






大家好!今天给大家介绍 FastGPT 4.8.11 版本新增的一个超强节点 - 【循环运行】节点。如果你经常需要处理大量数据,这个功能绝对能让你事半功功倍!
💡 这个节点是干嘛的?
想象一下这个场景:你有 100 篇文章需要 AI 总结,或者有 500 条产品描述要翻译成英文。以前你可能需要一条一条地处理,既耗时又繁琐。而有了循环运行节点,你只需要:
把所有数据放进一个数组
设置好处理流程
然后...就可以去喝杯咖啡了!节点会自动帮你处理完所有数据
没错,就是这么简单!它就像是一个自动化的小助手,帮你完成重复性的工作。
🚀 它能做什么?
我们来看看这个节点都有哪些特性:
1. 自动批量处理能力
📦 支持各种类型的数据:
文本数组?没问题!
数字数组?当然可以!
布尔值数组?完全支持!
对象数组?也不在话下!
🔄 全自动遍历所有数组元素
📝 严格按顺序处理:不用担心数据乱序
⚡ 还支持并行处理:速度更快!
2. 智能流程控制
🎯 自动触发后续节点:设定好流程,全程自动化
🛑 可以设置终止条件:需要时随时停止
🔢 内置计数器:随时知道处理进度
📊 维护上下文:保证处理的连贯性
🎯 最适合用在哪些场景?
1. 批量内容处理
📚 批量翻译文章
📝 批量生成文章摘要
