






目录
1.COCO数据集的预处理
所用数据集--coco train2017
先对COCO数据集中的每张图片的所有目标,裁剪成511大小的图片,以及127大小的模板图片。这个模板图片在本次训练中并没有用到,只不过通过用于跟踪训练coco数据集预处理工具包(API)处理后会将其裁剪成设置固定尺寸(可以自行设置参数,设置尺寸,这里选择的尺寸为511---255的2倍)的图片。
预处理后的图片举例如下所示:
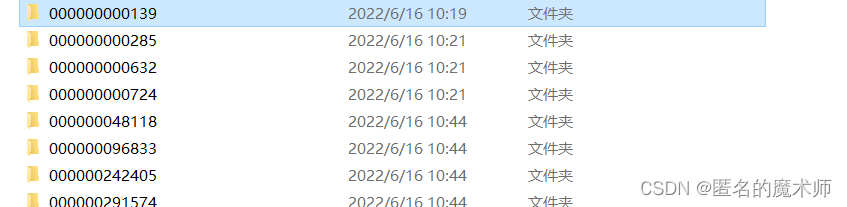
这里每个文件夹对应着一张图片, 每个文件夹下包含如下图所示:


000000.00.x.jpg

000000.00.z.jpg
可以看出,由于COCO是目标检测中的数据集,所以,对于其预处理相当于把每张图片中的所有标注的目标都单独裁剪成模板和搜索区域样本对儿(和z),这样就可以进行相似性匹配训练。而且无论样本(z)和搜索区域(x)都是以该目标为中心的。
2.coco数据集工具包处理细节
(1) 源代码
这里只复现了用到的部分,而且不需要额外的配置。这里不包含用于分割任务的 mask标签的生成,生成mask标签需要配置和导入由C++编写的文件模块。
par_crop.py
from os import mkdir, makedirs
from os.path import join, isdir
from concurrent import futures
import cv2
import sys
import time
import numpy as np
from coco import COCO
def printProgress(iteration, total, prefix='', suffix='', decimals=1, barLength=100):
"""
Call in a loop to create terminal progress bar
@params:
iteration - Required : current iteration (Int)
total - Required : total iterations (Int)
prefix - Optional : prefix string (Str)
suffix - Optional : suffix string (Str)
decimals - Optional : positive number of decimals in percent complete (Int)
barLength - Optional : character length of bar (Int)
"""
formatStr = "{0:." + str(decimals) + "f}"
percents = formatStr.format(100 * (iteration / float(total)))
filledLength = int(round(barLength * iteration / float(total)))
bar = '' * filledLength + '-' * (barLength - filledLength)
sys.stdout.write('\r%s |%s| %s%s %s' % (prefix, bar, percents, '%', suffix)),
if iteration == total:
sys.stdout.write('\x1b[2K\r')
sys.stdout.flush()
def crop_hwc(image, bbox, out_sz, padding=(0, 0, 0)):
a = (out_sz-1) / (bbox[2]-bbox[0]) # ratio size / w
b = (out_sz-1) / (bbox[3]-bbox[1]) # ratio size / h
c = -a * bbox[0]
d = -b * bbox[1]
mapping = np.array([[a, 0, c],
[0, b, d]]).astype(np.float) # 变换矩阵,这个应该就是实现以目标为中心,然后先以填充裁剪再resize
crop = cv2.warpAffine(image, mapping, (out_sz, out_sz), borderMode=cv2.BORDER_CONSTANT, borderValue=padding) # 利用仿射变换进行裁剪
return crop
def pos_s_2_bbox(pos, s): # 以目标为中心,返回填充后区域的左上角和右下角坐标 (x1,y1,x2,y2)
return [pos[0]-s/2, pos[1]-s/2, pos[0]+s/2, pos[1]+s/2]
def crop_like_SiamFC(image, bbox, context_amount=0.5, exemplar_size=127, instanc_size=255, padding=(0, 0, 0)):
target_pos = [(bbox[2]+bbox[0])/2., (bbox[3]+bbox[1])/2.] # [(x1+x2)/2, (y1+y2)/2] bbox的中心坐标,等价于 x1+(x2-x1)/2
target_size = [bbox[2]-bbox[0], bbox[3]-bbox[1]] # w, h
wc_z = target_size[1] + context_amount * sum(target_size) # w+(w+h)/2
hc_z = target_size[0] + context_amount * sum(target_size) # h+(w+h)/2
s_z = np.sqrt(wc_z * hc_z) # [(w+(w+h)/2)(h+(w+h)/2)]^1/2
scale_z = exemplar_size / s_z # ratio
d_search = (instanc_size - exemplar_size) / 2 # 尺寸差值,单边到单边
pad = d_search / scale_z # 填充时的一边范围的差值
s_x = s_z + 2 * pad # 直接加上填充的差值,就等于x填充后的尺寸
z = crop_hwc(image, pos_s_2_bbox(target_pos, s_z), exemplar_size, padding) # 返回裁剪后的模板图片
x = crop_hwc(image, pos_s_2_bbox(target_pos, s_x), instanc_size, padding) # 搜索图片
return z, x
def crop_img(img, anns, set_crop_base_path, set_img_base_path, instanc_size=511): # img,anns: <c> set_crop_base_path:'./crop511/val2017', set_img_base_path:'./val2017'
frame_crop_base_path = join(set_crop_base_path, img['file_name'].split('/')[-1].split('.')[0]) # 举例 './crop511/val2017/000000386912'
if not isdir(frame_crop_base_path): makedirs(frame_crop_base_path)
im = cv2.imread('{}/{}'.format(set_img_base_path, img['file_name'])) # 读入图片 举例 (480,640,3) 路径:'./val2017/000000386912.jpg'
avg_chans = np.mean(im, axis=(0, 1)) # 用于裁剪的填充 举例 [97.14272461, 99.71438477, 105.41124349]
for trackid, ann in enumerate(anns): # ann <c>
rect = ann['bbox'] # ground_truth bbox 举例 [210.27,143.29,219.82,276.15]
bbox = [rect[0], rect[1], rect[0] + rect[2], rect[1] + rect[3]] # xywh ---> xyxy
if rect[2] <= 0 or rect[3] <=0:
continue
z, x = crop_like_SiamFC(im, bbox, instanc_size=instanc_size, padding=avg_chans)
cv2.imwrite(join(frame_crop_base_path, '{:06d}.{:02d}.z.jpg'.format(0, trackid)), z) # 保存裁剪后的图片
cv2.imwrite(join(frame_crop_base_path, '{:06d}.{:02d}.x.jpg'.format(0, trackid)), x) # 这里裁剪后的x图片的尺寸为511
def main(instanc_size=511, num_threads=12):
dataDir = '.'
crop_path = './crop{:d}'.format(instanc_size) # 路径 ./crop511
if not isdir(crop_path): mkdir(crop_path) # 如果不存在该目录,则创建该目录
for dataType in ['val2017', 'train2017']: # 传入的两个数据集的目录
set_crop_base_path = join(crop_path, dataType) # 创建路径, ./crop511/val2017 ./crop511/train2017
set_img_base_path = join(dataDir, dataType) # ./val2017 ./train2017
annFile = '{}/annotations/instances_{}.json'.format(dataDir,dataType) # ./annotations/instances_val2017.json ./annotations/instances_train2017.json
coco = COCO(annFile)
n_imgs = len(coco.imgs) # 5000
with futures.ProcessPoolExecutor(max_workers=num_threads) as executor: # 实现多进程通信
fs = [executor.submit(crop_img, coco.loadImgs(id)[0],
coco.loadAnns(coco.getAnnIds(imgIds=id, iscrowd=None)),
set_crop_base_path, set_img_base_path, instanc_size) for id in coco.imgs]
for i, f in enumerate(futures.as_completed(fs)):
# Write progress to error so that it can be seen
printProgress(i, n_imgs, prefix=dataType, suffix='Done ', barLength=40)
print('done')
if __name__ == '__main__':
since = time.time()
# main(int(sys.argv[1]), int(sys.argv[2]))
main()
time_elapsed = time.time() - since
print('Total complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))coco.py
__author__ = 'tylin'
__version__ = '2.0'
import json
import time
try:
import matplotlib.pyplot as plt
from matplotlib.collections import PatchCollection
from matplotlib.patches import Polygon
except Exception as e:
print(e)
import numpy as np
import copy
import itertools
import os
from collections import defaultdict
import sys
PYTHON_VERSION = sys.version_info[0]
