






CILP这篇论文介绍的是 OpenAI 提出的 CLIP(Contrastive Language-Image Pretraining),它是多模态学习的一次重大突破。以下从技术角度深入分析:
1. 传统计算机视觉的局限性
目前大多数计算机视觉模型的训练方式都是 有监督学习,即:
- 需要大量 标注数据(如 ImageNet 1.28M 张图像,每张都有人类标注类别)。
- 只能识别 固定类别(比如 ImageNet 训练的 ResNet-50 只能分类 1000 个类别)。
- 一旦遇到新的类别(如 ImageNet 中没有的物种),就需要重新收集标注数据并训练。
➡ CLIP 旨在解决这一问题,让模型可以泛化到新的类别,甚至不需要额外的标注数据。
2. CLIP 的核心创新
CLIP 采用了一种自监督对比学习(Contrastive Learning) 的方式,用自然语言文本作为监督信号来训练图像模型:
- 数据来源:从互联网收集了 4 亿对(图像,文本)。
- 训练任务:对比学习:
- 正样本:真实的(图片,文本)对(即描述和图像匹配)。
- 负样本:随机匹配的(图片,文本)对(即错误描述)。
- 目标是让模型学会匹配正确的图像和描述,并区分错误的匹配。
模型架构:
- 视觉编码器(ViT 或 ResNet):将图像编码为特征向量。
- 文本编码器(Transformer):将文本描述编码为特征向量。
计算图像-文本相似度,通过对比学习优化。
这种方法使得 CLIP 具备了 视觉与语言的跨模态理解能力。
3. CLIP 的核心优势
✔ Zero-shot 迁移能力:
- 传统 CNN 需要针对 ImageNet 进行专门训练,但 CLIP 不需要 ImageNet 训练,仅仅依靠 互联网文本描述 进行学习后,就可以直接零样本分类。
- 在 ImageNet 上,CLIP zero-shot 准确率 ≈ ResNet-50(而 ResNet-50 需要 128 万张标注图片训练)。
✔ 通用视觉理解能力:
- 传统视觉模型只能识别固定类别,但 CLIP 可以识别和描述新类别,因为它学到了文本中的丰富语义信息。
- 例如,CLIP 可以理解“一只坐在键盘上的橘猫”这样复杂的自然语言描述,并匹配到对应的图片。
✔ 适应多种任务:
- CLIP 不只是用于分类,它还可以用于 OCR(光学字符识别)、动作识别、地理定位、细粒度分类 等多种任务,而不需要特定的数据集训练。
一.摘要和结论部分
1.1摘要翻译
当前最先进的计算机视觉系统通常被训练来预测一组预先确定的目标类别。这种受限的监督方式限制了模型的泛化能力和适用性,因为如果想要识别新的视觉概念,就必须额外获取标注数据。相比之下,直接从关于图像的原始文本中学习是一种更具潜力的替代方案,它可以利用更广泛的数据来源来进行监督学习。
本研究表明,仅通过一个简单的预训练任务——预测哪一张图片与哪一个文本描述匹配,就可以高效、可扩展地从头学习最先进(SOTA)的图像表示。我们使用从互联网收集的 4 亿对(图片、文本) 进行预训练。在训练完成后,模型可以利用自然语言来引用已学习的视觉概念(或描述新的概念),从而实现零样本(zero-shot)迁移,直接应用到下游任务中。
我们通过在超过 30 个不同的计算机视觉数据集 上进行基准测试,评估了该方法的性能,涵盖了 OCR(光学字符识别)、视频中的动作识别、地理定位以及多种细粒度目标分类任务。我们的模型可以非平凡地迁移到大多数任务,并且在许多情况下,即使不针对具体数据集进行额外训练,也能与完全监督的基线方法相媲美。例如,我们在 ImageNet 数据集上的 zero-shot 预测准确率达到与原始 ResNet-50 相当的水平,而无需使用其训练所需的 128 万个标注样本。
