







链接:https://www.zhihu.com/question/19558514/answer/65479687
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
第一,Protégé这个软件是斯坦福大学基于JAVA语言开发的用于编辑本体的软件,即只是一个「编辑本体的工具」
第二,DBpedia是目前已建立的一个比较大型的本体,它的术语和术语间的关系基于英文维基百科中的「词条」和「InfoBox」(可去官网dbpedia.org/下载)
第三,Taxonomy只是分类法,还不够到称为本体ontology的标准
————————————————————————————————————————————
本体这个概念,对于初学者来说的确有些抽象,不易理解。它是语义网中重要的一个技术。
我的思路和方法是,抛开哲学层面和我们日常生活中理解的本体含义,单从语义网的角度来理解本体这个概念。其实非常简单,用一句话就可以概括——本体定义了组成「主题领域」的词汇表的「基本术语」及其「关系」,以及结合这些术语和关系来定义词汇表外延的「规则」。
下面将根据其中涉及到的四个关键词一步步来看本体是如何建立的:
第一,领域(domain of discourse),一个本体描述的是一个特定的领域。比如我们确定这次要描述的领域是「大学」。
第二,术语(term),指给定领域中的重要概念。例如,确定要描述「大学」了,对于一个大学来说什么概念是重要的呢?我们可以列举出「教工」、「学生」、「课程」等等概念。
第三,基本术语之间的关系,包括类的层次结构(可类比「taxonomy」理解)。列举出了「教工」「学生」等这些重要的概念,那么这些概念之间是什么关系呢?并列?上下位类?下图就是对「大学」这个论域来说建立各术语之间的层次关系。
可以看到,大学师生员工中包含了教工和学生,学生又可分为本科生和研究生,教工同理,而学生和教工是两个并列的概念。
<img src="https://pic2.zhimg.com/a54481daee7d9759643375459a0cc949_b.png" data-rawwidth="584" data-rawheight="338" class="origin_image zh-lightbox-thumb" width="584" data-original="https://pic2.zhimg.com/a54481daee7d9759643375459a0cc949_r.png">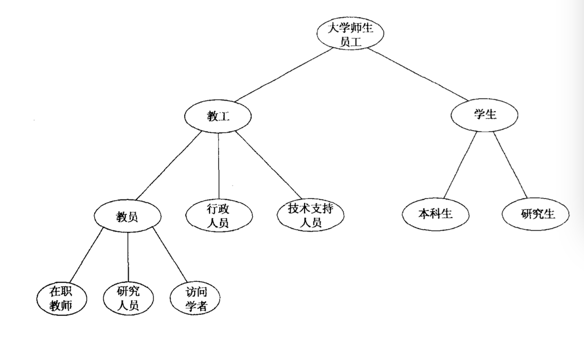
第四,词汇表外延的规则(可类比数据库中的「约束」概念理解),包括
(1)属性(例如X教Y)
(2)值约束(例如,只有教职人员才能授课)
(3)不相交描述(例如,教职人员和普通员工不相交)
(4)对象间逻辑关系的规定例如(例如,一个系至少要有10个教职员工)
其实上面说建立本体的四步这句话说的并不严谨。
手工建立本体一般分为8个阶段。
下面拿自己语义网的大作业举例子(还是拿 @cow wide 男神的作业吧23333),简单介绍建立本体的8个阶段,希望能对楼主理解“本体的具体例子”有帮助。
1. 确定范围:确定“小说”这个论域
2. 考虑复用:复用DBpedia和Dublin Core中的部分术语
3. 列举术语:列举出Library、Novel、Writer、Translator等小说论域中重要的术语
4. 定义分类:一级类包括Library, Novel, Person, Place, Publisher等,一级类Novel的子类包括Chinese_Novel和Foreign_Novel,以此类推
5. 定义属性:如定义isCreatedBy这一属性,其定义域是FictionalCharacter,值域是Writer
6. 定义侧面:如基数约束:在此本体中,如BirthTime、gender、ISBN等属性必须有且只有一个值
6. 定义实例:如,导入《射雕英雄传》这本书及其相关信息
8. 检查异常:在protégé4.3中,可以使用推理机对本体自身的不一致和置入本体的实例集不一致进行检查
介绍完了「本体是什么」和简单的「建立本体所用的工具」,下面的问题就是,「为什么要用本体?」
在万维网中,我们可能会用不同的术语来表达相同的含义,或者一个术语含有多个含义。因此,消除术语差异是很有必要的。目前我们的解决方案就是,对某个领域建立一个公共的本体。鼓励大家在涉及该领域的时候都使用公共本体里的术语和规则。
「本体的一些典型应用场景」:
1. 本体可用于网站的组织和导航。如,网站页面左边中往往会列出在概念层次结构中最高层的术语,用户可以点击其中之一来浏览相关子目录。
2. 本体可用于提高网络搜索的精确度。如,搜索引擎可以根据本体中的「概念」来查找相关概念,而不是「关键词」,以消除术语差别。
3. 本体可用于网络搜索中更一般或更特殊的查询。如果一个查询失败了,搜索引擎可以向用户推荐更一般的查询(或搜索引擎主动执行这样的查询);反之,如果一个查询查到的结果太多,搜索引擎可以建议用户使用更特殊的查询。
目前最重要的「本体语言」包括(逐层递进)
1. XML : 为结构化文档提供一种表层语法,但没有对这些文档的含义提供语义约束。XML与HTML的关系和区别计算机相关人员应该都有所了解,在此不再赘言。
2. XML Schema:定义XML文档结构,即定义所有可能用到的元素名和属性名,同时还要定义文档的结构:一个属性可以使用什么样的值,哪些元素可以出现在其他元素中。
