







12月10日
1.基础知识
1.1什么是大模型?
大模型LLM是large language model是指基于深度学习技术的大规模人工智能模型,有非常庞大的数据规模和训练数据量,可以在多种任务中表现出高度的通用性和卓越性能。
例如OpenAI的GPT-4模型拥有数千亿级别的参数。
训练数据来源于互联网海量数据,涵盖多种语言,多种领域和不同的任务。
1.2如何展现大模型通用性?
大模型并不是针对特定任务设计的,而是在训练后通过微调(Fine-tuning)或者提示学习(Prompt Learning)适应不同的任务,例如文本生成、翻译、代码编写、图像生成等。
1.3如何定制大模型?用到的技术主要是什么?
①定制大模型是指针对特定应用场景或需求,
对已有的大规模预训练模型进行优化、微调或改造,
以实现更高效、更贴合需求的性能。
②微调 (Fine-Tuning)
例如:LoRA (Low-Rank Adaptation):添加低秩矩阵更新,降低微调复杂度。
知识蒸馏 (Knowledge Distillation)
将大模型的知识传递给小模型,保留性能的同时降低计算成本。
多模态扩展
将文本模型扩展到处理图像、音频、视频等多模态数据。如结合视觉模型(如CLIP)、音频模型(如Whisper)。
增强学习(Reinforcement Learning)
RLHF (Reinforcement Learning with Human Feedback):通过人类反馈优化模型行为。例如,用于改进对话质量、消除有害内容。
1.4有什么参调方法呢?
①全参数调整(Full Tuning)
对大模型所有参数进行更新,可以根据需求对模型进行彻底调整,但是计算和存储成本太高。仅适用于需要精细化调整的高价值任务,例如医学诊断或者金融分析。
②参数高效微调Parameter Efficient Fine-tuning (PEFT)
简称:微调(Fine-Tuning)
适配器方法(Adapter Tuning)
在模型中间层插入小型神经网络模块,仅仅微调这些模块的参数,这样调整量小,节省资源。但需要不同任务不同设计。
例子:一个由2个全连接层和非线性激活组成的适配器,添加到transformer中。
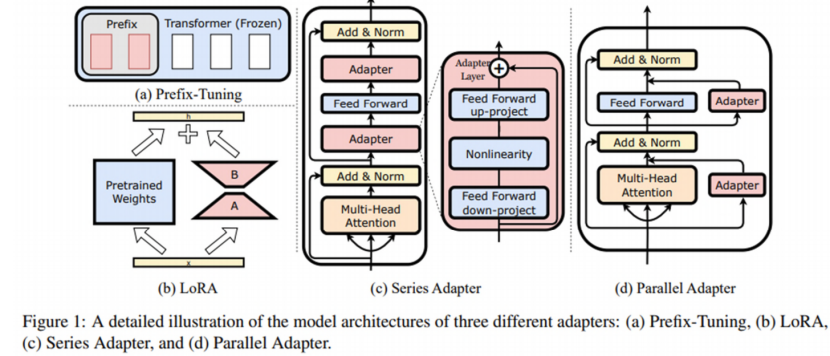
1.5什么是LoRA(Low-Rank Adaptation)?
原本要训练W这么多的参数,
现在只用训练A和B的参数了,A和B的秩很小,所以其组成的适配器需要训练的参数很少,就降低了计算和存储成本。
例如,使用Adam对GPT-3: 175B进行微调,与使用LoRA进行微调,可训练参数减少10,000倍和GPU内存需求减少3倍。
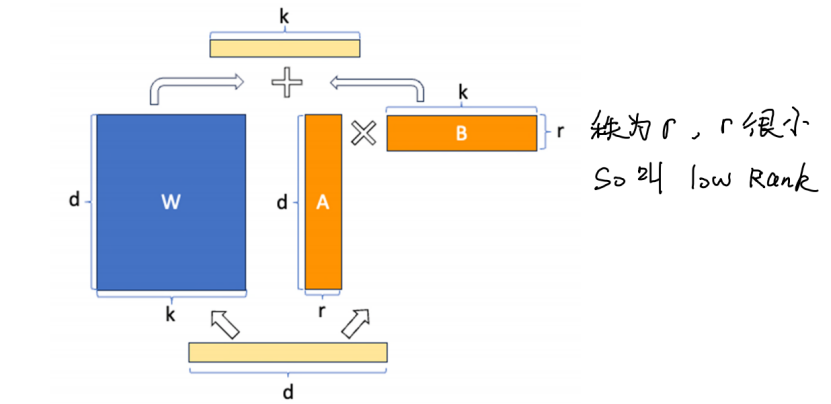
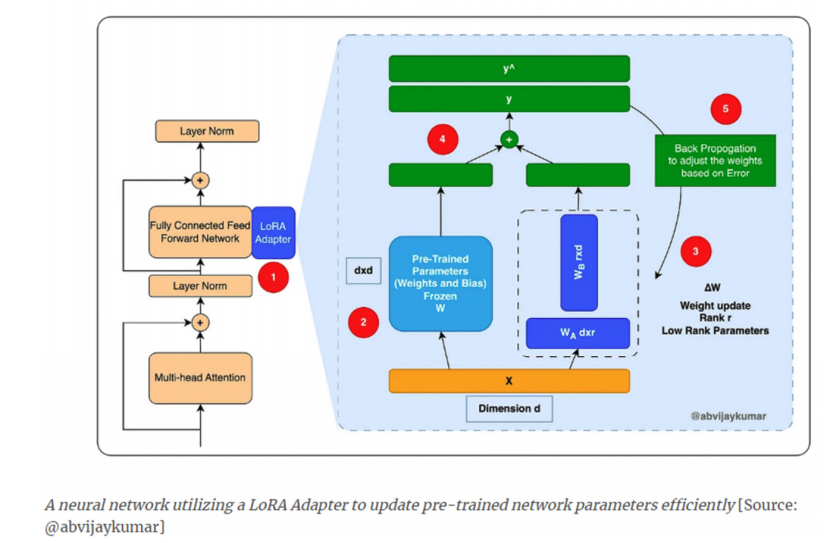
1.6如何通过LoRA进行微调?