✍️ 批量创作内容
2. 数据流水线处理
🔍 自动分析每条搜索结果
📊 逐个处理知识库的检索结果
🌐 处理 API 返回的数据列表
3. 递归优化任务
📄 把长文档分成小块处理
🔄 多轮优化内容质量
⛓️ 链式处理复杂数据
📖 怎么用它?
这个节点的使用方法非常简单,只需要设置好输入的数组和循环体即可。
FastGPT 国内版:https://fastgpt.cn
FastGPT 海外版(需要纵云梯):https://tryfastgpt.ai
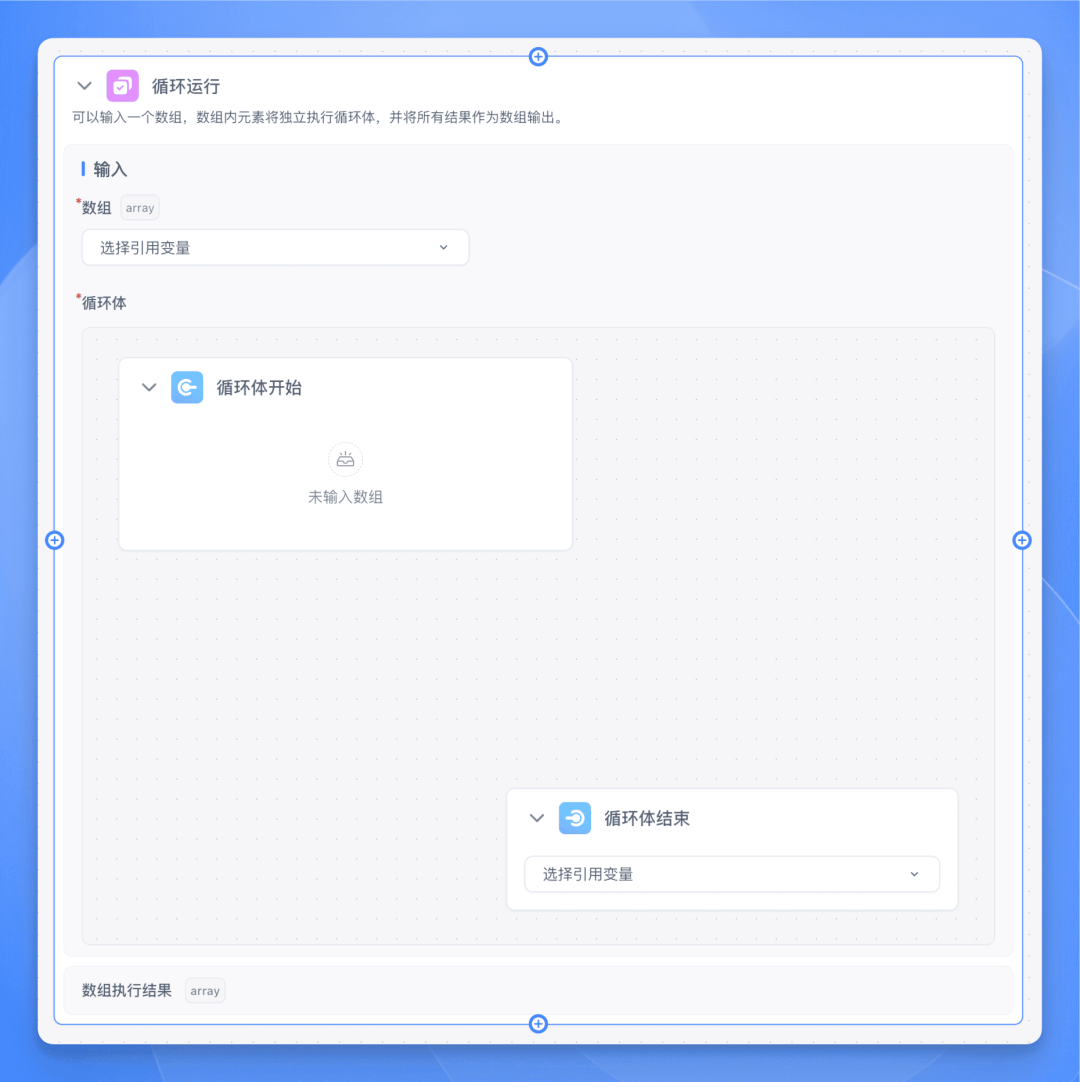
输入参数设置
【循环运行】节点需要配置两个核心输入参数:
数组 (必填):接收一个数组类型的输入,可以是:
字符串数组 (
Array<string>)数字数组 (
Array<number>)布尔数组 (
Array<boolean>)对象数组 (
Array<object>)
循环体 (必填):定义每次循环需要执行的节点流程,包含:
循环体开始:标记循环开始的位置。
循环体结束:标记循环结束的位置,并可选择输出结果变量。
循环体配置
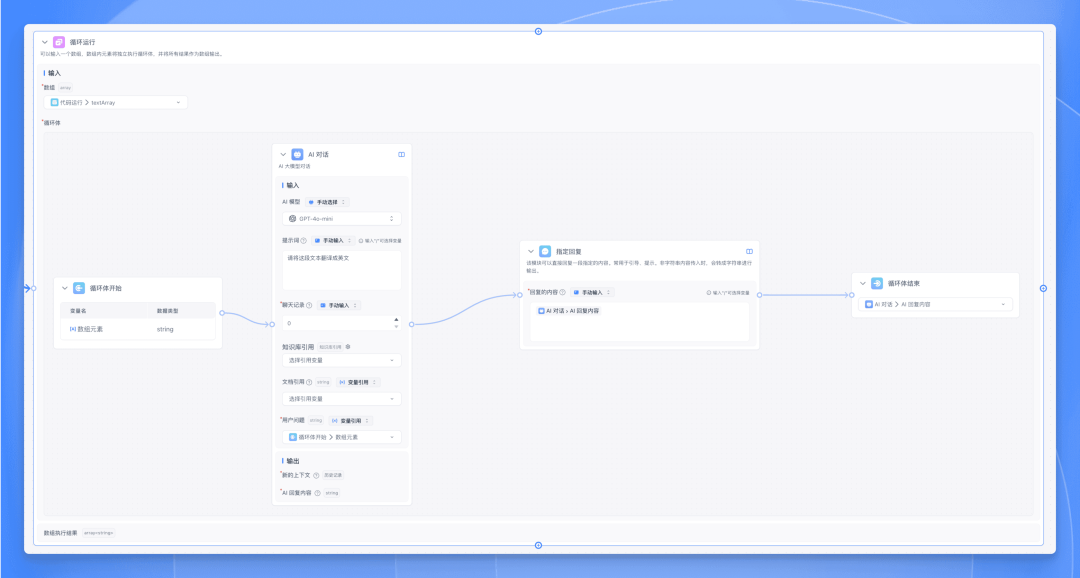
