaMA-2大型语言模型验证了该理论的一些预测,证明了简化模型可以产生泛化的洞察。
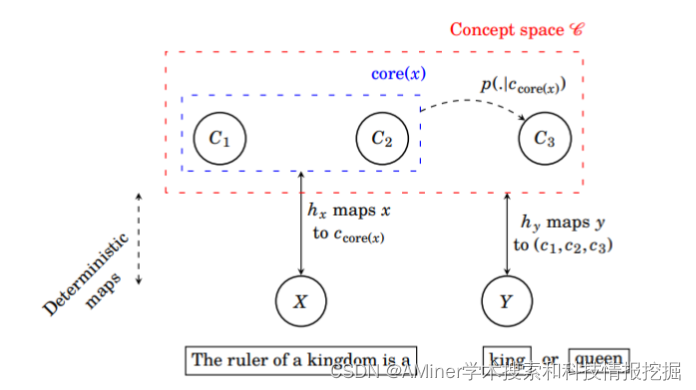
链接:https://www.aminer.cn/pub/65e9207613fb2c6cf62009e3/?f=cs
3.Generative AI for Synthetic Data Generation: Methods, Challenges and the Future
这篇论文主要介绍了利用大型语言模型(LLMs)生成合成数据的方法,特别是在数据稀缺的情境下。这一方法标志着生成式人工智能(AI)的一个显著转变。这些模型生成的数据与真实世界数据相比较具有一定竞争力,因此被视为解决资源匮乏挑战的有吸引力的解决方案。论文深入探讨了利用这些巨大的LLMs生成特定任务训练数据的高级技术。概述了方法论、评估技术、实际应用,讨论了当前的限制,并提出了未来研究的潜在途径。
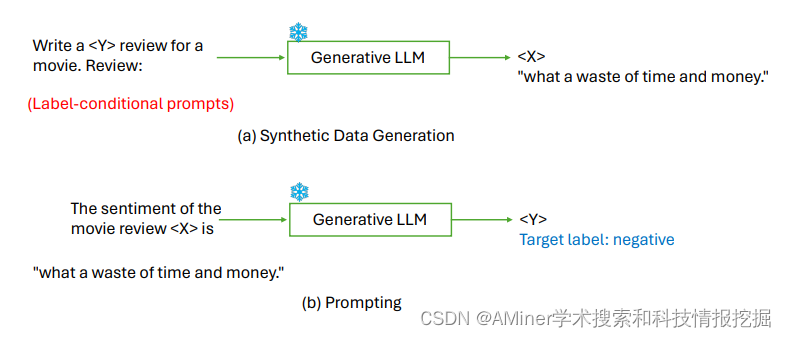
链接:https://www.aminer.cn/pub/65ea776113fb2c6cf61fc469/?f=cs
4.Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents
本文介绍了一种面向大型语言模型(LLM)代理的基于探索的轨迹优化方法,称为ETO。这种学习方法旨在提高开放LLM代理的表现。与之前仅在成功专家轨迹上进行训练的研究不同,该方法允许代理从探索失败中学习。通过迭代优化框架,提高了性能。在探索阶段,代理与环境互动,完成给定任务,同时收集失败轨迹以创建对比轨迹对。在随后的训练阶段,代理使用如DPO的对比学习方法更新其策略。这种探索和训练的迭代循环促进了代理的持续改进。我们在三个复杂任务上的实验表明,ETO的性能始终优于基线,并且在一系列缺乏专家轨迹的场景中,ETO的有效性也得到了证明。