if PYTHON_VERSION == 2:
from urllib import urlretrieve
elif PYTHON_VERSION == 3:
from urllib.request import urlretrieve
def _isArrayLike(obj):
return hasattr(obj, '__iter__') and hasattr(obj, '__len__')
class COCO:
def __init__(self, annotation_file=None): # ./annotations/instances_val2017.json ./annotations/instances_train2017.json
"""
Constructor of Microsoft COCO helper class for reading and visualizing annotations.
:param annotation_file (str): location of annotation file
:param image_folder (str): location to the folder that hosts images.
:return:
"""
# load dataset
self.dataset,self.anns,self.cats,self.imgs = dict(),dict(),dict(),dict()
self.imgToAnns, self.catToImgs = defaultdict(list), defaultdict(list) # 利用 defaultdict(list) 构建 键值对应列表
if not annotation_file == None: # 传入的是 注释的json文件
print('loading annotations into memory...')
tic = time.time()
dataset = json.load(open(annotation_file, 'r')) # <c>
assert type(dataset)==dict, 'annotation file format {} not supported'.format(type(dataset))
print('Done (t={:0.2f}s)'.format(time.time()- tic))
self.dataset = dataset # 上面已经加载了 json 文件
self.createIndex()
def createIndex(self):
# create index
print('creating index...')
anns, cats, imgs = {}, {}, {}
imgToAnns,catToImgs = defaultdict(list),defaultdict(list) # imgToAnns: 图片id对应注释 catToImgs: 一个类别id对应的所有该类别下的图片id
if 'annotations' in self.dataset: #
for ann in self.dataset['annotations']: # <c>
imgToAnns[ann['image_id']].append(ann)
anns[ann['id']] = ann
if 'images' in self.dataset:
for img in self.dataset['images']: # 包含图片的一些信息, 路径,长宽等
imgs[img['id']] = img
if 'categories' in self.dataset:
for cat in self.dataset['categories']: # 类别信息
cats[cat['id']] = cat
if 'annotations' in self.dataset and 'categories' in self.dataset:
for ann in self.dataset['annotations']:
catToImgs[ann['category_id']].append(ann['image_id'])
print('index created!')
# create class members
self.anns = anns
self.imgToAnns = imgToAnns
self.catToImgs = catToImgs
self.imgs = imgs
self.cats = cats
def info(self):
"""
Print information about the annotation file.
:return:
"""
for key, value in self.dataset['info'].items():
print('{}: {}'.format(key, value))
def getAnnIds(self, imgIds=[], catIds=[], areaRng=[], iscrowd=None):
"""
Get ann ids that satisfy given filter conditions. default skips that filter
:param imgIds (int array) : get anns for given imgs
catIds (int array) : get anns for given cats
areaRng (float array) : get anns for given area range (e.g. [0 inf])
iscrowd (boolean) : get anns for given crowd label (False or True)
:return: ids (int array) : integer array of ann ids
"""
imgIds = imgIds if _isArrayLike(imgIds) else [imgIds] # 后面的成立
catIds = catIds if _isArrayLike(catIds) else [catIds] # catIds={list:0} []
if len(imgIds) == len(catIds) == len(areaRng) == 0: # False
anns = self.dataset['annotations']
else:
if not len(imgIds) == 0: # True
lists = [self.imgToAnns[imgId] for imgId in imgIds if imgId in self.imgToAnns]
anns = list(itertools.chain.from_iterable(lists)) # 迭代拿出其中的元素装进一个列表里 <c>
else:
anns = self.dataset['annotations']
anns = anns if len(catIds) == 0 else [ann for ann in anns if ann['category_id'] in catIds] # <c> 1
anns = anns if len(areaRng) == 0 else [ann for ann in anns if ann['area'] > areaRng[0] and ann['area'] < areaRng[1]] # <c> 2 areaRng 传入的参数, 这里为 []
if not iscrowd == None: # False
ids = [ann['id'] for ann in anns if ann['iscrowd'] == iscrowd]
else:
ids = [ann['id'] for ann in anns] # <c> anns中 字典的 键id 对应的值 <c>
return ids
def loadImgs(self, ids=[]): # 图片的信息,不是具体的图片矩阵
"""
Load anns with the specified ids.
:param ids (int array) : integer ids specifying img
:return: imgs (object array) : loaded img objects
"""
if _isArrayLike(ids):
return [self.imgs[id] for id in ids]
elif type(ids) == int: # True
# a = self.imgs[ids] # 包含图片的路径啥的信息, <c>
return [self.imgs[ids]]
def loadAnns(self, ids=[]):
"""
Load anns with the specified ids.
:param ids (int array) : integer ids specifying anns
:return: anns (object array) : loaded ann objects
"""
if _isArrayLike(ids): # True
# b = [self.anns[id] for id in ids] # <c>
return [self.anns[id] for id in ids]
elif type(ids) == int:
return [self.anns[ids]]gen_json.py
from coco import COCO
from os.path import join
import json
dataDir = '.'
count = 0
for dataType in ['val2017', 'train2017']:
dataset = dict()
annFile = '{}/annotations/instances_{}.json'.format(dataDir, dataType) # './annotations/instances_val2017.json'
coco = COCO(annFile) # <c>
n_imgs = len(coco.imgs) # 5000
for n, img_id in enumerate(coco.imgs): # img_id 举例 397133 拿出每个图片的所有的标注信息
# print('subset: {} image id: {:04d} / {:04d}'.format(dataType, n, n_imgs))
img = coco.loadImgs(img_id)[0] # <c>
annIds = coco.getAnnIds(imgIds=img['id'], iscrowd=None) # <c>
anns = coco.loadAnns(annIds) # <c>
video_crop_base_path = join(dataType, img['file_name'].split('/')[-1].split('.')[0]) # 举例 'val2017/000000397133'
if len(anns) > 0:
dataset[video_crop_base_path] = dict() # {'val2017/000000397133':{}}
for trackid, ann in enumerate(anns): # ann <c> 相当于拿出每张图片的每个目标的bbox
rect = ann['bbox'] # bbox
c = ann['category_id'] # 类别 id
bbox = [rect[0], rect[1], rect[0] + rect[2], rect[1] + rect[3]] # xywh to xyxy
if rect[2] <= 0 or rect[3] <= 0: # lead nan error in cls.
count += 1
print(count, rect)
continue
dataset[video_crop_base_path]['{:02d}'.format(trackid)] = {'000000': bbox} # 举例 {'val2017/000000397133':{'00':{'000000':[217.62,240.54,256.61,298.289999]}}}
print('save json (dataset), please wait 20 seconds~')
json.dump(dataset, open('{}.json'.format(dataType), 'w'), indent=4, sort_keys=True) # 将字典写入json文件,indent表示前边间隔长度,sort_key 表示按键顺序进行排列
print('done!')(2)debug时的参数截图
i.coco.py
dataset---load json