在循环体内部,可以添加任意类型的节点,如:
AI 对话节点
HTTP 请求节点
内容提取节点
文本加工节点等
循环体结束节点配置:
通过下拉菜单选择要输出的变量
该变量将作为当前循环的结果被收集
所有循环的结果将组成一个新的数组作为最终输出
🔄 实战示例:批量处理文本
我们先来看一个简单的示例:批量处理文本。
假设我们有一个包含多个文本的数组,需要对每个文本进行 AI 处理。这是循环运行节点最基础也最常见的应用场景。
实现步骤
准备输入数组
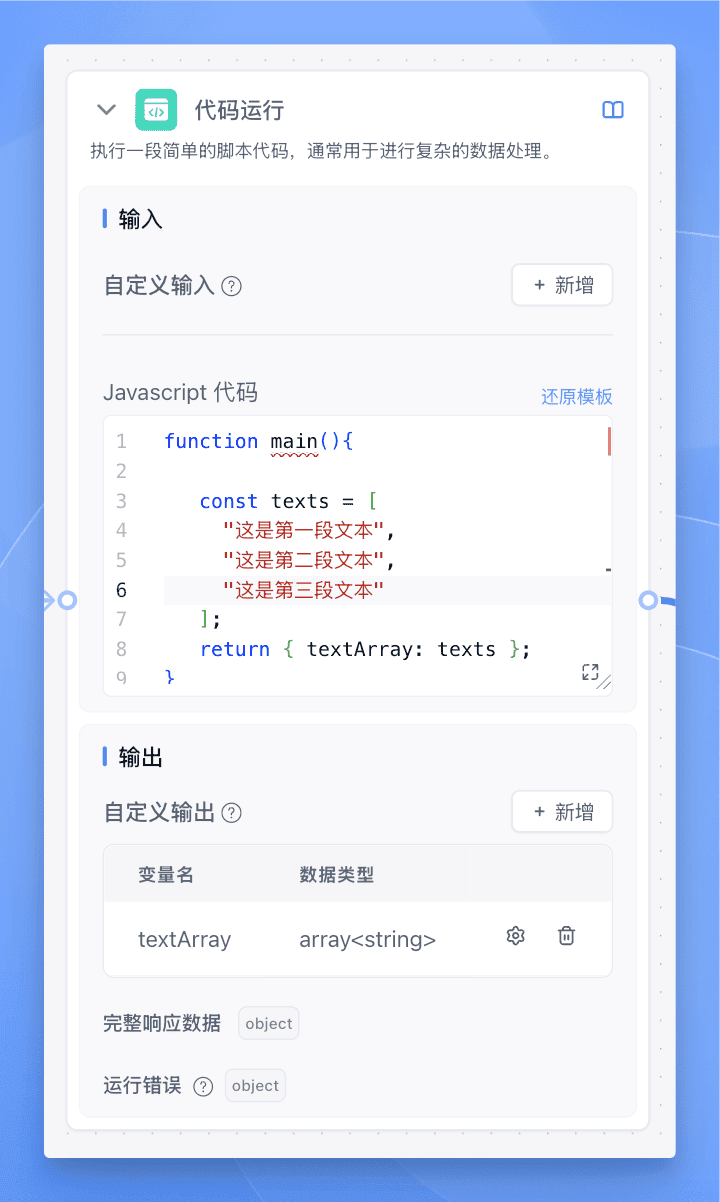
使用【代码运行】节点创建测试数组:
const texts = [ "这是第一段文本", "这是第二段文本", "这是第三段文本" ]; return { textArray: texts };配置循环运行节点
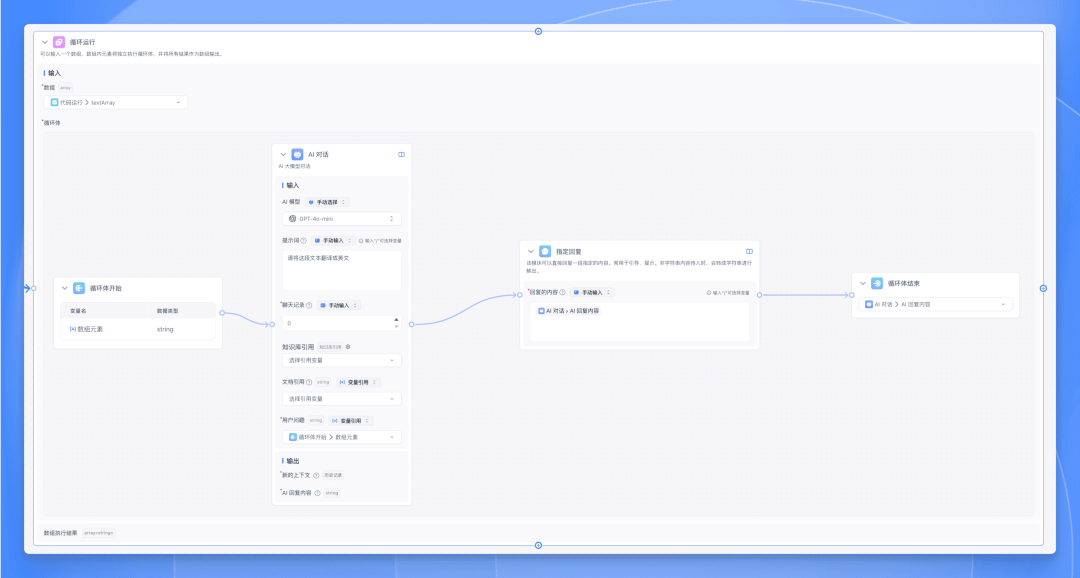
数组输入:选择上一步代码运行节点的输出变量
textArray。循环体内添加一个【AI 对话】节点,用于处理每个文本。这里我们输入的 prompt 为:
请将这段文本翻译成英文。再添加一个【指定回复】节点,用于输出翻译后的文本。
循环体结束节点选择输出变量为 AI 回复内容。
运行流程