首先,选择一个预训练的基础模型。
其次,选择一个要进行微调的层,例如Transformer的attention层。
然后,引入低秩矩阵对原来的权重矩阵W,进行低秩分解,让W’=AXB近似于W,X代表矩阵乘法。
然后,对矩阵进行微调。冻结原始权重矩阵W。使用目标用例数据,仅更新低秩矩阵A和B。
然后,评估调整后的模型性能,超参数调优,模型评估。
最后,对模型进行部署和监控。
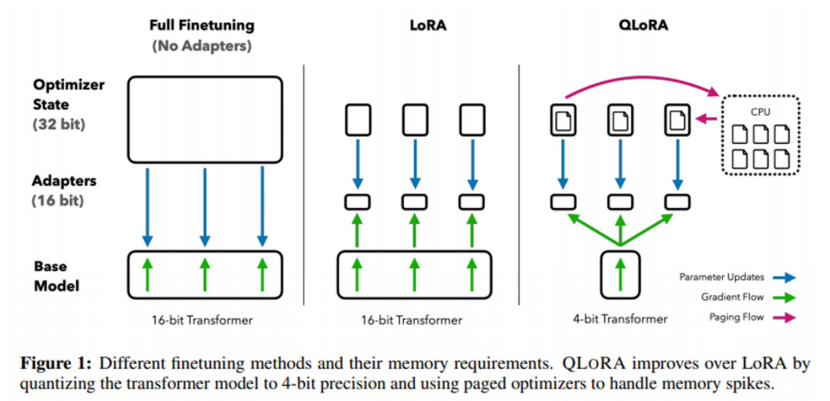
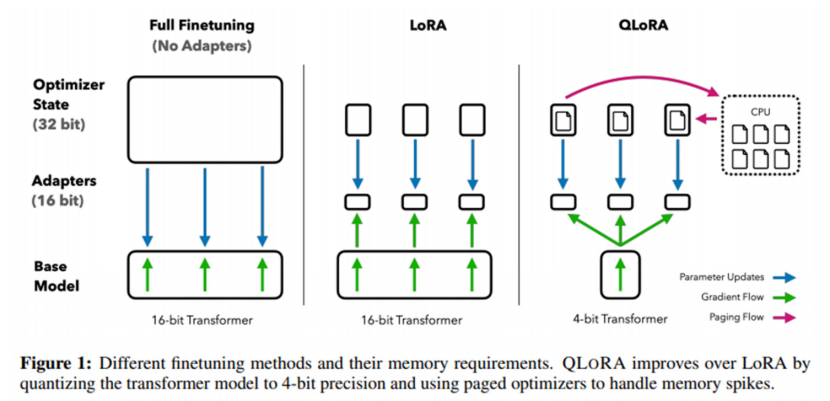
1.7什么是量化低秩适应(QLoRA)(Quantized Low-Rank Adaptation)?
将LoRA与量化相结合,优化内存使用和计算效率。
添加少量可训练的参数,同时保持原始参数冻结。
QLoRA通过将转换器模型量化到4位精度,并使用分页优化器处理内存峰值,来改进LoRA。
1.8什么是前缀调优(Prefix Tuning)?
一种通过在模型输入前,添加一系列可学习向量(前缀),来微调大型预训练模型的技术。
修改输入表示,而不是模型的内部参数,使其成为一种轻量级和高效的微调技术。
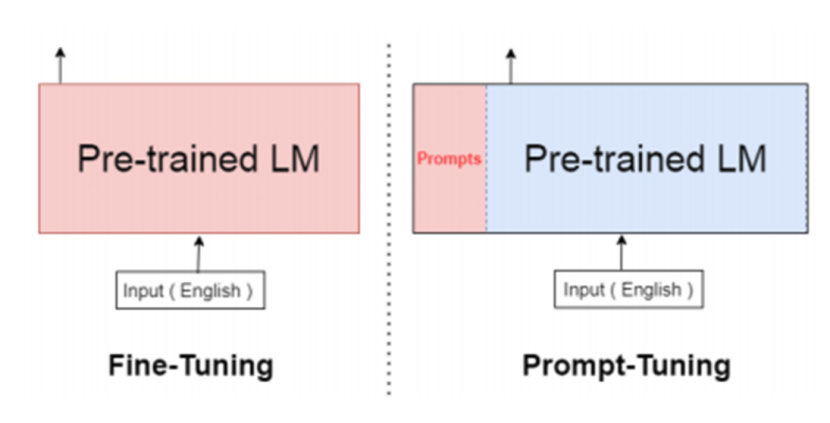
1.9什么是提示优化(Prompt Tuning)?
提示优化是一种使用提示 来指导模型行为的技术。
提示可以是静态的(固定文本),
也可以是引入输入序列的动态的(可学习的嵌入)。
修改模型的输入上下文以指导它的响应,而不更改模型的内部参数。
前缀调优使用可学习的向量(不是实际的文本),而提示调优可以使用固定的文本提示或可学习的嵌入。
1.10 什么是过拟合?