dataset--info

dataset--licenses

dataset--images
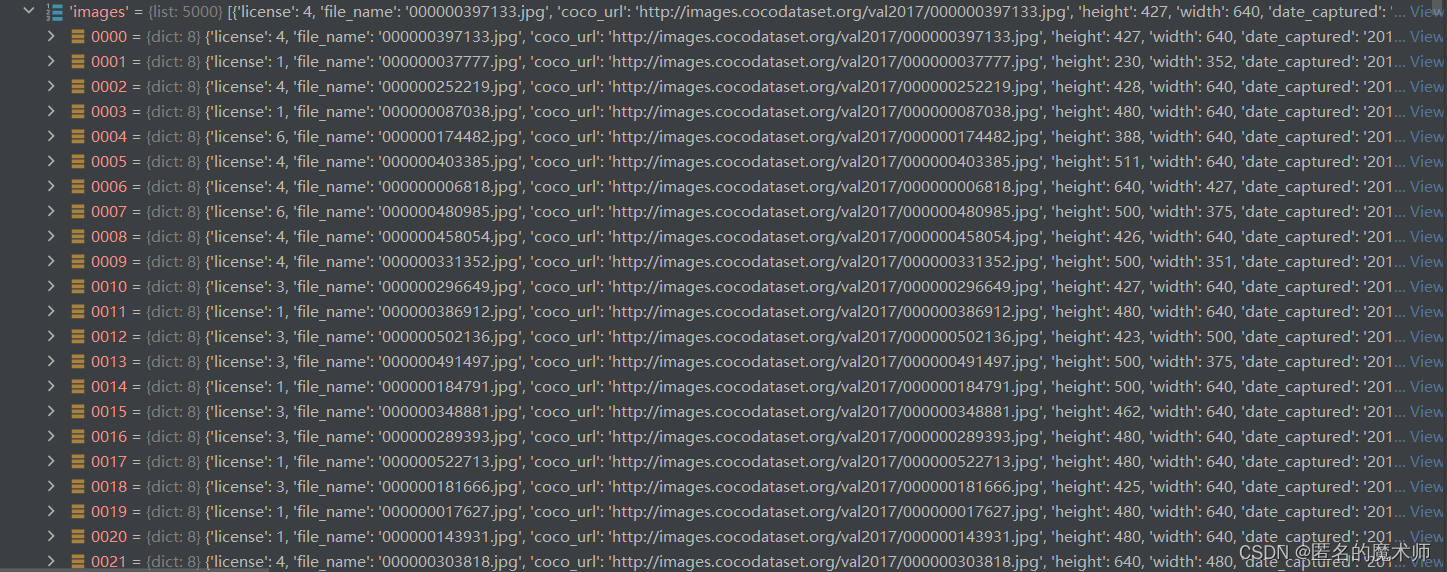
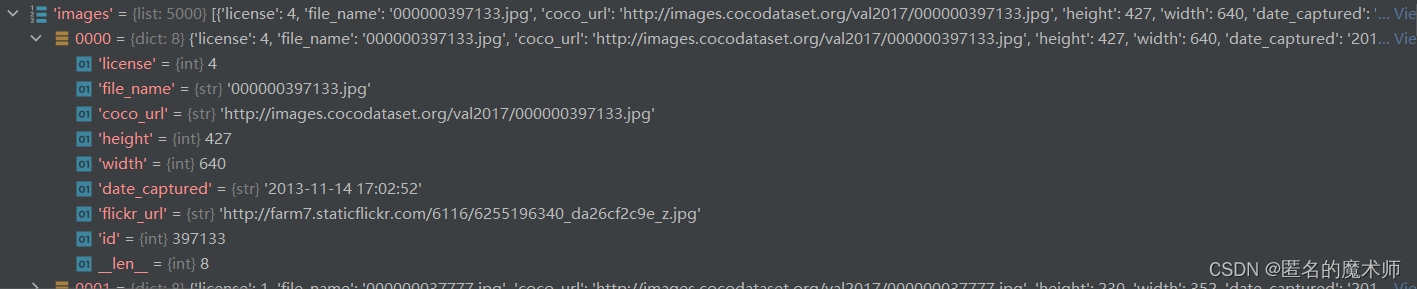
dataset--annotations (里面包含两种ground_ruth,segmentation分割的以及bbox)