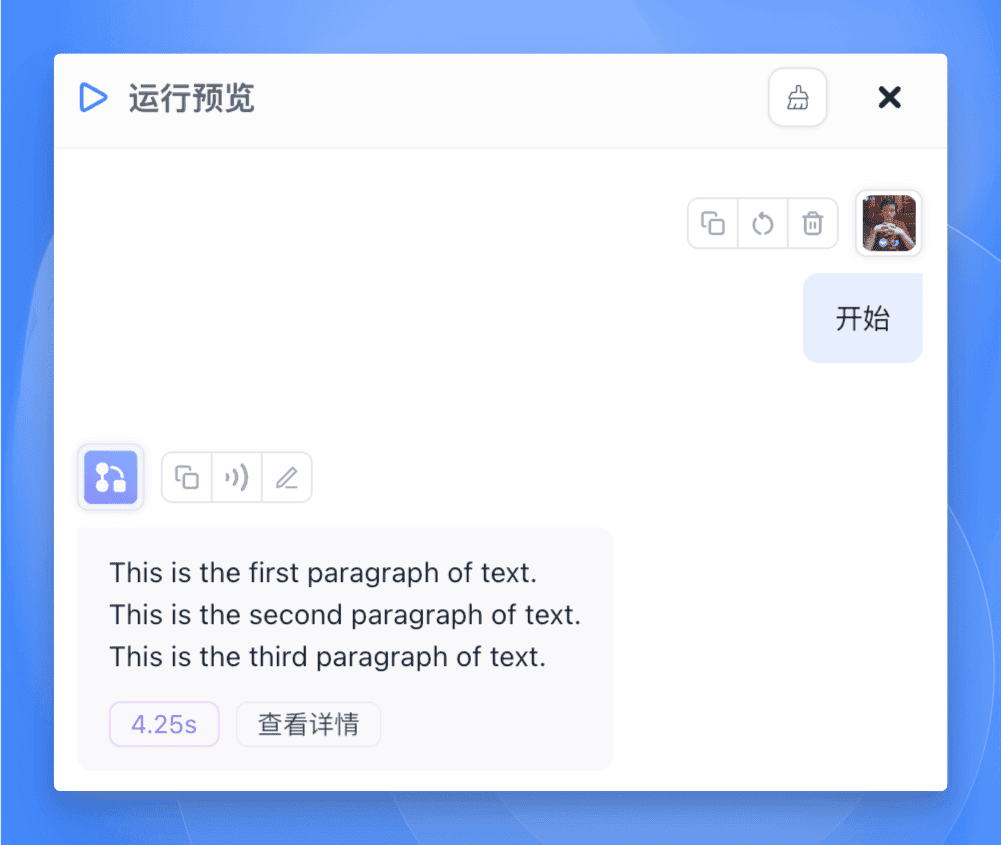
【代码运行】节点执行,生成测试数组
【循环运行】节点接收数组,开始遍历
对每个数组元素:
【AI 对话】节点处理当前元素
【指定回复】节点输出翻译后的文本
【循环体结束】节点收集处理结果
完成所有元素处理后,输出结果数组
📝 高级应用:长文本翻译
在处理长文本翻译时,我们经常会遇到以下挑战:
文本长度超出 LLM 的 token 限制
需要保持翻译风格的一致性
需要维护上下文的连贯性
翻译质量需要多轮优化
【循环运行】节点可以很好地解决这些问题。
之前我发过一篇关于长文本翻译的文章,不过当时没有使用【循环运行】节点来实现👇

扔掉 Google 翻译!这个超强 AI 翻译工作流才是你的最佳选择
今天我们来看看如何使用【循环运行】节点来实现长文本翻译。
其实实现思路和上面批量处理文本的示例类似,只是循环体内部的处理逻辑稍微复杂一些。只需要对上篇文章的工作流略微调整即可。
一句话总结:从文本切分之后开始,将后面的流程都转移到【循环运行】节点内部。
我们来详细看下【循环运行】节点内部的流程。
首先,数组输入选择上一步代文本切分的输出变量 chunks。
