






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.“Is ChatGPT a Better Explainer than My Professor?”: Evaluating the Explanation Capabilities of LLMs in Conversation Compared to a Human Baseline
本文研究了大型语言模型(LLM)在对话中解释能力的有效性,并与人类基线进行了比较。研究聚焦于对话式的解释方法,因为这种方法高度适应性和互动性强。该研究基于先前的解释行为工作,该框架用于理解解释者和被解释者在对话中使用不同的策略来解释、理解和与对方互动。研究使用了Wachsmuth等人从WIRED YouTube系列中构建的5-Levels数据集,并由Booshehri等人用解释行为进行了注释。这些注释提供了一个框架,用于理解解释者和被解释者在构造回应时如何组织他们的回应。随着过去一年生成式AI的兴起,研究者希望更好地理解LLM的能力以及它们如何在对话环境中增强专家解释者的能力。为了实现这一目标,5-Levels数据集(我们使用Booshehri等人2023年用解释行为注释的数据集)使我们能够审核LLM在参与解释对话方面的能力。为了评估LLM在生成解释性回应方面的有效性,我们比较了三种不同的策略,并请人类 annotators 评估了这三种策略:人类解释者回应、GPT4标准回应和GPT4带有解释性动作的回应。

链接:https://www.aminer.cn/pub/667cc7d901d2a3fbfc0ab009/?f=cs
2.A Closer Look into Mixture-of-Experts in Large Language Models
本文探讨了混合专家(MoE)架构在大型语言模型中的应用。该架构通过仅激活每个标记的子集参数,在不牺牲计算效率的情况下增加模型大小,从而在性能和训练成本之间实现了更好的平衡。然而,MoE的潜在机制尚需深入研究,其模块化程度也存在疑问。论文首次尝试理解基于MoE的大型语言模型的内部运作机制。具体来说,我们全面研究了三种最近基于MoE的模型的参数化和行为特征,并揭示了一些有趣的观察结果,包括:(1) 神经元表现得像细粒度的专家。(2) MoE的路由器通常选择输出范数较大的专家。(3) 随着层数的增加,专家多样性增加,而最后一层是个例外。基于这些观察结果,我们还为广泛的MoE从业者提供了一些建议,例如路由器设计和专家分配。我们希望这项工作能为未来关于MoE框架和其他模块化架构的研究提供启示。
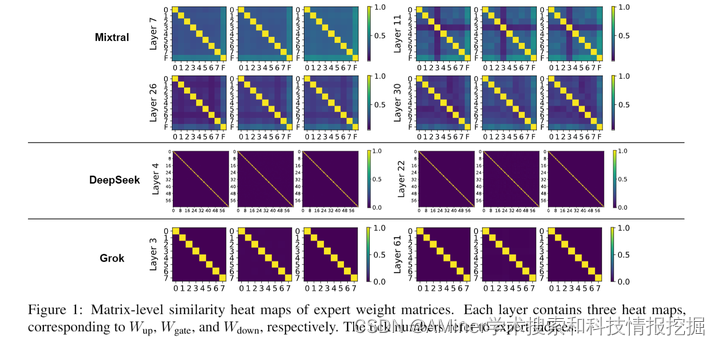
链接:https://www.aminer.cn/pub/667cc7d501d2a3fbfc0aa959/?f=cs
3.Do LLMs dream of elephants (when told not to)? Latent concept association and associative memory in transformers
大型语言模型(LLM)具有存储和回忆事实的能力。通过使用开源模型进行实验,我们发现这种回忆事实的能力可以很容易地通过改变上下文来操纵,甚至不改变事实的含义。这些发现表明,LLM可能表现得像一个关联记忆模型,其中上下文中的某些代币作为检索事实的线索。我们通过研究 transformer,LLM的构建模块,如何完成此类记忆任务来探讨这种属性。我们研究了一个简单的潜在概念关联问题,用一层 transformer 解决了该问题,从理论和实证两方面证明了 transformer 通过自注意力收集信息,并使用值矩阵进行关联记忆。

