






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Automatic Programming: Large Language Models and Beyond
这篇论文探讨了自动编程问题,特别是随着GitHub Copilot等基于大型语言模型(LLM)的工具的出现,自动编程越来越受欢迎。然而,自动生成的代码在部署时面临着质量和技术信任的挑战。文章研究了自动编码的一般问题,以及代码质量、安全性和程序员责任等相关问题,这些问题是组织在决定使用自动生成的代码时需要考虑的关键问题。文章还讨论了软件工程方面的进展,如程序修复和分析,如何促进自动编程。最后,文章以展望未来的编程环境结束,预测程序员可能需要转换到不同的角色,以充分利用自动编程的力量。自动从LLM修复自动生成的程序,可以帮助产生更有保证的代码,并附有保证的证据。
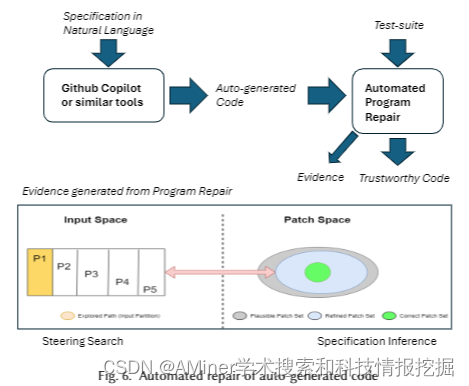
链接:https://www.aminer.cn/pub/663839b401d2a3fbfcdc82ab/?f=cs
2.Aloe: A Family of Fine-tuned Open Healthcare LLMs
本文探讨了在大型语言模型(LLM)在医疗和医学领域的功能不断进步的背景下,如何通过竞争性的开源模型来保护公众利益。目前,虽然高质量的开放源代码基础模型越来越多,但持续预训练的效果变得越来越不确定。为了改善现有的开源模型,研究者们推出了Aloe家族,这是一组在其规模范围内具有高度竞争力的开源医疗LLM。Aloe模型是基于当前最好的基础模型(Mistral,LLaMA 3)进行训练的,使用了一个新的自定义数据集,该数据集结合了通过合成链式思维(CoT)改进的公共数据源。Aloe模型经过对齐阶段,成为首批使用直接偏好优化进行政策对齐的开源医疗LLM之一,为医疗LLM的道德表现设定了新标准。模型评估扩展到了包括各种偏见和毒性数据集、专门的红队努力和一个对医疗LLM急需的风险评估。最后,为了探索当前LLM在推理方面的极限,研究了几种高级提示工程策略,以提高跨基准测试的表现,为开源医疗7B LLM取得了前所未有的最先进结果。
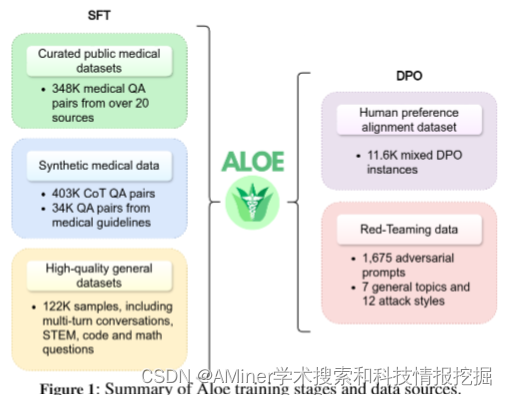
链接:https://www.aminer.cn/pub/663839ae01d2a3fbfcdc7acd/?f=cs
3.Understanding LLMs Requires More Than Statistical Generalization
在过去十年里,深度学习理论的研究日益繁荣,试图回答“为什么深度学习能够泛化”的问题。这一进展得益于一个强大的视角转变:研究过参数化模型在插值范围内的行为。然而,本文认为,由于大型语言模型(LLMs)的一些令人向往的特性并非是良好统计泛化的结果,因此需要另一个理论上的视角转变。我们的核心论点基于这样一个观察:自回归(AR)概率模型本质上是不可识别的:即使模型零或接近零的KL散度——即测试损失相等——也可能表现出明显不同的行为。我们通过数学示例和实证观察来支持我们的立场,并通过三个案例研究说明了非可识别性为什么具有实际相关性:(1)零样本规则外推的非可识别性;(2)上下文中学习的近似非可识别性;(3)微调可塑性的非可识别性。我们回顾了关注LLM相关泛化度量、转移性和归纳偏置的有前景的研究方向。