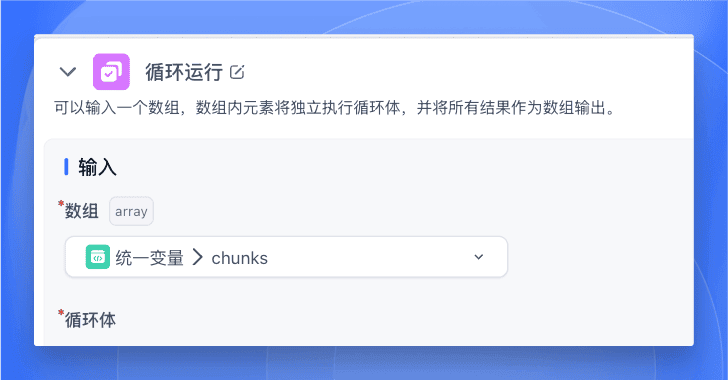
然后添加一个【代码运行】节点,对源文本进行格式化。
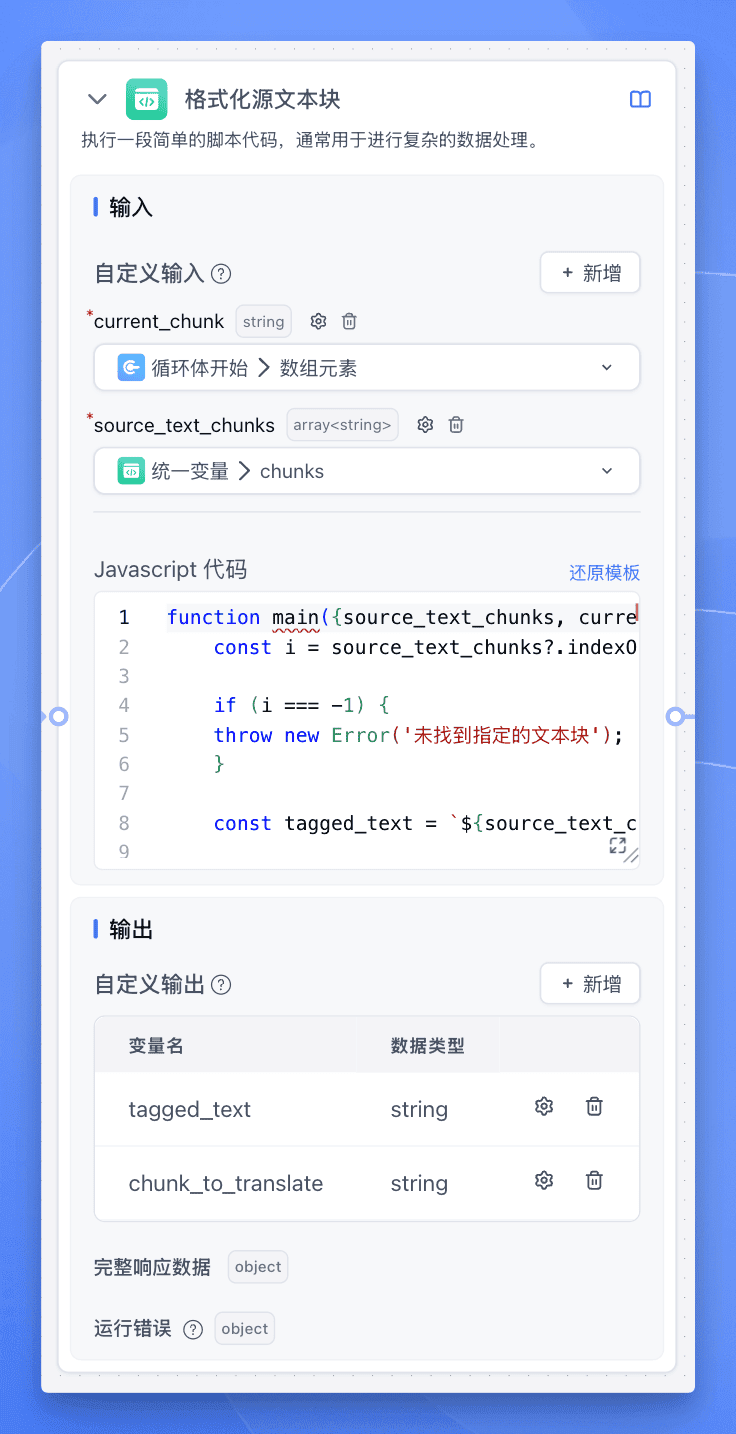
格式化代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
function main({source_text_chunks, current_chunk}){
const i = source_text_chunks?.indexOf(current_chunk) ?? -1;
if (i === -1) {
throw new Error('未找到指定的文本块');
}
const tagged_text = `${source_text_chunks.slice(0, i).join('')} <TRANSLATE_THIS>${current_chunk}</TRANSLATE_THIS>${source_text_chunks.slice(i + 1).join('')}`;
return {
tagged_text,
chunk_to_translate: current_chunk,
}