记忆了过多的不必要的细节(偶然的、不重要的噪声),从而导致处理新数据时候,表现得不好。
1.11JSON和JSONL介绍
JavaScript Object Notation 使用键值对来表示数据
通常包含一个对象(用{}表示),
键一般是字符串(“age”),
中间用冒号连接(:)
值可以为数字(30),字符串(“Zhang San”),boolean值(false),数组([“Chinese”,”Math”,”English”]),或者另一个对象。
JSON Lines
可以处理大型数据集
一行一个json
{“name”:”zhangsan”,”age”:18}
{“name”:”LI SI”,”age”:27}
1.12 主流数据集格式?
1.12.1.Alpaca
包括instruction、input、output、system、history组成
人类指令、人类输入、模型回答、提示词、历史消息记录表
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [ ["第一轮指令(选填)", "第一轮回答(选填)"], ["第二轮指令(选填)", "第二轮回答(选填)"] ]
}
]
更具体的可以看官方文档:
https://www.xfyun.cn/doc/spark/%E6%95%B0%E6%8D%AE%E9%9B%86%E6%A0%BC%E5%BC%8F%E8%AF%B4%E6%98%8E.html#_1-alpaca%E6%A0%BC%E5%BC%8F%E8%AF%B4%E6%98%8E
例子:instruction为别人的话,output为甄嬛的话
[{
"instruction": "小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——",
"input": "",
"output": "嘘——都说许愿说破是不灵的。"
}]
数据来源:https://github.com/datawhalechina/self-llm/blob/master/dataset/huanhuan.json
例子
{
"instruction": "回答以下用户问题,仅输出答案。",
"input": "1+1等于几?",
"output": "2"
}
例子来源:https://github.com/datawhalechina/self-llm/blob/master/models/LLaMA3/04-LLaMA3-8B-Instruct%20Lora%20%E5%BE%AE%E8%B0%83.md
1.12.2.ShareGPT
人类指令、模型回答、可选的系统提示词、工具列表
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
](必填),
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
{
"conversations": [
{
"from": "human",
"value": "你好,我出生于1990年5月15日。你能告诉我我今天几岁了吗?"
},
{
"from": "function_call",
"value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"
},
{
"from": "observation",
"value": "{\"age\": 31}"
},
{
"from": "gpt",
"value": "根据我的计算,你今天31岁了。"
}
],
"tools": "[{\"name\": \"calculate_age\", \"description\": \"根据出生日期计算年龄\", \"parameters\": {\"type\": \"object\", \"properties\": {\"birthdate\": {\"type\": \"string\", \"description\": \"出生日期以YYYY-MM-DD格式表示\"}}, \"required\": [\"birthdate\"]}}]"
}
2.模拟甄嬛对话的微调大模型程序
来源:基于小说、剧本微调出个性化的聊天大模型
技术:大模型人格化:使得大模型在语言表达、行为模式和情感反应方面更加接近人类。
应用:1.客服机器人 2.AI老师 3.情感陪伴 4.内容创作
2.1相关资料
(1)项目背景参考
https://www.datawhale.cn/activity/110/21/78?rankingPage=1
(2)详细步骤参考
https://www.datawhale.cn/activity/110/21/76?rankingPage=1
2.2如何准备数据?
通过网络获得《甄嬛传》剧本数据,每一句的人物及对应的台词。
使用正则表达式或者其他方法进行快速的提取,并抽取出关注的角色的对话。
最后再将其整理成 json 格式的数据。
2.2.1 原始数据
第十一集
第203幕(续)
甄嬛:兔子急了也会咬人的。
眉庄:可是连苏培盛都棘手的事,陵容却能解决得这么干脆利落,实在是让我太意外了。
甄嬛:虽然意外,可陵容毕竟也是为了咱们。
眉庄:话是如此,可是我总还觉得这不像我日日面对的那个陵容。
(陵容在屏风外听得对话,默然离去。)
第204幕
(翊坤宫)
华妃:死绝了?
颂芝:死得透透的了,拉去乱葬岗的时候,有人亲眼瞧见。下手可真够狠的,脖子都勒断了半根,可吓人了。
华妃:那些没根儿的东西,做事倒是挺利落的。也难怪呀,她连皇上身边的人都敢得罪,活该她有今天。她没说漏了嘴吧?