dataset--categories

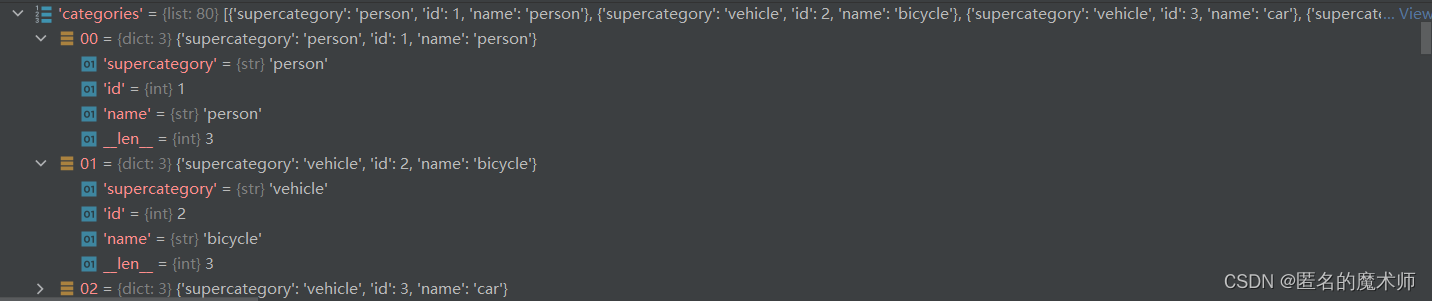
ann

imgToAnns 以及 anns
《刚开始时》

![]()
《第一次循环结束后》--它们的id不一样

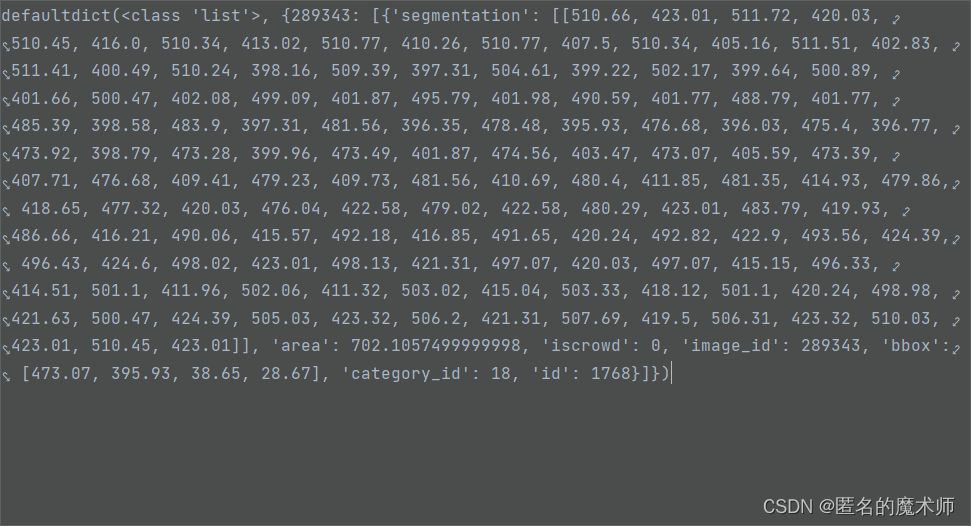

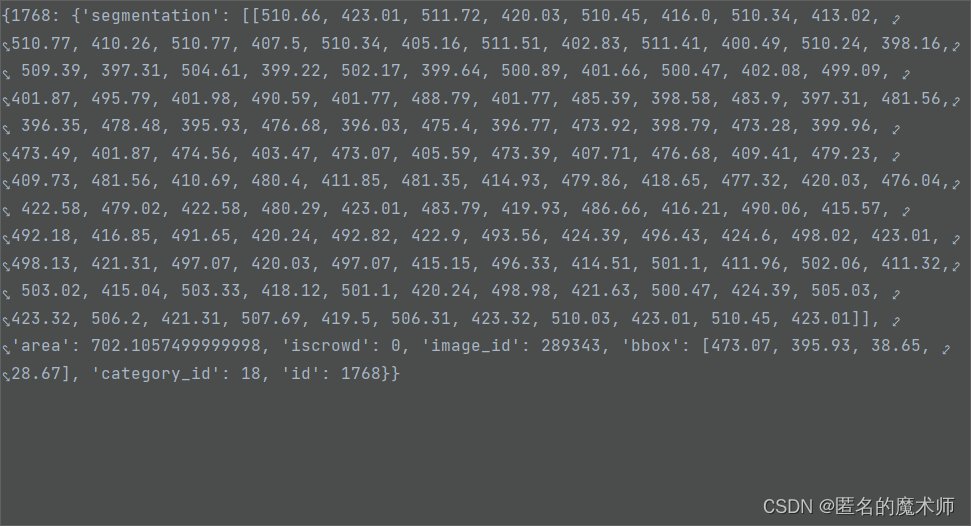
《循环结束后》


img

imgs
《第一次循环》

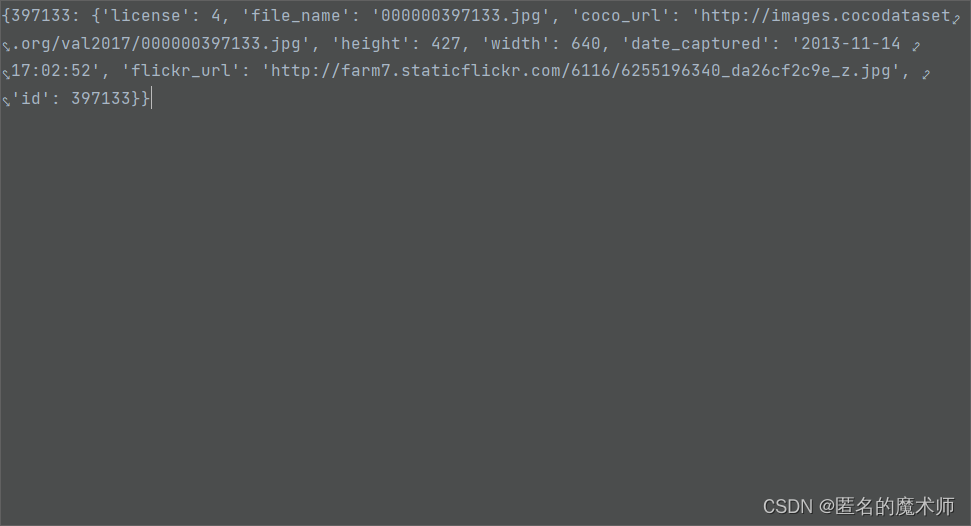
《循环结束后》
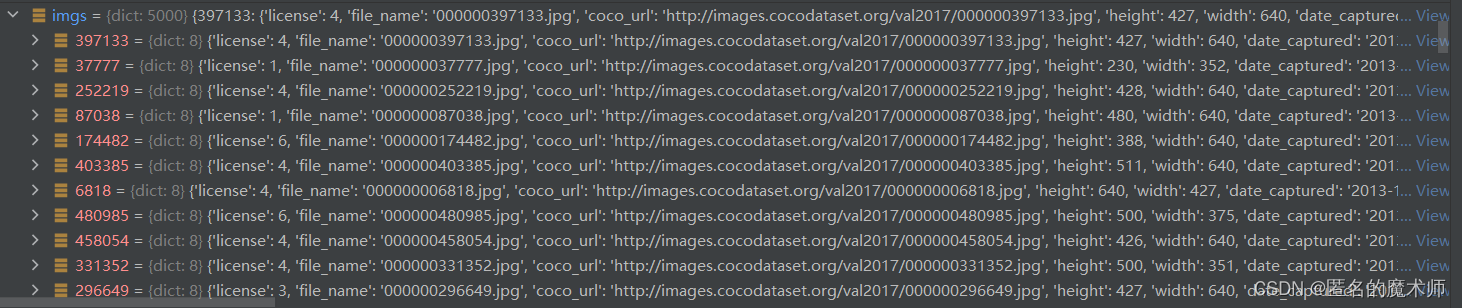
cat
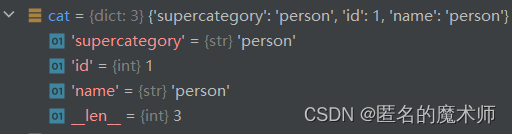
cats
《第一次循环结束后》

