






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning
这篇论文探讨了大规模语言模型(LLM)在精细调整过程中存在的内存消耗问题。尽管自大型语言模型首次出现以来,机器学习领域已经取得了显著的进步,但这些模型的巨大内存消耗已成为大规模训练的主要障碍。为了缓解这一问题,已经提出了参数有效精细调整技术,如低秩适应(LoRA),但其在大多数大规模精细调整设置中的性能仍无法与全参数训练相匹配。本文研究了LoRA在精细调整任务中的层间性质,并观察到不同层之间权重要素的不寻常偏斜。利用这一关键观察结果,发现了一种出奇简单且有效的训练策略,即层间重要性抽样AdamW(LISA),它在各种设置中的内存成本与LoRA相当,但性能优于LoRA和全参数训练。实验结果显示,在相似或更少的GPU内存消耗下,LISA在下游精细调整任务中的表现超过了LoRA甚至全参数训练,LISA在MT-Bench得分上始终比LoRA高出11%-37%。在大规模模型上,特别是LLaMA-2-70B,LISA在MT-Bench、GSM8K和PubMedQA上的表现与LoRA相当或更优,这证明了它在不同领域中的有效性。
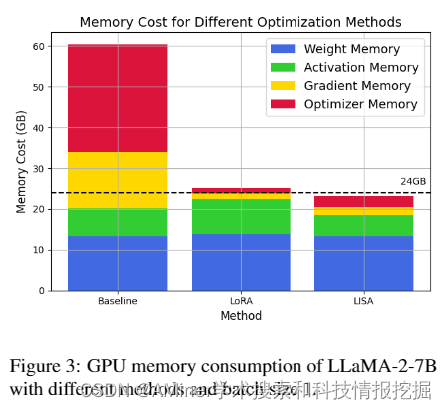
链接:https://www.aminer.cn/pub/66037de513fb2c6cf6e64b9f/?f=cs
2.Enhancing Legal Document Retrieval: A Multi-Phase Approach with Large Language Models
这篇论文探讨了如何通过大语言模型提高法律文档检索的效率。近年来,像GPT-3.5、GPT-4和LLaMA这样具有数十亿参数的大型语言模型越来越常见,许多研究也尝试探讨如何通过有效的提示技术来利用这些大型语言模型的力量解决各种研究问题。但在法律数据领域,尤其是在直接应用提示技术时,大量且内容较长的法律文章使得检索任务变得具有挑战性。该研究将提示技术作为检索系统的最后一阶段,并在这一阶段之前设定了两个辅助阶段:基于BM25的预排序和基于BERT的重新排序。在COLIEE 2023数据集上的实验表明,将提示技术集成到检索系统中可以显著提高检索的准确性。然而,错误分析揭示了一些现有的检索系统问题,这些问题仍然需要解决。
