






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Position Engineering: Boosting Large Language Models through Positional Information Manipulation
这篇论文介绍了一种新的技术,名为位置工程(Position Engineering),旨在更有效地指导大型语言模型(LLMs)。与需要修改提供给LLMs的文本的提示工程不同,位置工程只是改变提示中的位置信息,而无需修改文本本身。作者在两个广泛使用的LLM场景中评估了位置工程:检索增强生成(RAG)和在位学习(ICL)。研究结果表明,在两种情况下,位置工程都显著提高了基线性能。因此,位置工程是一种利用大型语言模型能力的很有前景的新策略。
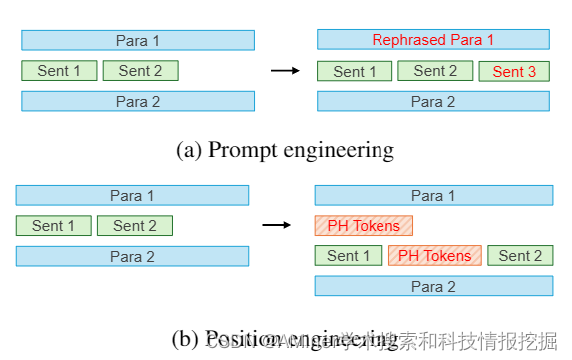
链接:https://www.aminer.cn/pub/66207e7f13fb2c6cf6b87dc5/?f=cs
2.Many-Shot In-Context Learning
这篇论文探讨了在大规模语言模型(LLM)中实现多示例在上下文中的学习(ICL),即在推理时从上下文中提供几个示例而无需进行任何权重更新。通过扩展上下文窗口,研究者们研究了在几百个或几千个示例 - 多示例范围内实现ICL的可行性。他们发现,从少示例到多示例,各种生成性和判别性任务的性能都有显著提高。然而,多示例ICL受限于可用的手动生成的示例数量。为了缓解这一限制,研究者们探索了两种新的设置:强化学习和无监督学习。强化学习ICL使用模型生成的链式思考理由代替手动示例,而无监督学习ICL则完全移除理由,仅用领域特定的问题提示模型。他们发现,这两种方法在多示例范围内都非常有效,尤其是在复杂的推理任务上。最后,研究者们证明了与少示例学习相比,多示例学习能够更有效地克服预训练偏差,并能够使用数值输入学习高维函数。他们的分析还揭示了下一个令牌预测损失作为下游ICL性能指标的局限性。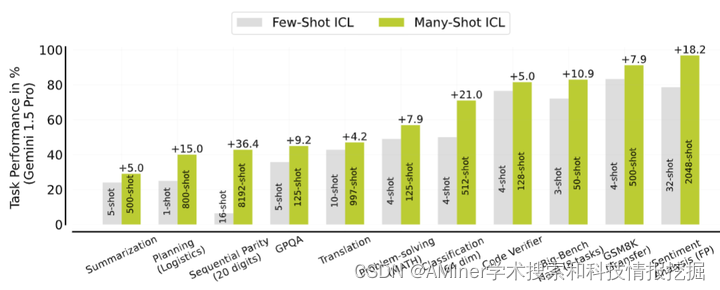
链接:https://www.aminer.cn/pub/66207e7f13fb2c6cf6b87d01/?f=cs
3.Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
论文探讨了目前广泛用于对大型语言模型(LLM)与人类偏好对齐的基于人类反馈的强化学习(RLHF)方法。这些方法大致可以分为基于奖励或奖励自由两种。像ChatGPT和Claude这样的新应用使用了基于奖励的方法,首先学习一个奖励模型,然后应用演员-评论家算法,如近端策略优化(PPO)。然而,在学术基准测试中,最先进的结果通常是通过奖励自由方法实现的,如直接偏好优化(DPO)。论文问DPO是否真的优于PPO以及PPO在这些基准测试中表现不佳的原因。作者首先对DPO的算法特性进行了理论和实证研究,并指出DPO可能存在根本性的局限性。同时,作者还全面检查了PPO,揭示了PPO在微调LLM时表现最佳的关键因素。最后,作者在多个RLHF测试环境中对DPO和PPO进行了基准测试,包括从对话到代码生成的各种场景。实验结果显示,PPO能够在所有情况下超越其他对齐方法,并在具有挑战性的代码竞赛中取得最先进的结果。
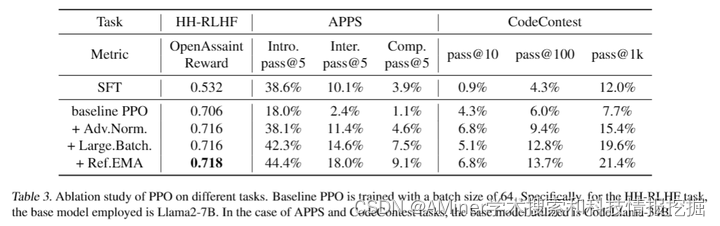
链接:https://www.aminer.cn/pub/661f2cf013fb2c6cf6b178f3/?f=cs
4.How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs’ internal prior
这篇论文探讨了大型语言模型(LLM)与检索增强生成(RAG)模型之间的“拉锯战”。RAG模型通常用于纠正大型语言模型的虚构现象,并为大型语言模型提供最新的知识。然而,当LLM独立回答问题时出现错误,提供正确的检索内容是否总能纠正错误?相反,当检索内容不正确时,LLM是否知道忽略错误信息,或者它会重复错误信息?为了解答这些问题,作者系统地分析了当LLM的内部知识(即其先验)与检索信息不一致时的“拉锯战”。作者在有和没有参考文档的多个数据集上测试了GPT-4和其他LLM的问答能力。结果发现,提供正确的检索信息可以纠正大多数模型错误(准确率为94%)。然而,当参考文档随着错误值的增加而被干扰时,当LLM的内部先验较弱时,它更可能重复错误的、修改过的信息,但当先验较强时,它更抗拒这样做。类似地,作者还发现,修改过的信息与模型的先验越偏离,模型就越不可能偏好它。这些结果突出了模型先验知识与参考文档中呈现的信息之间的潜在紧张关系。
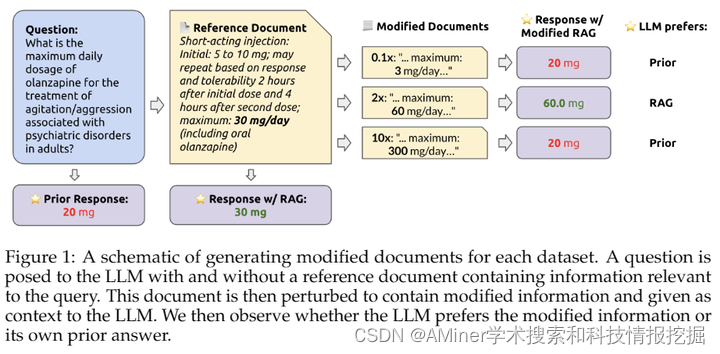
链接:https://www.aminer.cn/pub/661f2cf013fb2c6cf6b176e0/?f=cs
5.Foundational Challenges in Assuring Alignment and Safety of Large Language Models
这篇论文指出,在大语言模型(LLM)的规范和安全方面存在18个基础性挑战。这些挑战被分为三类:对LLM的科学理解、开发和部署方法以及社会技术挑战。基于这些识别出的挑战,作者提出了200多个具体的研究问题。

链接:https://www.aminer.cn/pub/661dec8113fb2c6cf6c8f8fb/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