《循环结束后》--可以看到一共80个类别
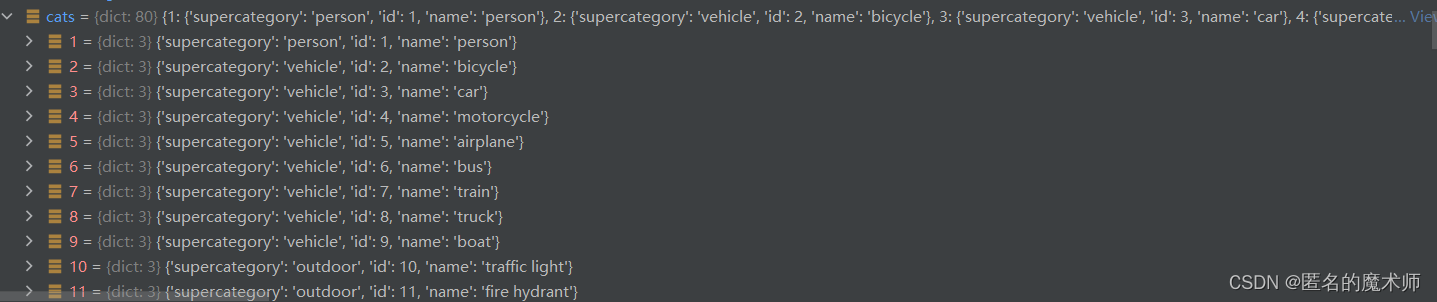
catToImgs 以及 ann
《第一次循环结束后》