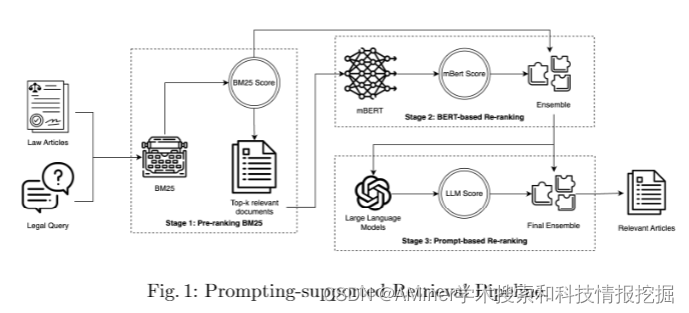
链接:https://www.aminer.cn/pub/6604cf2313fb2c6cf6b8a631/?f=cs
3.A comparison of Human, GPT-3.5, and GPT-4 Performance in a University-Level Coding Course
这篇论文比较了人类、GPT-3.5和GPT-4在大学级别编程课程中的表现。研究评估了ChatGPT变体、GPT-3.5和GPT-4(有无提示工程)在大学级别的物理编程作业中的表现,这些作业使用Python语言完成。将50份学生提交的作品与50份AI生成的作品在不同类别中进行比较,并由三位独立的评分员盲评,共收集了300个数据点。学生的平均得分为91.9%(标准误差:0.4),超过了表现最好的AI提交类别,即经过提示工程的GPT-4,其得分为81.1%(标准误差:0.8)——这是一个统计学上显著的差异(p = 2.482 × 10^-10)。提示工程显著提高了GPT-4(p = 1.661 × 10^-4)和GPT-3.5(p = 4.967 × 10^-9)的得分。此外,盲评员还被要求猜测提交作品的作者,使用一个四点Likert量表从“绝对是AI”到“绝对是人类”。他们准确地识别了作者,将有92.1%被归类为“绝对是人类”的作品是由人类撰写的。如果简化为此二进制的“AI”或“人类”分类,则平均准确率为85.3%。这些发现表明,虽然AI生成的作品在质量上接近大学学生的作品,但它们通常可以被人类评估员检测出来。
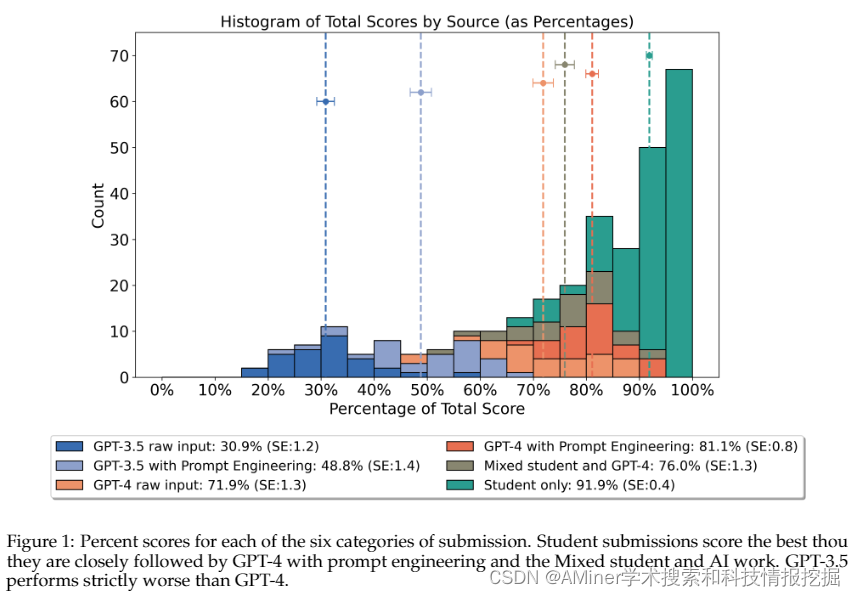
链接:https://www.aminer.cn/pub/66023c0313fb2c6cf6aa8192/?f=cs
4.MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions
这篇论文介绍了一种新的自监督图像检索模型MagicLens,该模型能够处理开放性的文本指令。传统的图像检索方法主要基于图像的视觉相似性,而MagicLens则通过分析同一网页上自然出现的图像对之间的多种隐含关系,利用大型多模态模型和大型语言模型合成指令,从而实现更加丰富的关系检索。该模型在3670万(查询图像、指令、目标图像)的三元组数据上进行训练,这些三元组数据从网页中挖掘出了丰富的语义关系。实验结果显示,MagicLens在多个图像检索任务基准测试中取得了与或优于先前最先进方法的结果,并且在多个基准测试中,其模型大小只有先前最先进方法的50分之一,表现出了优异的性能。此外,对一个未见过的140万图像数据集的人类分析进一步证明了MagicLens支持多样化的搜索意图。
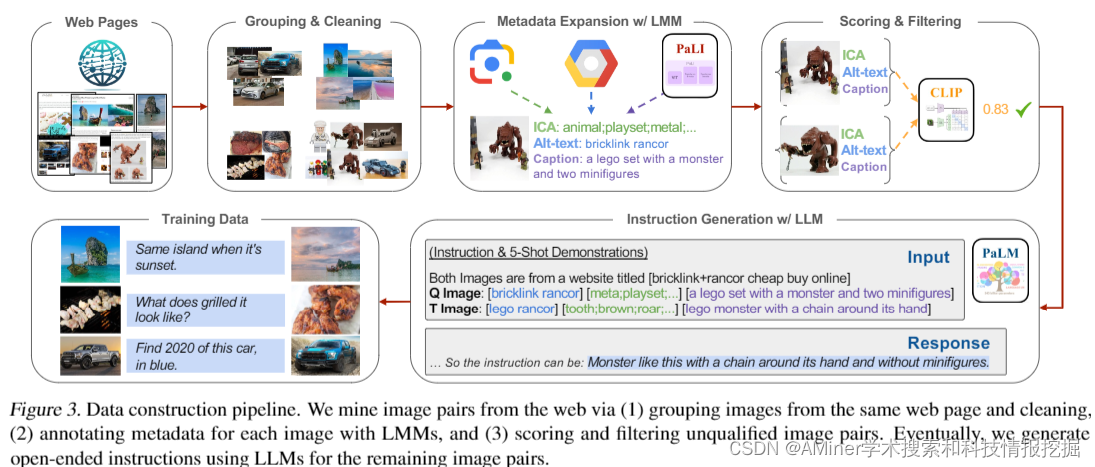
链接:https://www.aminer.cn/pub/6606208b13fb2c6cf61c6e92/?f=cs
5.AIOS: LLM Agent Operating System
本文介绍了一种名为AIOS的LLM智能代理操作系统。该系统将大型语言模型整合到操作系统中,作为操作系统的“大脑”,实现具有灵魂的操作系统,这是迈向通用人工智能(AGI)的重要一步。AIOS旨在优化资源分配,便于代理之间的上下文切换,实现代理的并发执行,为代理提供工具服务,并维护代理的访问控制。文章概述了该操作系统的架构,阐述了它旨在解决的核心挑战,并提供了AIOS的基本设计和实现。通过实验表明,AIOS模块在多个代理的并发执行中具有可靠性和效率。该项目的目标是不仅提高基于LLM的智能代理的性能和效率,而且还为AIOS生态系统的未来发展和部署开辟新的途径。
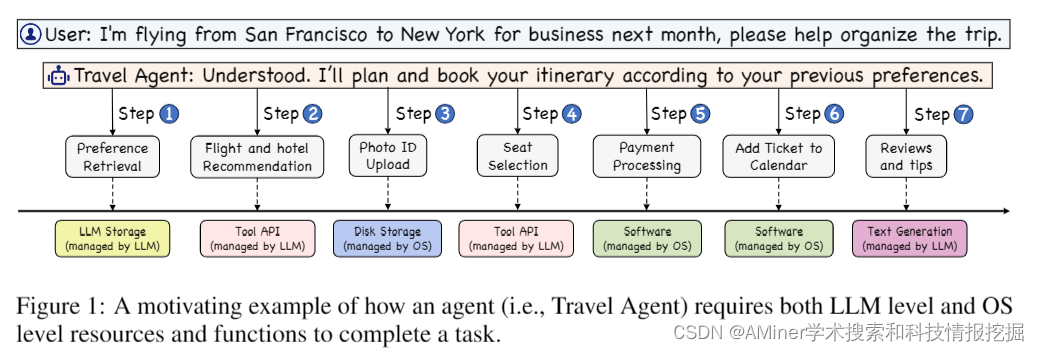
链接:https://www.aminer.cn/pub/66023c0213fb2c6cf6aa7d1e/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









