







 本文是cs224d课程的学习笔记,详细介绍了如何使用Tensorflow搭建神经网络,包括基本流程、主要步骤、Tensorflow概念、神经网络概念、Tensorboard可视化以及模型的保存和加载。通过实例解析神经网络的训练过程,帮助读者快速掌握Tensorflow入门技巧。
本文是cs224d课程的学习笔记,详细介绍了如何使用Tensorflow搭建神经网络,包括基本流程、主要步骤、Tensorflow概念、神经网络概念、Tensorboard可视化以及模型的保存和加载。通过实例解析神经网络的训练过程,帮助读者快速掌握Tensorflow入门技巧。
cs224d-Day 6: 快速入门 Tensorflow
本文是学习这个视频课程系列的笔记,课程链接是 youtube 上的,
讲的很好,浅显易懂,入门首选, 而且在github有代码,
想看视频的也可以去他的优酷里的频道找。
神经网络是一种数学模型,是存在于计算机的神经系统,由大量的神经元相连接并进行计算,在外界信息的基础上,改变内部的结构,常用来对输入和输出间复杂的关系进行建模。
神经网络由大量的节点和之间的联系构成,负责传递信息和加工信息,神经元也可以通过训练而被强化。
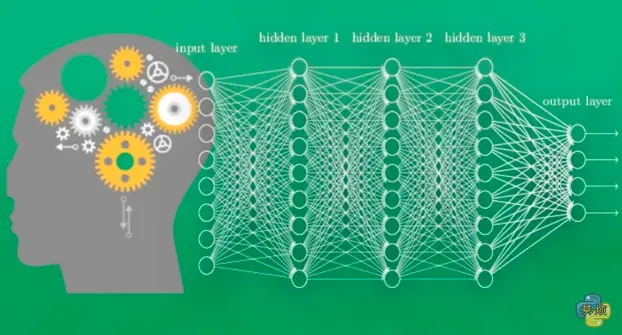
这个图就是一个神经网络系统,它由很多层构成。输入层就是负责接收信息,比如说一只猫的图片。输出层就是计算机对这个输入信息的认知,它是不是猫。隐藏层就是对输入信息的加工处理。
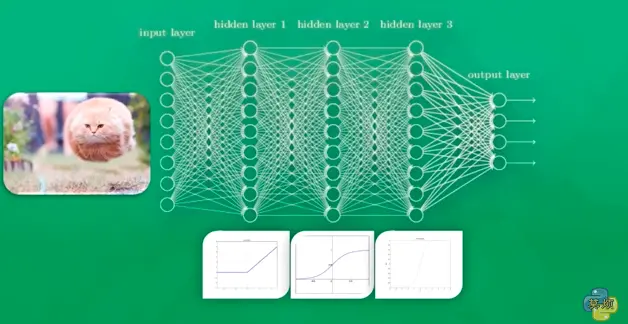
神经网络是如何被训练的,首先它需要很多数据。比如他要判断一张图片是不是猫。就要输入上千万张的带有标签的猫猫狗狗的图片,然后再训练上千万次。
神经网络训练的结果有对的也有错的,如果是错误的结果,将被当做非常宝贵的经验,那么是如何从经验中学习的呢?就是对比正确答案和错误答案之间的区别,然后把这个区别反向的传递回去,对每个相应的神经元进行一点点的改变。那么下一次在训练的时候就可以用已经改进一点点的神经元去得到稍微准确一点的结果。
神经网络是如何训练的呢?每个神经元都有属于它的激活函数,用这些函数给计算机一个刺激行为。
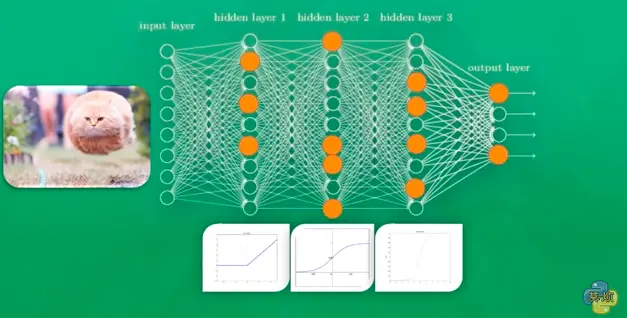
在第一次给计算机看猫的图片的时候,只有部分的神经元被激活,被激活的神经元所传递的信息是对输出结果最有价值的信息。如果输出的结果被判定为是狗,也就是说是错误的了,那么就会修改神经元,一些容易被激活的神经元会变得迟钝,另外一些神经元会变得敏感。这样一次次的训练下去,所有神经元的参数都在被改变,它们变得对真正重要的信息更为敏感。