《循环结束后》-- 可以看出,其中包含的字典信息是 一个类别下的 所有图片的id
a

lists

anns
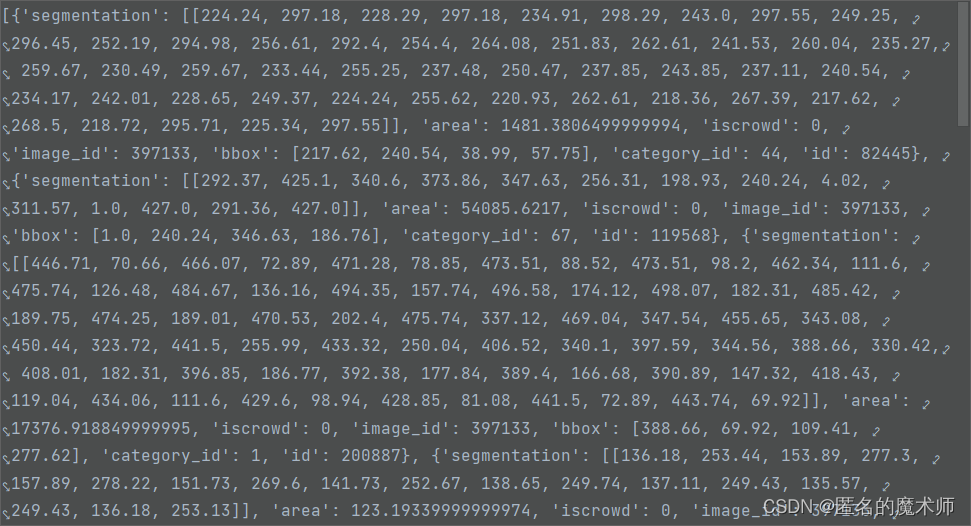
《if 下的》
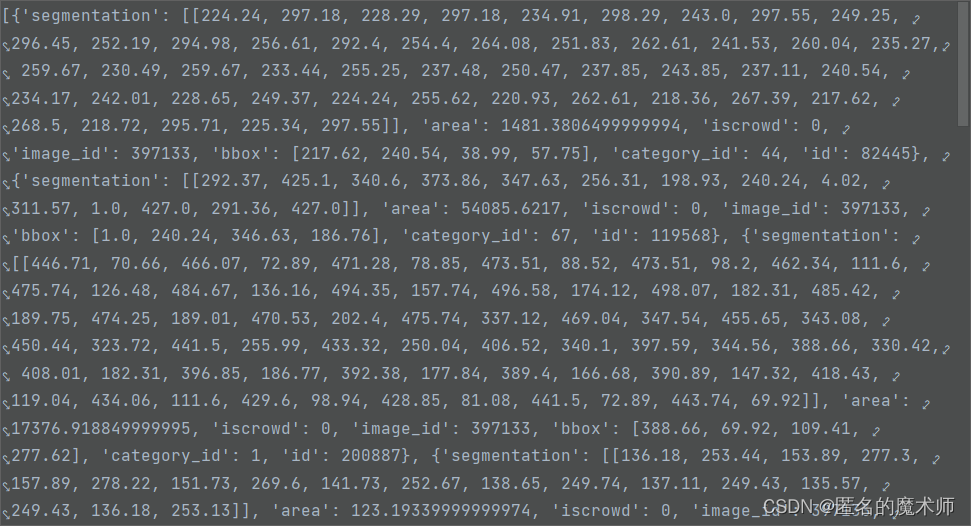
《1》
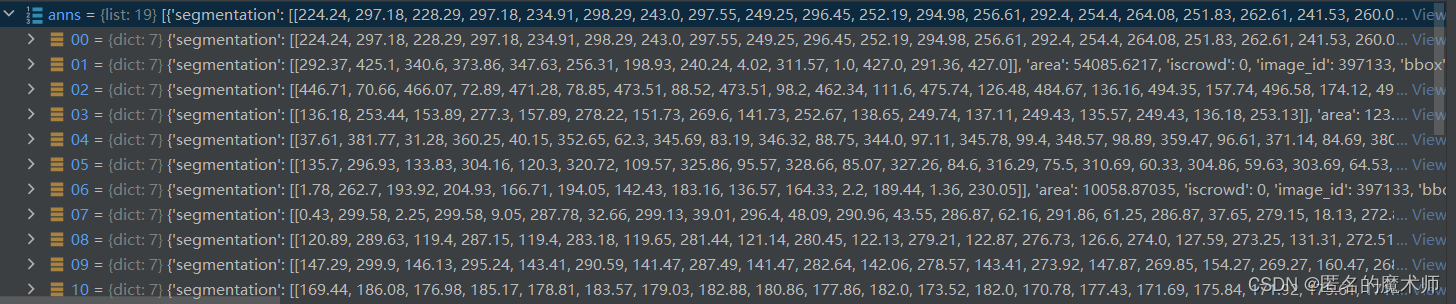
《2》
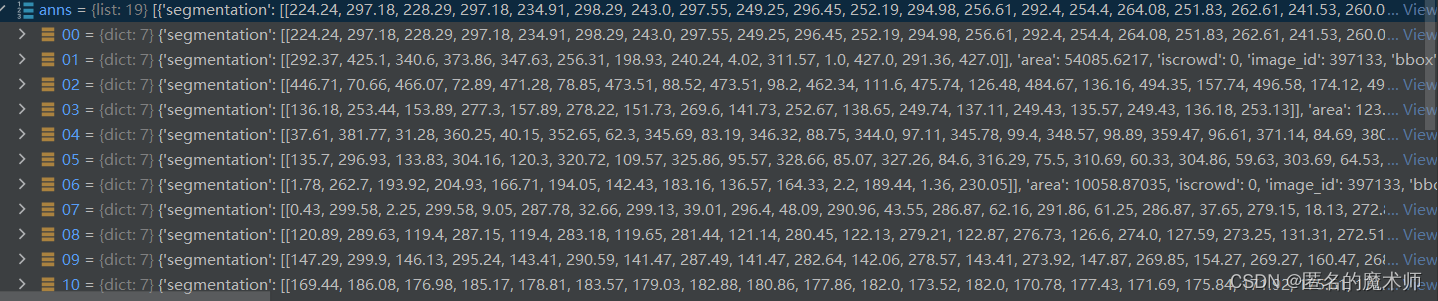
ids
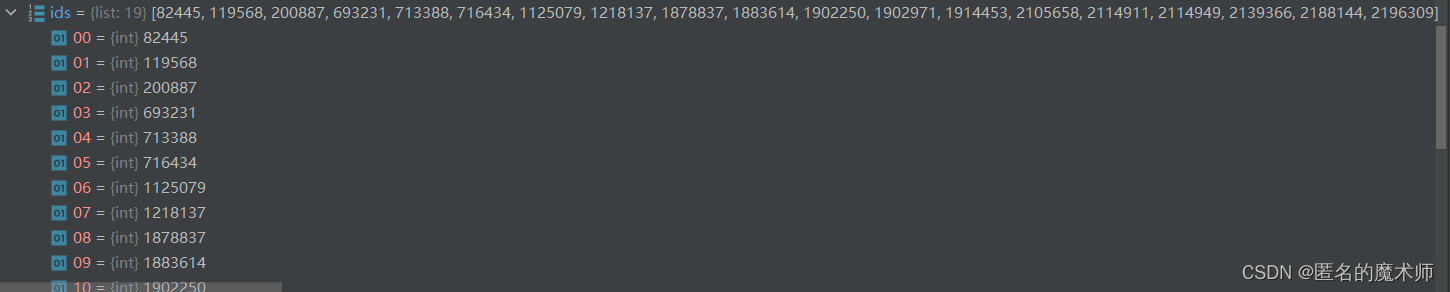
b
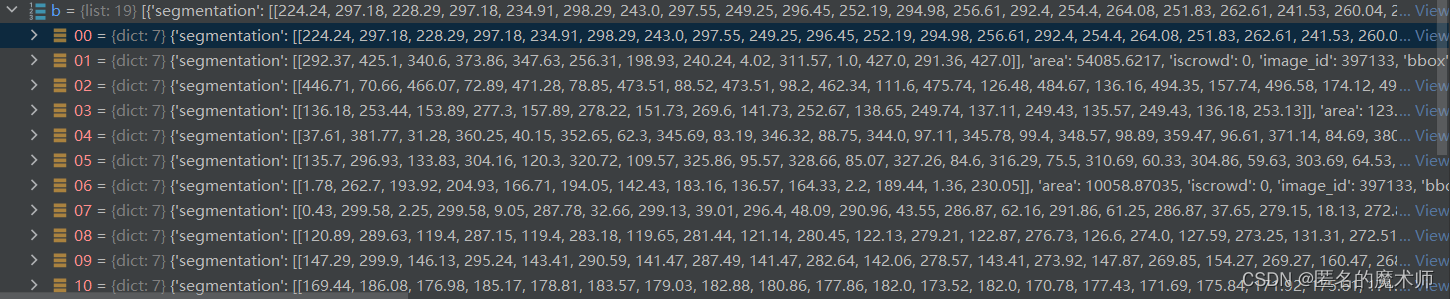
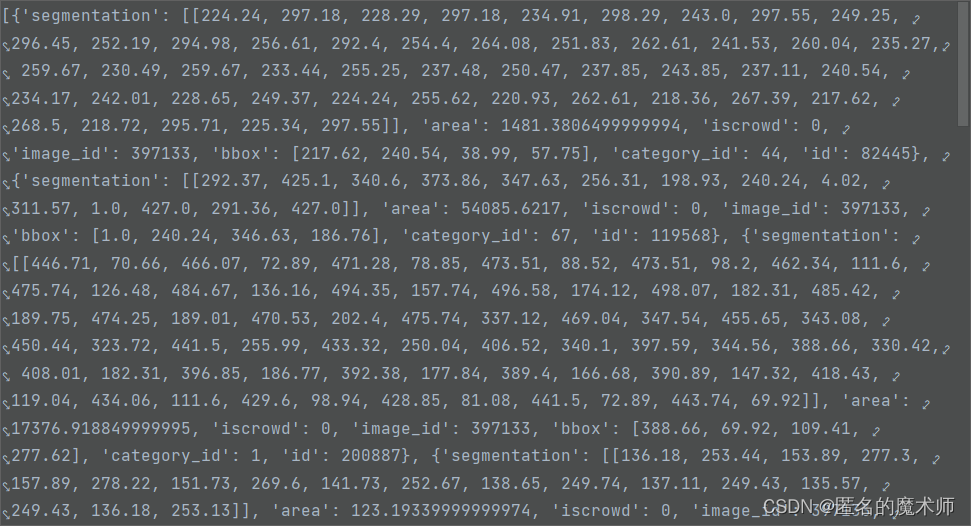
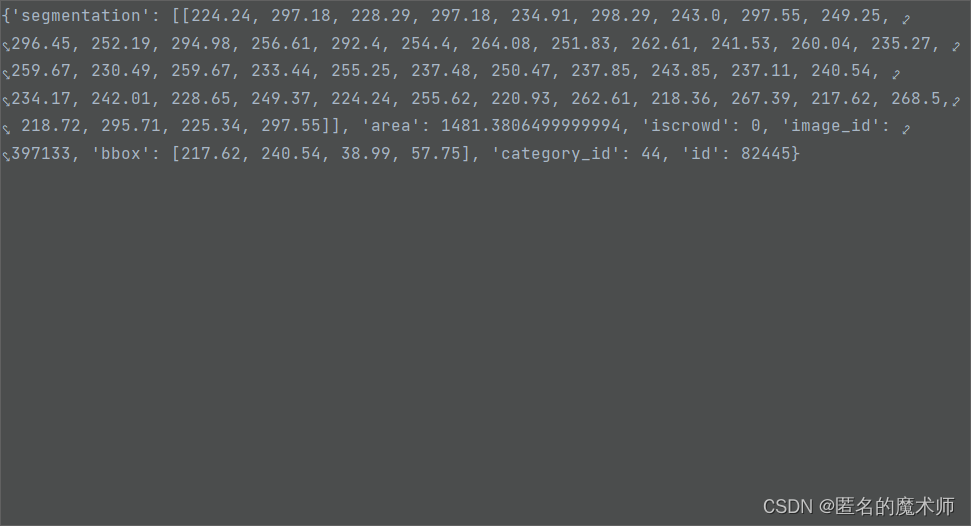
ii. par_crop.py
img