我们在 GitHub(https://github.com/OpenAI/CLIP)上开源了代码和预训练模型权重。
1.2结论翻译
我们研究了是否可以将 NLP 领域中无任务特定、基于大规模 Web 预训练的成功经验迁移到其他领域。研究表明,采用这一方法后,在计算机视觉领域也会出现类似的现象。我们还探讨了这一研究方向可能带来的社会影响。
为了优化训练目标,CLIP 模型在预训练阶段学会执行多种任务。这些任务学习的能力可以通过自然语言提示(prompting)加以利用,使得 CLIP 能够在无需额外训练的情况下(zero-shot)适配多个已有数据集。
在足够大规模的数据和模型条件下,该方法的性能可以与特定任务的监督学习模型相竞争,但仍然有较大的提升空间。
1.3解析
CLIP 对计算机视觉的跨任务泛化能力
CLIP 采用了类似 NLP 预训练的方式,使得计算机视觉模型可以像 NLP 一样,通过大规模自监督学习获得跨任务泛化能力。以下是 CLIP 在计算机视觉领域的重要突破点和挑战。
1. 任务无关(Task-agnostic)大规模预训练的迁移
在 NLP 领域,大规模的无监督预训练(self-supervised pretraining) 取得了巨大的成功,例如:
BERT(Devlin et al., 2019):通过Masked Language Model (MLM) 学习文本表示,之后可迁移到多种任务(如情感分析、问答、文本生成)。
GPT(Radford et al., 2018):通过自回归语言建模,可以完成文本生成、对话、代码生成等任务。
这些模型的核心思想是:先进行大规模的通用预训练,使其学习到丰富的语义知识,再通过少量样本微调(fine-tuning)或直接零样本推理(zero-shot inference)迁移到下游任务。
CLIP 试图将这一策略迁移到计算机视觉领域:
通过对比学习(contrastive learning)在图像-文本数据上进行预训练,而不是传统的监督学习。不局限于某个特定的任务,而是学习通用的视觉概念,使其可以跨任务泛化。
➡ 这意味着 CLIP 不再是一个专门用于分类、检测或分割的模型,而是一个可以适配不同任务的通用视觉模型。
2. 任务学习与自然语言提示(Prompting)
在 NLP 领域,GPT、BERT 这类模型的一个关键特性是可以通过 Prompting 调整行为:
- 例如,GPT-3 在没有微调的情况下,只需要输入“翻译成法语:Hello, how are you?”,它就能正确地翻译出 “Bonjour, comment ça va?”。
- 这种能力使得大模型可以零样本适配(zero-shot transfer) 到许多不同的 NLP 任务,而不需要额外训练。
CLIP 采用了类似的策略:
- 训练阶段,模型学习到如何将图像和文本进行匹配。
- 推理时,只需要输入合适的文本提示(prompt),CLIP 就能找到最匹配的图像(或者反向地,从图像中匹配最相关的文本)。
例如,在 ImageNet 上做 zero-shot 任务时:
- 传统 CNN 需要训练 1000 个类别的分类器。
- CLIP 只需要给定 “这是一只猫”/“这是一条狗” 的文本提示,它就能从图像中选出匹配的类别。
- 完全不需要对 ImageNet 进行额外训练!