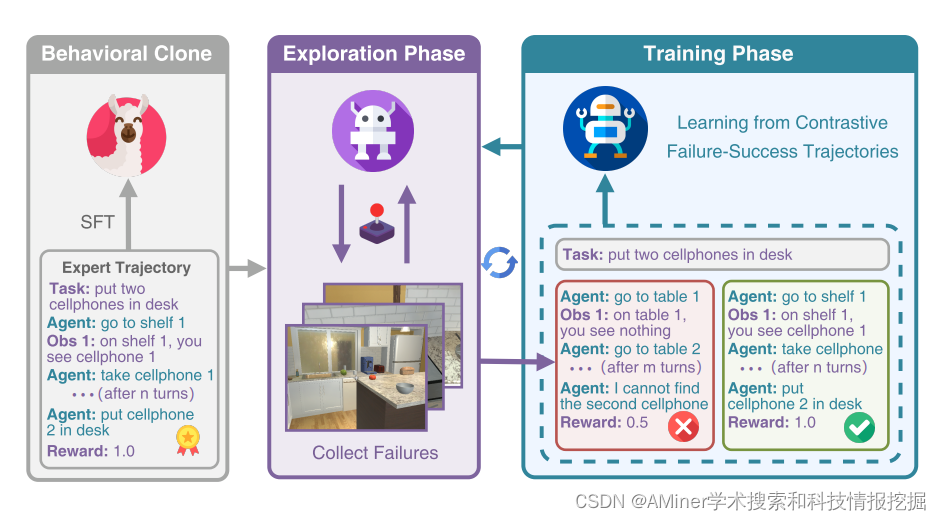
链接:https://www.aminer.cn/pub/65e7d20613fb2c6cf6f5b22e/?f=cs
5.Teaching Large Language Models to Reason with Reinforcement Learning
这篇论文探讨了通过强化学习让人工智能语言模型(LLM)进行推理的能力。在受到人类反馈的强化学习(RLHF)成功启发下,研究了多种从反馈中学习的算法(包括专家迭代、近端策略优化(PPO)和基于回报的强化学习),以改进语言模型的推理能力。文中研究了模型在稀疏和密集奖励下,如何通过启发式方法和通过学习得到的奖励模型进行学习。此外,研究还从不同大小的模型和初始化开始,包括有监督的微调(SFT)数据和没有SFT数据的情况。研究发现,所有算法表现相当,专家迭代在大多数情况下表现最佳。令人惊讶的是,专家迭代的样本复杂性与PPO相似,从预训练检查点开始,最多需要大约10^6个样本才能收敛。研究还探讨了模型在强化学习训练中为什么不能显著超出SFT模型已经产生的解决方案,以及SFT训练中maj@1和pass@96指标表现之间的权衡,而强化学习训练如何同时提高这两个指标。最后,本文讨论了这些发现对RLHF以及强化学习在LLM微调中未来角色的影响。
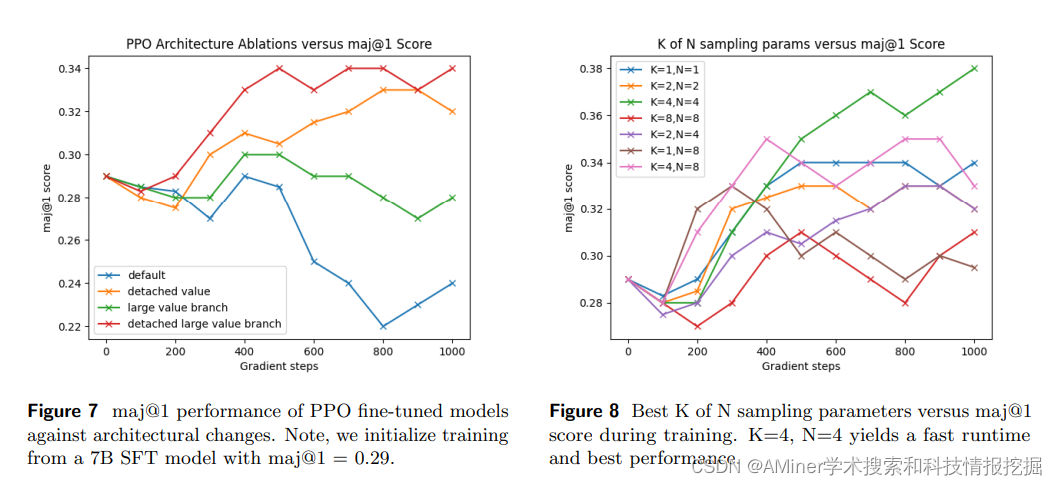
链接:https://www.aminer.cn/pub/65ea801113fb2c6cf6266234/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