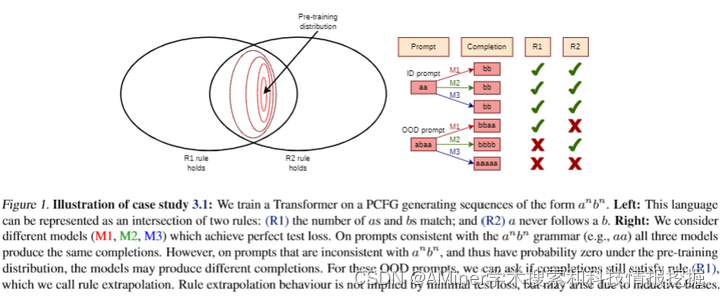
链接:https://www.aminer.cn/pub/663839ae01d2a3fbfcdc7b1b/?f=cs
4.Large Language Models are Inconsistent and Biased Evaluators
大型语言模型是不一致且有偏见的评估者。大型语言模型(LLM)的零样本能力使得它们能够成为各种任务中灵活、无需参考的评分工具,从而成为NLP中常见的评分者。然而,这些LLM评分者的鲁棒性相对较少受到研究;现有工作主要追求与人类专家评分相关联的最佳性能。在本文中,我们使用SummEval数据集进行了一系列分析,确认了LLM是不一致且有偏见的评估者,因为它们:(1)表现出熟悉性偏见,即对较低困惑度的文本的偏好,(2)显示出偏斜和有偏的评分分布,(3)在多属性判断中经历锚定效应。我们还发现,LLM是不一致的评估者,它们的“样本间”一致性低,且对提示差异的敏感度低,这对于人类理解文本质量是微不足道的。此外,我们还分享了配置LLM评分者的配方以减轻这些局限性。在RoSE数据集上的实验结果表明,我们的方法超过了现有的最佳LLM评分者。
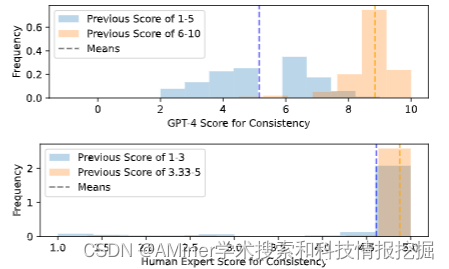
链接:https://www.aminer.cn/pub/663839ae01d2a3fbfcdc7a2c/?f=cs
5.Efficient and Economic Large Language Model Inference with Attention Offloading
这篇论文探讨了基于Transformer的大型语言模型(LLM)在实际应用中遇到的计算效率问题。由于这些模型采用自回归方式生成文本,导致在不同的操作阶段对计算资源的需求各不相同,特别是在注意力机制这一部分,其内存密集型的特性与现代化加速器的长处不匹配,随着上下文长度的增加,这种不匹配问题尤为明显。为了解决这个问题,论文提出了“注意力卸载”的概念,即使用一系列成本低廉、优化内存的设备来处理注意力操作,而高端加速器则负责模型的其他部分。这种异构的设置确保每个组件都能根据其特定的工作负载进行优化,从而最大化整体性能和成本效益。论文通过详尽的分析和实验验证了将注意力计算分散到多个设备上是可行的,并且不同设备之间的通信带宽需求可以借助现有的网络技术得到有效管理。为了进一步验证理论,研究者开发了Lamina系统,一个整合了注意力卸载的LLM推理系统。实验结果显示,Lamina系统在每美元的吞吐量方面比同质解决方案高出1.48倍到12.1倍。
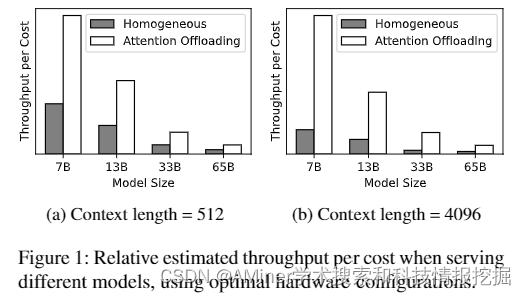
链接:https://www.aminer.cn/pub/663839ae01d2a3fbfcdc7a83/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