➡ 这使得 CLIP 在跨任务迁移时更具灵活性,不再依赖于固定类别的训练数据。
3. 规模效应(Scale Effect)与性能
CLIP 论文强调了**规模(scale)**的重要性:
在 NLP 领域,BERT、GPT 的成功很大程度上依赖于大量的无标注文本数据 和 超大规模模型(如 GPT-4)。
在计算机视觉领域,CLIP 也展示了类似的趋势:
训练数据达到 4 亿对(图像,文本),远超 ImageNet(仅有 128 万张)。
模型规模越大,泛化能力越强,在 zero-shot 任务上的表现也越接近有监督训练的 SOTA 模型。
然而,论文也指出:
尽管 CLIP 已经非常强大,但仍然没有完全超越监督学习方法。
Zero-shot 任务在某些特定领域仍然存在性能差距(如医学影像、工业检测等)。
这表明 CLIP 虽然证明了“任务无关预训练”在计算机视觉领域的可行性,但仍然有优化空间,特别是在提升 few-shot 或 zero-shot 任务的性能方面。
二.Intro部分
CLIP 如何利用大规模自然语言监督进行图像表示学习
1. NLP 领域的预训练革命
论文首先回顾了基于大规模文本数据的预训练方法如何彻底改变 NLP 领域:
- 无任务特定(task-agnostic)的目标函数(如自回归语言模型、MLM)在计算、模型容量和数据规模上不断扩展,提高了泛化能力。
- 标准化的“文本到文本”接口(text-to-text)(如 T5,GPT)使得 NLP 预训练模型可以直接进行 zero-shot 迁移,而无需特定任务的分类头或数据集定制。
- 例如,GPT-3 在许多任务上可以与专门微调的模型竞争,但几乎不需要特定数据集的训练,表明Web 规模的文本集合比人工标注的 NLP 数据集提供了更丰富的监督信号。
- 但是,在计算机视觉领域,主流的预训练方法仍然依赖于人工标注的数据集(如 ImageNet),论文提出一个核心问题: 💡 如果视觉模型也采用从 Web 规模文本中直接学习的可扩展预训练方法,是否能带来类似的突破?
2. 计算机视觉中的文本监督尝试
论文回顾了历史上使用文本作为监督信号训练视觉模型的尝试:
- 早期探索(1999-2016):
- Mori et al. (1999) 训练模型来预测文本文档中的名词和形容词,以改进基于内容的图像检索。
- Quattoni et al. (2007) 研究通过**流形学习(manifold learning)**来提高视觉表示的效率。
- Joulin et al. (2016) 训练 CNN 预测图像的标题、描述和标签,将其转化为多标签分类任务,并发现其迁移性能可以媲美 ImageNet 预训练。
- 近年 Transformer 时代的进展(2017-2020):
- VirTex (Desai & Johnson, 2020):利用 Transformer 进行文本生成任务,以学习更好的图像表示。
- ICMLM (Bulent Sariyildiz et al., 2020):使用掩码语言建模(MLM)来学习视觉特征。
- ConVIRT (Zhang et al., 2020):采用对比学习(contrastive learning)从文本中学习视觉表示。
这些研究表明,自然语言监督在理论上可行,但在实践中存在以下挑战:
- 这些方法在常见基准(如 ImageNet)上的性能远低于传统监督学习方法(例如,Li et al. (2017) 的 zero-shot ImageNet 准确率仅为 11.5%,远低于 SOTA 88.4%)。
- 受限于计算资源,过去的方法通常仅在 10 万到 100 万级别的数据集上训练,而传统视觉模型的预训练数据量往往是数十亿级别。
3. CLIP 的提出:大规模对比学习(Contrastive Learning)
💡 论文提出 CLIP(Contrastive Language-Image Pre-training)方法,通过大规模对比学习实现更有效的视觉表征学习:
- 从互联网中收集 4 亿个(图像,文本)对,显著扩展数据规模。
- 采用改进版 ConVIRT 方法,直接从自然语言监督信号中学习视觉特征,而不依赖传统的静态 softmax 分类器。
- 训练了8 个不同规模的 CLIP 模型,研究其性能随计算量扩展的变化,并发现其表现类似 GPT 系列:
- 随着计算量的增加,模型性能可预测地提升(符合 Hestness et al., 2017 和 Kaplan et al., 2020 提出的计算扩展定律)。
CLIP 在预训练中学习了一系列视觉任务,包括:
- ✅ OCR(光学字符识别)
- ✅ 地理定位(Geo-localization)
- ✅ 动作识别(Action recognition)
- ✅ 物体分类(Object classification)
📌 这表明 CLIP 可以像 GPT 那样,在没有特定监督的情况下,自然地学习不同任务的能力!