anns
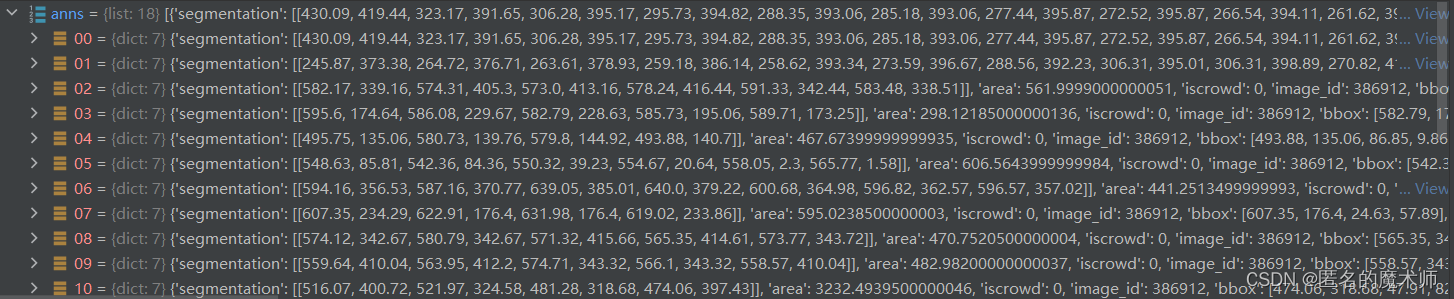
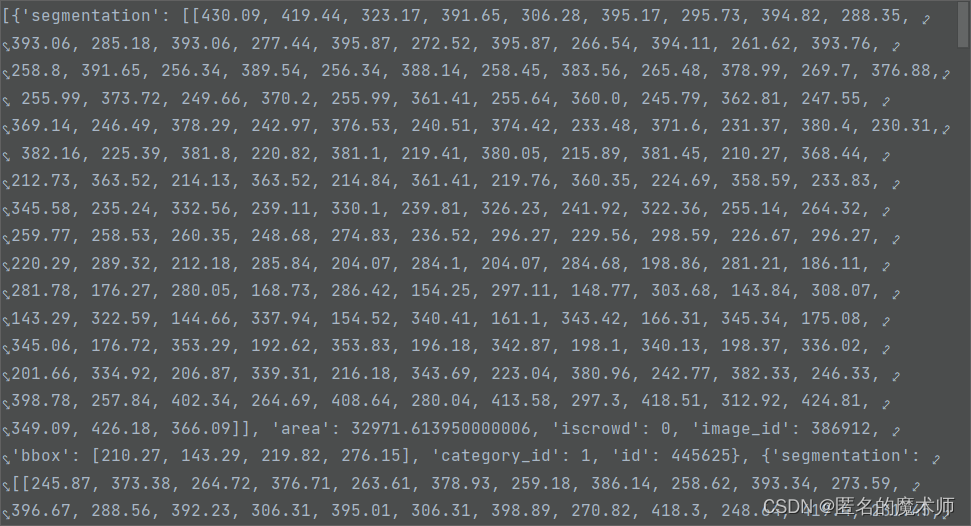