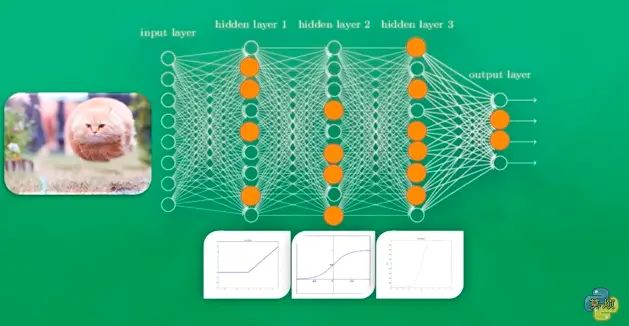
Tensorflow 是谷歌开发的深度学习系统,用它可以很快速地入门神经网络。
它可以做分类,也可以做拟合问题,就是要把这个模式给模拟出来。
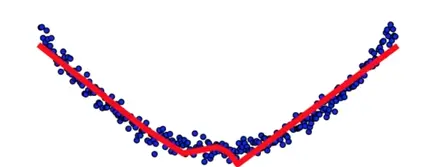
这是一个基本的神经网络的结构,有输入层,隐藏层,和输出层。
每一层点开都有它相应的内容,函数和功能。
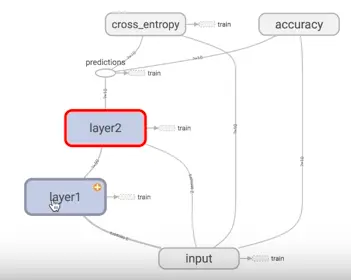
那我们要做的就是要建立一个这样的结构,然后把数据喂进去。
把数据放进去后它就可以自己运行,TensorFlow 翻译过来就是向量在里面飞。
这个动图的解释就是,在输入层输入数据,然后数据飞到隐藏层飞到输出层,用梯度下降处理,梯度下降会对几个参数进行更新和完善,更新后的参数再次跑到隐藏层去学习,这样一直循环直到结果收敛。
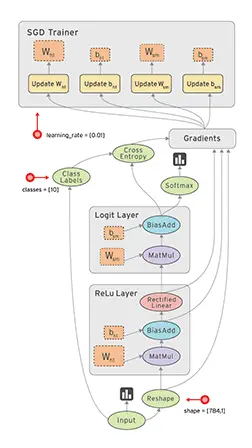
今天一口气把整个系列都学完了,先来一段完整的代码,然后解释重要的知识点!
1. 搭建神经网络基本流程
定义添加神经层的函数
1.训练的数据
2.定义节点准备接收数据
3.定义神经层:隐藏层和预测层
4.定义 loss 表达式
5.选择 optimizer 使 loss 达到最小
然后对所有变量进行初始化,通过 sess.run optimizer,迭代 1000 次进行学习:
import tensorflow as tf
import numpy as np
#### 添加层
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
#### 1.训练的数据
#### Make up some real data
x_data = np.linspace(-1,1,300)[:, np.newaxis]
noise = np.random.normal(0, 0.05, x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
#### 2.定义节点准备接收数据
#### define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
#### 3.定义神经层 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