颂芝:一句都没有。
华妃:算她识相。从前小看了那个病歪歪的甄嬛,以后走着瞧吧。(雷声)且闷了这么些天,也该下场大雨了。
如果没有台本的原始数据
可以通过LLM抽取对话
2.2.2.提取数据
def extract_dialogues(file_path):
result = []
current_act_dialogues = []
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
for line in lines:
line = line.strip()
if line.startswith("("): # 过滤旁白行
continue
if line.startswith("第") and line.endswith("幕"): # 解析新的一幕
if current_act_dialogues:
result.append(current_act_dialogues)
current_act_dialogues = []
elif ":" in line: # 按:切分角色和对话内容
role, content = line.split(":", 1)
role = role.strip()
content = content.strip()
current_act_dialogues.append({"role": role, "content": content})
if current_act_dialogues: # 保存最后一幕
result.append(current_act_dialogues)
return result
file_path = '甄嬛传剧本11-20.txt'
dialogues = extract_dialogues(file_path)
print(dialogues)
2.2.3 处理结果
[
{"role": "甄嬛", "content": "兔子急了也会咬人的。"},
{"role": "眉庄", "content": "可是连苏培盛都棘手的事,陵容却能解决得这么干脆利落,实在是让我太意外了。"},
{"role": "甄嬛", "content": "虽然意外,可陵容毕竟也是为了咱们。"},
{"role": "眉庄", "content": "话是如此,可是我总还觉得这不像我日日面对的那个陵容。"}
],
[
{"role": "华妃", "content": "死绝了?"},
{"role": "颂芝", "content": "死得透透的了,拉去乱葬岗的时候,有人亲眼瞧见。下手可真够狠的,脖子都勒断了半根,可吓人了。"},
{"role": "华妃", "content": "那些没根儿的东西,做事倒是挺利落的。也难怪呀,她连皇上身边的人都敢得罪,活该她有今天。她没说漏了嘴吧?"},
{"role": "颂芝", "content": "一句都没有。"},
{"role": "华妃", "content": "算她识相。从前小看了那个病歪歪的甄嬛,以后走着瞧吧。(雷声)且闷了这么些天,也该下场大雨了。"}