4. CLIP 的 Zero-shot 能力与 ImageNet 评测
- 在 30 多个数据集上评测 CLIP 的 Zero-shot 迁移能力,发现其可以与特定任务的监督模型竞争。
- 线性探针(Linear Probe)分析显示 CLIP 预训练的特征比最好的公开 ImageNet 预训练模型表现更好,同时计算效率更高。
- CLIP 的 Zero-shot 模型比 ImageNet 监督模型更具鲁棒性:
- 传统监督模型容易受到数据分布变化的影响(如对抗样本、图像模糊、风格变化)。
- CLIP 由于学习了更广泛的视觉概念,在分布外数据上更具稳健性。
这些结果表明:
- ➡ Zero-shot 评测比传统的 ImageNet 评测更能代表一个模型的真实能力。
- ➡ 自然语言提供的监督比静态分类头更灵活,能够覆盖更广泛的视觉概念。
三.方法部分
自然语言监督与大规模视觉模型训练解析
2.1. 自然语言监督(Natural Language Supervision)
这一部分强调了利用自然语言作为监督信号来训练视觉模型的核心理念。研究者指出,虽然这一方法已有前人尝试,但不同研究对于其描述方式不一(如无监督、自监督、弱监督或监督学习),导致概念混乱。然而,所有方法的共同点在于利用自然语言来训练视觉模型,而非具体的方法细节。
关键点解析:
早期方法(如主题建模、n-gram)在处理自然语言时较为复杂,而现代**深度上下文表示学习(如Transformer)**极大提升了自然语言的可利用性。
自然语言监督的优势:
- 可扩展性强:相比人工标注(如ImageNet的1-of-N多数投票标签),自然语言数据可通过互联网大规模获取。
- 超越无监督/自监督学习:不仅学习视觉表征,还将其直接对齐到语言,提升零样本(zero-shot)迁移能力。
2.2. 构建大规模数据集
研究者指出,以往的主要视觉数据集(如MS-COCO、Visual Genome、YFCC100M)规模较小或标注质量参差不齐。因此,他们创建了一个包含4亿对(图片,文本)数据的新数据集——WebImageText(WIT),该数据集主要来自公开互联网,并采用了以下策略:
- 从500,000个查询构建数据集,以尽可能覆盖广泛的视觉概念。
- 类别均衡:每个查询最多包含20,000对(图片,文本)。
- 规模匹配WebText(GPT-2训练数据),以确保高质量的文本监督。
核心价值:
- 比ImageNet更大(15M vs. 400M),增强泛化能力。
- 网络爬取的文本数据提供了更丰富的语义信息,相比人工标注更加自然、开放。
2.3. 选择高效的预训练方法
研究发现,传统的监督学习方法计算成本过高(如ResNeXt101-32x48d训练耗时19 GPU年),因此他们探索更高效的训练方式。
关键技术突破:
对比学习(Contrastive Learning):
- 传统方法(如VirTex)直接预测图像的文本描述,难以扩展。
- 采用对比学习,仅预测哪对(图片,文本)匹配,而非精确文本内容。
- 这种方法相比预测模型,在零样本任务上的效率提升了4倍。
**CLIP(Contrastive Language-Image Pretraining)**的训练机制:
- 给定一个批次的N对(图片,文本),模型需要在N×N种可能的匹配中找出真实的N对。
- 采用对比损失(InfoNCE)最大化正确匹配的余弦相似度,同时最小化错误匹配的相似度。
