







《白话机器学习》(学习笔记)
白话机器学习(回归)
几个机器学习非常擅长的任务:
1.回归(预测)
2.分类(2分类:男女性别区分;多分类:0~9数字识别)
3.聚类(通过成绩单判断学生是否偏科)
其中,
有监督学习就是使用有标签的数据进行的学习(回归、分类)
无监督学习就是使用没有标签的数据进行的学习(聚类)
学习回归——基于广告费预测点击量
设置问题:尝试进行根据广告费预测点击量的任务

点击量有噪声(有变化),所以函数并不能完整通过所有点
定义一次函数表达式
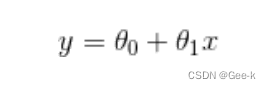
已知y=点击量,x=广告费。随机设另外两个参数,然后代入x=100时,看y的值是否与上图数据一致。不一致,接下来就是通过机器学习去求算参数的值。
最小二乘法
先把公式换成这样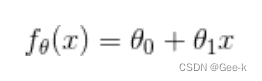 已知图上的点为训练数据,将训练数据中的广告费代入函数,再将求得的点击量与训练数据中的点击量做对比,然后找出两者差最小的西塔
已知图上的点为训练数据,将训练数据中的广告费代入函数,再将求得的点击量与训练数据中的点击量做对比,然后找出两者差最小的西塔
最理想的情况是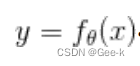 ,因为不可能让所有点的误差为0,所以我们要做的是让所有点的误差之和尽可能地小。
,因为不可能让所有点的误差为0,所以我们要做的是让所有点的误差之和尽可能地小。
找出合适的西塔值,想办法缩小误差虚线的高度,就能预测正确的点击量了。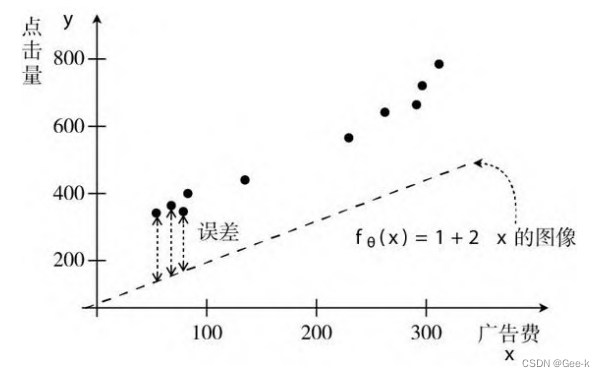
假设有n个训练数据,那么它们的误差之和可以用这样的表达式表示。这个表达式称为目标函数
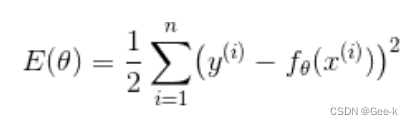 其中x(i),y(i)指的是第i个训练数据。
其中x(i),y(i)指的是第i个训练数据。
我们对每个训练数据的误差取平方之后,全部相加,然后乘2分之1。这么做是为了找到使Exita的值最
小的 。这样的问题称为最优化问题。
为什么取平方
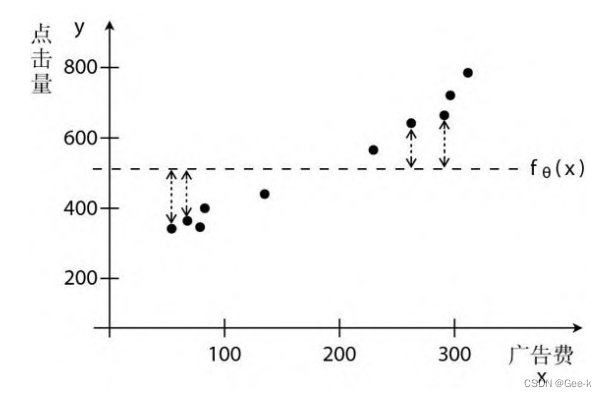 如果只是简单地计算差值,我们就得考虑误差为负值的情况。如果是上图这种情况,那么很有可能误差最后的求和为0,看似函数很完美,其实却是有很大的误差。
如果只是简单地计算差值,我们就得考虑误差为负值的情况。如果是上图这种情况,那么很有可能误差最后的求和为0,看似函数很完美,其实却是有很大的误差。
为什么乘以2分之1
后面微分相关(方便消去后期平方微分后的2),并且乘以一个正的常数。函数的形状就会被横向压扁或者纵向拉长,但函数本身取最小值的点是不变的。