]
2.2.4正则提取
def extract_zhenhuan_dialogues(dialogues):
result = []
zhenhuan_dialogues = []
for act in dialogues:
for i, dialogue in enumerate(act):
if "甄嬛" in dialogue["role"] and i > 0:
zhenhuan_dialogues.append(act[i-1])
zhenhuan_dialogues.append(dialogue)
result.append(zhenhuan_dialogues)
zhenhuan_dialogues = []
return result
zhenhuan_dialogues = extract_zhenhuan_dialogues(dialogues)
print(zhenhuan_dialogues)
[
{"role": "眉庄", "content": "可是连苏培盛都棘手的事,陵容却能解决得这么干脆利落,实在是让我太意外了。"},
{"role": "甄嬛", "content": "虽然意外,可陵容毕竟也是为了咱们。”}
]
2.2.5 数据增强
利用两到三条数据作为 example 丢给LLM,让其生成风格类似的数据。
也可以找一部分日常对话的数据集,使用 RAG 生成一些固定角色风格的对话数据。
2.3如何微调?
定制一个自己的专属大模型最方便的步骤 ≈ 指定数据集 + 开源大模型 + 微调平台(如讯飞星辰Maas)
①选择基础模型
②选择微调方法
③上传数据集
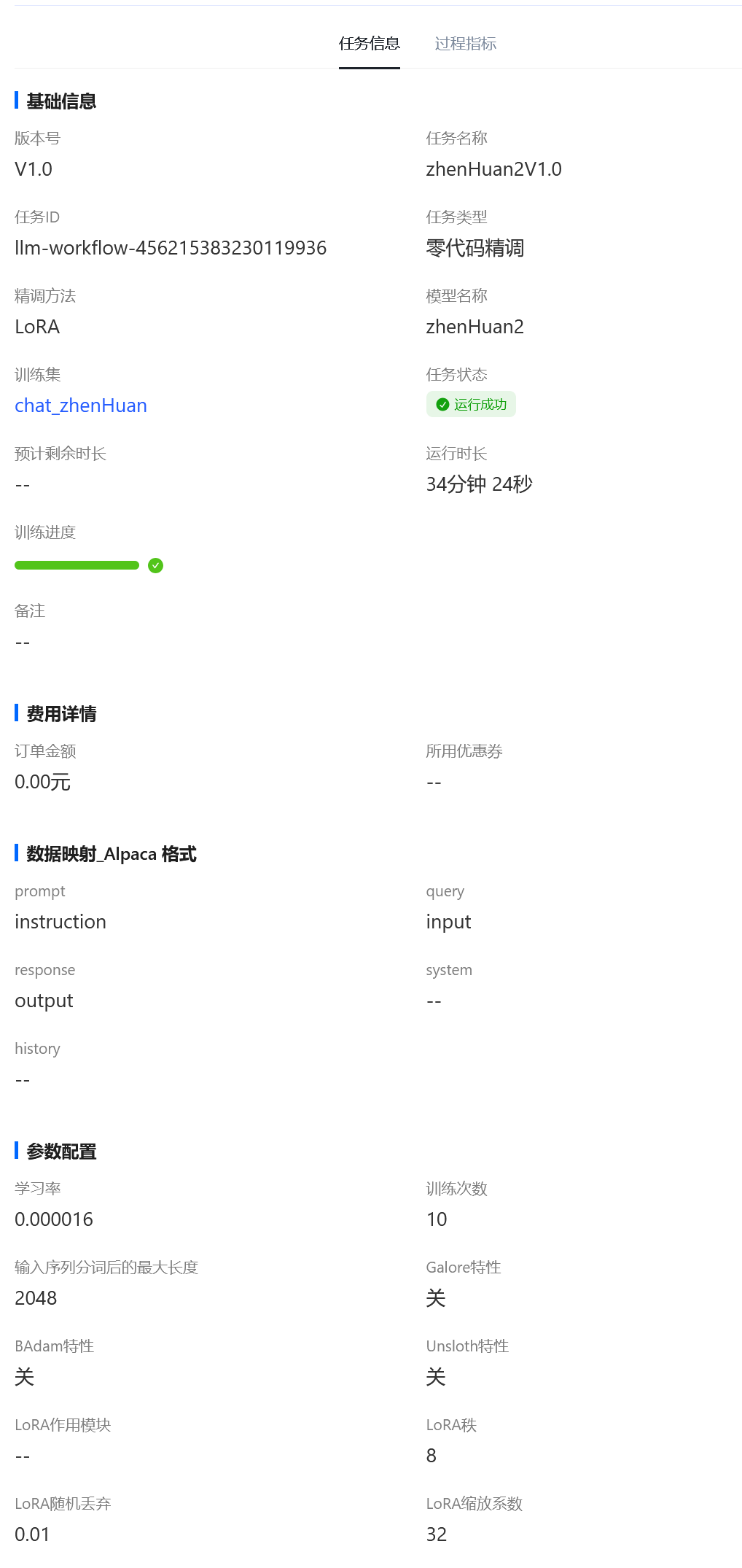
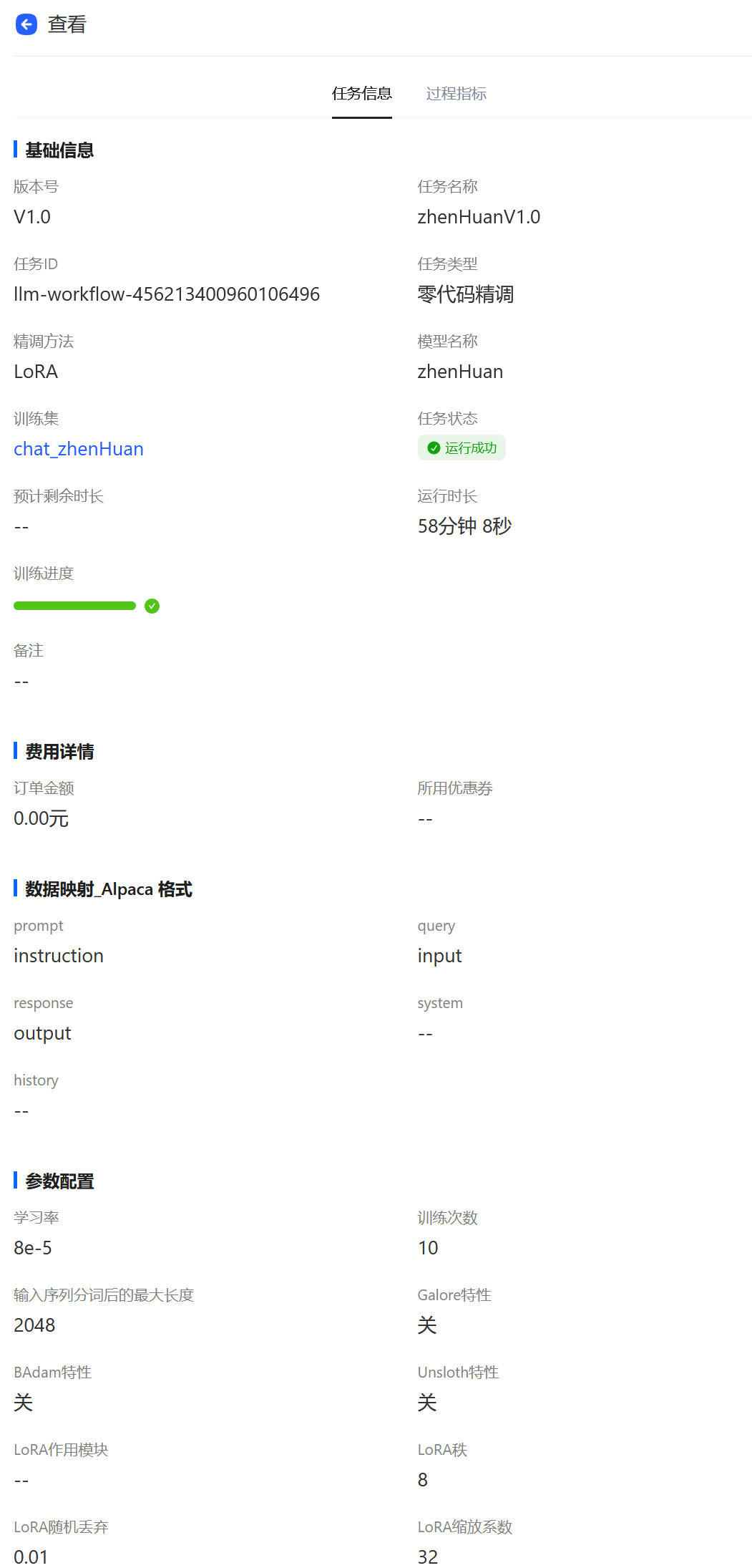
2.3.1 参数调整
1.深度学习
学习率:控制每次迭代更新模型参数的步幅。较小学习率更新慢但精确,较大学习率训练速
度快但可能不稳定。
训练次数:建议根据数据规模设置合理的 epochs。
输入序列长度:模型输入序列的最大长度,短序列效率高,长序列适合上下文较多的任务。
2.LORA(低秩自适应)
LORA秩:决定模型更新参数的数量,影响计算量与性能表现。
·LORA随机丢弃:类似于正则化操作,避免过拟合,提升泛化能力。
LORA作用模块:主要在预训练模型的自注意力机制和前馈网络中进行权重适配。
LORA缩放因数:控制训练过程参数更新幅度,适配不同任务要求。
3.训练加速
Galore特性:通过低秩特性减少参数存储和计算量,提高模型加速效果。
BAdam特性:一种内存高效的优化算法,通过减少参数计算次数和内存占用,进一步提高
训练效率。
2.4如何评价生成结果?
人工评价:准确率、流畅度。
机器评价:BLEU分数、F1-score。
准确率 :计算模型生成的回答与真实回答的匹配度。
流畅度 :通过人工评估或使用语言模型评估生成文本的自然性。
BLEU分数 :用于评估生成文本与参考文本之间的相似度。
F1-score :用于评估模型在分类任务中的表现。
2.5如何优化?