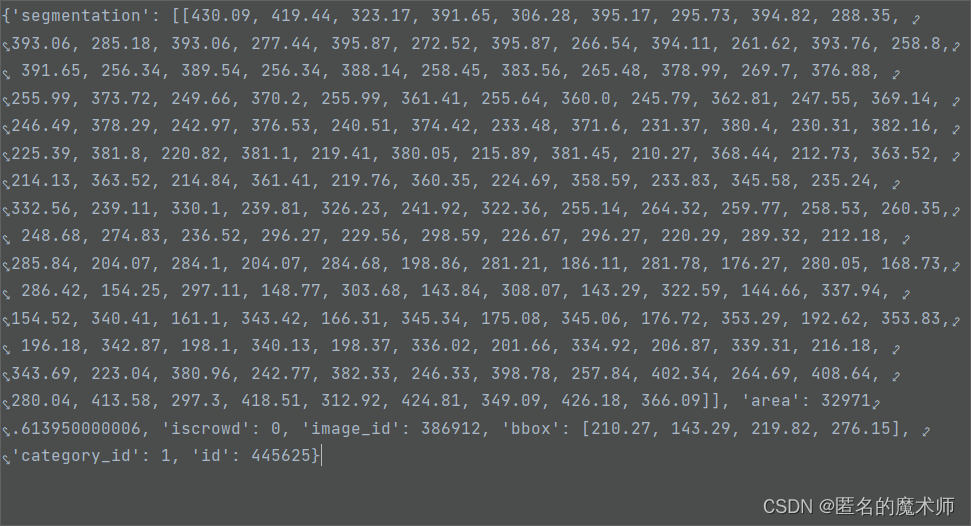
ann

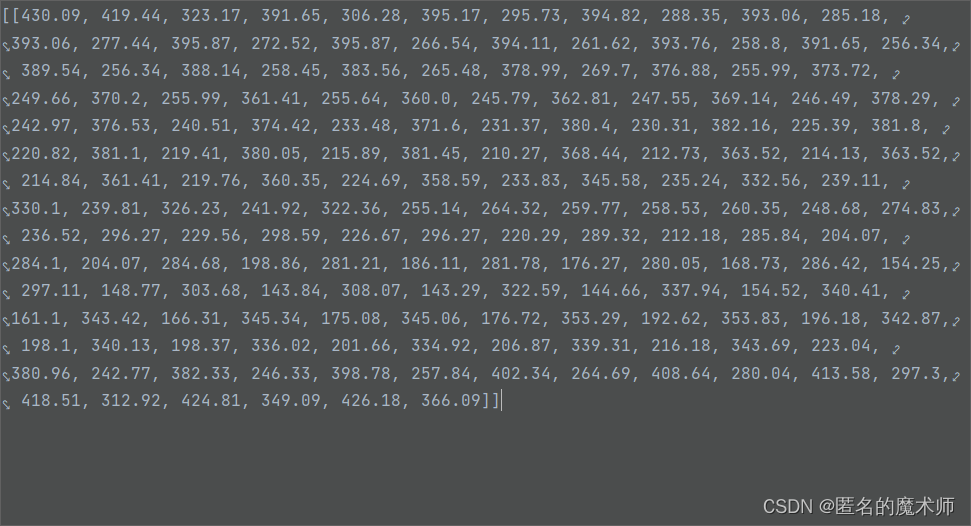
iii gen_json.py
coco

img

annIds

anns

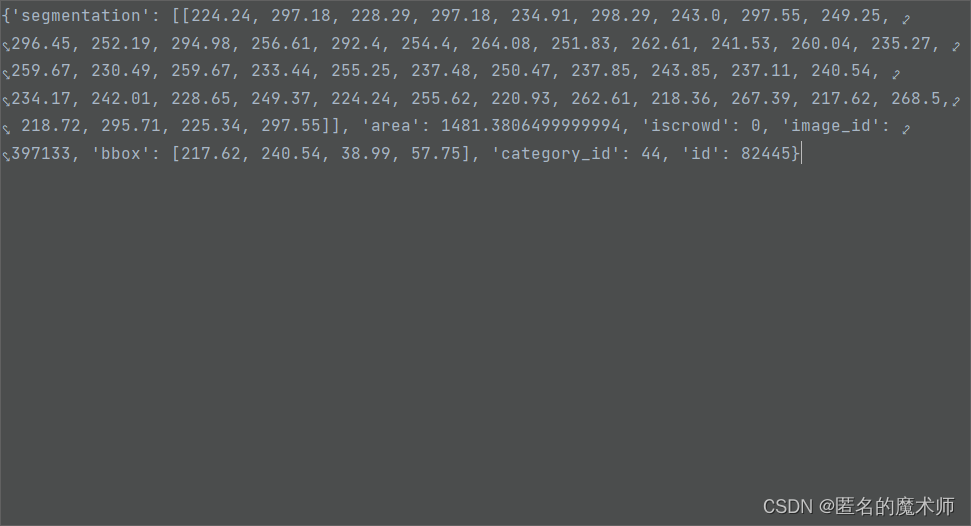
ann

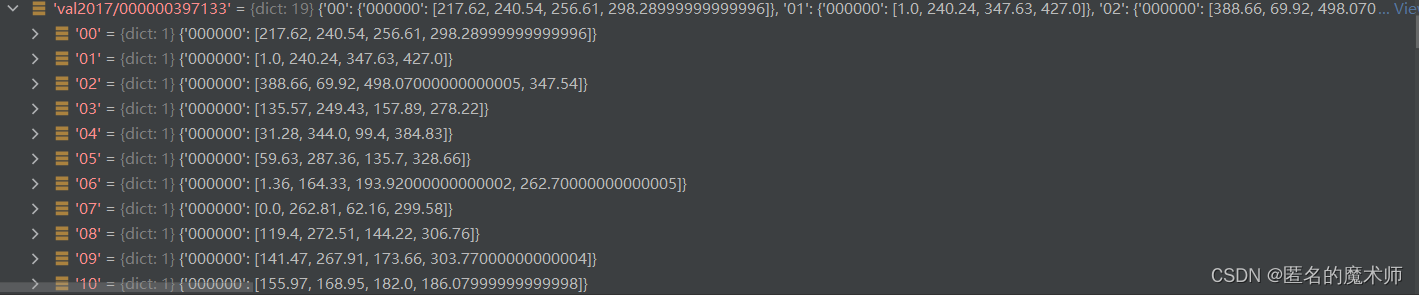
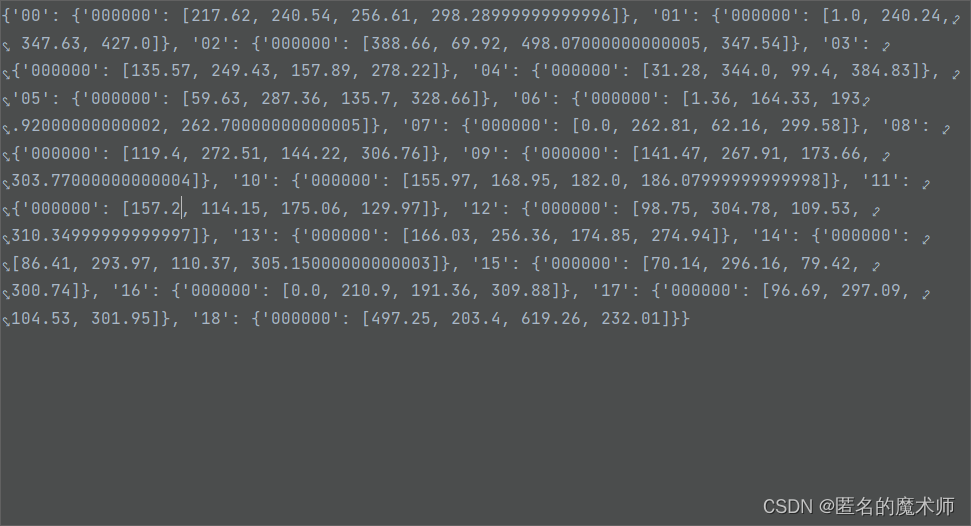
dataset------《循环结束后》
下面这个例子不是完整的,真正的dict长度远大于4952

3. 训练数据的 数据增强操作
(1) 所处理的图片
模板 和 搜索图片 用的都是同一张图片,之后会对其进行处理,resize成相应的输出。举例如下(511,511,3)

ground_truth如下:

(2) 平移加尺度变换
对训练数据的平移加尺度变换 体现在对其 裁剪基准的bbox 的变换。如下所示,标注了一些裁剪的bbox

裁剪后的图片如下图所示

(3)模糊

(4)颜色增强
这里用cv2显示图片时需要将颜色增强后的图片矩阵中元素从浮点数类型转换成int类型再现示才可以,否则浮点数显示会异常。用 astype语句准换格式
search1 = search.astype(np.int8)如下所示


(5)翻转
没什么可说的,如下图所示:



















 3770
3770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