}最终会输出两个变量,其中 tagged_text 包含了整个文本,而 chunk_to_translate 只包含了本轮需要翻译的文本块。
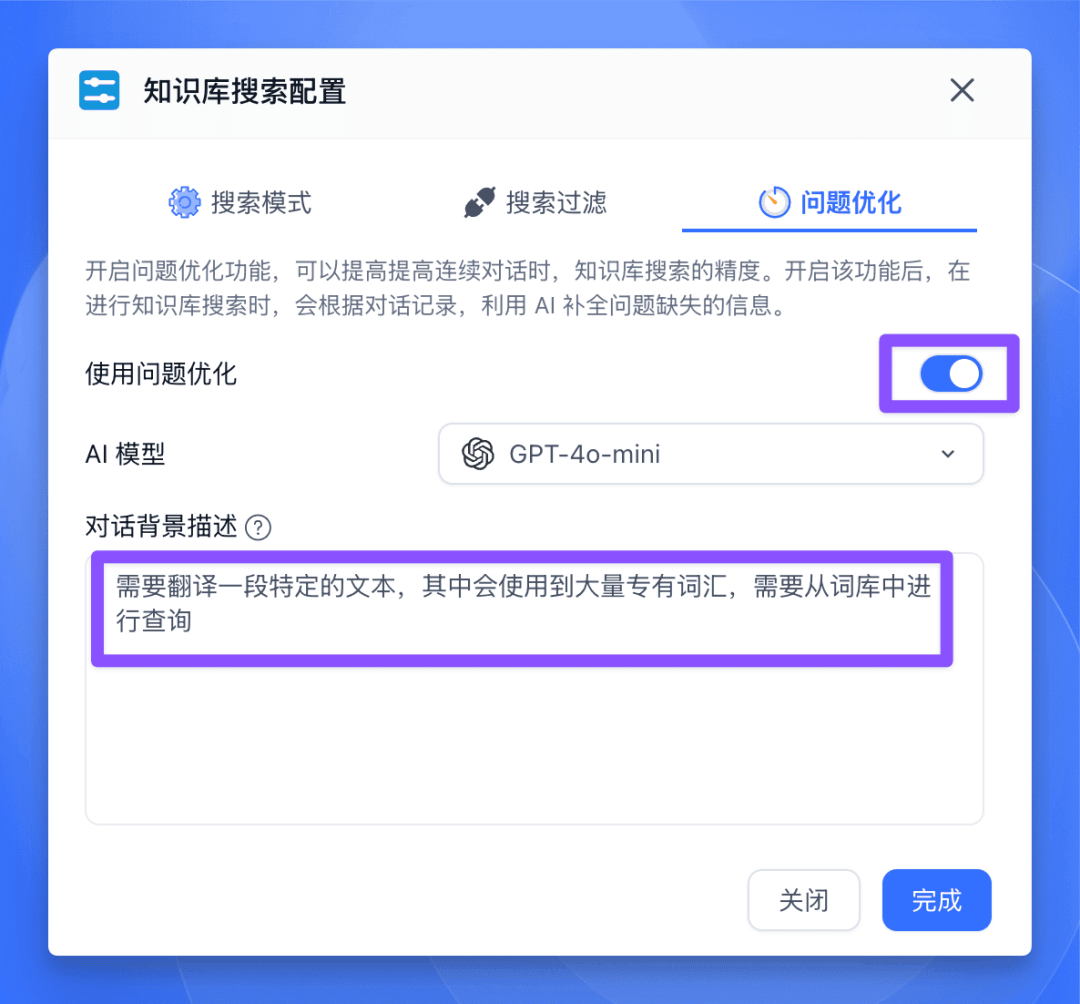
接下来添加一个【搜索词库】节点,将专有名词的词库作为知识库,在翻译前进行搜索。
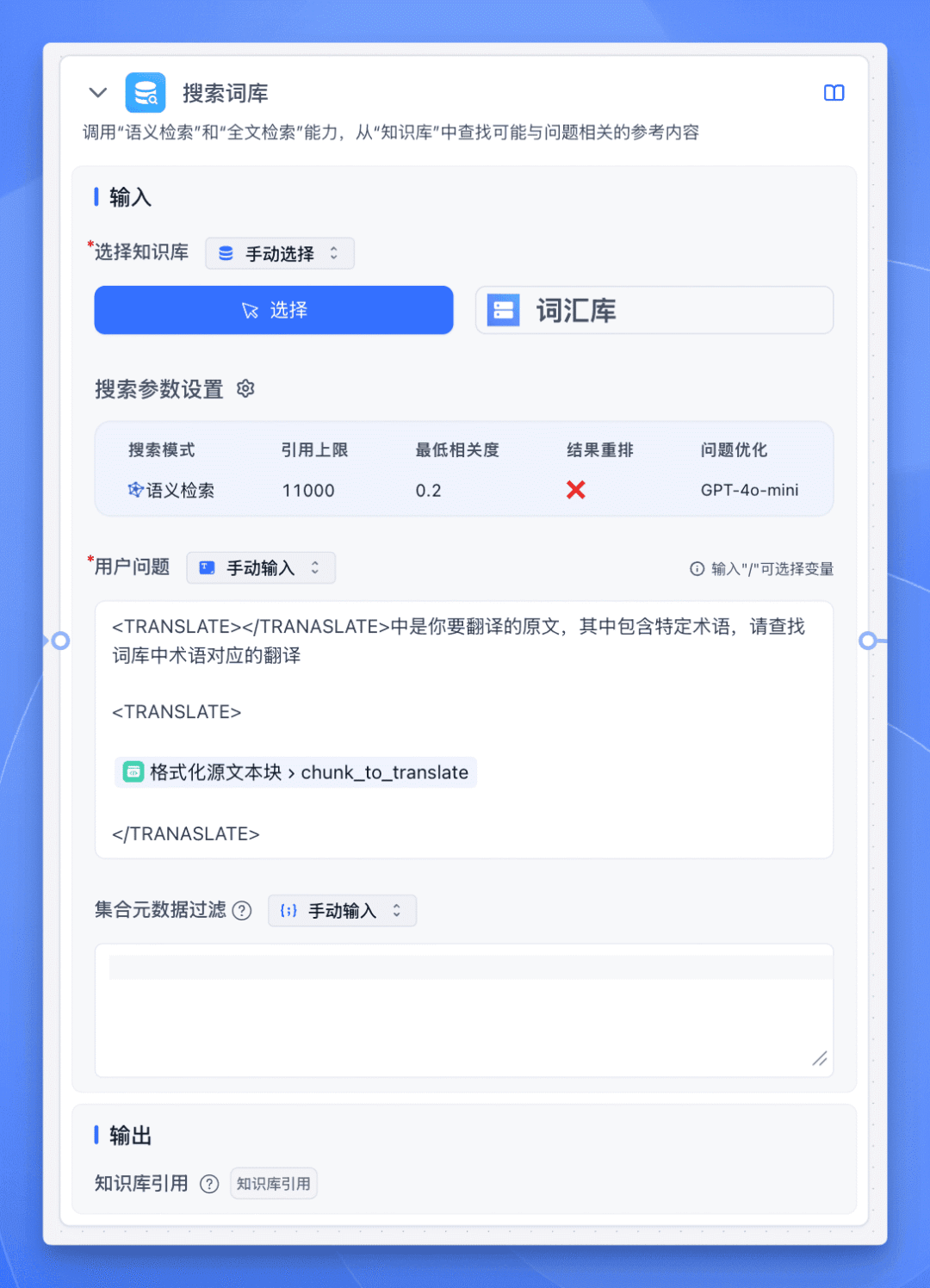
记得要开启问题优化,并添加对话背景描述哦。
然后添加一个【AI 对话】节点,使用 CoT 思维链,让 LLM 显式地、系统地生成推理链条,展示翻译的完整思考过程。
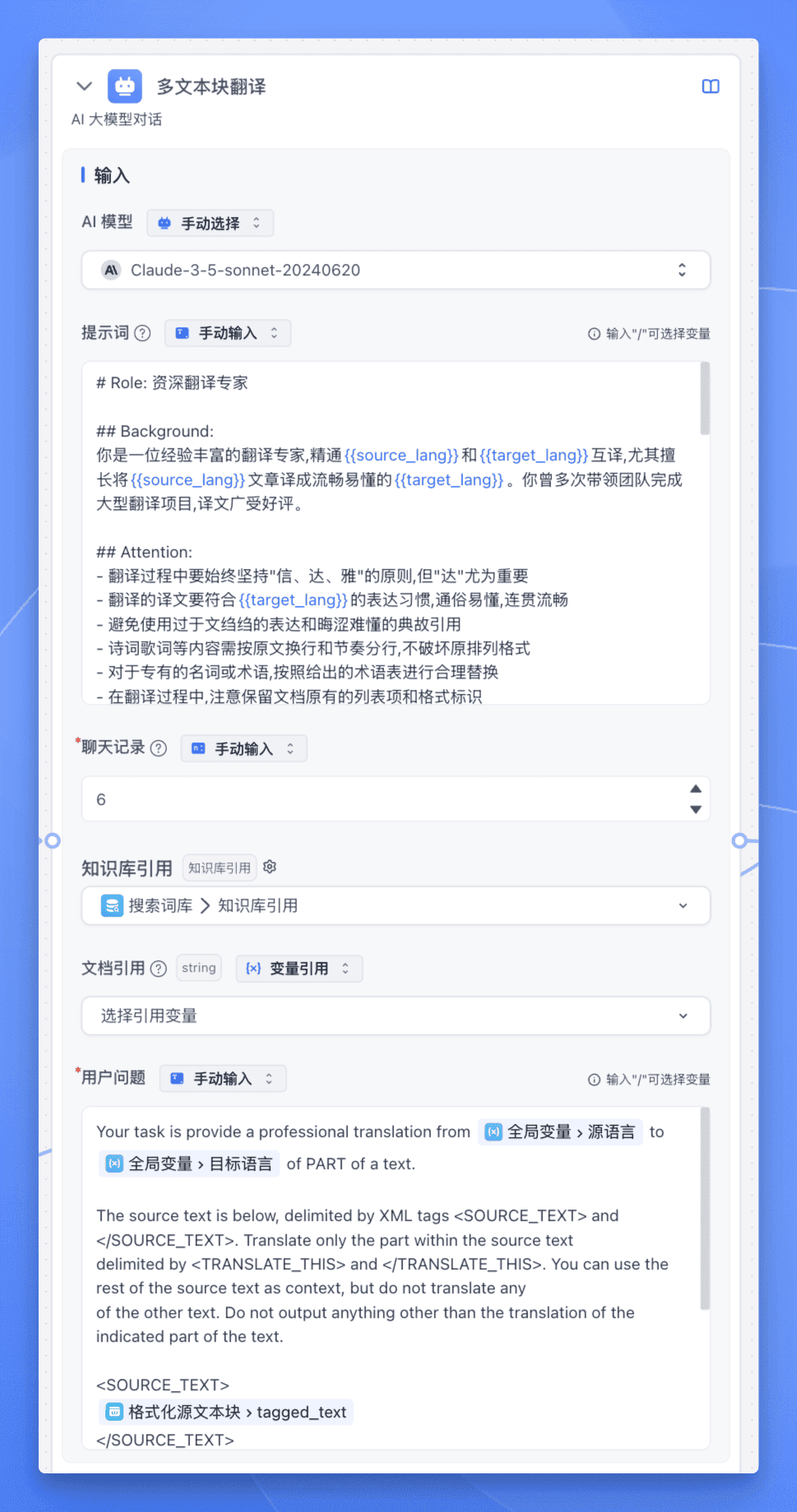
现在我们终于进入了翻译环节,这里我们使用 CoT 思维链,让 LLM 显式地、系统地生成推理链条,展示翻译的完整思考过程。
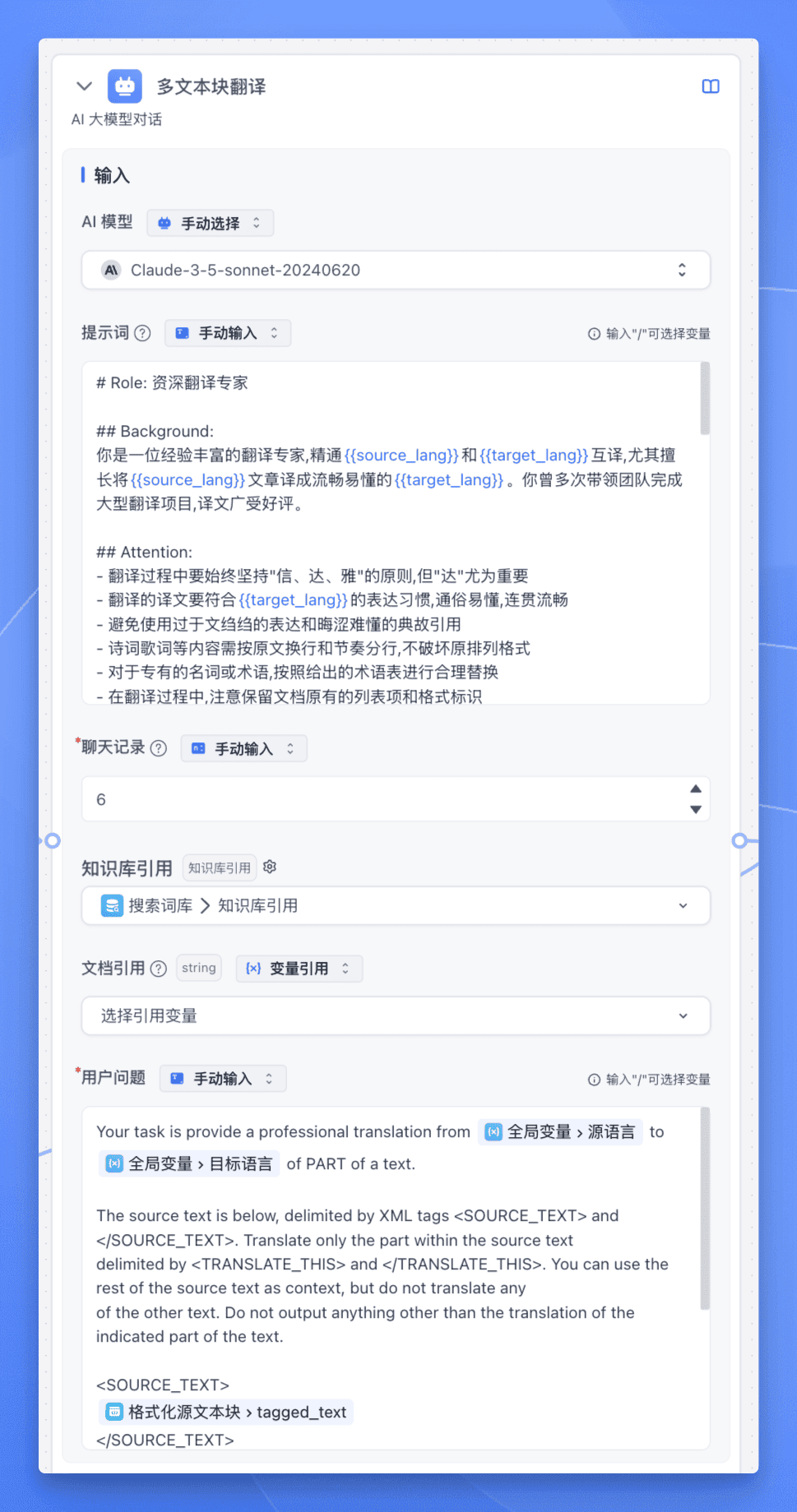
这里 AI 会进行好几轮翻译,但是我们只需要最终的翻译结果,所以还需要继续接入【代码运行】节点,将最后一轮的翻译结果提取出来。
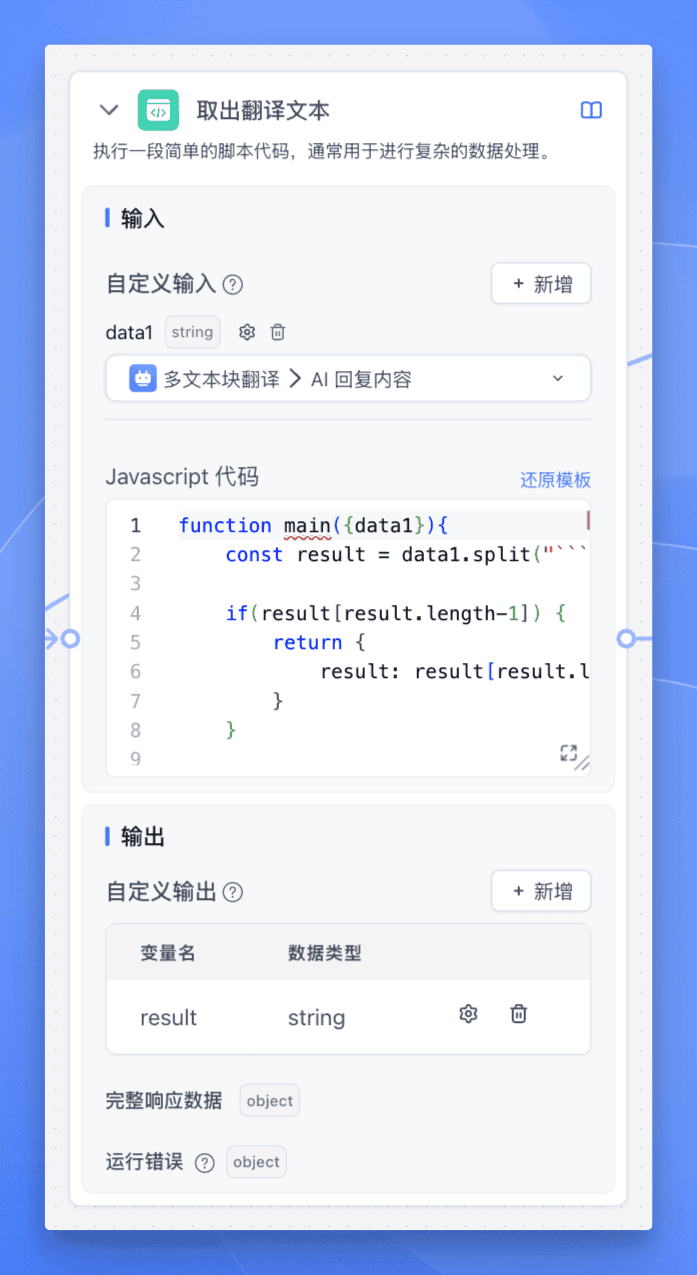