- 这种方法源于深度度量学习(Multi-class N-pair Loss),并在**自监督学习(SimCLR)**中得到推广。
优势:
- 相比传统生成模型(如GAN、VAE),对比学习更高效。
- 无需ImageNet预训练,直接从零开始训练。
2.4. 选择与扩展模型
在图像编码器(Image Encoder)方面:
ResNet变体:
- 采用ResNet-50,并结合ResNet-D改进(He et al., 2019)和抗锯齿模糊池化(anti-aliased rect-2 blur pooling)。
- 使用**注意力池化(attention pooling)**替代全局平均池化,提高信息保留能力。
Vision Transformer(ViT):
- 在标准ViT基础上增加额外的层归一化(Layer Norm),增强训练稳定性。
在文本编码器(Text Encoder)方面:
- 使用Transformer架构(Radford et al., 2019),参数规模为63M,采用BPE分词(49,152词汇量),最大序列长度76。
文本特征提取方式:
- 最高层的[EOS] token表示文本嵌入,再映射到多模态嵌入空间。
- 采用掩码自注意力(Masked Self-Attention),便于与预训练语言模型兼容。
模型扩展策略(Scaling Strategy):
- ResNet扩展方式:同时增加宽度、深度和分辨率(类似EfficientNet)。
- ViT扩展方式:主要增加分辨率,如ViT-L/14在336px下进行额外训练。
2.5. 训练
研究者训练了5个ResNet和3个ViT,采用以下优化策略:
优化器:
Adam + 权重衰减(Weight Decay)。
学习率策略:
余弦退火(Cosine Annealing)。
超参数搜索:
- 先在ResNet-50上用网格搜索+随机搜索调优1个epoch。
- 再根据经验调整更大模型的超参数。
计算资源消耗:
批次大小:32,768(极大加速训练)。
计算优化:
- 混合精度(Mixed Precision),减少显存占用。
- 梯度检查点(Gradient Checkpointing),节省显存。
- 半精度Adam权重(Half-Precision Adam),加速计算。
- GPU并行计算相似度,优化大规模矩阵计算。
训练时长:
- 最大ResNet(RN50x64):592个V100 GPU上训练18天。
- 最大ViT(ViT-L/14):256个V100 GPU上训练12天。
最终模型:
ViT-L/14@336px 被选为最佳模型,主要因其性能最优。
总结
本研究构建了一个4亿张图片+文本的超大规模数据集(WIT),并采用对比学习(Contrastive Learning)训练了CLIP,实现了高效的跨模态(Vision-Language)学习。相比传统方法,CLIP的优势如下:
- 无需手工标注,利用海量互联网数据训练。
- 零样本能力强,可适用于开放集分类任务。
- 计算效率高,对比学习显著减少计算资源需求。
- 支持多种架构(ResNet、ViT),具备良好的可扩展性。
CLIP的成功验证了自然语言监督的可行性,预示着未来视觉模型将更加依赖开放世界知识,而非封闭标签数据集。这一方向可能会对**多模态AI(Multimodal AI)**的发展产生深远影响。