最小二乘法
修改参数西塔,让这个值E(西塔变小,也就是让误差变小
最速下降法(梯度下降法)
由于一边不停的更新西塔,计算E,再不停的与y相比较的做法实在是太慢了,耗时耗力,所以就想到用微分解决问题。结合增减表
微分是计算变化的快慢程度时使用的方法
根据导数的符号来决定移动X的方向。只要向与导数的符号相反的方向移动 X,g(X) 就会自
然而然地沿着最小值的方向前进了。
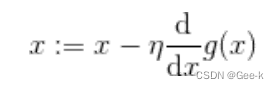 A := B 这种写法,它的意思是通过 B 来定义 A
A := B 这种写法,它的意思是通过 B 来定义 A
n是学习率。如果n较大,那么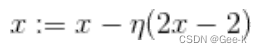 会在两个值上跳来跳去,甚至有可能远离最小值。这就是发散状态。而当n较小时,移动量也变小,更新次数就会增加,但是值确实是会朝着收敛的方向而去。
会在两个值上跳来跳去,甚至有可能远离最小值。这就是发散状态。而当n较小时,移动量也变小,更新次数就会增加,但是值确实是会朝着收敛的方向而去。
接下来回来我们的目标函数,由于其中的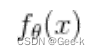 中包含两个参数,属于双变量函数。所以要使用偏微分,所以得到
中包含两个参数,属于双变量函数。所以要使用偏微分,所以得到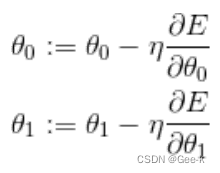
结合复合函数的微分,我们可以得到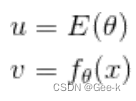 再分别去考虑它们
再分别去考虑它们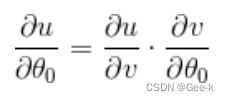
最后得到参数的更新表达式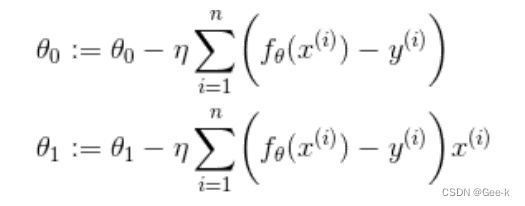 就可以找到正确的一次函数
就可以找到正确的一次函数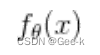 了
了
多项式回归
对于上面讲的例子来说,使用的是一次函数,图像是直线。但对于实际情况来讲,曲线的拟合情况远远比直线更好。
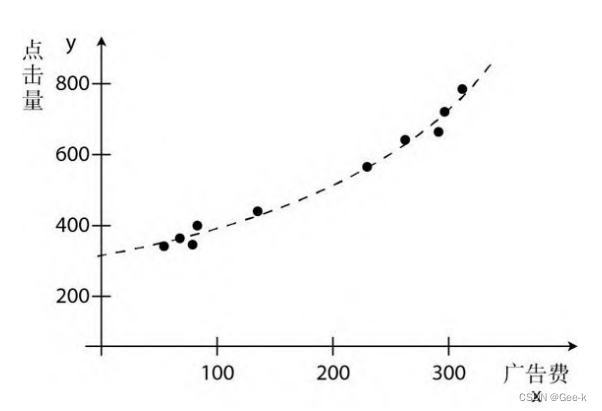
所以我们可以重新定义f(x),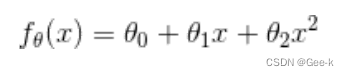
或者用更大次数的表达式来表示更复杂的曲线。(虽然次数越大拟合得越好,但难免也会出现过拟合的问题)
用目标函数对 偏微分
偏微分
参数更新表达式:
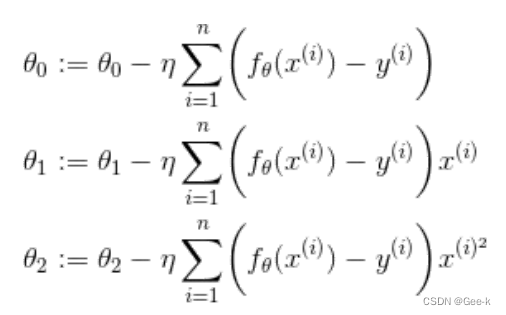
像这样增加函数中多项式的次数,然后再使用函数的分析方法被称为多项式回归**
多重回归