链接:https://www.aminer.cn/pub/667cc7d501d2a3fbfc0aaa0e/?f=cs
4.From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data
本文研究了大规模语言模型(LLM)在处理长上下文输入时的信息检索和保持推理能力存在的局限性。为了解决这些问题,研究者提出了一种利用精心设计的合成数据集进行微调的方法,该数据集包括数值键值检索任务。实验结果表明,在GPT-3.5 Turbo和Mistral 7B等模型上进行这种微调,可以显著提高LLM在长上下文设置中的信息检索和推理能力。研究还发现,微调后的LLM在通用基准测试上的表现几乎保持不变,而其他基线长上下文增强数据微调的LLM可能会导致虚构现象。该研究强调了利用合成数据微调以提高LLM在长上下文任务表现的可能性。
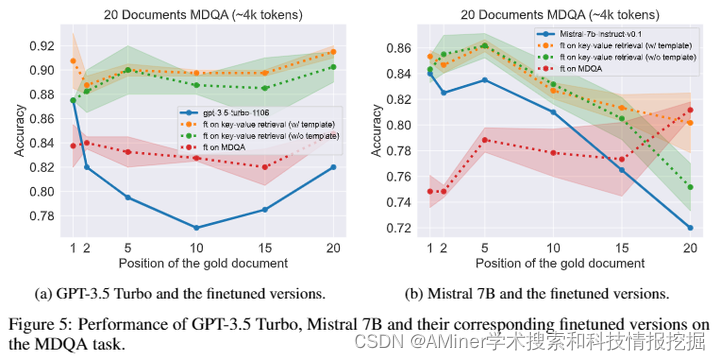
链接:https://www.aminer.cn/pub/667e191d01d2a3fbfc79d267/?f=cs
5.Revealing Fine-Grained Values and Opinions in Large Language Models
本文研究了大型语言模型(LLM)中的细微价值观和观点。通过揭示大型语言模型中的潜在价值观和观点,可以帮助识别偏见并减轻潜在的伤害。最近的研究通过向LLM呈现调查问题,并量化它们对道德和政治敏感声明的立场来实现这一点。然而,LLM产生的立场可能因提示方式的不同而有很大差异,对于给定的立场有多种论证方式。本文通过分析6个LLM对政治坐标测试(PCT)中62个命题的156k个回应,这些回应是通过420个提示变体生成的,来解决这个问题。我们进行了粗略的立场分析以及对于这些立场的纯文本解释的细微分析。在细微分析中,我们提出通过识别回应中的刻板印象来找出提示之间的相似短语:在不同的提示中反复出现且一致的语义相似短语,揭示给定LLM倾向于产生的文本模式。研究发现,在提示中添加人口统计特征对PCT的结果有显著影响,反映出偏见,以及当激发封闭形式与开放领域回应时的测试结果之间的差异。此外,通过刻板印象揭示的纯文本理由模式表明,即使立场相反,模型和提示之间也会反复生成类似的解释。
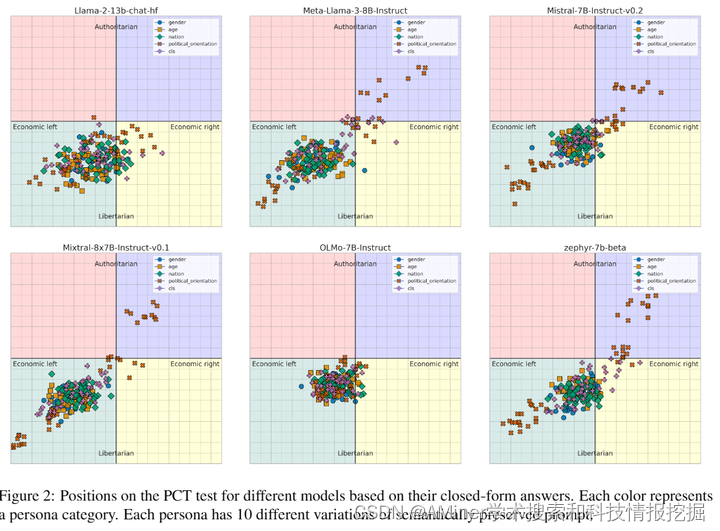
链接:https://www.aminer.cn/pub/667e191d01d2a3fbfc79d21c/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