通过以下方式优化微调方式及性能
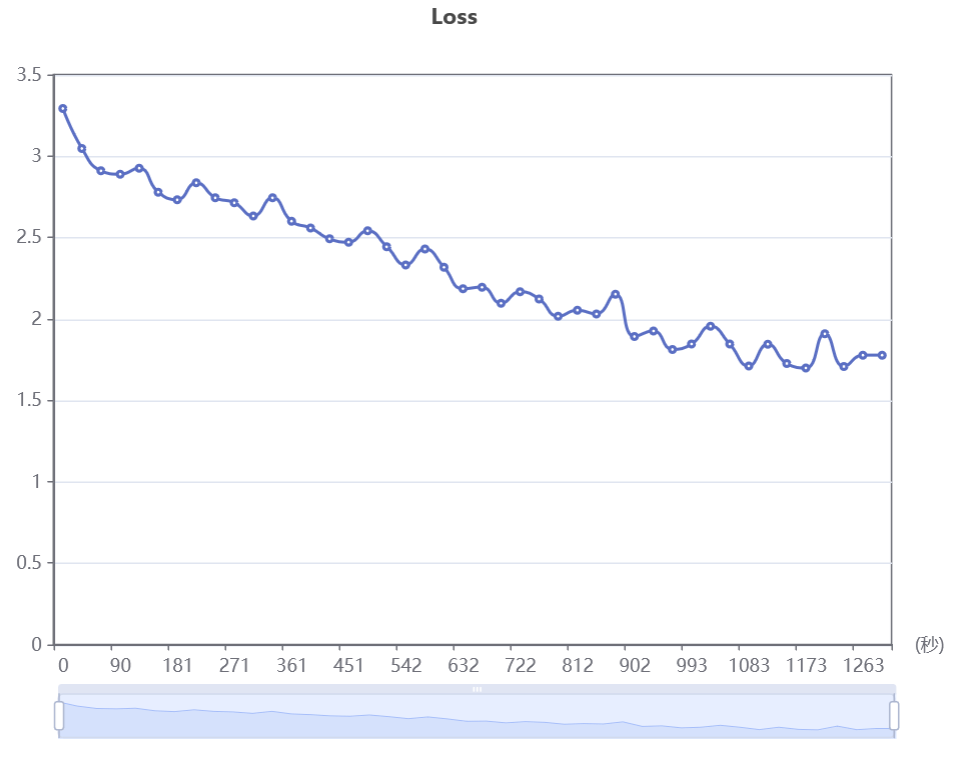
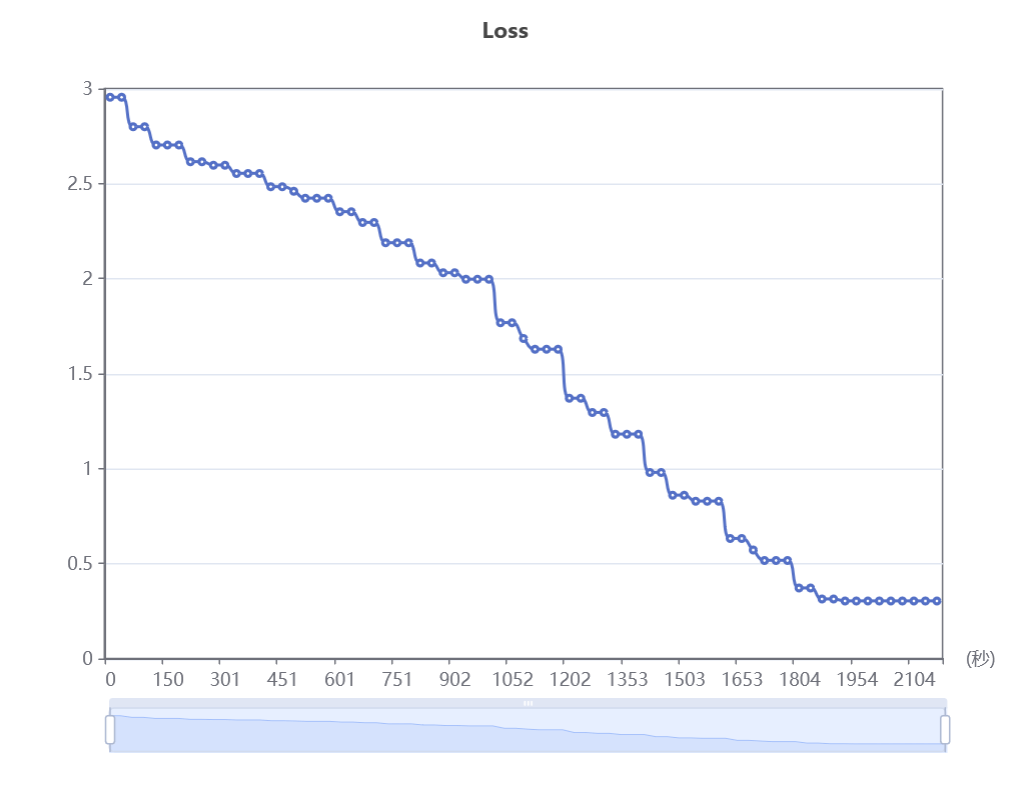
(1)损失图 :绘制训练损失和验证损失的曲线图。
如果验证损失在训练损失持续下降时上升,可能表明模型过拟合。
(2)平衡语料比例 :根据原始语料和新添加语料的比例进行微调,防止模型过拟合。
可以采用如80%原始语料和20%新语料的比例开始。
2.6深入学习?