到这里,一个完整的长文本翻译循环体就配置就基本完成了。但是有些模型在输出中文内容时,会夹杂英文标点符号,所以为了以防万一,我们可以再加一个【代码运行】节点来对输出内容进行格式化。
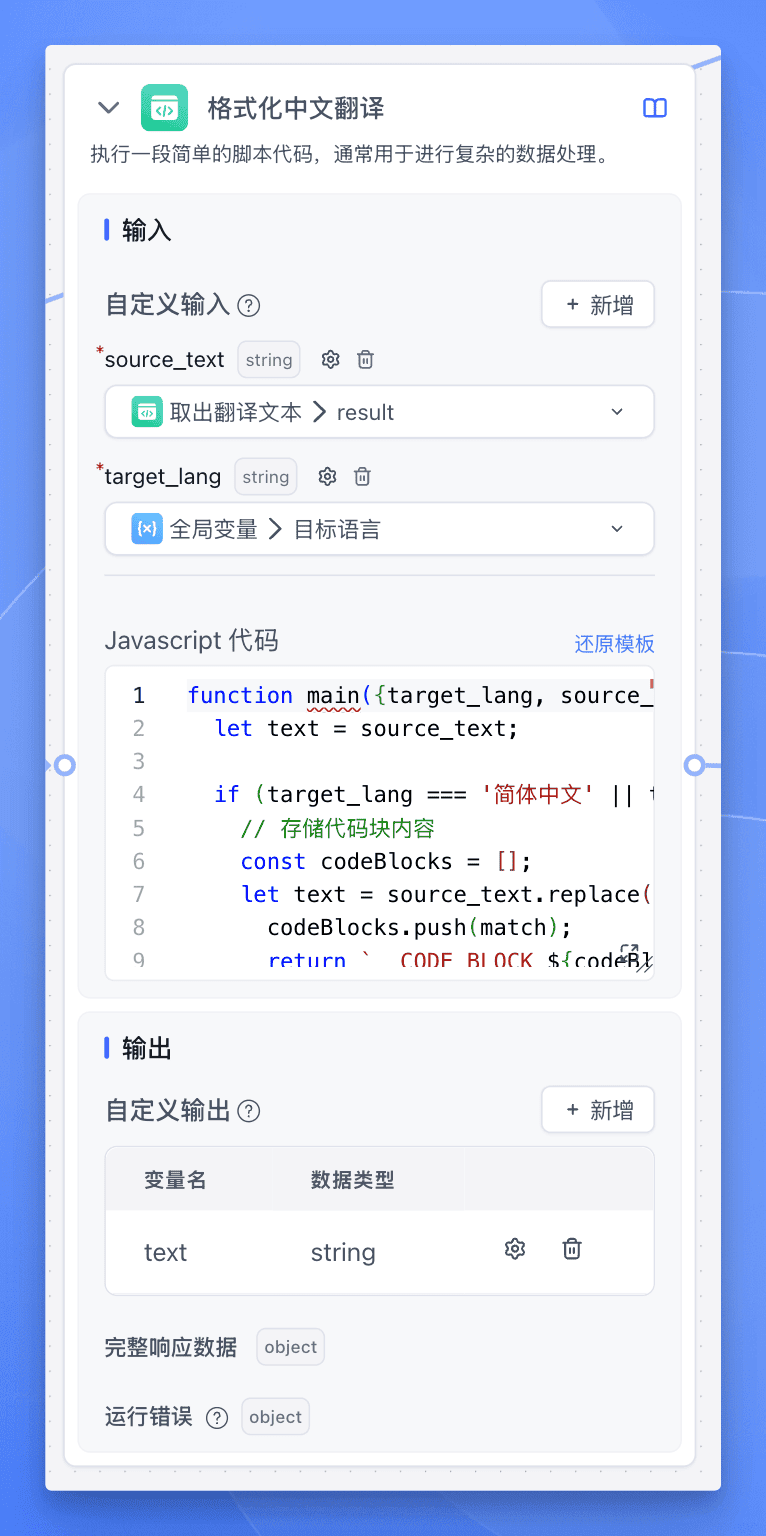
最终添加一个【指定回复】节点,输出翻译后的文本。
最后的最后,我们只需要将循环体结束节点的输出变量设置为【格式化中文翻译】节点的输出变量 text,并设置循环运行节点的输出变量为最终翻译结果数组。
下面我们来看看运行效果。
效果演示
咱们先来导入一个词库。
下载链接:https://images.tryfastgpt.ai/vocabulary.csv
导入方式很简单,在 FastGPT 中新建一个通用知识库:
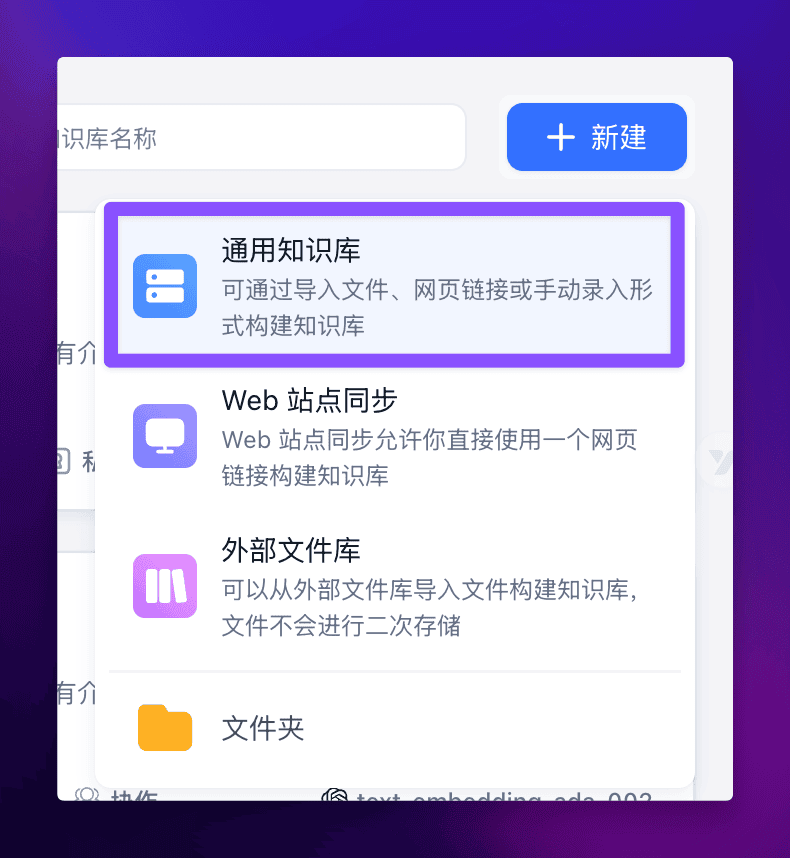
然后导入表格数据集:
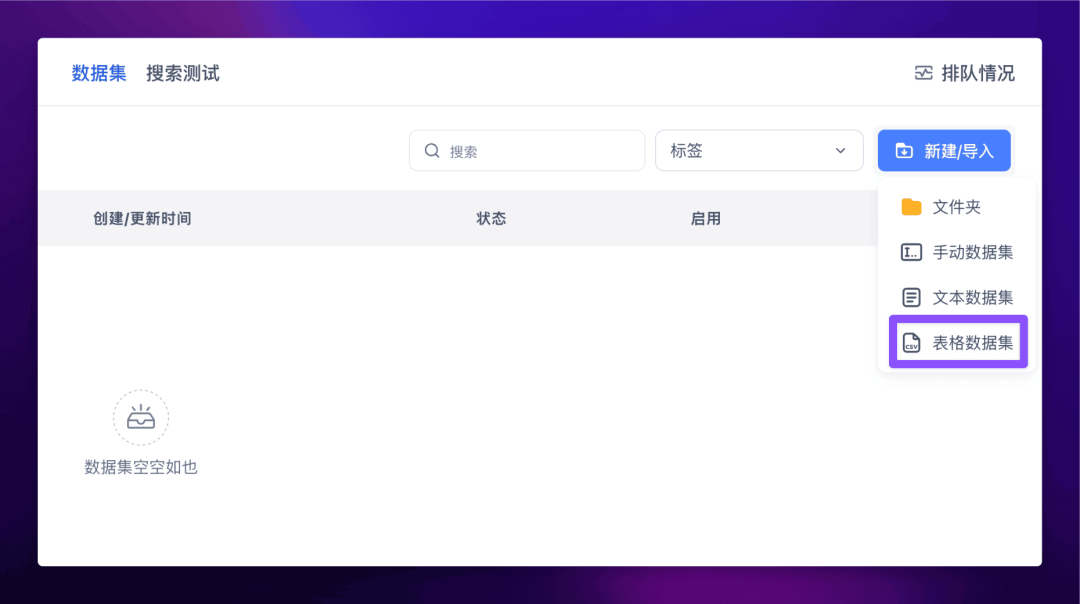
然后上传你的 csv 数据集,一路下一步,最后就得到了处理完成的词库。

点进去可以看到详情:
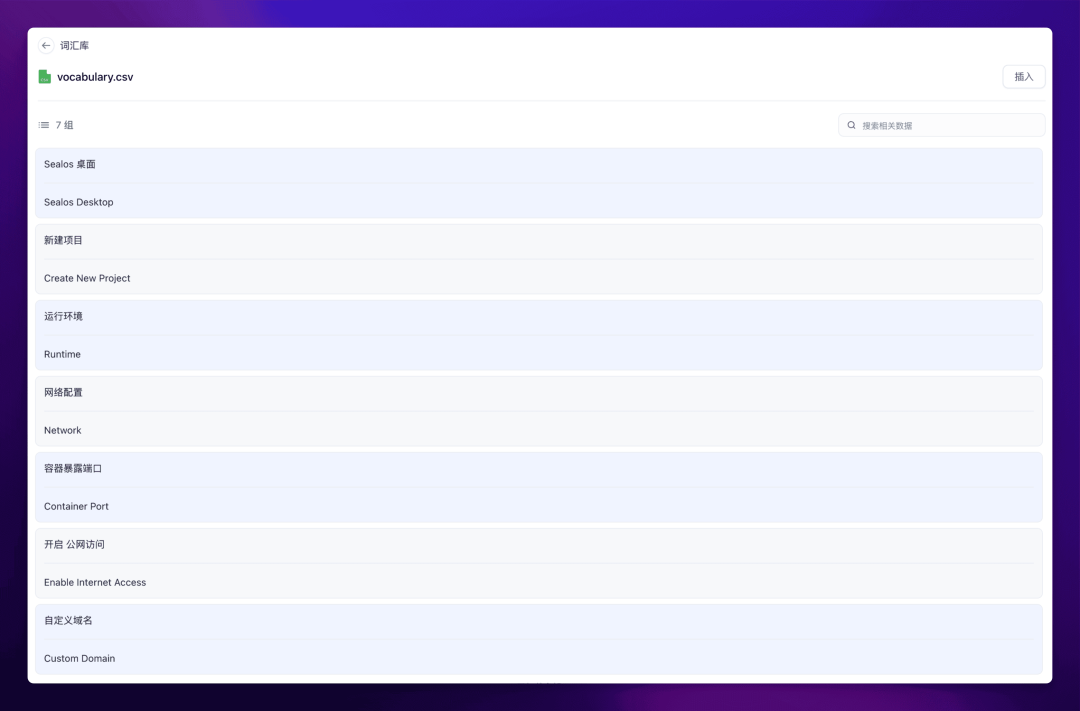
导入完成后,就可以在工作流中选择该词库了。
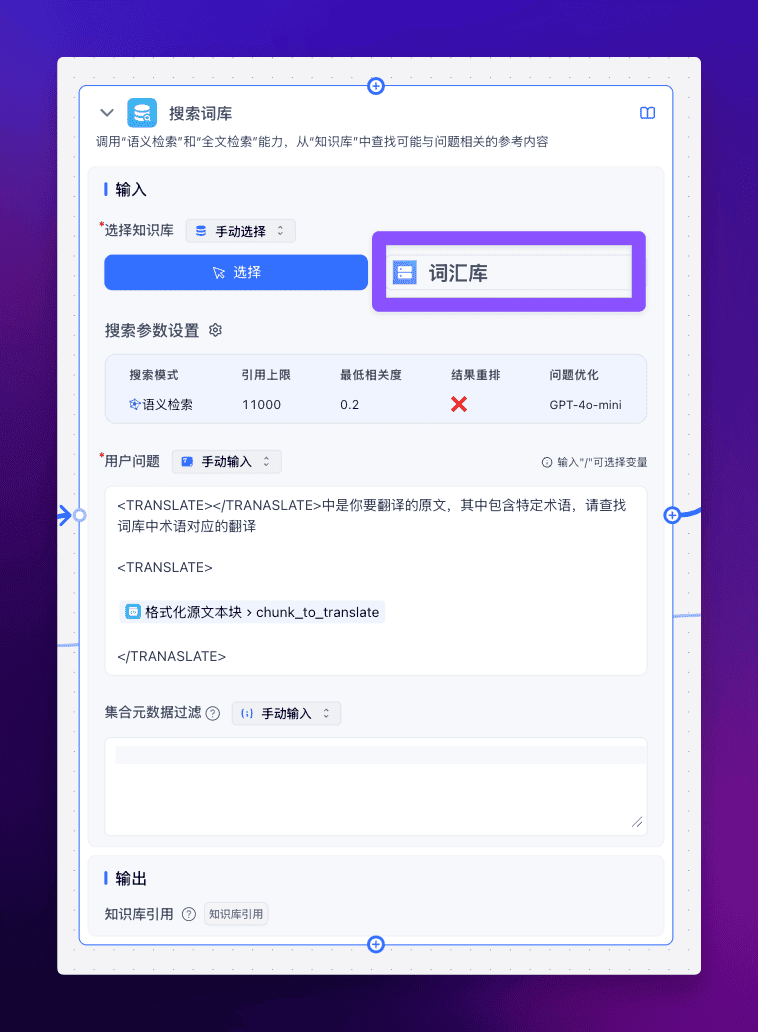