3. RDF:描述对象(“资源”)和对象间关系的数据模型,并为这种数据模型提供一个简单的语义。
XML是一种定义标记的通用元语言,它向用户提供统一的框架,以便在不同应用之间交换数据和元数据。然而,XML并没有提供任何表示数据语义(semantics)的手段。例如,XML中的标签嵌套没有预定含义,完全由应用程序自行解释。例如,计算机并不能理解下面一段XML的含义。
<course name =“离散数学”>
<lecturer>David Billington</lecturer>
</course>
而RDF,实际上是一个数据模型(data-model),它由一系列陈述(statement)——即“对象-属性-值”三元组(object-attribute-value triple)组成。例如,
&lt;img src="https://pic4.zhimg.com/f102ec63345d545a4c863c8b785d9637_b.png" data-rawwidth="314" data-rawheight="20" class="content_image" width="314"&gt;使用RDF陈述为: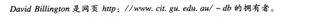 使用RDF陈述为:
使用RDF陈述为:
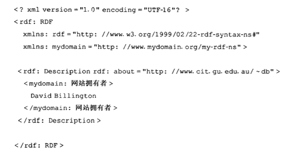
4. RDF Schema:刻画RDF资源的属性和类的词汇描述语言。RDFS定义RDF数据模型所使用的词汇,规定什么属性可以作用于什么类型的对象,属性可以取什么值,也可以描述对象之间的关系。从语义网的观点来看,RDFS使机器可以解读语义信息。
5. OWL:是一个更丰富的词汇描述语言。
———————————————————————————————————————————
一些延伸:语义网的相关知识
「语义网是什么,为什么需要语义网」
由于目前基于关键词的搜索引擎存在着缺少「语义」的困难,往往会出现高匹配低精度、低匹配或无匹配、检索结果对词汇高度敏感、检索结果的是单一的网页等问题。
因此,W3C联盟发起了“用一种更容易被机器处理的方式来描述网上内容,并采用智能技术来利用这种表示方法所提供的便利”的方案,称为语义网Semantic Web运动。
语义网旨在改进万维网的现状。语义网的核心想法是使用机器可处理的网络信息。
「语义网设计蓝图的主要层次(layer cake)」
语义网的研发是逐层进行的——
“语义网的研究要一步一步地推进,每一步都要在前一层上搭建新的一层。”
“这样做的理由是,小步前进比较容易达成共识。一般情况下,会有多个团队沿着不同方向研究同一个问题。这样一来,即使更宏伟的目标失败了,至少还能得到一些积极的部分成果。”
&lt;img src="https://pic3.zhimg.com/7322e96fe1e753c4a22a4cc1c4e07912_b.png" data-rawwidth="519" data-rawheight="379" class="origin_image zh-lightbox-thumb" width="519" data-original="https://pic3.zhimg.com/7322e96fe1e753c4a22a4cc1c4e07912_r.png"&gt;
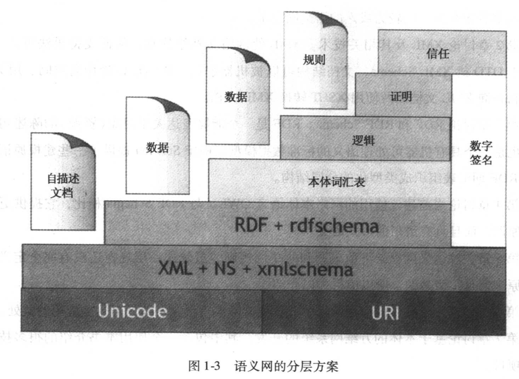
第一层:“字符集”层,包括Unicode和URI。在语义网体系结构中,该层是整个语义网的基础,其中Unicode负责处理资源的编码,URI负责资源的标识。
第二层:根标记语言层。
XML+NS+xmlschema。该层负责从语法上表示数据的内容和结构,通过使用标准的语言将网络信息的表现形式、数据结构和内容分离。
第三层:“资源描述框架”层。
RDF+rdfschema。RDF是一种描述WWW上的信息资源的一种语言,其目标是建立一种供多种元数据标准共存的框架。该框架能充分利用各种元数据的优势,进行基于Web 的数据交换和再利用。RDF解决的是如何采用XML标准语法无二义性地描述资源对象的问题,使得所描述的资源的元数据信息成为机器可理解的信息。如果把XML看作为一种标准化的元数据语法规范的话,那么RDF就可以看作为一种标准化的元数据语义描述规范。Rdfschema使用一种机器可以理解的体系来定义描述资源的词汇,其目的是提供词汇嵌入的机制或框架,在该框架下多种词汇可以集成在一起实现对Web资源的描述。
第四层:“本体词汇”层。
“本体词汇”,(外语:Ontology vocabulary)。该层是在RDF(S)基础上定义的概念及其关系的抽象描述,用于描述应用领域的知识,描述各类资源及资源之间的关系,实现对词汇表的扩展。在这一层,用户不仅可以定义概念而且可以定义概念之间丰富的关系。
第五至七层:Logic、Proof、Trust。
Logic负责提供公理和推理规则,而Logic一旦建立,便可以通过逻辑推理对资源、资源之间的关系以及推理结果进行验证,证明其有效性。
通过Proof交换以及数字签名,建立一定的信任关系,从而证明语义网输出的可靠性以及其是否符合用户的要求。














 2113
2113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