参考目录链接
https://www.datawhale.cn/activity/110/21/83?rankingPage=1
2.7《tianji blog:如何从零搜集网络数据形成训练语料》
如何建立自己的数据集
可以借助一个小工具:extract-dialogue 从文本中提取对话。
1.从原始数据中提取出角色和对话
2. 筛选出我们关注的角色的对话
3. 将对话转换成我们需要的格式
https://tianji.readthedocs.io/en/latest/finetune/get_finetune_data.html#
2.8《Chat-嬛嬛 是如何炼成的》
如何在自己的电脑进行训练,而非借助其他平台。
https://github.com/datawhalechina/self-llm/blob/master/examples/Chat-%E5%AC%9B%E5%AC%9B/readme.md
选择 LLaMA3_1-8B-Instruct 模型进行微调,首先还是要下载模型。
其次,准备训练代码,在当前目录下放置train.py。
微调教程链接:https://github.com/datawhalechina/self-llm/blob/master/models/LLaMA3/04-LLaMA3-8B-Instruct%20Lora%20%E5%BE%AE%E8%B0%83.md
(1)指令集构建:微调数据集构建
(2)数据格式化: 需要将输入文本编码为 input_ids,将输出文本编码为 labels,编码之后的结果都是多维的向量。我们首先定义一个预处理函数,这个函数用于对每一个样本,编码其输入、输出文本并返回一个编码后的字典。