2.5训练过程详解
与传统的图像模型(通常训练一个图像特征提取器和线性分类器来预测标签)不同,CLIP的目标是通过对比学习(Contrastive Learning)让图像和文本在特征空间中对齐,从而实现强大的泛化能力,例如零样本(zero-shot)分类。以下是详细的训练步骤:
1. CLIP的基本架构
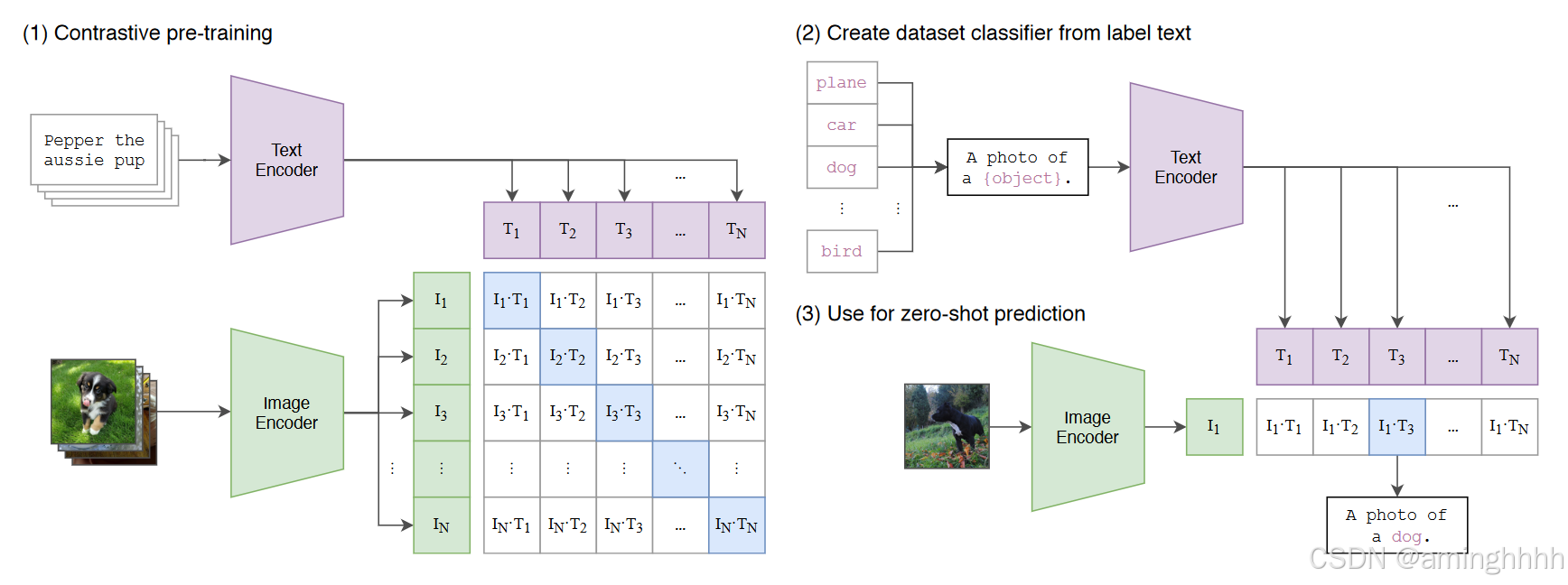
CLIP由两个核心组件组成:
- 图像编码器(Image Encoder)
功能:将输入的图像转换为固定维度的特征向量。
实现:通常使用卷积神经网络(如ResNet)或视觉Transformer(如ViT)。
输出:一个d维的图像特征向量 。
- 文本编码器(Text Encoder)
功能:将输入的文本(例如标题或描述)转换为固定维度的特征向量。
实现:通常基于Transformer架构(如BERT的变体)。
输出:一个d维的文本特征向量,
- 目标:通过训练,使相关联的图像和文本对(即正确配对)的特征向量在嵌入空间中更接近,而不相关对(即错误配对)更远。
2. 训练数据
CLIP的训练依赖于大规模的图像-文本对数据集。这些数据通常从互联网上抓取,例如:
- 图像及其对应的标题(captions)。
- 图像及其描述性文本(descriptions)。
- 假设一个数据集包含数千万到数亿个这样的配对,每个训练样本是一个二元组
- (𝑖𝑚𝑎𝑔𝑒𝑖,𝑡𝑒𝑥𝑡𝑖)。这些配对不需要额外的类别标签,直接利用自然语言描述与图像的对应关系。
3. 对比学习的核心思想
·CLIP采用对比学习作为训练范式。对比学习的目标是通过优化模型,使其能够区分“正样本”(正确的图像-文本对)和“负样本”(错误的图像-文本对)。在CLIP中:
- 正样本:在一个batch中,图像 是正确的配对。
- 负样本:同一batch中,图像 与其他文本 的组合,或文本 与其他图像 的组合。
通过这种方式,模型学习到的表示能够反映图像和文本之间的语义关联。
4. 训练过程的详细步骤
4.1 数据批处理(Batch Preparation)
- 假设一个batch包含N个图像-文本对:
![]()
- 这些配对是预先定义的正确对
4.2 特征提取(Feature Extraction)
- 图像编码
- 文本编码
4.3 相似度计算(Similarity Computation)

4.4 对比损失函数(Contrastive Loss)
CLIP的损失函数基于交叉熵,目标是:
- 最大化正确配对(的相似度。
- 最小化错误配对的相似度。
损失函数是对称的,包含两个方向:
- 图像到文本(Image-to-Text)。
- 文本到图像(Text-to-Image)。
CLIP的总损失是两个方向损失的平均
CLIP通过对比学习联合训练图像编码器和文本编码器,使其能够预测图像-文本对的正确配对。其训练过程包括特征提取、相似度计算和基于交叉熵的对比损失优化。对比学习的核心在于最大化正样本相似度、最小化负样本相似度,通过对称的损失函数实现双向对齐。训练后的模型具备强大的跨模态表示能力,可直接应用于zero-shot分类等任务,体现了对比学习在多模态任务中的潜力。

















 3295
3295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