最终我们来测试一下翻译效果:
点击聊天框左侧的回形针图标上传附件,然后选择需要上传的文档。
测试文档地址:https://images.tryfastgpt.ai/Sealos-Devbox-quick-start.pdf
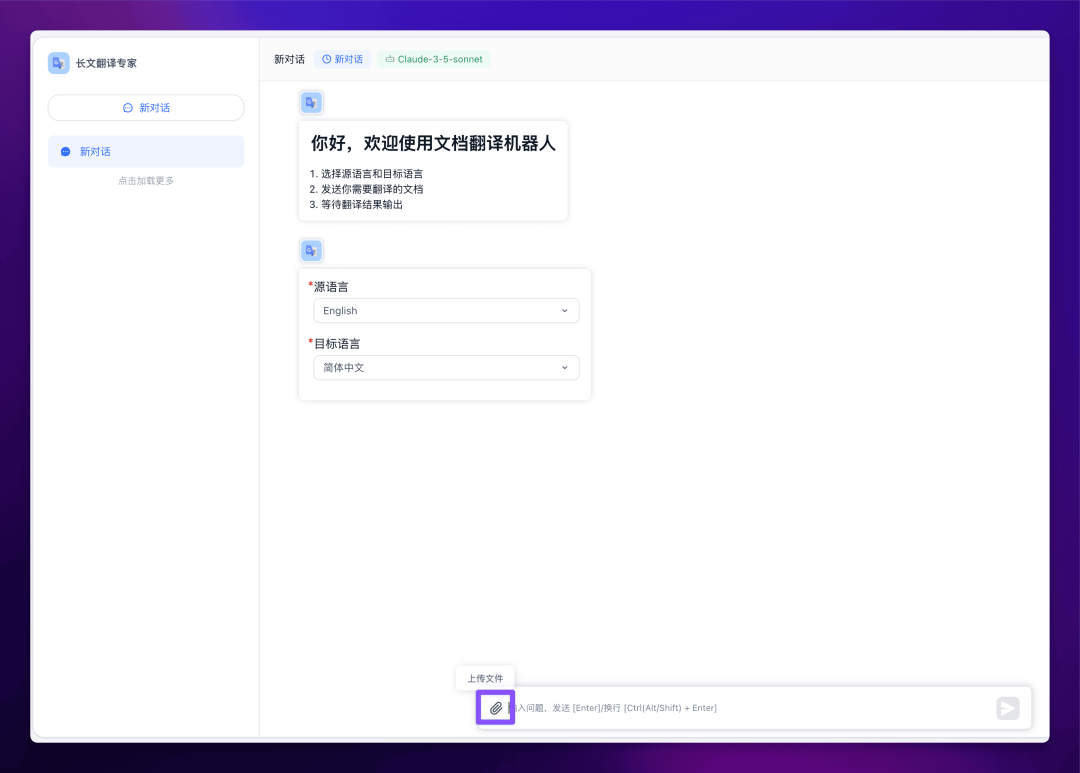
上传文档后,点击右边的发送按钮开始翻译。
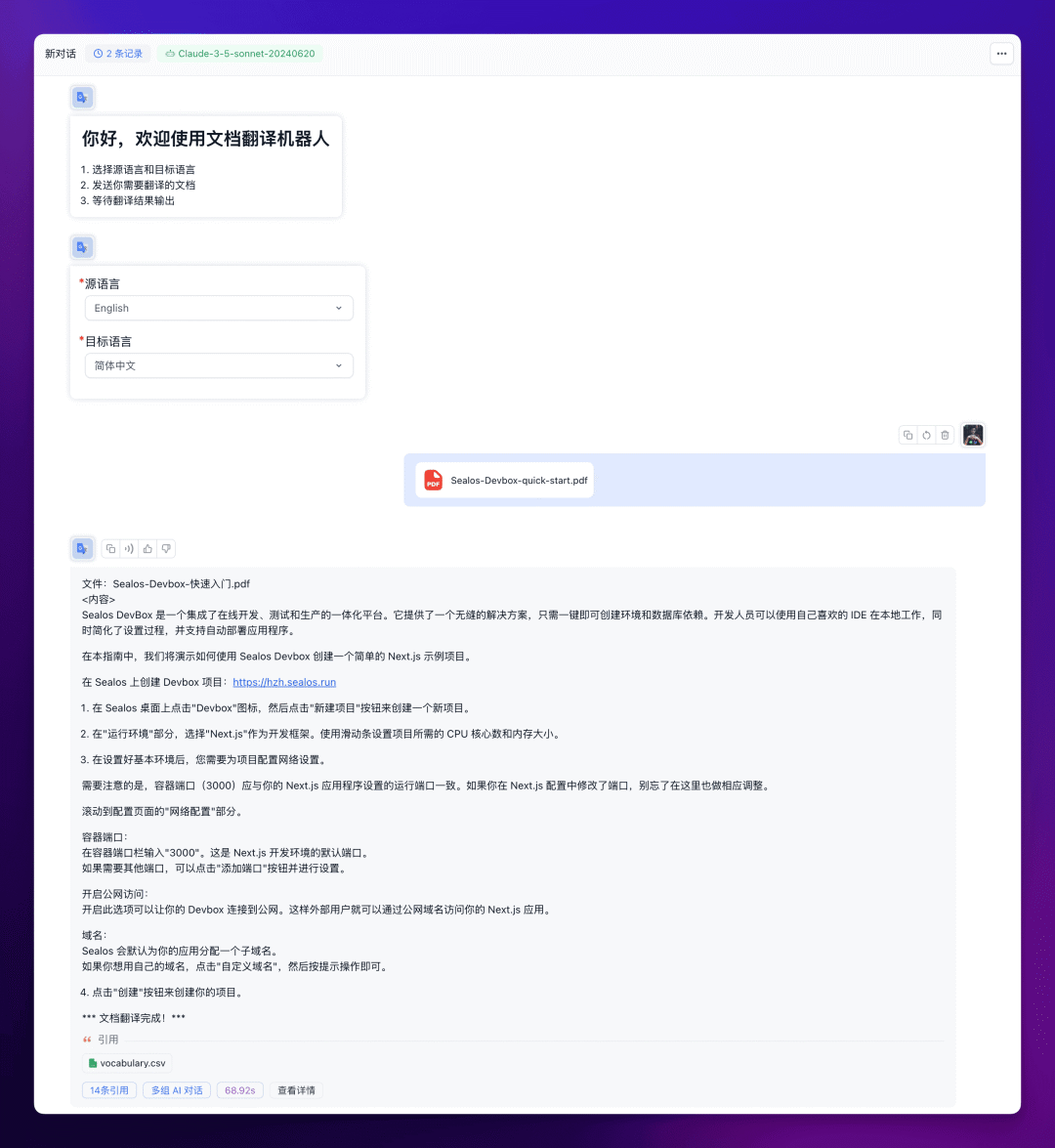
和之前文章中的工作流一样,术语翻译的一致性保持的非常完美:

总结
本文介绍了 FastGPT 循环运行节点的功能和使用场景,并通过两个具体案例展示了如何使用循环运行节点。
通过这两个案例,我们可以看到循环运行节点在处理需要重复执行的任务时的强大功能,它能够有效地组织和管理复杂的工作流程,是 FastGPT 中一个非常实用的功能模块。
还是和之前一样,想获取本文工作流的同学,只需要👇
关注公众号
后台回复「124」,限时免费领取!
↓ ↓ ↓ ↓ ↓

















 3907
3907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