之前只是根据广告费来预测点击量,现在呢,决定点击量的除了广告费之外,还有广告的展示位置和广告版面的大小等多个要素
为了让问题尽可能地简单,这次我们只考虑广告版面的大小
设广告费为X1、广告栏的宽为X2、广告栏的高为X3,那么f(x)可以表示如下:
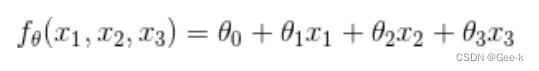
简化表达式写法
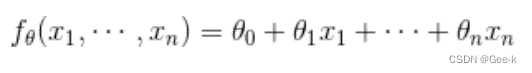
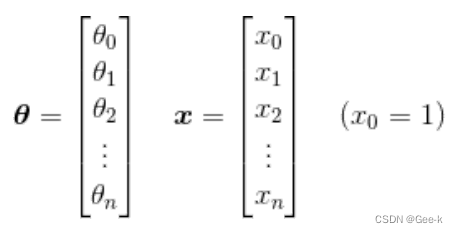
不过每次都像这样写n个X岂不是很麻烦?所以我们还可以把参数xita和变量X看作向量。
把参数xita和变量X用列向量来表示
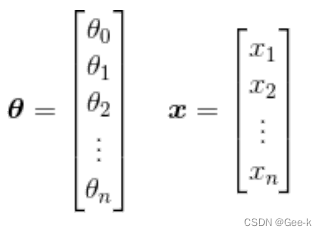 但是xita和X的维度不同。所以要做如下变换。
但是xita和X的维度不同。所以要做如下变换。
求xita转置之后,计算一下它与X相乘的结果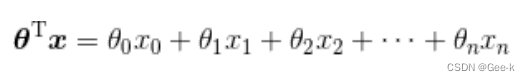
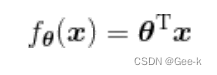
然后使用f(x)来更新参数表达式,依然是求偏微分。复合函数求微分这里是一样的。
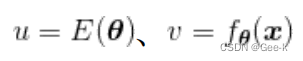
然后为了一般化,可以考虑对第j个元素xitaj偏微分
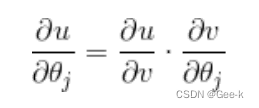
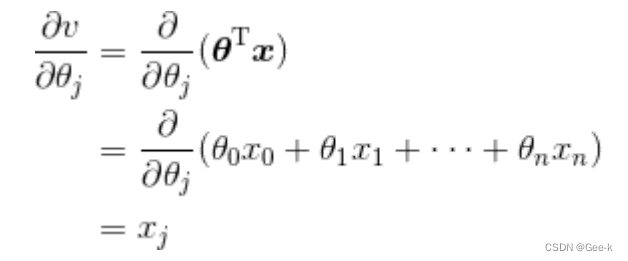
所以第j个参数的更新表达式就是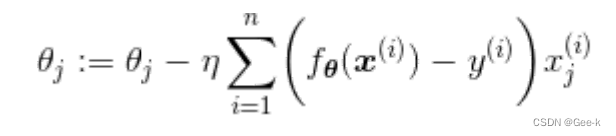
像这样包含了多个变量的回归称为多重回归
随机梯度下降法
最速下降法除了计算花时间以外,还有容易陷入局部最优解的缺点
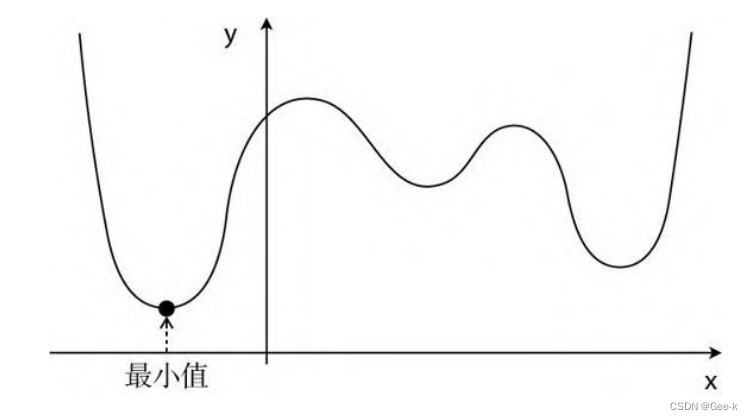
选用随机数作为初始值的情况比较多。不过这样每次初始值都会变,进而导致陷入局部最优解的问题
最速下降法的参数更新表达式
使用了所有训练数据的误差
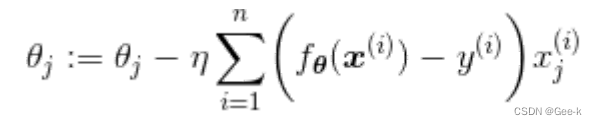
随机梯度下降法的参数更新表达式
随机选择一个训练数据,并使用它来更新参数。这个表达式中的k就是被随机选中的数据索引
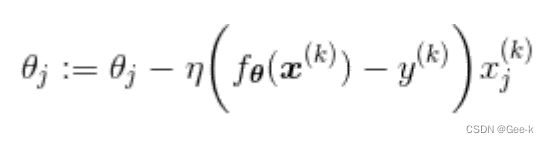
小批量梯度下降法
假设训练数据有 100 个,那么在m=10时,创建一个有10 个随机数的索引的集合,然后重复更新参数。
不管是随机梯度下降法还是小批量梯度下降法学习率n的设置很重要














 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