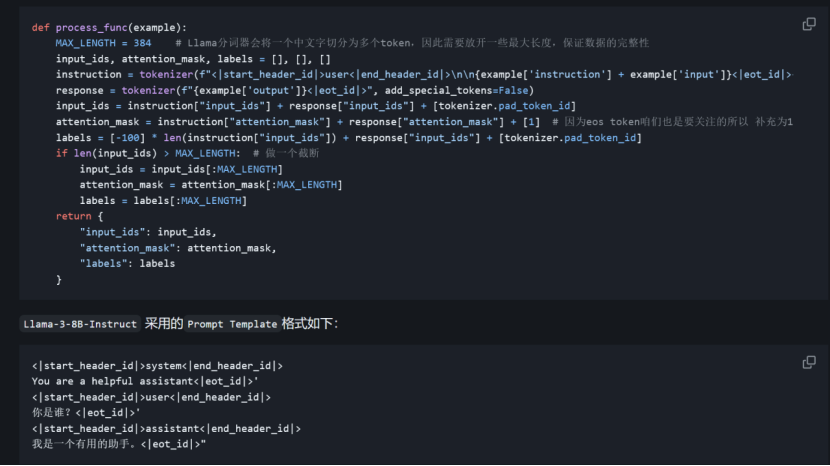
(3)加载 tokenizer 和半精度模型
模型以半精度形式加载,如果你的显卡比较新的话,可以用torch.bfolat形式加载。对于自定义的模型一定要指定trust_remote_code参数为True。
(4)定义 LoraConfig
模型类型,需要训练的模型层名字,秩,和lora_alaph
(5)自定义 TrainingArguments 参数
模型输出路径,每批训练数量,log输出步数,轮数,梯度检查(防止梯度爆炸或者梯度消失)
(6)使用 Trainer 训练
(7)保存 lora 权重
(8)加载 lora 权重推理
训练好了之后可以使用如下方式加载lora权重进行推理
3.模拟甄嬛对话的微调大模型程序:结果
3.1模型训练
3.2应用
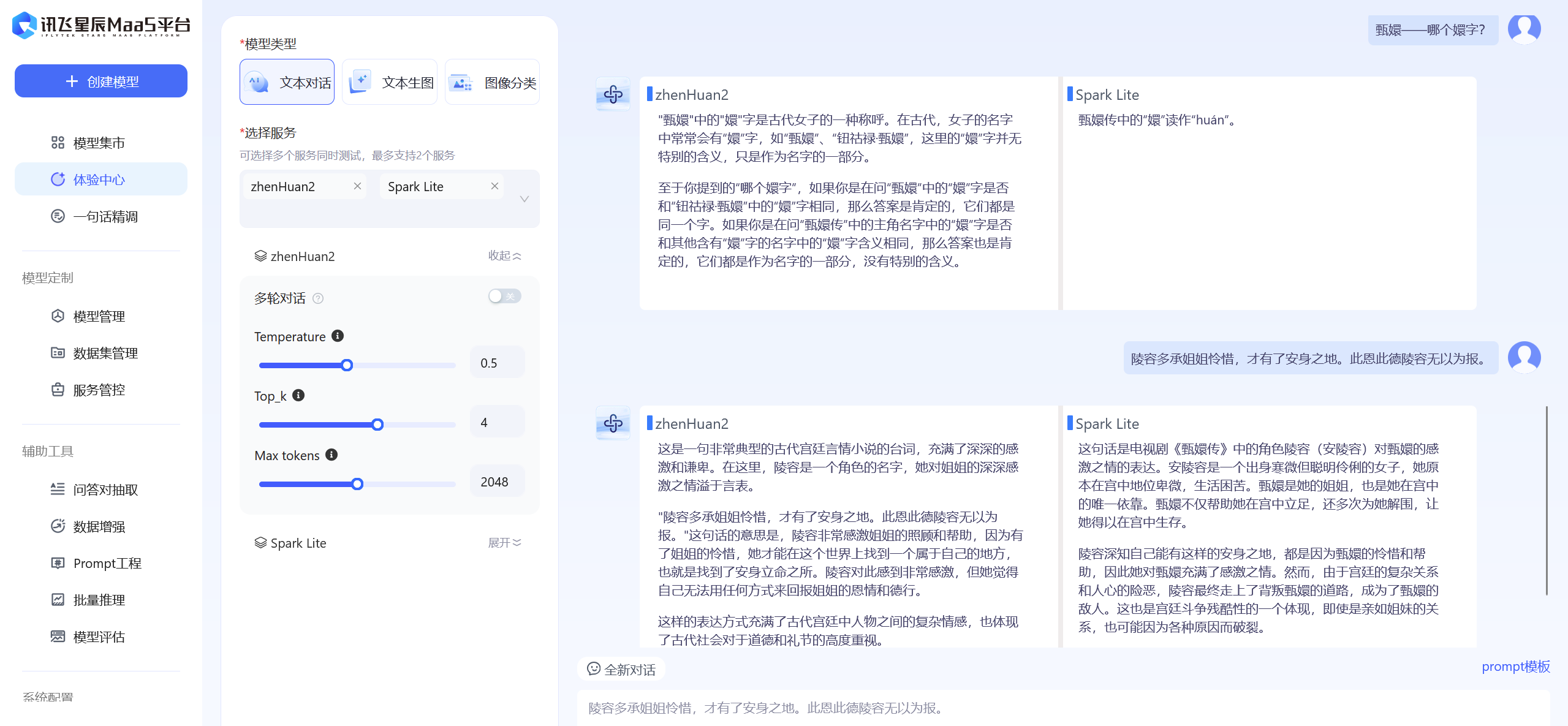
1.训练结果体验截图
结果很不理想,有一种没有训练过的美
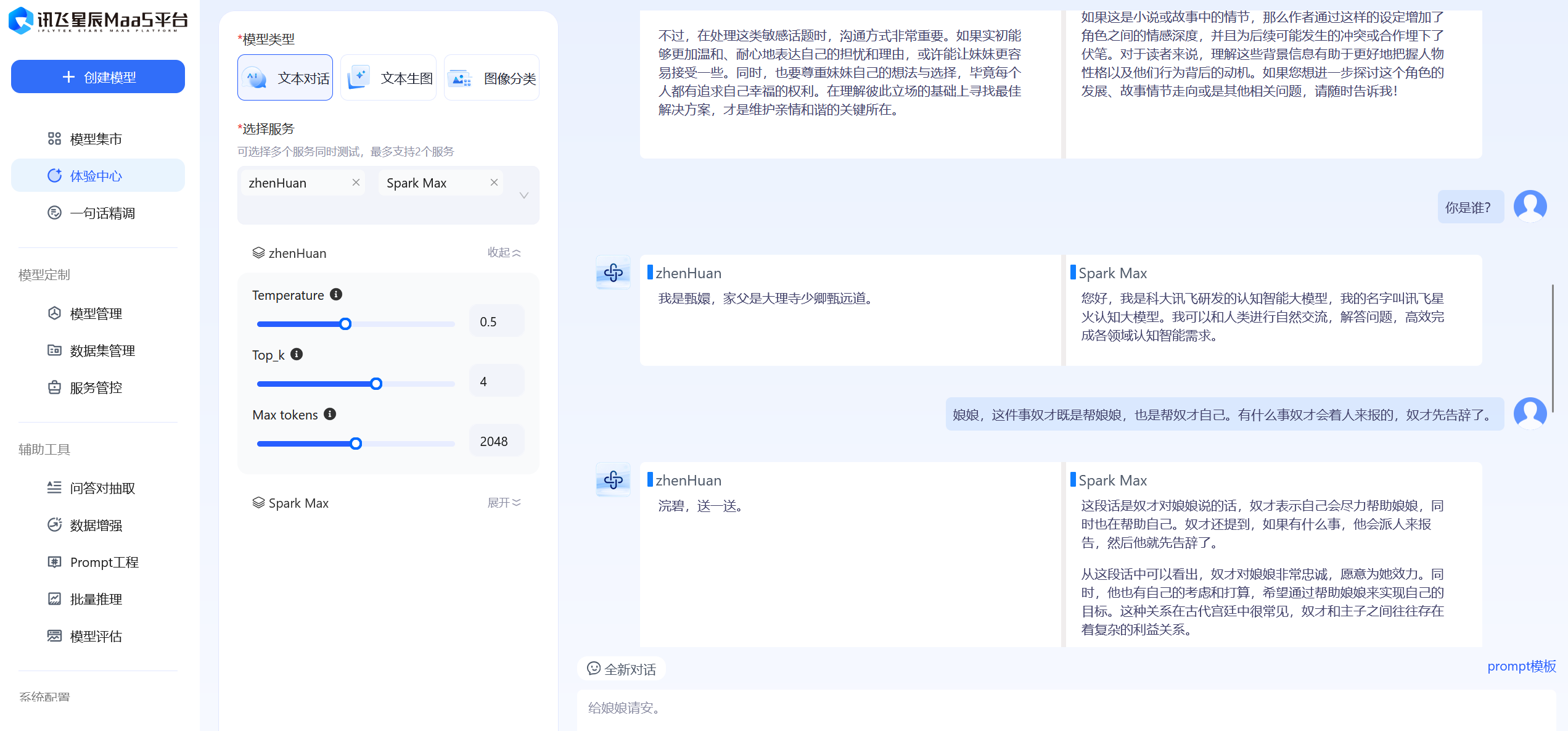
3.3改进:Spark Max
应该是基础模型的问题,改用了Spark Max进行十次迭代后,效果比原来好了很多
提问效果如下
3.4 Spark Max模型截图
llm-workflow-456213400960106496

















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









